BinaryVectorDB
1.0.0
Repositori ini berisi Database Vektor Biner untuk pencarian efisien pada kumpulan data besar, yang ditujukan untuk tujuan pendidikan.
Kebanyakan model penyematan mewakili vektornya sebagai float32: Ini menghabiskan banyak memori dan pencariannya sangat lambat. Di Cohere, kami memperkenalkan model penyematan pertama dengan int8 asli dan dukungan biner, yang memberi Anda kualitas penelusuran luar biasa dengan biaya yang lebih murah:
| Model | MIRACL Kualitas Pencarian | Saatnya Mencari 1 Juta dokumen | Memori Dibutuhkan 250 Juta Penyematan Wikipedia | Harga di AWS (contoh x2gb) |
|---|---|---|---|---|
| Penyematan teks OpenAI-3-kecil | 44.9 | 680 ms | 1431GB | $65.231 / tahun |
| Penyematan teks OpenAI-3-besar | 54.9 | 1240 mdtk | 2861GB | $130,463 / tahun |
| Cohere Sematkan v3 (Multibahasa) | ||||
| Sematkan v3 - float32 | 66.3 | 460 ms | 954 GB | $43.488 / tahun |
| Sematkan v3 - biner | 62.8 | 24 ms | 30 GB | $1.359 / tahun |
| Sematkan v3 - skor ulang biner + int8 | 66.3 | 28 ms | Memori 30 GB + disk 240 GB | $1.589 / tahun |
Kami membuat demo yang memungkinkan Anda mencari di 100 juta Wikipedia Embeddings untuk VM yang harganya hanya $15/bulan: Demo - Cari di 100 juta Wikipedia Embeddings hanya dengan $15/bln
Anda dapat dengan mudah menggunakan BinaryVectorDB pada data Anda sendiri.
Pengaturannya mudah:
pip install BinaryVectorDB
Untuk menggunakan beberapa contoh di bawah ini, Anda memerlukan kunci API Cohere (gratis atau berbayar) dari cohere.com. Anda harus menyetel kunci API ini sebagai variabel lingkungan: export COHERE_API_KEY=your_api_key
Nanti kami akan menunjukkan cara membuat DB vektor pada data Anda sendiri. Untuk memulainya, mari kita gunakan database vektor biner yang sudah dibuat sebelumnya . Kami meng-host berbagai database pra-pembuatan di https://huggingface.co/datasets/Cohere/BinaryVectorDB. Anda dapat mengunduhnya dan menggunakannya secara lokal.
Mari kita lihat versi bahasa Inggris sederhana dari Wikipedia untuk memulai:
wget https://huggingface.co/datasets/Cohere/BinaryVectorDB/resolve/main/wikipedia-2023-11-simple.zip
Dan kemudian unzip file ini:
unzip wikipedia-2023-11-simple.zip
Anda dapat memuat database dengan mudah dengan mengarahkannya ke folder yang tidak di-zip dari langkah sebelumnya:
from BinaryVectorDB import BinaryVectorDB
# Point it to the unzipped folder from the previous step
# Ensure that you have set your Cohere API key via: export COHERE_API_KEY=<<YOUR_KEY>>
db = BinaryVectorDB ( "wikipedia-2023-11-simple/" )
query = "Who is the founder of Facebook"
print ( "Query:" , query )
hits = db . search ( query )
for hit in hits [ 0 : 3 ]:
print ( hit )Basis datanya memiliki 646.424 penyematan dan ukuran total 962 MB. Namun, hanya 80 MB untuk penyematan biner yang dimuat di memori. Dokumen dan penyematannya di int8 disimpan di disk dan hanya dimuat saat diperlukan.
Pemisahan penyematan biner di memori dan penyematan int8 & dokumen di disk memungkinkan kami menskalakan ke kumpulan data yang sangat besar tanpa memerlukan banyak memori.
