distrifuser
v0.0.1beta0
[29 Juli 2024] DistriFusion didukung di ColossalAI!
[4 April 2024] DistriFusion terpilih sebagai poster utama di CVPR 2024!
[29 Feb 2024] DistriFusion diterima oleh CVPR 2024! Kode kami tersedia untuk umum!
 Kami memperkenalkan DistriFusion, algoritme tanpa pelatihan untuk memanfaatkan banyak GPU guna mempercepat inferensi model difusi tanpa mengorbankan kualitas gambar. Naïve Patch (Ikhtisar (b)) mengalami masalah fragmentasi karena kurangnya interaksi patch. Contoh yang disajikan dihasilkan dengan SDXL menggunakan sampler Euler 50 langkah pada resolusi 1280×1920, dan latensi diukur pada GPU A100.
Kami memperkenalkan DistriFusion, algoritme tanpa pelatihan untuk memanfaatkan banyak GPU guna mempercepat inferensi model difusi tanpa mengorbankan kualitas gambar. Naïve Patch (Ikhtisar (b)) mengalami masalah fragmentasi karena kurangnya interaksi patch. Contoh yang disajikan dihasilkan dengan SDXL menggunakan sampler Euler 50 langkah pada resolusi 1280×1920, dan latensi diukur pada GPU A100.
DistriFusion: Inferensi Paralel Terdistribusi untuk Model Difusi Resolusi Tinggi
Muyang Li*, Tianle Cai*, Jiaxin Cao, Qinsheng Zhang, Han Cai, Junjie Bai, Yangqing Jia, Ming-Yu Liu, Kai Li, dan Song Han
MIT, Princeton, Lepton AI, dan NVIDIA
Di CVPR 2024.
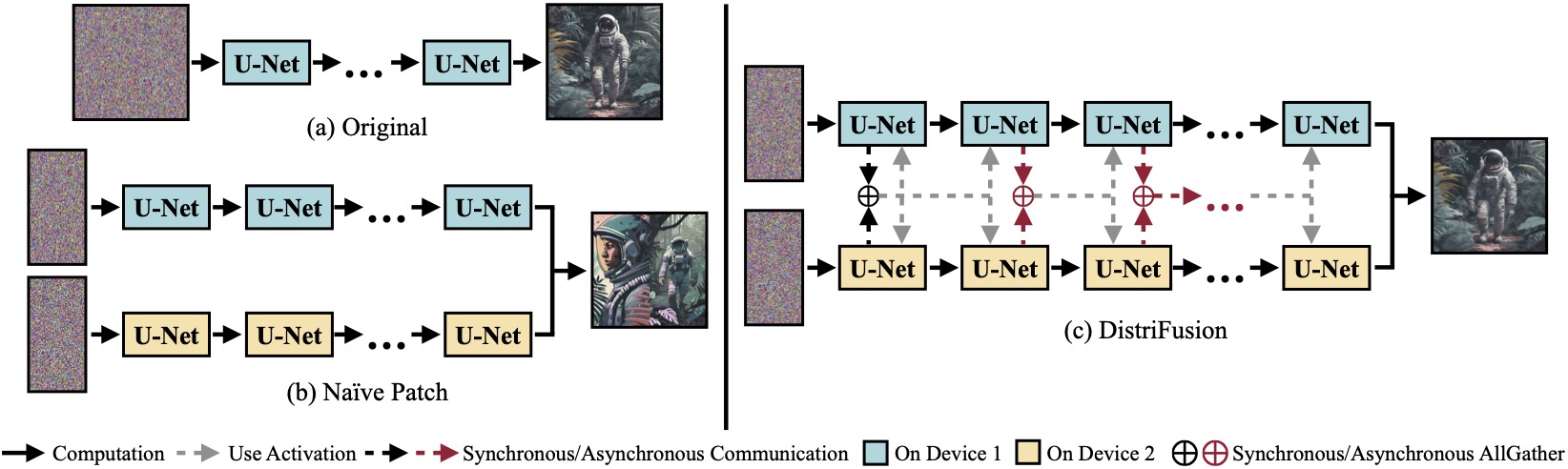 (a) Model difusi asli yang berjalan pada satu perangkat. (b) Secara naif membagi gambar menjadi 2 patch pada 2 GPU memiliki jahitan yang jelas pada batasnya karena tidak adanya interaksi antar patch. (c) DistriFusion kami menggunakan komunikasi sinkron untuk interaksi patch pada langkah pertama. Setelah itu, kami menggunakan kembali aktivasi dari langkah sebelumnya melalui komunikasi asinkron. Dengan cara ini, overhead komunikasi dapat disembunyikan ke dalam jalur komputasi.
(a) Model difusi asli yang berjalan pada satu perangkat. (b) Secara naif membagi gambar menjadi 2 patch pada 2 GPU memiliki jahitan yang jelas pada batasnya karena tidak adanya interaksi antar patch. (c) DistriFusion kami menggunakan komunikasi sinkron untuk interaksi patch pada langkah pertama. Setelah itu, kami menggunakan kembali aktivasi dari langkah sebelumnya melalui komunikasi asinkron. Dengan cara ini, overhead komunikasi dapat disembunyikan ke dalam jalur komputasi.
