PointLLM
1.0.0
 PointLLM: Memberdayakan Model Bahasa Besar untuk Memahami Point Clouds
PointLLM: Memberdayakan Model Bahasa Besar untuk Memahami Point Clouds Runsen Xu Xiaolong Wang Tai Wang Yilun Chen Jiangmiao Pang* Dahua Lin
Laboratorium AI Shanghai Universitas Cina Hong Kong Universitas Zhejiang

PointLLM sedang online! Cobalah di http://101.230.144.196 atau di OpenXLab/PointLLM.
Anda dapat mengobrol dengan PointLLM tentang model kumpulan data Objaverse atau tentang point cloud Anda sendiri!
Harap jangan ragu untuk memberi tahu kami jika Anda memiliki masukan! ?
| Dialog 1 | Dialog 2 | Dialog 3 | Dialog 4 |
|---|---|---|---|
 |  |  |  |
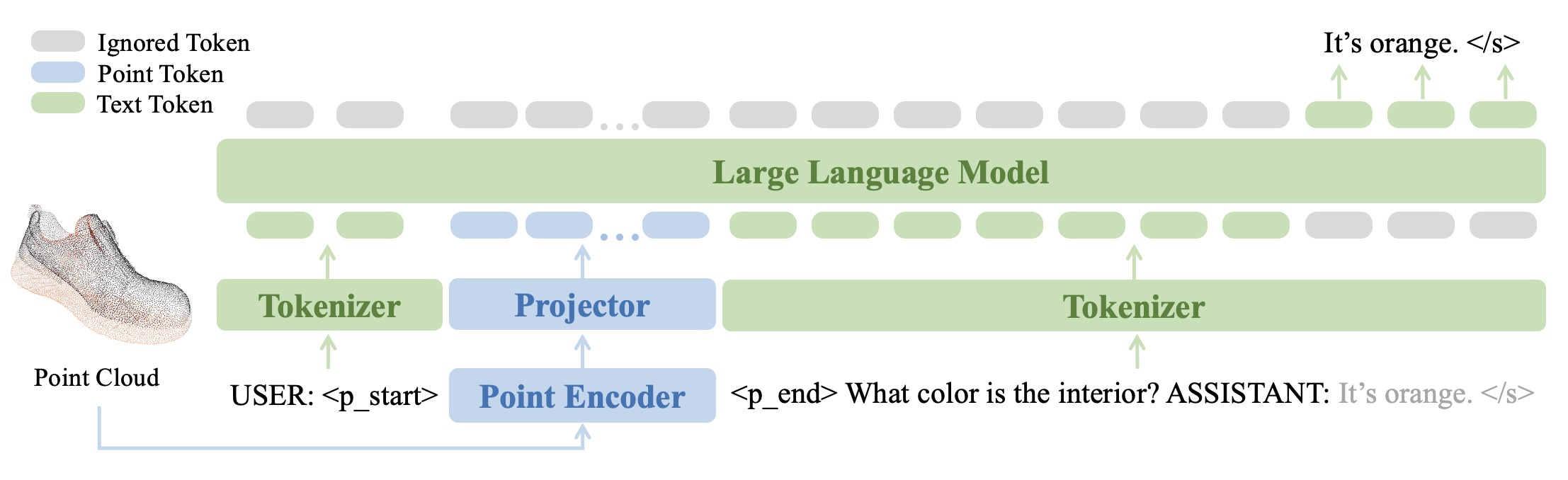
Silakan merujuk ke makalah kami untuk hasil lebih lanjut.
