open_llama
1.0.0
TL;DR : kami merilis pratinjau publik OpenLLaMA, reproduksi open source berlisensi permisif dari LLaMA Meta AI. Kami merilis serangkaian model 3B, 7B, dan 13B yang dilatih pada campuran data yang berbeda. Bobot model kami dapat berfungsi sebagai pengganti LLaMA dalam implementasi yang ada.
Dalam repo ini, kami menyajikan reproduksi open source berlisensi permisif dari model bahasa besar LLaMA Meta AI. Kami merilis serangkaian model 3B, 7B, dan 13B yang dilatih pada token 1T. Kami menyediakan bobot PyTorch dan JAX dari model OpenLLaMA terlatih, serta hasil evaluasi dan perbandingan terhadap model LLaMA asli. Model v2 lebih baik dibandingkan model v1 lama yang dilatih pada campuran data yang berbeda.
Kami merilis model OpenLLaMA 3Bv3, yang merupakan model 3B yang dilatih untuk token 1T pada campuran kumpulan data yang sama dengan model 7Bv2.
Kami dengan senang hati merilis model OpenLLaMA 7Bv2, yang dilatih pada campuran kumpulan data web Falcon yang disempurnakan, dicampur dengan kumpulan data starcoder, dan wikipedia, arxiv, buku, dan pertukaran tumpukan dari RedPajama.
Kami dengan senang hati merilis versi token 1T terakhir dari OpenLLaMA 13B. Kami telah memperbarui hasil evaluasi. Untuk model OpenLLaMA versi saat ini, tokenizer kami dilatih untuk menggabungkan beberapa ruang kosong menjadi satu sebelum tokenisasi, mirip dengan tokenizer T5. Oleh karena itu, tokenizer kami tidak akan berfungsi dengan tugas pembuatan kode (misalnya HumanEval) karena kode melibatkan banyak ruang kosong. Untuk tugas terkait kode, silakan gunakan model v2.
Kami dengan senang hati merilis versi token 1T terakhir kami dari OpenLLaMA 3B dan 7B. Kami telah memperbarui hasil evaluasi. Kami juga dengan senang hati merilis pratinjau token 600 miliar dari model 13B, yang dilatih melalui kolaborasi dengan Stability AI.
Kami dengan senang hati merilis pos pemeriksaan token 700 miliar untuk model OpenLLaMA 7B dan pos pemeriksaan token 600 miliar untuk model 3B. Kami juga telah memperbarui hasil evaluasi. Kami memperkirakan pelatihan token 1T penuh akan selesai pada akhir minggu ini.
Setelah menerima umpan balik dari komunitas, kami menemukan bahwa tokenizer dari rilis pos pemeriksaan kami sebelumnya tidak dikonfigurasi dengan benar sehingga baris baru tidak dipertahankan. Untuk memperbaiki masalah ini, kami telah melatih ulang tokenizer dan memulai kembali pelatihan model. Kami juga mengamati kerugian pelatihan yang lebih rendah dengan tokenizer baru ini.
Kami merilis bobot dalam dua format: format EasyLM untuk digunakan dengan kerangka kerja EasyLM kami, dan format PyTorch untuk digunakan dengan pustaka transformator Hugging Face. Kerangka kerja pelatihan kami EasyLM dan bobot pos pemeriksaan dilisensikan secara permisif di bawah lisensi Apache 2.0.
Pos pemeriksaan pratinjau dapat langsung dimuat dari Hugging Face Hub. Harap dicatat bahwa disarankan untuk menghindari penggunaan tokenizer cepat Hugging Face untuk saat ini, karena kami telah mengamati bahwa tokenizer cepat yang dikonversi secara otomatis terkadang memberikan tokenisasi yang salah . Hal ini dapat dicapai dengan menggunakan kelas LlamaTokenizer secara langsung, atau meneruskan opsi use_fast=False untuk kelas AutoTokenizer . Lihat contoh penggunaan berikut.
import torch
from transformers import LlamaTokenizer , LlamaForCausalLM
## v2 models
model_path = 'openlm-research/open_llama_3b_v2'
# model_path = 'openlm-research/open_llama_7b_v2'
## v1 models
# model_path = 'openlm-research/open_llama_3b'
# model_path = 'openlm-research/open_llama_7b'
# model_path = 'openlm-research/open_llama_13b'
tokenizer = LlamaTokenizer . from_pretrained ( model_path )
model = LlamaForCausalLM . from_pretrained (
model_path , torch_dtype = torch . float16 , device_map = 'auto' ,
)
prompt = 'Q: What is the largest animal? n A:'
input_ids = tokenizer ( prompt , return_tensors = "pt" ). input_ids
generation_output = model . generate (
input_ids = input_ids , max_new_tokens = 32
)
print ( tokenizer . decode ( generation_output [ 0 ]))Untuk penggunaan lebih lanjut, silakan ikuti dokumentasi transformator LLaMA.
