VideoX
1.0.0
Ini adalah kumpulan video karya pemahaman kami
SeqTrack (
@CVPR'23): SeqTrack: Pembelajaran Urutan ke Urutan untuk Pelacakan Objek Visual
X-CLIP (
@ECCV'22 Oral): Memperluas Model Bahasa-Gambar yang Telah Dilatih untuk Pengenalan Video Umum
MS-2D-TAN (
@TPAMI'21): Jaringan Berdekatan Temporal 2D Multi-Skala untuk Lokalisasi Momen dengan Bahasa Alami
2D-TAN (
@AAAI'20): Mempelajari Jaringan Berdekatan Temporal 2D untuk Lokalisasi Momen dengan Bahasa Alami
Mempekerjakan peneliti magang dengan keterampilan pengkodean yang kuat: [email protected] | [email protected]
April 2023: Kode untuk SeqTrack kini dirilis.
Februari 2023: SeqTrack diterima di CVPR'23
Sep, 2022: X-CLIP kini terintegrasi
Agustus 2022: Kode untuk X-CLIP kini dirilis.
Juli 2022: X-CLIP diterima di ECCV'22 sebagai Lisan
Okt 2021: Kode untuk MS-2D-TAN kini dirilis.
Sep 2021: MS-2D-TAN diterima di TPAMI'21
Des, 2019: Kode untuk 2D-TAN kini dirilis.
Nov, 2019: 2D-TAN diterima di AAAI'20
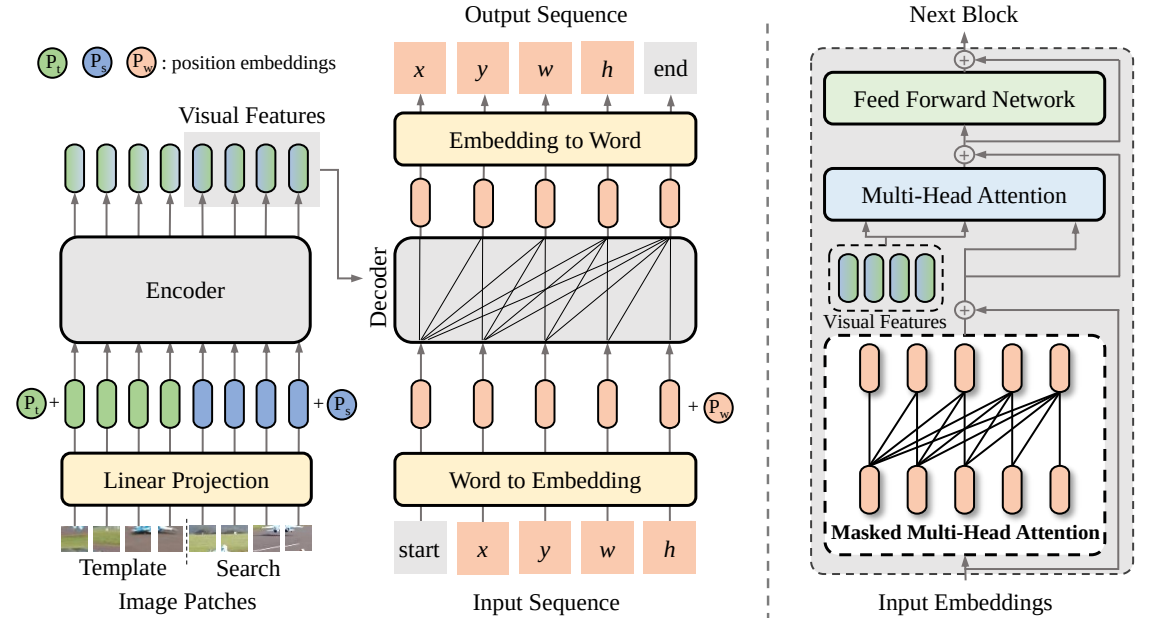
Dalam makalah ini, kami mengusulkan kerangka pembelajaran urutan-ke-urutan baru untuk pelacakan visual, yang disebut SeqTrack. Ini menjadikan pelacakan visual sebagai masalah pembuatan urutan, yang memprediksi kotak pembatas objek secara autoregresif. SeqTrack hanya mengadopsi arsitektur transformator encoder-decoder sederhana. Encoder mengekstrak fitur visual dengan transformator dua arah, sedangkan decoder menghasilkan urutan nilai kotak pembatas secara otomatis dengan decoder kausal. Fungsi kerugian adalah entropi silang biasa. Paradigma pembelajaran berurutan seperti itu tidak hanya menyederhanakan kerangka pelacakan, namun juga mencapai kinerja kompetitif pada banyak tolok ukur.