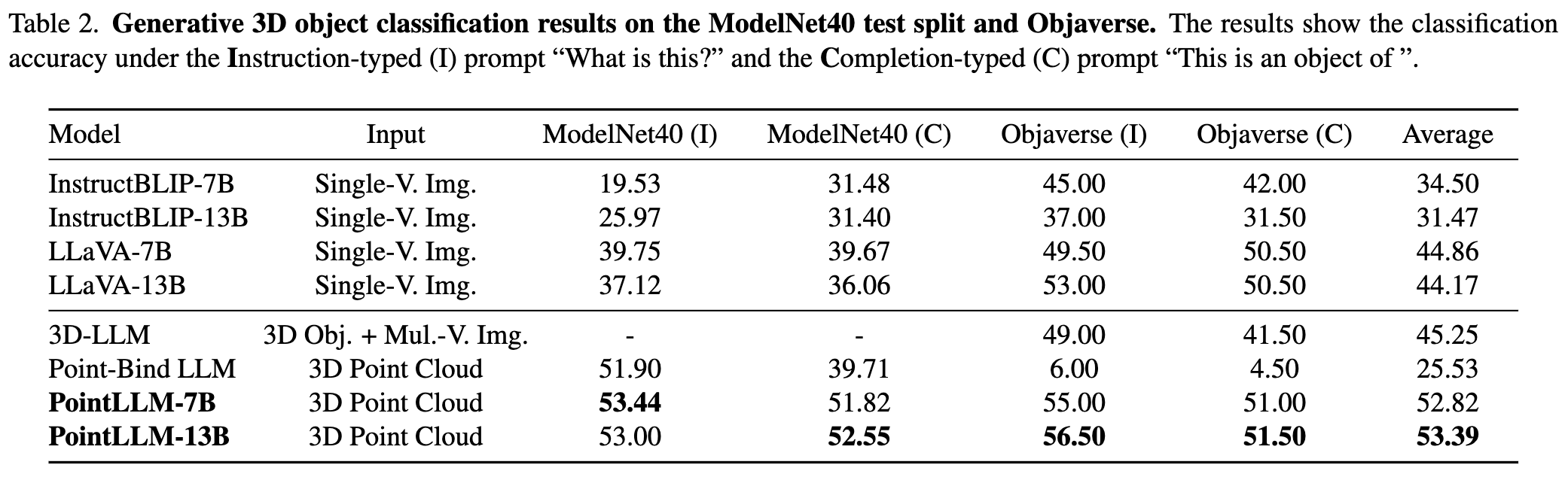
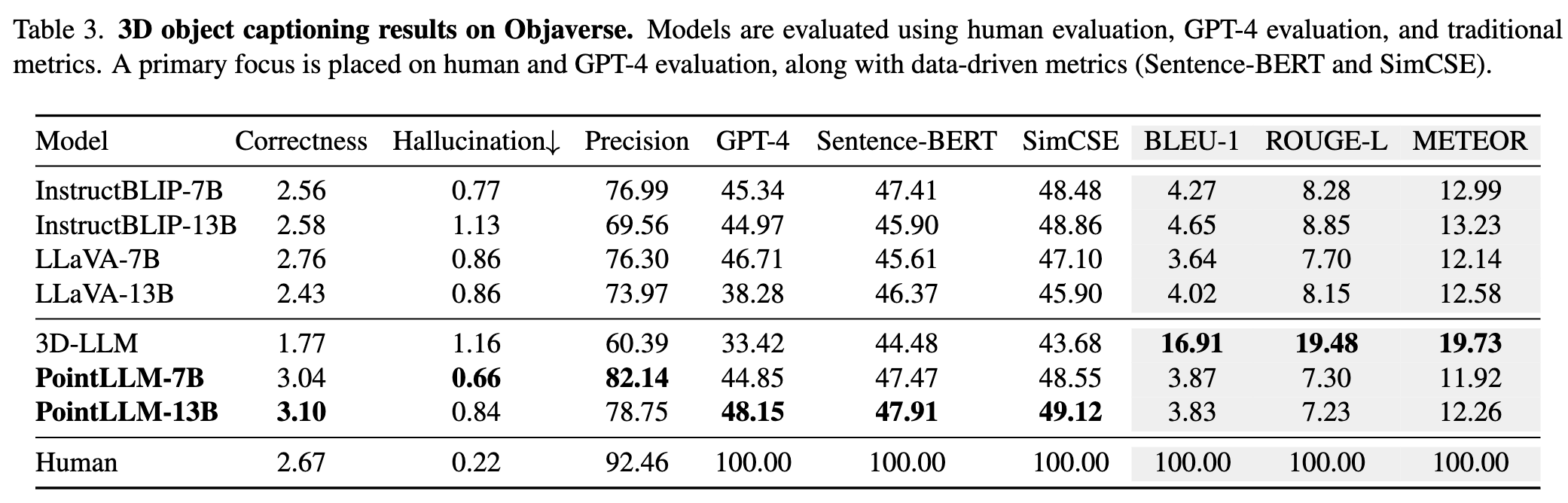
Silakan merujuk ke makalah kami untuk hasil lebih lanjut.

Kami menguji kode kami dalam lingkungan berikut:
Untuk memulai:
git clone [email protected]:OpenRobotLab/PointLLM.git
cd PointLLMconda create -n pointllm python=3.10 -y
conda activate pointllm
pip install --upgrade pip # enable PEP 660 support
pip install -e .
