LLM4Decompile
1.0.0
![]()
Hasil | ? Model | Mulai Cepat | HumanEval-Dekompilasi | ? Kutipan | Kertas | Kolaborasi |
Rekayasa Terbalik: Mendekompilasi Kode Biner dengan Model Bahasa Besar
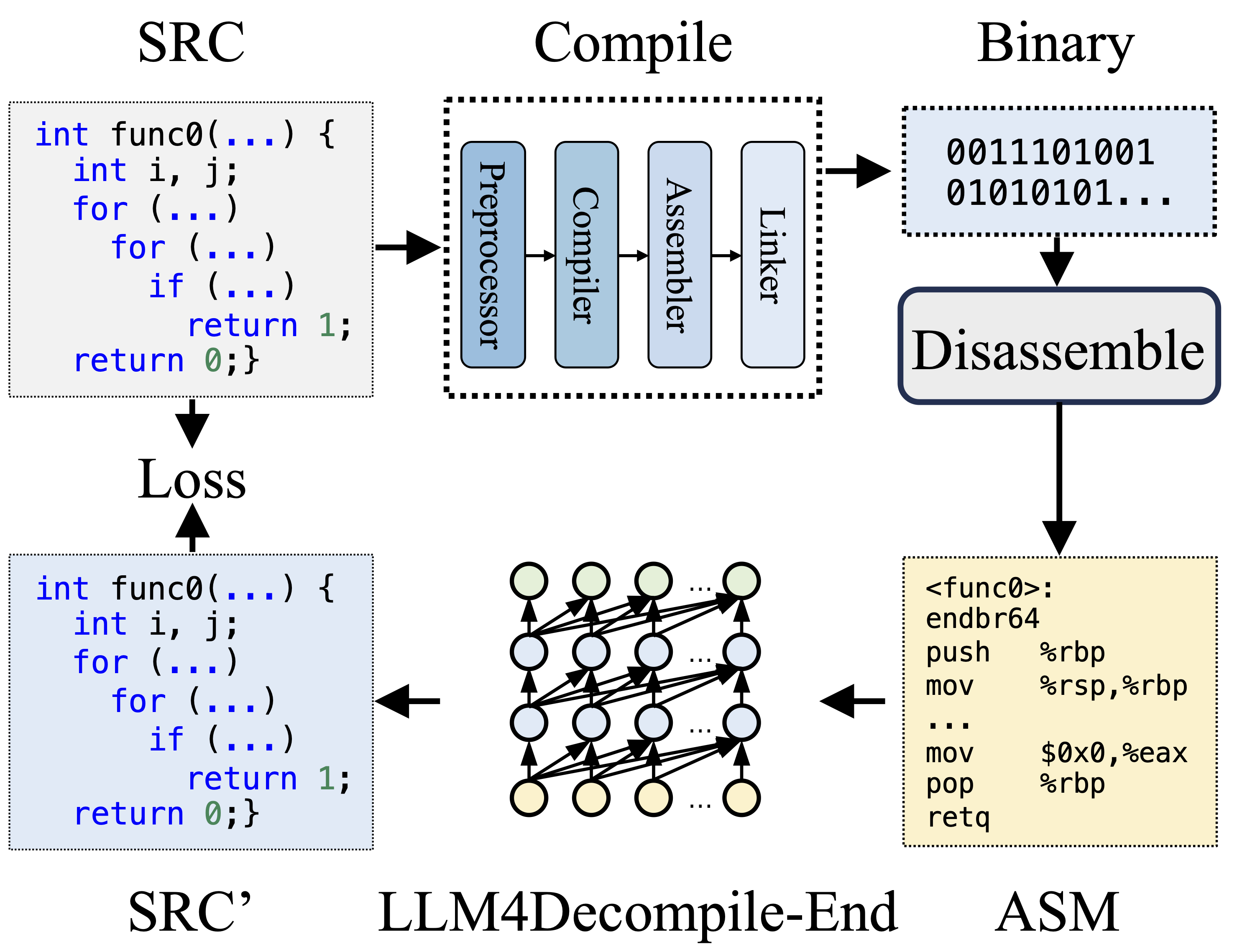
Selama kompilasi, Praprosesor memproses kode sumber (SRC) untuk menghilangkan komentar dan memperluas makro atau penyertaan. Kode yang telah dibersihkan kemudian diteruskan ke Compiler, yang mengubahnya menjadi kode assembly (ASM). ASM ini diubah menjadi kode biner (0 dan 1) oleh Assembler. Linker menyelesaikan proses dengan menghubungkan pemanggilan fungsi untuk membuat file yang dapat dieksekusi. Dekompilasi, di sisi lain, melibatkan konversi kode biner kembali menjadi file sumber. LLM, yang dilatih dalam bentuk teks, tidak memiliki kemampuan untuk memproses data biner secara langsung. Oleh karena itu, binari harus dibongkar oleh Objdump ke dalam bahasa assembly (ASM) terlebih dahulu. Perlu dicatat bahwa ASM biner dan ASM yang dibongkar adalah setara, keduanya dapat saling dikonversi, dan oleh karena itu kami menyebutnya secara bergantian. Terakhir, kerugian dihitung antara kode yang didekompilasi dan kode sumber untuk memandu pelatihan. Untuk menilai kualitas kode yang didekompilasi (SRC'), kode tersebut diuji fungsinya melalui pernyataan pengujian (eksekusi ulang).
