Panduan End-to-End Difusi Stabil - Dari Noob hingga Expert
Saya menjadi tertarik menggunakan SD untuk menghasilkan gambar untuk aplikasi militer. Sebagian besar sumber daya diambil dari papan NSFW 4chan, karena segera menggunakan SD untuk membuat hentai. Menariknya, SD WebUI kanonik memiliki fungsionalitas bawaan dengan papan gambar anime/hentai... Salah satu kasus penggunaan SD pertama tepat setelah DALL-E menghasilkan gadis-gadis anime, jadi lompatan ke hentai tidaklah mengejutkan.
Bagaimanapun, teknik dari orang-orang aneh ini dapat diterapkan pada berbagai aplikasi, terutama LoRA, yang seperti model fine-tuner. Idenya adalah untuk bekerja dengan LoRA tertentu (misalnya, kendaraan militer, pesawat terbang, senjata, dll.) untuk menghasilkan data gambar sintetis untuk melatih model visi. Melatih LoRA yang baru dan bermanfaat juga merupakan hal yang menarik. Hal-hal selanjutnya mungkin termasuk pengecatan ulang untuk gangguan.
Penafian dan Sumber
Every link here may contain NSFW content, as most of the cutting-edge work on SD and LoRAs is with porn or hentai. So, please be wary when you are working with these resources. ALSO, Rentry.org pages are the main resources linked to in this guide. If any of the rentry pages do not work, change the .org to .co and the link should work. Otherwise, use the Wayback machine.
-TP
Mainkan Dengan Itu!
Apa yang sebenarnya dapat Anda lakukan dengan SD? Huggingface dan beberapa lainnya memiliki beberapa aplikasi di browser untuk Anda. Bermain-main dengan mereka untuk melihat kekuatannya! Apa yang akan kita lakukan dalam panduan ini adalah mendapatkan WebUI lengkap dan dapat diperluas untuk memungkinkan kita melakukan apa pun yang kita inginkan.