Sangat mudah untuk membangun Database Vektor Biner Anda sendiri.
from BinaryVectorDB import BinaryVectorDB
import os
import gzip
import json
simplewiki_file = "simple-wikipedia-example.jsonl.gz"
#If file not exist, download
if not os . path . exists ( simplewiki_file ):
cmd = f"wget https://huggingface.co/datasets/Cohere/BinaryVectorDB/resolve/main/simple-wikipedia-example.jsonl.gz"
os . system ( cmd )
# Create the vector DB with an empty folder
# Ensure that you have set your Cohere API key via: export COHERE_API_KEY=<<YOUR_KEY>>
db_folder = "path_to_an_empty_folder/"
db = BinaryVectorDB ( db_folder )
if len ( db ) > 0 :
exit ( f"The database { db_folder } is not empty. Please provide an empty folder to create a new database." )
# Read all docs from the jsonl.gz file
docs = []
with gzip . open ( simplewiki_file ) as fIn :
for line in fIn :
docs . append ( json . loads ( line ))
#Limit it to 10k docs to make the next step a bit faster
docs = docs [ 0 : 10_000 ]
# Add all documents to the DB
# docs2text defines a function that maps our documents to a string
# This string is then embedded with the state-of-the-art Cohere embedding model
db . add_documents ( doc_ids = list ( range ( len ( docs ))), docs = docs , docs2text = lambda doc : doc [ 'title' ] + " " + doc [ 'text' ]) Dokumen tersebut dapat berupa objek apa pun yang dapat diserialkan dengan Python. Anda perlu menyediakan fungsi untuk docs2text yang memetakan dokumen Anda ke sebuah string. Dalam contoh di atas, kami menggabungkan judul dan kolom teks. String ini dikirim ke model penyematan untuk menghasilkan penyematan teks yang diperlukan.
Menambah/menghapus/memperbarui dokumen itu mudah. Lihat contoh/add_update_delete.py untuk contoh skrip cara menambah/memperbarui/menghapus dokumen dalam database.
Kami mengumumkan penyematan Cohere int8 & biner Embeddings kami, yang menawarkan pengurangan 4x dan 32x dalam memori yang dibutuhkan. Lebih jauh lagi, ini memberikan kecepatan hingga 40x dalam pencarian vektor.
Kedua teknik tersebut digabungkan dalam BinaryVectorDB. Sebagai contoh, mari kita asumsikan Wikipedia bahasa Inggris dengan 42 juta embeddings. Penyematan float32 normal memerlukan memori 42*10^6*1024*4 = 160 GB untuk sekadar menghosting penyematan. Karena pencarian di float32 agak lambat (sekitar 45 detik pada 42 juta embeddings), kita perlu menambahkan indeks seperti HNSW, yang menambah memori 20 GB lagi, jadi Anda memerlukan total 180 GB.
Penyematan biner mewakili setiap dimensi sebagai 1 bit. Hal ini mengurangi kebutuhan memori menjadi 160 GB / 32 = 5GB . Selain itu, karena penelusuran dalam ruang biner 40x lebih cepat, Anda tidak lagi memerlukan indeks HNSW dalam banyak kasus. Anda mengurangi kebutuhan memori dari 180 GB menjadi 5 GB, penghematan 36x yang menyenangkan.
Saat kami menanyakan indeks ini, kami juga mengkodekan kueri dalam biner dan menggunakan jarak hamming. Jarak Hamming mengukur perbedaan 1-bit antara 2 vektor. Ini adalah operasi yang sangat cepat: Untuk membandingkan dua vektor biner, Anda hanya memerlukan 2 siklus CPU: popcount(xor(vector1, vector2)) . XOR adalah operasi paling mendasar pada CPU, oleh karena itu ia berjalan sangat cepat. popcount menghitung angka 1 di register, yang juga hanya membutuhkan 1 siklus CPU.
Secara keseluruhan, ini memberi kami solusi yang mempertahankan sekitar 90% kualitas penelusuran.
Kita dapat meningkatkan kualitas pencarian dari langkah sebelumnya dari 90% menjadi 95% dengan penilaian ulang <float, binary> .
Misalnya, kami mengambil 100 hasil teratas dari langkah 1, dan menghitung dot_product(query_float_embedding, 2*binary_doc_embedding-1) .