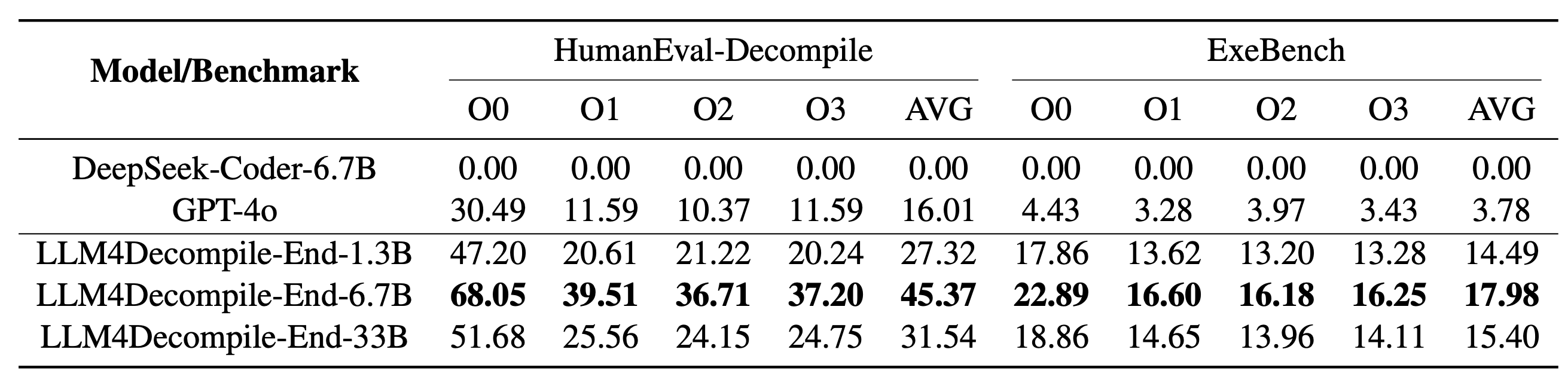
LLM4Decompile kami mencakup model dengan ukuran antara 1,3 miliar dan 33 miliar parameter, dan kami telah membuat model ini tersedia di Hugging Face.
| Model | Pos pemeriksaan | Ukuran | Eksekusi ulang | Catatan |
|---|---|---|---|---|
| llm4dekompilasi-1.3b-v1.5 | ? Tautan HF | 1.3B | 27,3% | Catatan 3 |
| llm4dekompilasi-6.7b-v1.5 | ? Tautan HF | 6.7B | 45,4% | Catatan 3 |
| llm4dekompilasi-1.3b-v2 | ? Tautan HF | 1.3B | 46,0% | Catatan 4 |
| llm4dekompilasi-6.7b-v2 | ? Tautan HF | 6.7B | 52,7% | Catatan 4 |
| llm4dekompilasi-9b-v2 | ? Tautan HF | 9B | 64,9% | Catatan 4 |
| llm4dekompilasi-22b-v2 | ? Tautan HF | 22B | 63,6% | Catatan 4 |
Catatan 3: Seri V1.5 dilatih dengan kumpulan data yang lebih besar (15 miliar token) dan ukuran token maksimum 4.096, dengan performa luar biasa (peningkatan lebih dari 100%) dibandingkan model sebelumnya.
Catatan 4: Seri V2 dibuat berdasarkan Ghidra dan dilatih pada 2 miliar token untuk menyempurnakan kode semu yang didekompilasi dari Ghidra. Periksa folder ghidra untuk detailnya.
Pengaturan: Silakan gunakan skrip di bawah ini untuk menginstal lingkungan yang diperlukan.
git clone https://github.com/albertan017/LLM4Decompile.git
cd LLM4Decompile
conda create -n 'llm4decompile' python=3.9 -y
conda activate llm4decompile
pip install -r requirements.txt
Berikut adalah contoh cara menggunakan model kami (Direvisi untuk V1.5. Untuk model sebelumnya, silakan periksa halaman model terkait di HF). Catatan: Ganti "func0" dengan nama fungsi yang ingin Anda dekompilasi .