- Teks Huggingface ke Gambar SD Playground
- Aplikasi Teks ke Gambar SD Dreamstudio
- Aplikasi Dezgo Teks ke Gambar SD
- Gambar Huggingface ke Gambar SD Playground
- Taman Bermain Lukisan Huggingface
Daftar isi
- Dasar-dasar WebUI
- Atur penggunaan GPU Lokal
- Pengaturan Linux
- Menjadi Lebih Dalam
- Dorongan
- Model NovelAI
- LoRA
- Bermain dengan Model
- VAE
- Gabungkan semuanya
- Proses SD Umum
- Menyimpan Anjuran
- Pengaturan txt2img
- Meregenerasi Gambar yang Dibuat Sebelumnya
- Mengatasi Masalah Kesalahan
- Menjadi Nyaman
- Pengujian
- WebUI Lanjutan
- Pengeditan Cepat
- Xformer
- Gambar2Img
- melukis
- Ekstra
- Jaringan Kontrol
- Membuat Barang Baru (WIP)
- Penggabungan Pos Pemeriksaan
- Pelatihan LoRA
- Melatih Model Baru
- Penyiapan Google Colab (WIP)
- Tengah perjalanan
- Parameter MJ
- Perintah Lanjutan MJ
- Studio Impian (WIP)
- Gerombolan Stabil (WIP)
- Booth Impian (WIP)
- Difusi Video (WIP)
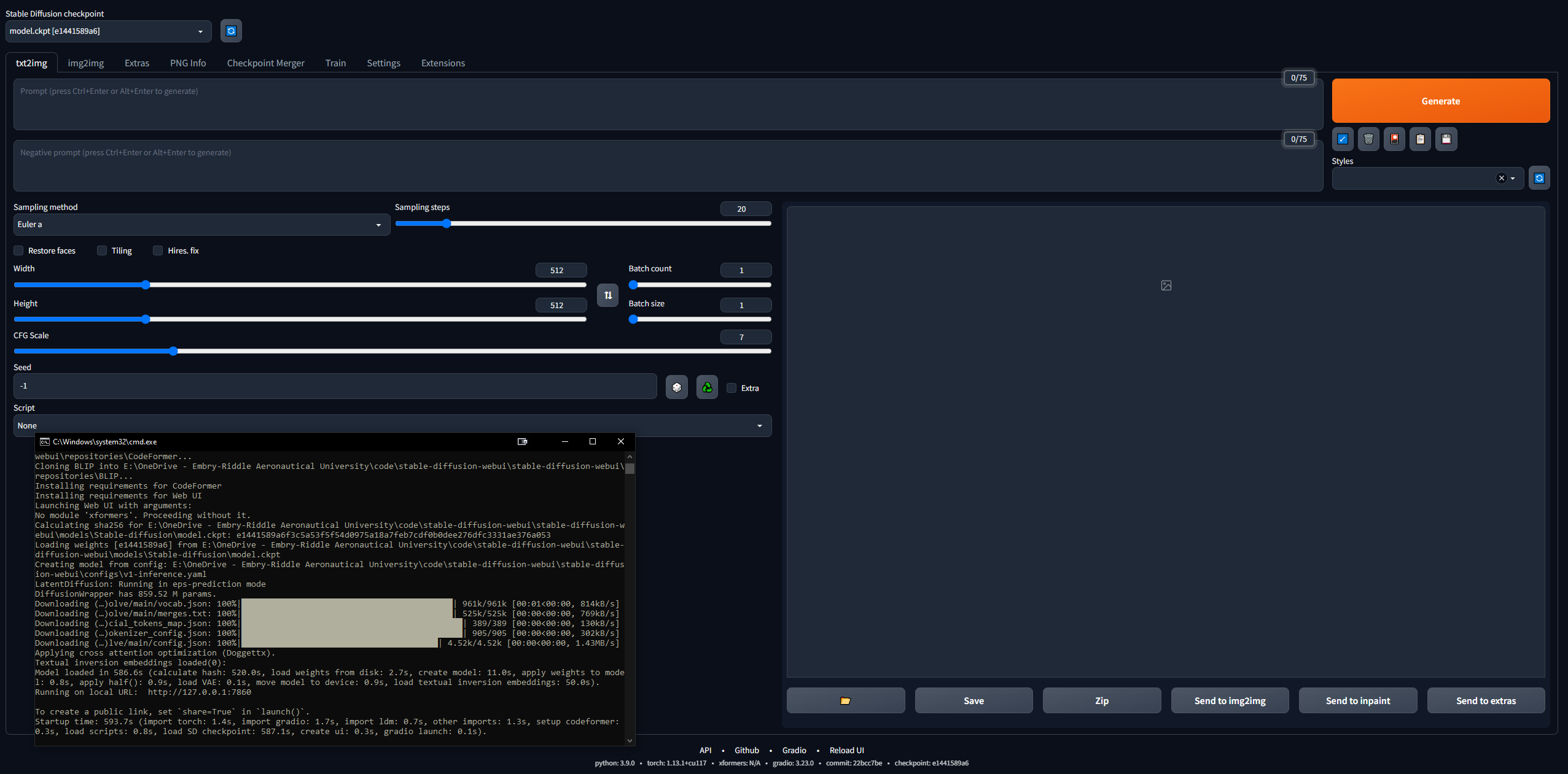
Dasar-dasar WebUI
Agak menakutkan untuk membahas hal ini... tetapi 4channer telah melakukan pekerjaan yang baik sehingga membuat hal ini mudah didekati. Di bawah ini adalah langkah-langkah yang saya ambil, dalam istilah yang paling sederhana. Tujuan Anda adalah menjalankan WebUI Difusi Stabil (dibangun dengan Gradio) secara lokal sehingga Anda dapat mulai meminta dan membuat gambar.
Atur Penggunaan GPU Lokal
Kami akan melakukan penyiapan Google Colab Pro nanti, sehingga kami dapat menjalankan SD di perangkat apa pun di mana pun kami mau; tapi untuk memulai, mari kita siapkan WebUI di PC. Anda memerlukan RAM 16 GB, GPU dengan VRAM 2 GB, Windows 7+, dan ruang disk 20+ GB.