# * for training
pip install ninja
pip install flash-attn8192_npy yang berisi 660 ribu titik file cloud bernama {Objaverse_ID}_8192.npy . Setiap file adalah array numpy dengan dimensi (8192, 6), dengan tiga dimensi pertama adalah xyz dan tiga dimensi terakhir adalah rgb dalam rentang [0, 1]. cat Objaverse_660K_8192_npy_split_a * > Objaverse_660K_8192_npy.tar.gz
tar -xvf Objaverse_660K_8192_npy.tar.gzPointLLM , buat folder data dan buat tautan lunak ke file yang tidak terkompresi di direktori. cd PointLLM
mkdir data
ln -s /path/to/8192_npy data/objaverse_dataPointLLM/data , buat direktori bernama anno_data .anno_data . Direktorinya akan terlihat seperti ini: PointLLM/data/anno_data
├── PointLLM_brief_description_660K_filtered.json
├── PointLLM_brief_description_660K.json
└── PointLLM_complex_instruction_70K.jsonPointLLM_brief_description_660K_filtered.json difilter dari PointLLM_brief_description_660K.json dengan menghapus 3000 objek yang kami pesan sebagai set validasi. Jika Anda ingin mereproduksi hasil di makalah kami, Anda harus menggunakan PointLLM_brief_description_660K_filtered.json untuk pelatihan. PointLLM_complex_instruction_70K.json berisi objek dari set pelatihan.pointllm/data/data_generation/system_prompt_gpt4_0613.txt . PointLLM_brief_description_val_200_GT.json yang kami gunakan untuk tolok ukur pada kumpulan data Objaverse di sini, dan masukkan ke dalam PointLLM/data/anno_data . Kami juga menyediakan 3000 id objek yang kami filter selama pelatihan di sini dan GT referensi terkait di sini, yang dapat digunakan untuk mengevaluasi seluruh 3000 objek.modelnet40_data di PointLLM/data . Unduh pemisahan pengujian cloud titik ModelNet40 modelnet40_test_8192pts_fps.dat di sini dan letakkan di PointLLM/data/modelnet40_data .PointLLM , buat direktori bernama checkpoints .checkpoints . cd PointLLM
scripts/PointLLM_train_stage1.shscripts/PointLLM_train_stage2.shBiasanya Anda tidak perlu mempedulikan konten berikut ini. Mereka hanya untuk mereproduksi hasil di makalah v1 kami (PointLLM-v1.1). Jika Anda ingin membandingkan dengan model kami atau menggunakan model kami untuk tugas hilir, silakan gunakan PointLLM-v1.2 (lihat makalah v2 kami), yang memiliki kinerja lebih baik.
PointLLM v1.1 dan v1.2 menggunakan encoder dan proyektor titik terlatih yang sedikit berbeda. Jika Anda ingin mereproduksi PointLLM v1.1, edit file config.json di direktori LLM awal dan bobot encoder titik, misalnya vim checkpoints/PointLLM_7B_v1.1_init/config.json .
Ubah kunci "point_backbone_config_name" untuk menentukan konfigurasi encoder titik lainnya:
# change from
" point_backbone_config_name " : " PointTransformer_8192point_2layer " # v1.2
# to
" point_backbone_config_name " : " PointTransformer_base_8192point " , # v1.1 Edit jalur pos pemeriksaan pembuat enkode titik di scripts/train_stage1.sh :
# change from
point_backbone_ckpt= $model_name_or_path /point_bert_v1.2.pt # v1.2
# to
point_backbone_ckpt= $model_name_or_path /point_bert_v1.1.pt # v1.1torch.float32 untuk mengobrol tentang model 3D Objaverse. Pos pemeriksaan model akan diunduh secara otomatis. Anda juga dapat mengunduh model pos pemeriksaan secara manual dan menentukan jalurnya. Berikut ini contohnya: cd PointLLM
PYTHONPATH= $PWD python pointllm/eval/PointLLM_chat.py --model_name RunsenXu/PointLLM_7B_v1.2 --data_name data/objaverse_data --torch_dtype float32 Anda juga dapat dengan mudah memodifikasi kode penggunaan point cloud selain dari Objaverse, selama input point cloud ke model memiliki dimensi (N, 6), dengan tiga dimensi pertama adalah xyz dan tiga dimensi terakhir adalah rgb ( dalam rentang [0, 1]). Anda dapat mengambil sampel awan titik untuk mendapatkan 8192 titik, karena model kami dilatih pada awan titik tersebut.