Pra-pemrosesan: Kompilasi kode C ke dalam biner, dan bongkar biner ke dalam instruksi perakitan.
import subprocess
import os
func_name = 'func0'
OPT = [ "O0" , "O1" , "O2" , "O3" ]
fileName = 'samples/sample' #'path/to/file'
for opt_state in OPT :
output_file = fileName + '_' + opt_state
input_file = fileName + '.c'
compile_command = f'gcc -o { output_file } .o { input_file } - { opt_state } -lm' #compile the code with GCC on Linux
subprocess . run ( compile_command , shell = True , check = True )
compile_command = f'objdump -d { output_file } .o > { output_file } .s' #disassemble the binary file into assembly instructions
subprocess . run ( compile_command , shell = True , check = True )
input_asm = ''
with open ( output_file + '.s' ) as f : #asm file
asm = f . read ()
if '<' + func_name + '>:' not in asm : #IMPORTANT replace func0 with the function name
raise ValueError ( "compile fails" )
asm = '<' + func_name + '>:' + asm . split ( '<' + func_name + '>:' )[ - 1 ]. split ( ' n n ' )[ 0 ] #IMPORTANT replace func0 with the function name
asm_clean = ""
asm_sp = asm . split ( " n " )
for tmp in asm_sp :
if len ( tmp . split ( " t " )) < 3 and '00' in tmp :
continue
idx = min (
len ( tmp . split ( " t " )) - 1 , 2
)
tmp_asm = " t " . join ( tmp . split ( " t " )[ idx :]) # remove the binary code
tmp_asm = tmp_asm . split ( "#" )[ 0 ]. strip () # remove the comments
asm_clean += tmp_asm + " n "
input_asm = asm_clean . strip ()
before = f"# This is the assembly code: n " #prompt
after = " n # What is the source code? n " #prompt
input_asm_prompt = before + input_asm . strip () + after
with open ( fileName + '_' + opt_state + '.asm' , 'w' , encoding = 'utf-8' ) as f :
f . write ( input_asm_prompt )Instruksi perakitan harus dalam format:
<FUNCTION_NAME>:nOPERASInOPERASIn
Petunjuk perakitan umumnya mungkin terlihat seperti ini:
<func0>:
endbr64
lea (%rdi,%rsi,1),%eax
retq
Dekompilasi: Gunakan LLM4Decompile untuk menerjemahkan instruksi perakitan ke dalam C:
from transformers import AutoTokenizer , AutoModelForCausalLM
import torch
model_path = 'LLM4Binary/llm4decompile-6.7b-v1.5' # V1.5 Model
tokenizer = AutoTokenizer . from_pretrained ( model_path )
model = AutoModelForCausalLM . from_pretrained ( model_path , torch_dtype = torch . bfloat16 ). cuda ()
with open ( fileName + '_' + OPT [ 0 ] + '.asm' , 'r' ) as f : #optimization level O0
asm_func = f . read ()
inputs = tokenizer ( asm_func , return_tensors = "pt" ). to ( model . device )
with torch . no_grad ():
outputs = model . generate ( ** inputs , max_new_tokens = 2048 ) ### max length to 4096, max new tokens should be below the range
c_func_decompile = tokenizer . decode ( outputs [ 0 ][ len ( inputs [ 0 ]): - 1 ])
with open ( fileName + '.c' , 'r' ) as f : #original file
func = f . read ()
print ( f'original function: n { func } ' ) # Note we only decompile one function, where the original file may contain multiple functions
print ( f'decompiled function: n { c_func_decompile } ' ) Data disimpan di llm4decompile/decompile-eval/decompile-eval-executable-gcc-obj.json , menggunakan format daftar JSON. Ada 164*4 (O0, O1, O2, O3) sampel, masing-masing dengan lima kunci:
task_id : menunjukkan ID masalahnya.type : tahap optimasi, merupakan salah satu dari [O0, O1, O2, O3].c_func : Solusi C untuk masalah HumanEval.c_test : pernyataan pengujian C.input_asm_prompt : instruksi perakitan dengan petunjuknya, dapat diturunkan seperti pada contoh prapemrosesan kami.Silakan periksa skrip evaluasi.
Repositori kode ini dilisensikan di bawah Lisensi MIT dan DeepSeek.
@misc{tan2024llm4decompile,
title={LLM4Decompile: Decompiling Binary Code with Large Language Models},
author={Hanzhuo Tan and Qi Luo and Jing Li and Yuqun Zhang},
year={2024},
eprint={2403.05286},
archivePrefix={arXiv},
primaryClass={cs.PL}
}