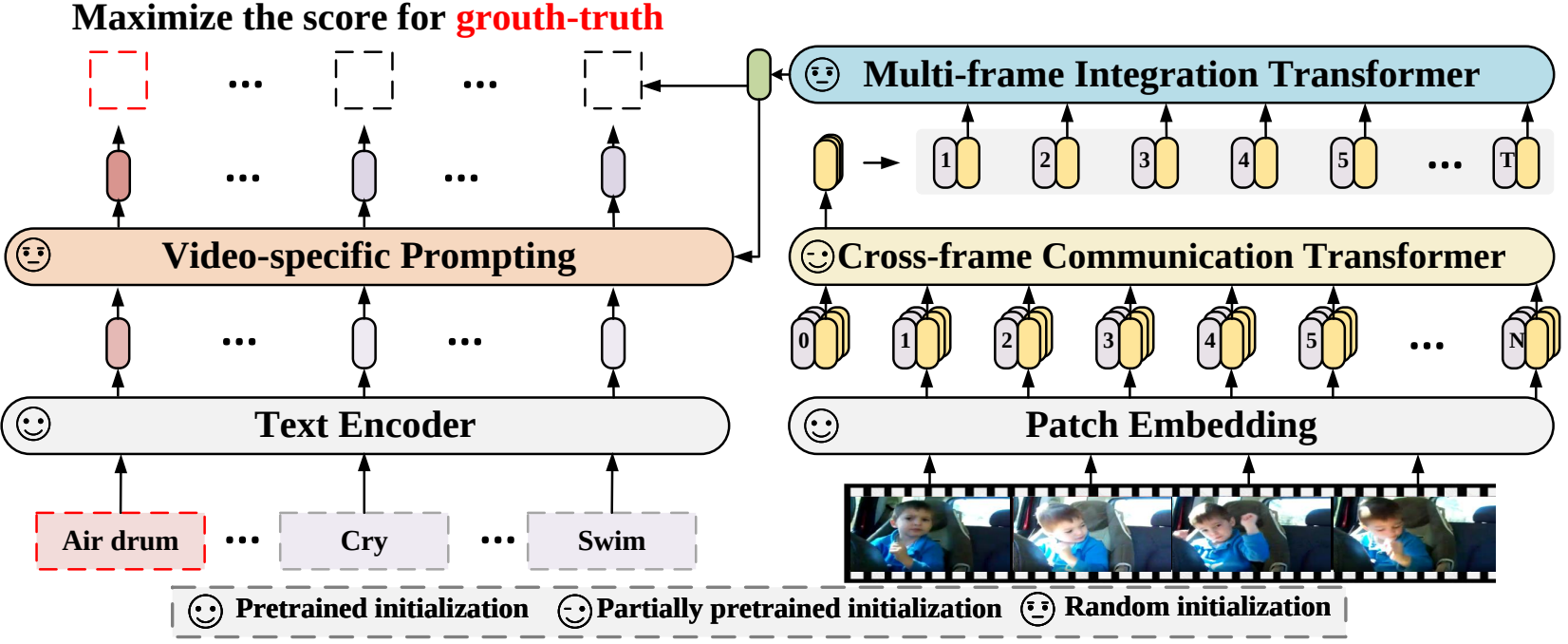
Dalam makalah ini, kami mengusulkan kerangka pengenalan video baru yang mengadaptasi model bahasa-gambar yang telah dilatih sebelumnya ke pengenalan video. Secara khusus, untuk menangkap informasi temporal, kami mengusulkan mekanisme perhatian lintas bingkai yang secara eksplisit menukar informasi antar bingkai. Untuk memanfaatkan informasi teks dalam kategori video, kami merancang teknik dorongan khusus video yang dapat menghasilkan representasi teks diskriminatif tingkat contoh. Eksperimen ekstensif menunjukkan bahwa pendekatan kami efektif dan dapat digeneralisasikan ke berbagai skenario pengenalan video, termasuk pengawasan penuh, pengambilan gambar sedikit, dan pengambilan gambar tanpa gambar.