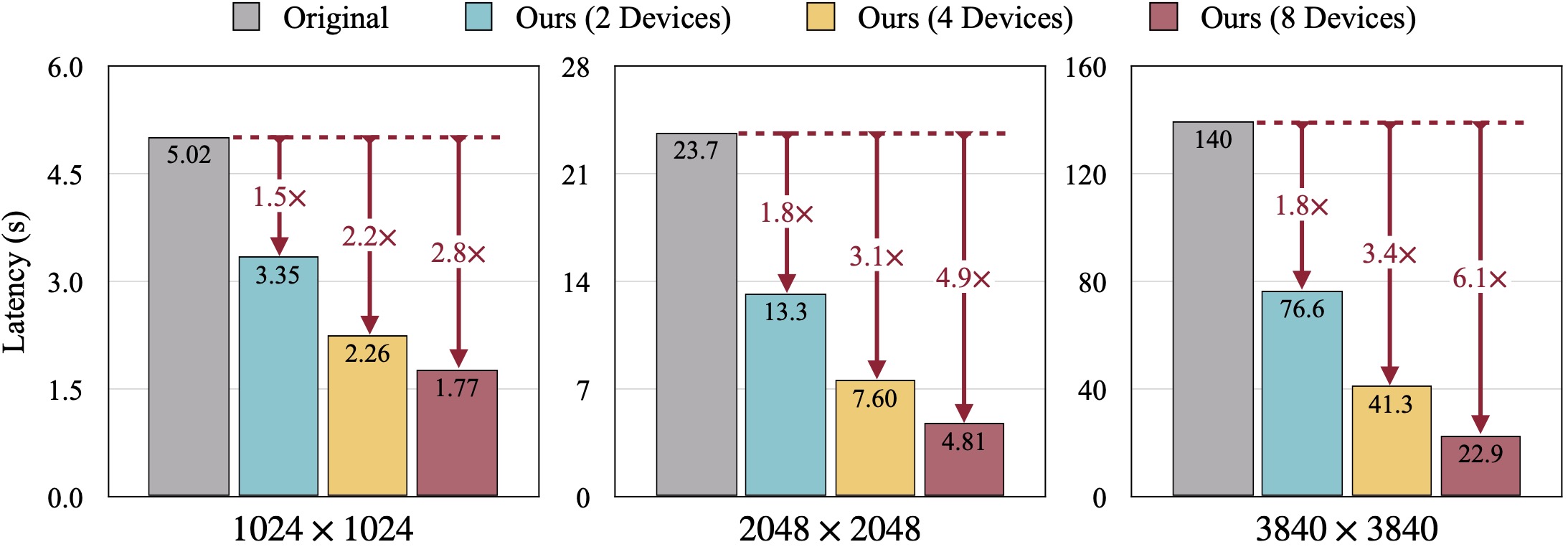
 Hasil kualitatif SDXL. FID dihitung berdasarkan gambar kebenaran dasar. DistriFusion kami dapat mengurangi latensi sesuai dengan jumlah perangkat yang digunakan dengan tetap menjaga fidelitas visual.
Hasil kualitatif SDXL. FID dihitung berdasarkan gambar kebenaran dasar. DistriFusion kami dapat mengurangi latensi sesuai dengan jumlah perangkat yang digunakan dengan tetap menjaga fidelitas visual.
Referensi:
Setelah menginstal PyTorch, Anda seharusnya dapat menginstal distrifuser dengan PyPI
pip install distrifuseratau melalui GitHub:
pip install git+https://github.com/mit-han-lab/distrifuser.gitatau lokal untuk pembangunan
git clone [email protected]:mit-han-lab/distrifuser.git
cd distrifuser
pip install -e . Di scripts/sdxl_example.py , kami menyediakan skrip minimal untuk menjalankan SDXL dengan DistriFusion.
import torch
from distrifuser . pipelines import DistriSDXLPipeline
from distrifuser . utils import DistriConfig
distri_config = DistriConfig ( height = 1024 , width = 1024 , warmup_steps = 4 )
pipeline = DistriSDXLPipeline . from_pretrained (
distri_config = distri_config ,
pretrained_model_name_or_path = "stabilityai/stable-diffusion-xl-base-1.0" ,
variant = "fp16" ,
use_safetensors = True ,
)
pipeline . set_progress_bar_config ( disable = distri_config . rank != 0 )
image = pipeline (
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k" ,
generator = torch . Generator ( device = "cuda" ). manual_seed ( 233 ),
). images [ 0 ]
if distri_config . rank == 0 :
image . save ( "astronaut.png" ) Secara khusus, distrifuser kami berbagi API yang sama dengan diffuser dan dapat digunakan dengan cara yang serupa. Anda hanya perlu mendefinisikan DistriConfig dan menggunakan DistriSDXLPipeline kami yang terbungkus untuk memuat model SDXL yang telah dilatih sebelumnya. Kemudian, kita dapat menghasilkan gambar seperti StableDiffusionXLPipeline di diffuser. Perintah yang berjalan adalah
torchrun --nproc_per_node= $N_GPUS scripts/sdxl_example.py di mana $N_GPUS adalah jumlah GPU yang ingin Anda gunakan.
