GenerativeRL
v0.0.1
Bahasa Inggris | 简体中文 (Cina Sederhana)
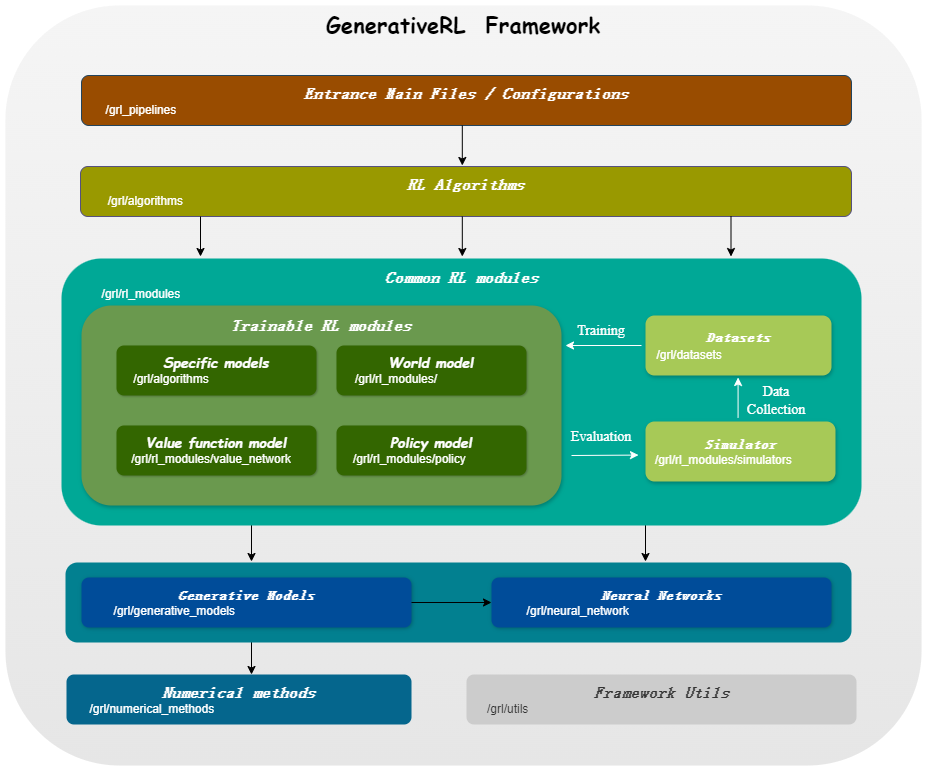
GenerativeRL , kependekan dari Generative Reinforcement Learning, adalah pustaka Python untuk memecahkan masalah pembelajaran penguatan (RL) menggunakan model generatif, seperti model difusi dan model aliran. Perpustakaan ini bertujuan untuk menyediakan kerangka kerja untuk menggabungkan kekuatan model generatif dengan kemampuan pengambilan keputusan dari algoritma pembelajaran penguatan.
| Pencocokan Skor | Pencocokan Aliran | |
|---|---|---|
| Model Difusi | ||
| Wakil Presiden SDE linier | ✔ | ✔ |
| Wakil Presiden SDE Umum | ✔ | ✔ |
| SDE linier | ✔ | ✔ |
| Model Aliran | ||
| Pencocokan Aliran Bersyarat Independen | ✔ | |
| Pencocokan Aliran Bersyarat Transportasi Optimal | ✔ |
| Algo./Model | Model Difusi | Model Aliran |
|---|---|---|
| IDQL | ✔ | |
| QGPO | ✔ | |
| SRPO | ✔ | |
| GPO | ✔ | ✔ |
| GMPG | ✔ | ✔ |
pip install GenerativeRLAtau, jika Anda ingin menginstal dari sumber:
git clone https://github.com/opendilab/GenerativeRL.git
cd GenerativeRL
pip install -e .Atau Anda dapat menggunakan gambar buruh pelabuhan:
docker pull opendilab/grl:torch2.3.0-cuda12.1-cudnn8-runtime
docker run -it --rm --gpus all opendilab/grl:torch2.3.0-cuda12.1-cudnn8-runtime /bin/bashBerikut adalah contoh cara melatih model difusi untuk pengoptimalan kebijakan yang dipandu Q (QGPO) di lingkungan LunarLanderContinuous-v2 menggunakan GenerativeRL.
Instal dependensi yang diperlukan:
pip install ' gym[box2d]==0.23.1 '(Versi gym bisa dari 0,23 hingga 0,25 untuk lingkungan box2d, tetapi disarankan untuk menggunakan 0.23.1 untuk kompatibilitas dengan D4RL.)
Unduh kumpulan data dari sini dan simpan sebagai data.npz di direktori saat ini.
GenerativeRL menggunakan WandB untuk pencatatan. Ini akan meminta Anda untuk masuk ke akun Anda saat Anda menggunakannya. Anda dapat menonaktifkannya dengan menjalankan:
wandb offline import gym
from grl . algorithms . qgpo import QGPOAlgorithm
from grl . datasets import QGPOCustomizedTensorDictDataset
from grl . utils . log import log
from grl_pipelines . diffusion_model . configurations . lunarlander_continuous_qgpo import config
def qgpo_pipeline ( config ):
qgpo = QGPOAlgorithm ( config , dataset = QGPOCustomizedTensorDictDataset ( numpy_data_path = "./data.npz" , action_augment_num = config . train . parameter . action_augment_num ))
qgpo . train ()
agent = qgpo . deploy ()
env = gym . make ( config . deploy . env . env_id )
observation = env . reset ()
for _ in range ( config . deploy . num_deploy_steps ):
env . render ()
observation , reward , done , _ = env . step ( agent . act ( observation ))
if __name__ == '__main__' :
log . info ( "config: n {}" . format ( config ))
qgpo_pipeline ( config )Untuk contoh dan dokumentasi lebih detail, silakan merujuk ke dokumentasi GenerativeRL.
Dokumentasi lengkap untuk GenerativeRL dapat ditemukan di Dokumentasi GenerativeRL.
Kami menyediakan beberapa tutorial kasus untuk membantu Anda lebih memahami GenerativeRL. Lihat selengkapnya di tutorial.
Kami menawarkan beberapa eksperimen dasar untuk mengevaluasi kinerja algoritma pembelajaran penguatan generatif. Lihat selengkapnya di benchmark.
Kami menyambut kontribusi ke GenerativeRL! Jika Anda tertarik untuk berkontribusi, silakan lihat Panduan Berkontribusi.
@misc{generative_rl,
title={GenerativeRL: A Python Library for Solving Reinforcement Learning Problems Using Generative Models},
author={Zhang, Jinouwen and Xue, Rongkun and Niu, Yazhe and Chen, Yun and Chen, Xinyan and Wang, Ruiheng and Liu, Yu},
publisher={GitHub},
howpublished={ url {https://github.com/opendilab/GenerativeRL}},
year={2024},
}GenerativeRL dilisensikan di bawah Lisensi Apache 2.0. Lihat LISENSI untuk lebih jelasnya.


