BeatLearning
1.0.0
Pernahkah Anda ingin memainkan lagu yang tidak tersedia di permainan ritme favorit Anda? Pernahkah Anda ingin memainkan variasi lagu itu tanpa batas?
Proyek penelitian Open Source ini bertujuan untuk mendemokratisasi proses pembuatan beatmap otomatis, menawarkan alat dan model dasar yang dapat diakses oleh pengembang, pemain, dan penggemar game, membuka jalan bagi era baru kreativitas dan inovasi dalam permainan ritme.
Contoh (selengkapnya segera hadir):
Pertama-tama Anda perlu menginstal Python 3.12, masuk ke direktori repositori dan membuat lingkungan virtual melalui:
python3 -m venv venv
Kemudian hubungi source venv/bin/activate atau venvScriptsactivate jika Anda menggunakan mesin Windows. Setelah lingkungan virtual diaktifkan, Anda dapat menginstal perpustakaan yang diperlukan melalui:
pip3 install -r requirements.txt
Anda dapat menggunakan Jupyter untuk mengakses contoh notebooks/ :
jupyter notebook
Anda juga dapat mencoba versi Google Collab, selama Anda memiliki instance GPU yang tersedia (CPU default memerlukan waktu lama untuk mengonversi lagu).
Pipeline ini hanya mendukung beatmap OSU saat ini.
Repositori ini masih dalam tahap PEKERJAAN . Tujuannya adalah untuk mengembangkan model generatif yang mampu secara otomatis menghasilkan beatmap untuk beragam permainan ritme, apa pun lagunya. Penelitian ini masih berlangsung, namun tujuannya adalah untuk mengeluarkan MVP secepat mungkin.
Semua kontribusi dihargai, terutama dalam bentuk donasi komputasi untuk model landasan pelatihan. Jadi, jika Anda tertarik, silakan ikut serta!
Bergabunglah bersama kami dalam mengeksplorasi kemungkinan tak terbatas dari pembuatan beatmap berbasis AI dan membentuk masa depan permainan ritme!
Model tersedia di HuggingFace.
Beatmap permainan ritme pada awalnya diubah menjadi format file perantara, yang kemudian diberi token menjadi potongan-potongan 100 ms. Setiap token mampu mengkodekan hingga dua peristiwa berbeda dalam periode waktu ini (penangguhan dan/atau hit) yang dikuantisasi hingga akurasi 10 ms. Kosakata tokenizer telah dihitung sebelumnya dan bukan dipelajari dari data untuk memenuhi kriteria ini. Panjang konteks dan ukuran kosa kata sengaja dibuat kecil karena kurangnya contoh pelatihan berkualitas di lapangan.
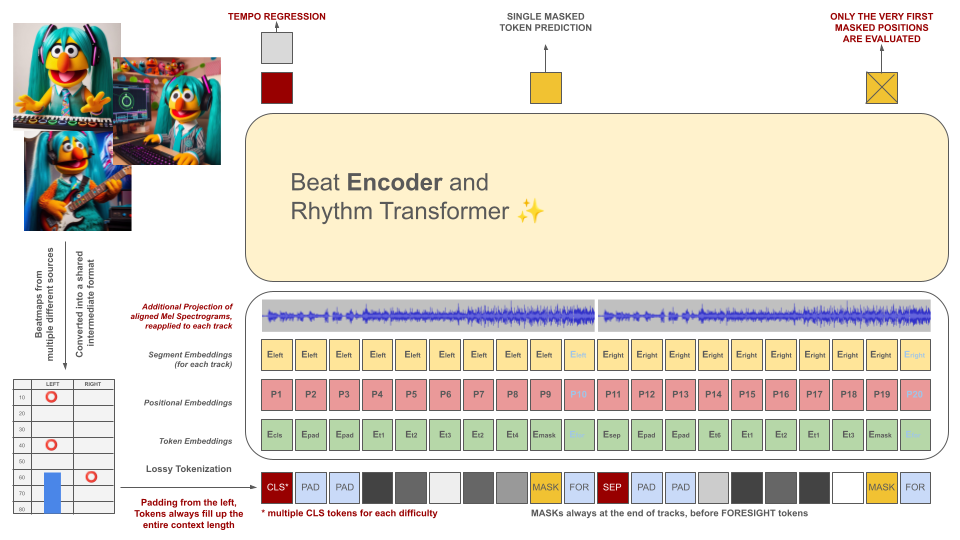 Token ini, bersama dengan potongan data audio (Spektogram Mel yang diproyeksikan selaras dengan token), berfungsi sebagai masukan untuk model pembuat enkode bertopeng. Mirip dengan BeRT, model encoder memiliki dua tujuan selama pelatihan: memperkirakan tempo melalui tugas regresi dan memprediksi token yang disamarkan (berikutnya) melalui fungsi gangguan pendengaran . Beatmap dengan 1, 2, dan 4 track didukung. Setiap token diprediksi dari kiri ke kanan, mencerminkan proses pembuatan arsitektur dekoder. Namun, token bertopeng juga memiliki akses ke informasi audio tambahan dari masa depan, yang ditandai sebagai token tinjauan ke masa depan dari kanan.
Token ini, bersama dengan potongan data audio (Spektogram Mel yang diproyeksikan selaras dengan token), berfungsi sebagai masukan untuk model pembuat enkode bertopeng. Mirip dengan BeRT, model encoder memiliki dua tujuan selama pelatihan: memperkirakan tempo melalui tugas regresi dan memprediksi token yang disamarkan (berikutnya) melalui fungsi gangguan pendengaran . Beatmap dengan 1, 2, dan 4 track didukung. Setiap token diprediksi dari kiri ke kanan, mencerminkan proses pembuatan arsitektur dekoder. Namun, token bertopeng juga memiliki akses ke informasi audio tambahan dari masa depan, yang ditandai sebagai token tinjauan ke masa depan dari kanan.
Tujuan model AI ini bukan untuk mendevaluasi beatmap yang dibuat secara individual, melainkan:
Semua konten yang dihasilkan harus mematuhi peraturan UE dan diberi label yang sesuai, termasuk metadata yang menunjukkan keterlibatan model AI.
PEMBUATAN BEATMAPS UNTUK MATERI YANG BERHAK CIPTA DILARANG KERAS! HANYA GUNAKAN LAGU YANG HAKNYA ANDA PUNYA!
Audio yang ditampilkan dalam contoh file OSU berasal dari artis yang terdaftar di situs web OSU pada bagian artis unggulan dan dilisensikan untuk digunakan secara khusus dalam konten terkait osu!.
Untuk mencegah beatmap Anda digunakan sebagai data pelatihan di masa mendatang, sertakan metadata berikut dalam file beatmap Anda:
robots: disallow
Proyek ini mengambil inspirasi dari upaya sebelumnya yang dikenal sebagai AIOSU.
Selain mengandalkan wiki OSU, osu-parser juga berperan penting dalam memperjelas deklarasi beatmap (terutama slider). Model transformator dipengaruhi oleh NanoGPT dan implementasi BerRT pytorch.