Tabel berikut menunjukkan persyaratan GPU untuk berbagai model dan tipe data. Kami merekomendasikan penggunaan torch.bfloat16 jika memungkinkan, yang digunakan dalam eksperimen di makalah kami.
| Model | Tipe Data | Memori GPU |
|---|---|---|
| PoinLLM-7B | obor.float16 | 14GB |
| PoinLLM-7B | obor.float32 | 28GB |
| PoinLLM-13B | obor.float16 | 26GB |
| PoinLLM-13B | obor.float32 | 52GB |
cd PointLLM
PYTHONPATH= $PWD python pointllm/eval/chat_gradio.py --model_name RunsenXu/PointLLM_7B_v1.2 --data_name data/objaverse_data cd PointLLM
export PYTHONPATH= $PWD
# Open Vocabulary Classification on Objaverse
python pointllm/eval/eval_objaverse.py --model_name RunsenXu/PointLLM_7B_v1.2 --task_type classification --prompt_index 0 # or --prompt_index 1
# Object captioning on Objaverse
python pointllm/eval/eval_objaverse.py --model_name RunsenXu/PointLLM_7B_v1.2 --task_type captioning --prompt_index 2
# Close-set Zero-shot Classification on ModelNet40
python pointllm/eval/eval_modelnet_cls.py --model_name RunsenXu/PointLLM_7B_v1.2 --prompt_index 0 # or --prompt_index 1{model_name}/evaluation sebagai dict dengan format sebagai berikut: {
" prompt " : " " ,
" results " : [
{
" object_id " : " " ,
" ground_truth " : " " ,
" model_output " : " " ,
" label_name " : " " # only for classification on modelnet40
}
]
} cd PointLLM
export PYTHONPATH= $PWD
export OPENAI_API_KEY=sk- ****
# Open Vocabulary Classification on Objaverse
python pointllm/eval/evaluator.py --results_path /path/to/model_output --model_type gpt-4-0613 --eval_type open-free-form-classification --parallel --num_workers 15
# Object captioning on Objaverse
python pointllm/eval/evaluator.py --results_path /path/to/model_output --model_type gpt-4-0613 --eval_type object-captioning --parallel --num_workers 15
# Close-set Zero-shot Classification on ModelNet40
python pointllm/eval/evaluator.py --results_path /path/to/model_output --model_type gpt-3.5-turbo-0613 --eval_type modelnet-close-set-classification --parallel --num_workers 15Ctrl+C . Ini akan menyimpan hasil sementara. Jika terjadi kesalahan selama evaluasi, skrip juga akan menyimpan status saat ini. Anda dapat melanjutkan evaluasi dari bagian terakhirnya dengan menjalankan perintah yang sama lagi.{model_name}/evaluation sebagai dict lain. Beberapa metrik dijelaskan sebagai berikut: " average_score " : The GPT-evaluated captioning score we report in our paper.
" accuracy " : The classification accuracy we report in our paper, including random choices made by ChatGPT when model outputs are vague or ambiguous and ChatGPT outputs " INVALID " .
" clean_accuracy " : The classification accuracy after removing those " INVALID " outputs.
" total_predictions " : The number of predictions.
" correct_predictions " : The number of correct predictions.
" invalid_responses " : The number of " INVALID " outputs by ChatGPT.
# Some other statistics for calling OpenAI API
" prompt_tokens " : The total number of tokens of the prompts for ChatGPT/GPT-4.
" completion_tokens " : The total number of tokens of the completion results from ChatGPT/GPT-4.
" GPT_cost " : The API cost of the whole evaluation process, in US Dollars ?.--start_eval dan menentukan --gpt_type . Misalnya: python pointllm/eval/eval_objaverse.py --model_name RunsenXu/PointLLM_7B_v1.2 --task_type classification --prompt_index 0 --start_eval --gpt_type gpt-4-0613python pointllm/eval/traditional_evaluator.py --results_path /path/to/model_captioning_outputKontribusi komunitas diterima!? Jika Anda memerlukan dukungan apa pun, jangan ragu untuk membuka masalah atau menghubungi kami.
Jika menurut Anda pekerjaan kami dan basis kode ini bermanfaat, harap pertimbangkan untuk memberi bintang pada repo ini? dan mengutip:
@inproceedings { xu2024pointllm ,
title = { PointLLM: Empowering Large Language Models to Understand Point Clouds } ,
author = { Xu, Runsen and Wang, Xiaolong and Wang, Tai and Chen, Yilun and Pang, Jiangmiao and Lin, Dahua } ,
booktitle = { ECCV } ,
year = { 2024 }
}
Karya ini berada di bawah Lisensi Internasional Creative Commons Attribution-NonCommercial-ShareAlike 4.0.
Bersama-sama, Mari kita jadikan LLM untuk 3D hebat!