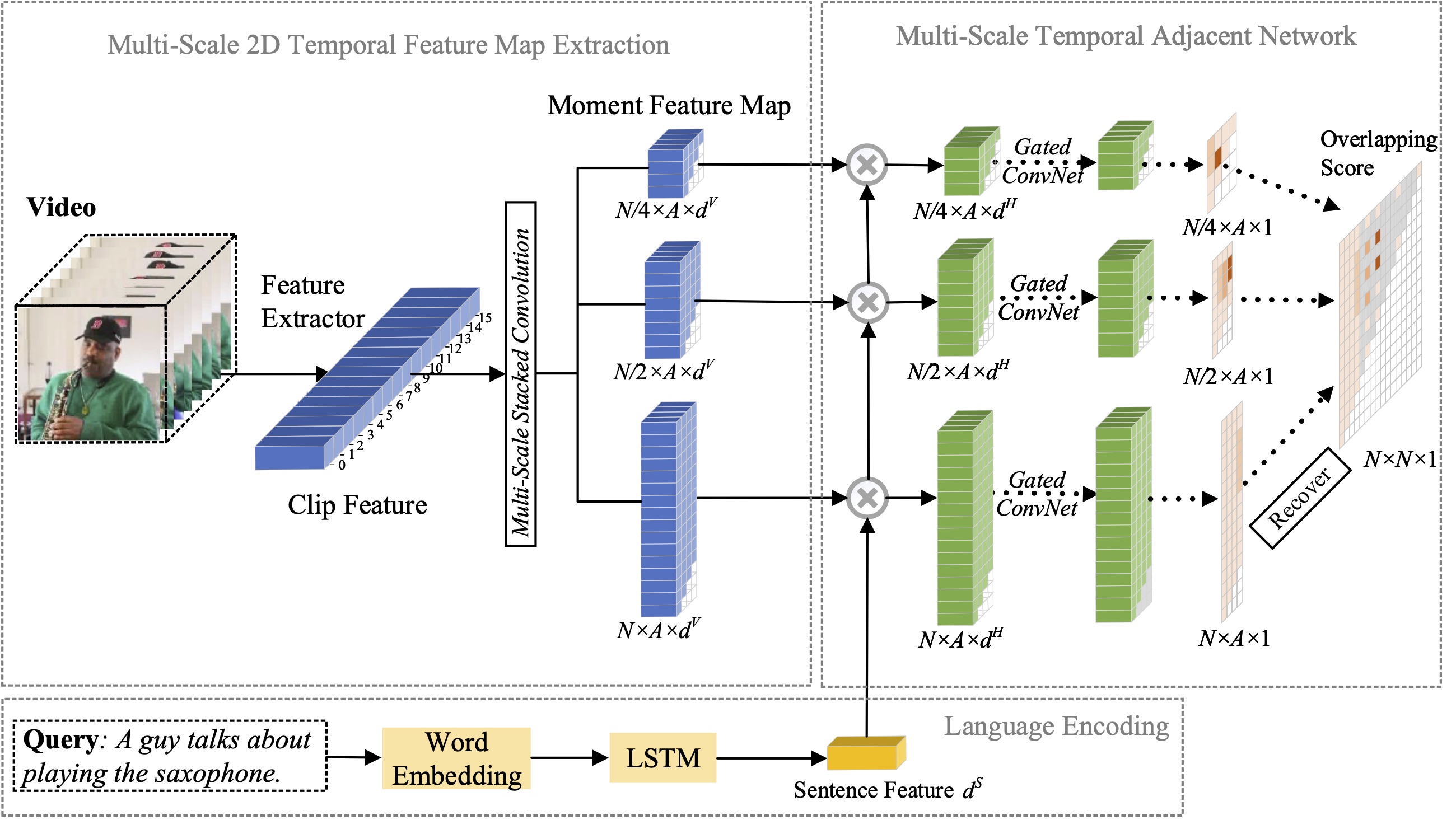
Dalam makalah ini, kami mempelajari masalah lokalisasi momen dengan bahasa alami, dan mengusulkan perluasan metode 2D-TAN yang kami usulkan sebelumnya ke versi multi-skala. Ide intinya adalah untuk mengambil momen dari peta temporal dua dimensi pada skala temporal yang berbeda, yang mempertimbangkan kandidat momen yang berdekatan sebagai konteks temporal. Versi yang diperluas mampu mengkodekan hubungan temporal yang berdekatan pada skala yang berbeda, sambil mempelajari fitur diskriminatif untuk mencocokkan momen video dengan ekspresi rujukan. Model kami sederhana dalam desain dan mencapai kinerja kompetitif dibandingkan dengan metode canggih pada tiga kumpulan data benchmark.