- Selesaikan panduan pengaturan awal
- Saya mengikuti ini hingga langkah 7, setelah itu masuk ke hal-hal hentai
- Langkah 3 membutuhkan waktu rata-rata kecepatan Internet 15-45 menit, karena masing-masing model berukuran 5+ GB
- Langkah 7 dapat memakan waktu hingga setengah jam dan mungkin tampak "macet" di CLI
- Pada langkah 3 saya mengunduh SD1.5, bukan versi 2.x, karena 1.5 memberikan hasil yang jauh lebih baik
- CivitAI memiliki semua model SD; ini seperti HuggingFace tetapi khusus untuk SD
- Verifikasi bahwa WebUI berfungsi
- Copy URL keluaran CLI setelah selesai, misal
127.0.0.1:7860 ( JANGAN gunakan Ctrl+C karena perintah ini dapat menutup CLI) - Rekatkan ke browser dan voila; coba prompt dan Anda berangkat ke balapan
- Gambar akan disimpan secara otomatis ketika dibuat ke
stable-diffusion-webuioutputstxt2img-images<date>
- Ingat, untuk mengupdate, cukup buka CLI di folder stable-diffusion-webui dan masukkan perintah
git pull
Pengaturan Linux
Abaikan ini sepenuhnya jika Anda memiliki Windows. Saya berhasil menjalankannya di Linux juga, meskipun sedikit lebih rumit. Saya mulai dengan mengikuti panduan ini, tetapi tulisannya agak buruk, jadi di bawah ini adalah langkah-langkah yang saya ambil untuk menjalankannya di Linux. Saya menggunakan Linux Mint 20, yang merupakan distribusi Ubuntu 20.
- Mulailah dengan mengkloning repo webui:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git - Dapatkan model SD (misalnya SD 1.5, seperti di bagian sebelumnya)
- Masukkan file model ckpt ke dalam
stable-diffusion-webui/models/Stable-diffusion - Unduh Python (jika Anda belum memilikinya):
sudo apt install python3 python3-pip python3-virtualenv wget git - Dan WebUI sangat khusus, jadi kita perlu menginstal Conda, manajer lingkungan virtual, untuk bekerja di dalam:
wget https://repo.anaconda.com/miniconda/Minconda3-latest-Linux-x86_64.sh
chmod +x Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh
- Sekarang buat lingkungan:
conda create --name sdwebui python=3.10.6 - Aktifkan lingkungan:
conda activate sdwebui - Arahkan ke folder WebUI Anda dan ketik
./webui.sh - Itu harus dijalankan sebentar sampai Anda mendapatkan kesalahan karena tidak dapat mengakses CUDA/GPU Anda... ini baik-baik saja, karena ini adalah langkah kami selanjutnya
- Mulailah dengan menghapus semua driver Nvidia yang ada:
sudo apt update
sudo apt purge *nvidia*
- Sekarang, ikuti beberapa bagian dari panduan ini, cari tahu GPU apa yang dimiliki mesin Linux Anda (cara termudah untuk melakukannya adalah dengan membuka aplikasi Driver Manager dan GPU Anda akan terdaftar; tetapi ada banyak cara, cukup Google saja)
- Buka halaman ini dan klik "Cabang Fitur Baru Terbaru" di Linux x86_64 (bagi saya, itu adalah 530.xx.xx)
- Klik tab "Produk yang Didukung" dan Ctrl + F untuk menemukan GPU Anda; jika terdaftar, lanjutkan, jika tidak mundur dan coba "Versi Cabang Produksi Terbaru"; catat nomornya, misal 530
- Di terminal, ketik:
sudo add-apt-repository ppa:graphics-drivers/ppa - Perbarui dengan
sudo apt-get update - Luncurkan aplikasi Driver Manager dan Anda akan melihat daftarnya; JANGAN pilih yang direkomendasikan (misal, nvidia-driver-530-open), pilih yang sama persis dari sebelumnya (misal, nvidia-driver-530), dan Terapkan Perubahan; ATAU, instal di terminal dengan