Asumsikan penyematan kueri kita adalah [0.1, -0.3, 0.4] dan penyematan dokumen biner kita adalah [1, 0, 1] . Langkah ini kemudian menghitung:
(0.1)*(1) + (-0.3)*(-1) + 0.4*(1) = 0.1 + 0.3 + 0.4 = 0.8

Kami menggunakan skor ini dan menilai ulang hasil kami. Ini mendorong kualitas pencarian dari 90% menjadi 95%. Operasi ini dapat dilakukan dengan sangat cepat: Kita mendapatkan penyematan float kueri dari model penyematan, penyematan biner ada di memori, jadi kita hanya perlu melakukan 100 operasi penjumlahan.
Untuk lebih meningkatkan kualitas pencarian, dari 95% menjadi 99,99%, kami menggunakan penilaian ulang int8 dari disk.
Kami menyimpan semua penyematan dokumen int8 di disk. Kami kemudian mengambil 30 teratas dari langkah di atas, memuat int8-embeddings dari disk, dan menghitung cossim(query_float_embedding, int8_doc_embedding_from_disk)
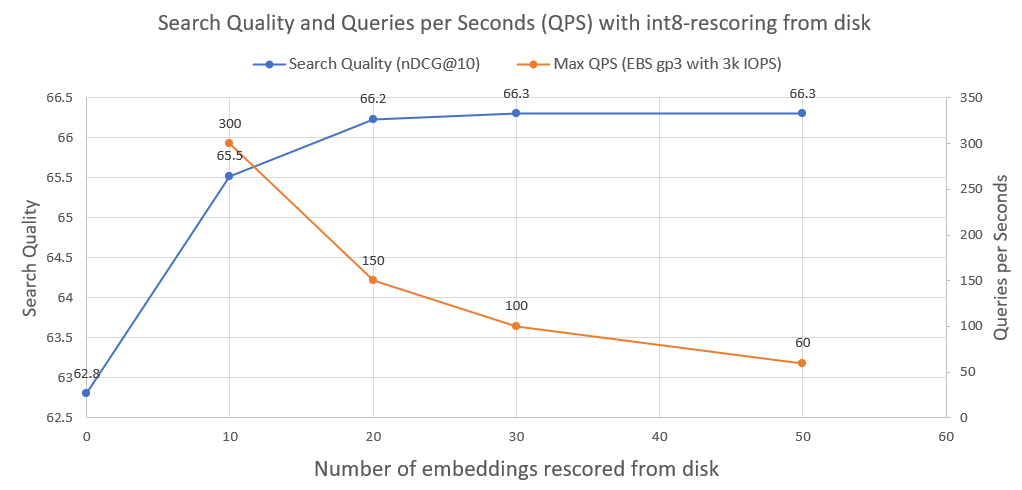
Pada gambar berikut Anda dapat melihat seberapa banyak int8-rescoring dan meningkatkan kinerja pencarian:
Kami juga merencanakan Kueri per Detik yang dapat dicapai sistem tersebut ketika dijalankan pada drive jaringan AWS EBS normal dengan 3000 IOPS. Seperti yang bisa kita lihat, semakin banyak embeddings int8 yang perlu kita muat dari disk, semakin sedikit QPS.
Untuk melakukan pencarian biner, kami menggunakan indeks IndexBinaryFlat dari faiss. Itu hanya menyimpan penyematan biner, memungkinkan pengindeksan super cepat dan pencarian super cepat.
Untuk menyimpan dokumen dan penyematan int8, kami menggunakan RocksDict, penyimpanan nilai kunci pada disk untuk Python berdasarkan RocksDB.
Lihat BinaryVectorDB untuk implementasi penuh kelas tersebut.
Tidak terlalu. Repositori ini sebagian besar dimaksudkan untuk tujuan pendidikan untuk menunjukkan teknik bagaimana menskalakan ke kumpulan data yang besar. Fokusnya lebih pada kemudahan penggunaan dan beberapa aspek penting tidak ada dalam implementasi, seperti keamanan multi-proses, rollback, dll.
Jika Anda benar-benar ingin memulai produksi, gunakan database vektor yang tepat seperti Vespa.ai, yang memungkinkan Anda mencapai hasil serupa.
Di Cohere kami membantu pelanggan menjalankan Pencarian Semantik pada puluhan miliar embeddings, dengan biaya yang lebih murah. Jangan ragu untuk menghubungi Nils Reimers jika Anda membutuhkan solusi yang berskala.