Model dapat dievaluasi dengan lm-eval-harness. Namun, karena masalah tokenizer yang disebutkan di atas, kita perlu menghindari penggunaan tokenizer cepat untuk mendapatkan hasil yang benar. Hal ini dapat dicapai dengan meneruskan use_fast=False ke bagian lm-eval-harness ini, seperti yang ditunjukkan pada contoh di bawah ini:
tokenizer = self . AUTO_TOKENIZER_CLASS . from_pretrained (
pretrained if tokenizer is None else tokenizer ,
revision = revision + ( "/" + subfolder if subfolder is not None else "" ),
use_fast = False
)Untuk menggunakan bobot dalam kerangka EasyLM kami, silakan merujuk ke dokumentasi LLaMA EasyLM. Perhatikan bahwa tidak seperti model LLaMA asli, tokenizer dan bobot OpenLLaMA kami dilatih sepenuhnya dari awal sehingga tidak diperlukan lagi untuk mendapatkan tokenizer dan bobot LLaMA asli.
Model v1 dilatih pada dataset RedPajama. Model v2 dilatih pada campuran kumpulan data web halus Falcon, kumpulan data StarCoder, dan bagian wikipedia, arxiv, book, dan stackexchange dari kumpulan data RedPajama. Kami mengikuti langkah-langkah pra-pemrosesan dan hyperparameter pelatihan yang sama persis seperti makalah LLaMA asli, termasuk arsitektur model, panjang konteks, langkah-langkah pelatihan, jadwal kecepatan pembelajaran, dan pengoptimal. Satu-satunya perbedaan antara pengaturan kami dan yang asli adalah kumpulan data yang digunakan: OpenLLaMA menggunakan kumpulan data terbuka, bukan yang digunakan oleh LLaMA asli.
Kami melatih model di cloud TPU-v4 menggunakan EasyLM, pipeline pelatihan berbasis JAX yang kami kembangkan untuk pelatihan dan menyempurnakan model bahasa besar. Kami menggunakan kombinasi paralelisme data normal dan paralelisme data sharded penuh (juga dikenal sebagai ZeRO tahap 3) untuk menyeimbangkan throughput pelatihan dan penggunaan memori. Secara keseluruhan kami mencapai throughput lebih dari 2200 token/detik/chip TPU-v4 untuk model 7B kami. Training loss dapat dilihat pada gambar di bawah ini.
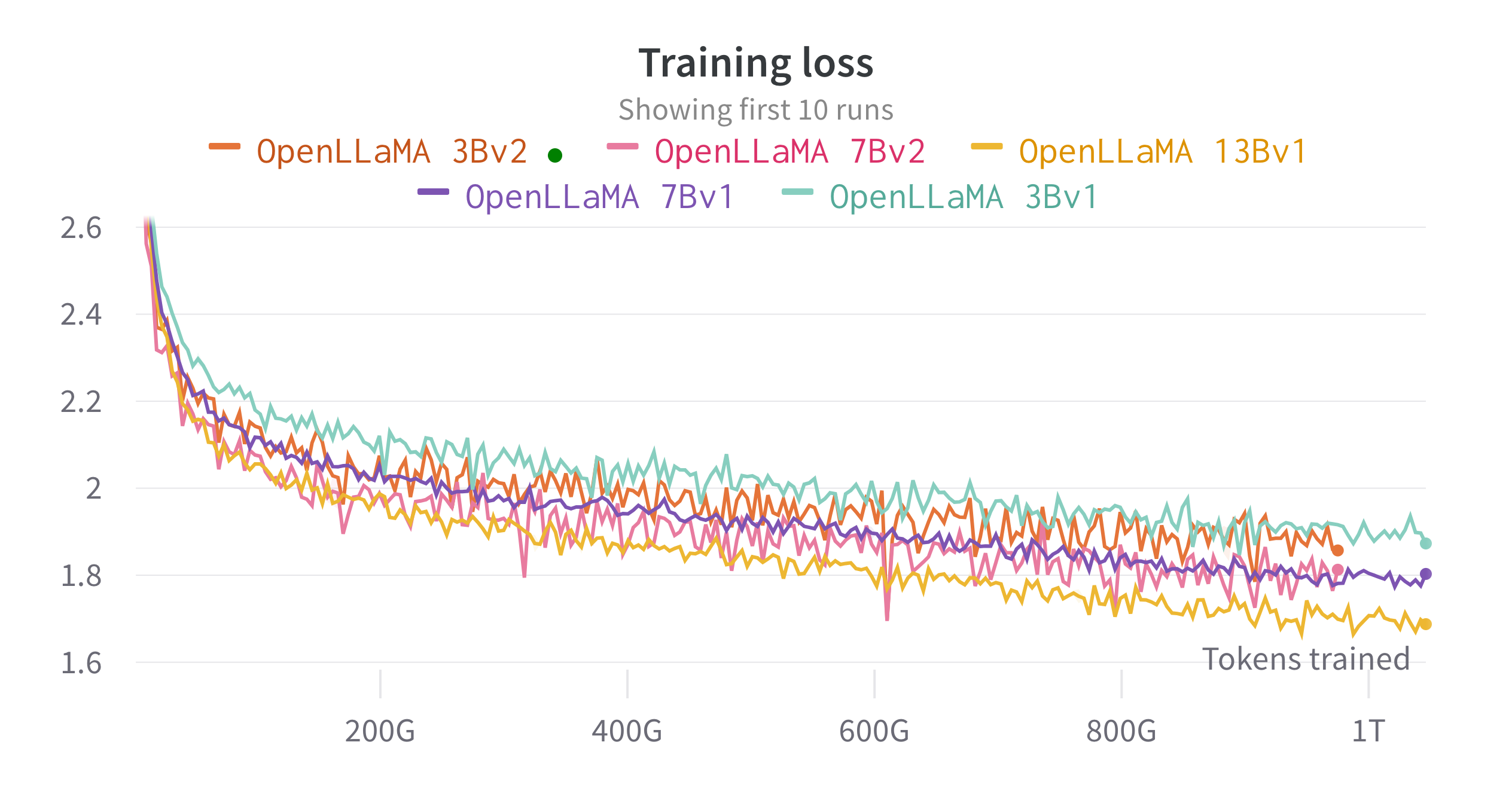
Kami mengevaluasi OpenLLaMA pada berbagai tugas menggunakan lm-evaluation-harness. Hasil LLaMA dihasilkan dengan menjalankan model LLaMA asli pada metrik evaluasi yang sama. Kami mencatat bahwa hasil kami untuk model LLaMA sedikit berbeda dari makalah LLaMA asli, yang kami yakini merupakan hasil dari protokol evaluasi yang berbeda. Perbedaan serupa telah dilaporkan dalam edisi lm-evaluation-harness ini. Selain itu, kami menyajikan hasil GPT-J, model parameter 6B yang dilatih pada kumpulan data Pile oleh EleutherAI.