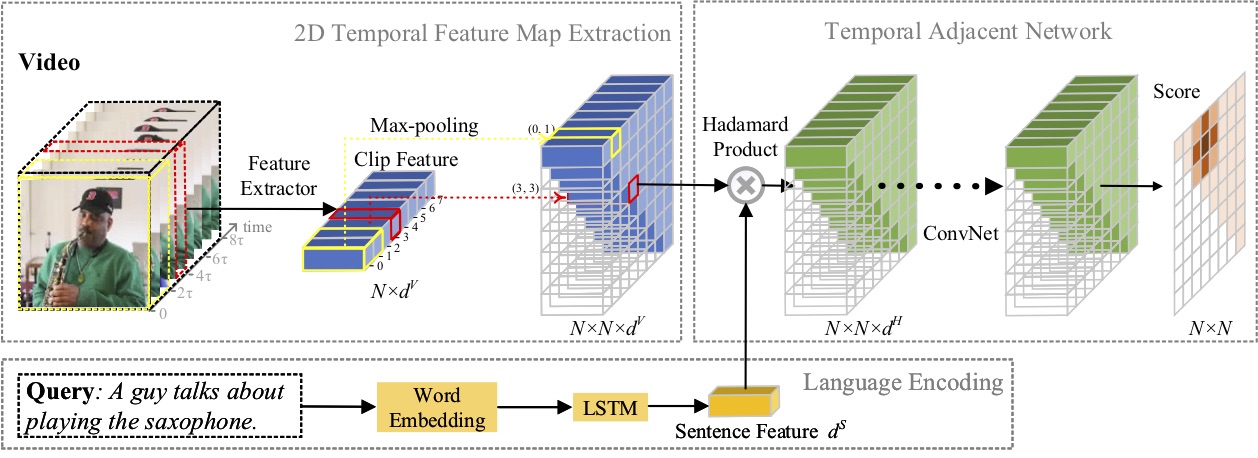
Dalam makalah ini, kami mempelajari masalah lokalisasi momen dengan bahasa alami, dan mengusulkan metode 2D Temporal Adjacent Networks (2D-TAN) yang baru. Ide intinya adalah mengambil momen pada peta temporal dua dimensi, yang mempertimbangkan kandidat momen yang berdekatan sebagai konteks temporal. 2D-TAN mampu menyandikan hubungan temporal yang berdekatan, sambil mempelajari fitur diskriminatif untuk mencocokkan momen video dengan ekspresi rujukan. Model kami sederhana dalam desain dan mencapai kinerja kompetitif dibandingkan dengan metode canggih pada tiga kumpulan data benchmark.
@InProceedings{SeqTrack, title={SeqTrack: Pembelajaran Urutan ke Urutan untuk Pelacakan Objek Visual}, author={Chen, Xin dan Peng, Houwen dan Wang, Dong dan Lu, Huchuan dan Hu, Han}, booktitle={CVPR}, year={2023}}@InProceedings{XCLIP, title={Memperluas Model Terlatih Bahasa-Gambar untuk Pengenalan Video Umum}, author={Ni, Bolin dan Peng, Houwen dan Chen, Minghao dan Zhang, Songyang dan Meng, Gaofeng dan Fu, Jianlong dan Xiang, Shiming dan Ling, Haibin}, booktitle={Konferensi Eropa tentang Computer Vision (ECCV)}, tahun ={2022}}@DalamProsiding{Zhang2021MS2DTAN,
penulis = {Zhang, Songyang dan Peng, Houwen dan Fu, Jianlong dan Lu, Yijuan dan Luo, Jiebo},
title = {Jaringan Berdekatan Temporal 2D Multi-Skala untuk Lokalisasi Momen dengan Bahasa Alami},
judul buku = {TPAMI},
tahun = {2021}}@InProceedings{2DTAN_2020_AAAI,
penulis = {Zhang, Songyang dan Peng, Houwen dan Fu, Jianlong dan Luo, Jiebo},
title = {Mempelajari Jaringan Berdekatan Temporal 2D untuk Lokalisasi Momen dengan Bahasa Alami},
judul buku = {AAAI},
tahun = {2020}}Lisensi di bawah lisensi MIT.