Kami juga menyediakan skrip minimal untuk menjalankan SD1.4/2 dengan DistriFusion di scripts/sd_example.py . Penggunaannya sama.
Hasil benchmark kami menggunakan PyTorch 2.2 dan diffusers 0.24.0. Pertama, Anda mungkin perlu menginstal beberapa dependensi tambahan:
pip install git+https://github.com/zhijian-liu/torchprofile datasets torchmetrics dominate clean-fid Anda dapat menggunakan scripts/generate_coco.py untuk menghasilkan gambar dengan keterangan COCO. Perintahnya adalah
torchrun --nproc_per_node=$N_GPUS scripts/generate_coco.py --no_split_batch
di mana $N_GPUS adalah jumlah GPU yang ingin Anda gunakan. Secara default, hasil yang dihasilkan akan disimpan di results/coco . Anda juga dapat menyesuaikannya dengan --output_root . Beberapa argumen tambahan yang mungkin ingin Anda sesuaikan:
--num_inference_steps : Jumlah langkah inferensi. Kami menggunakan 50 secara default.--guidance_scale : Skala panduan bebas pengklasifikasi. Kami menggunakan 5 secara default.--scheduler : Sampler difusi. Kami menggunakan sampler DDIM secara default. Anda juga dapat menggunakan euler untuk sampler Euler dan dpm-solver untuk pemecah DPM.--warmup_steps : Jumlah langkah pemanasan tambahan (4 secara default).--sync_mode : Mode sinkronisasi GroupNorm yang berbeda. Secara default, ini menggunakan GroupNorm asinkron kami yang telah diperbaiki.--parallelism : Paradigma paralelisme yang Anda gunakan. Secara default, ini adalah paralelisme patch. Anda dapat menggunakan tensor untuk paralelisme tensor dan naive_patch untuk naïve patch. Setelah Anda membuat semua gambar, Anda dapat menggunakan skrip scripts scripts/compute_metrics.py kami untuk menghitung PSNR, LPIPS, dan FID. Penggunaannya adalah
python scripts/compute_metrics.py --input_root0 $IMAGE_ROOT0 --input_root1 $IMAGE_ROOT1 di mana $IMAGE_ROOT0 dan $IMAGE_ROOT1 merupakan jalur ke folder gambar yang ingin Anda bandingkan. Jika IMAGE_ROOT0 adalah foler kebenaran dasar, harap tambahkan tanda --is_gt untuk mengubah ukuran. Kami juga menyediakan skrip scripts/dump_coco.py untuk membuang gambar kebenaran dasar.
Anda dapat menggunakan scripts/run_sdxl.py untuk mengukur latensi dengan berbagai metode kami. Perintahnya adalah
torchrun --nproc_per_node= $N_GPUS scripts/run_sdxl.py --mode benchmark --output_type latent di mana $N_GPUS adalah jumlah GPU yang ingin Anda gunakan. Mirip dengan scripts/generate_coco.py , Anda juga dapat mengubah beberapa argumen:
--num_inference_steps : Jumlah langkah inferensi. Kami menggunakan 50 secara default.--image_size : Ukuran gambar yang dihasilkan. Secara default, ini adalah 1024×1024.--no_split_batch : Nonaktifkan pemisahan batch untuk panduan bebas pengklasifikasi.--warmup_steps : Jumlah langkah pemanasan tambahan (4 secara default).--sync_mode : Mode sinkronisasi GroupNorm yang berbeda. Secara default, ini menggunakan GroupNorm asinkron kami yang telah diperbaiki.--parallelism : Paradigma paralelisme yang Anda gunakan. Secara default, ini adalah paralelisme patch. Anda dapat menggunakan tensor untuk paralelisme tensor dan naive_patch untuk naïve patch.--warmup_times / --test_times : Jumlah pemanasan/pengujian yang dijalankan. Secara default, masing-masing berjumlah 5 dan 20. Jika Anda menggunakan kode ini untuk penelitian Anda, silakan kutip makalah kami.
@inproceedings { li2023distrifusion ,
title = { DistriFusion: Distributed Parallel Inference for High-Resolution Diffusion Models } ,
author = { Li, Muyang and Cai, Tianle and Cao, Jiaxin and Zhang, Qinsheng and Cai, Han and Bai, Junjie and Jia, Yangqing and Liu, Ming-Yu and Li, Kai and Han, Song } ,
booktitle = { Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) } ,
year = { 2024 }
}Kode kami dikembangkan berdasarkan huggingface/diffusers dan lmxyy/sige. Kami berterima kasih kepada torchprofile untuk pengukuran MAC, clean-fid untuk komputasi FID, dan Lightning-AI/torchmetrics untuk PSNR dan LPIPS.
Kami berterima kasih kepada Jun-Yan Zhu dan Ligeng Zhu atas diskusi mereka yang bermanfaat dan masukan yang berharga. Proyek ini didukung oleh MIT-IBM Watson AI Lab, Amazon, MIT Science Hub, dan National Science Foundation.