Model LLaMA asli dilatih untuk 1 triliun token dan GPT-J dilatih untuk 500 miliar token. Hasilnya kami sajikan pada tabel di bawah ini. OpenLLaMA menunjukkan kinerja yang sebanding dengan LLaMA dan GPT-J asli di sebagian besar tugas, dan mengungguli mereka dalam beberapa tugas.
| Tugas/Metrik | GPT-J 6B | LLaMA 7B | LLaMA 13B | BukaLLaMA 3Bv2 | BukaLLaMA 7Bv2 | BukaLLaMA 3B | BukaLLaMA 7B | BukaLLaMA 13B |
|---|---|---|---|---|---|---|---|---|
| anli_r1/acc | 0,32 | 0,35 | 0,35 | 0,33 | 0,34 | 0,33 | 0,33 | 0,33 |
| anli_r2/acc | 0,34 | 0,34 | 0,36 | 0,36 | 0,35 | 0,32 | 0,36 | 0,33 |
| anli_r3/acc | 0,35 | 0,37 | 0,39 | 0,38 | 0,39 | 0,35 | 0,38 | 0,40 |
| arc_challenge/acc | 0,34 | 0,39 | 0,44 | 0,34 | 0,39 | 0,34 | 0,37 | 0,41 |
| arc_challenge/acc_norm | 0,37 | 0,41 | 0,44 | 0,36 | 0,41 | 0,37 | 0,38 | 0,44 |
| arc_easy/acc | 0,67 | 0,68 | 0,75 | 0,68 | 0,73 | 0,69 | 0,72 | 0,75 |
| arc_easy/acc_norm | 0,62 | 0,52 | 0,59 | 0,63 | 0,70 | 0,65 | 0,68 | 0,70 |
| boolq/acc | 0,66 | 0,75 | 0,71 | 0,66 | 0,72 | 0,68 | 0,71 | 0,75 |
| hellaswag/acc | 0,50 | 0,56 | 0,59 | 0,52 | 0,56 | 0,49 | 0,53 | 0,56 |
| hellaswag/acc_norm | 0,66 | 0,73 | 0,76 | 0,70 | 0,75 | 0,67 | 0,72 | 0,76 |
| openbookqa/acc | 0,29 | 0,29 | 0,31 | 0,26 | 0,30 | 0,27 | 0,30 | 0,31 |
| openbookqa/acc_norm | 0,38 | 0,41 | 0,42 | 0,38 | 0,41 | 0,40 | 0,40 | 0,43 |
| piqa / acc | 0,75 | 0,78 | 0,79 | 0,77 | 0,79 | 0,75 | 0,76 | 0,77 |
| piqa/acc_norm | 0,76 | 0,78 | 0,79 | 0,78 | 0,80 | 0,76 | 0,77 | 0,79 |
| rekam/em | 0,88 | 0,91 | 0,92 | 0,87 | 0,89 | 0,88 | 0,89 | 0,91 |
| catatan/f1 | 0,89 | 0,91 | 0,92 | 0,88 | 0,89 | 0,89 | 0,90 | 0,91 |
| rte / acc | 0,54 | 0,56 | 0,69 | 0,55 | 0,57 | 0,58 | 0,60 | 0,64 |
| jujurqa_mc/mc1 | 0,20 | 0,21 | 0,25 | 0,22 | 0,23 | 0,22 | 0,23 | 0,25 |
| jujurqa_mc/mc2 | 0,36 | 0,34 | 0,40 | 0,35 | 0,35 | 0,35 | 0,35 | 0,38 |
| wic/acc | 0,50 | 0,50 | 0,50 | 0,50 | 0,50 | 0,48 | 0,51 | 0,47 |
| winogrande/menurut | 0,64 | 0,68 | 0,70 | 0,63 | 0,66 | 0,62 | 0,67 | 0,70 |
| Rata-rata | 0,52 | 0,55 | 0,57 | 0,53 | 0,56 | 0,53 | 0,55 | 0,57 |
Kami menghapus tugas CB dan WSC dari tolok ukur kami, karena model kami berkinerja sangat tinggi pada kedua tugas ini. Kami berhipotesis bahwa mungkin ada tolok ukur kontaminasi data dalam set pelatihan.
Kami sangat ingin mendapatkan masukan dari komunitas. Jika Anda memiliki pertanyaan, silakan buka masalah atau hubungi kami.
OpenLLaMA dikembangkan oleh: Xinyang Geng* dan Hao Liu* dari Berkeley AI Research. *Kontribusi Setara
Kami berterima kasih kepada program Google TPU Research Cloud yang telah menyediakan sebagian sumber daya komputasi. Kami ingin mengucapkan terima kasih khusus kepada Jonathan Caton dari TPU Research Cloud yang telah membantu kami mengatur sumber daya komputasi, Rafi Witten dari tim Google Cloud, dan James Bradbury dari tim Google JAX yang telah membantu kami mengoptimalkan hasil pelatihan. Kami juga ingin mengucapkan terima kasih kepada Charlie Snell, Gautier Izacard, Eric Wallace, Lianmin Zheng, dan komunitas pengguna kami atas diskusi dan masukannya.
Model OpenLLaMA 13B v1 dilatih melalui kolaborasi dengan Stability AI, dan kami berterima kasih kepada Stability AI karena telah menyediakan sumber daya komputasi. Kami terutama ingin mengucapkan terima kasih kepada David Ha dan Shivanshu Purohit atas koordinasi logistik dan penyediaan dukungan teknik.
Jika Anda merasa OpenLLaMA berguna dalam penelitian atau aplikasi Anda, silakan mengutip menggunakan BibTeX berikut:
@software{openlm2023openllama,
author = {Geng, Xinyang and Liu, Hao},
title = {OpenLLaMA: An Open Reproduction of LLaMA},
month = May,
year = 2023,
url = {https://github.com/openlm-research/open_llama}
}
@software{together2023redpajama,
author = {Together Computer},
title = {RedPajama-Data: An Open Source Recipe to Reproduce LLaMA training dataset},
month = April,
year = 2023,
url = {https://github.com/togethercomputer/RedPajama-Data}
}
@article{touvron2023llama,
title={Llama: Open and efficient foundation language models},
author={Touvron, Hugo and Lavril, Thibaut and Izacard, Gautier and Martinet, Xavier and Lachaux, Marie-Anne and Lacroix, Timoth{'e}e and Rozi{`e}re, Baptiste and Goyal, Naman and Hambro, Eric and Azhar, Faisal and others},
journal={arXiv preprint arXiv:2302.13971},
year={2023}
}