sudo apt-get install nvidia-driver-530 - PADA TITIK INI, Anda akan mendapatkan popup melalui CLI Anda tentang Boot Aman, yang meminta Anda memasukkan kata sandi 8 digit: atur dan tuliskan
- Nyalakan ulang PC Anda dan sebelum enkripsi/login pengguna, Anda akan melihat layar seperti BIOS (saya menulis ini dari memori) dengan opsi untuk memasukkan kunci MOK; klik dan masukkan kata sandi Anda, lalu kirim dan boot; beberapa info di sini
- Masuk seperti biasa dan ketik perintah
nvidia-smi ; jika berhasil, ia akan mencetak tabel; jika tidak, ia akan mengatakan sesuatu seperti "Tidak dapat terhubung ke GPU; pastikan driver terbaru telah diinstal" - Sekarang untuk menginstal CUDA (perintah terakhir di sini akan mencetak beberapa informasi tentang instalasi CUDA baru Anda); dari panduan ini:
sudo apt update
sudo apt install apt-transport-https ca-certificates gnupg
sudo apt install nvidia-cuda-toolkit
nvcc-version
- Sekarang kembali dan lakukan langkah 7-9; jika Anda mendapatkan "ERROR: Cannot activation python venv, aborting...", lanjutkan ke langkah berikutnya (jika tidak, Anda akan melanjutkan balapan dan akan menyalin alamat IP dari CLI seperti biasa dan dapat mulai bermain dengan SD)
- Masalah Github ini memiliki beberapa pemecahan masalah untuk masalah venv ini... bagi saya, yang berhasil adalah berjalan
python3 -c 'import venv'
python3 -m venv venv/
Dan kemudian pergi ke folder /stable-diffusion-webui dan menjalankan:
rm -rf venv/
python3 -m venv venv/
Setelah itu, itu berhasil untuk saya.
Menjadi Lebih Dalam
- Bacalah teknik-teknik prompting, karena ada banyak hal yang perlu diketahui (misalnya, prompt positif vs. prompt negatif, langkah-langkah pengambilan sampel, metode pengambilan sampel, dll.)
- Panduan Buku Prompt OpenArt
- Panduan Definitif SD Prompt
- Panduan bisikan yang ringkas
- Tip prompt 4chan (NSFW)
- Koleksi petunjuk dan gambar
- Panduan Anjuran Gadis Anime Langkah demi Langkah
- Baca pengetahuan SD secara umum:
- Publikasi Difusi Stabil Mani
- CompVis / Stability AI Github (rumah bagi model SD asli)
- Ringkasan Difusi Stabil (sumber daya luar yang bagus)
- Hub Tautan Difusi Stabil (sumber daya 4chan yang luar biasa)
- Tambang Emas Difusi Stabil
- Tambang Emas SD yang disederhanakan
- Acak/Lain-lain. Tautan SD
- Pertanyaan Umum (NSFW)
- Pertanyaan Umum lainnya
- Bergabunglah dengan Perselisihan Difusi Stabil
- Tetap up to date dengan berita Difusi Stabil
- Tahukah Anda bahwa mulai Maret 2023, model difusi teks-ke-video dengan parameter 1,7 miliar telah tersedia?
- Berantakan di WebUI, bermain dengan berbagai model, pengaturan, dll.
Dorongan
Urutan kata dalam prompt mempunyai pengaruh: kata-kata sebelumnya diutamakan. Struktur umum prompt yang bagus, dari sini:
<general positives> <descriptors of subject> <descriptors of background> <post-processing, camera, etc.>
Dan panduan bagus lainnya mengatakan bahwa perintahnya harus mengikuti struktur ini:
<subject> <medium> <style> <artist> <website> <resolution> <additional details> <color> <lighting>
Makalah penting tentang rekayasa cepat model txt2img, di sini. Sumber daya pasti tentang permintaan LLM, di sini.
Apa pun yang Anda minta, cobalah mengikuti semacam struktur sehingga proses Anda dapat ditiru. Di bawah ini adalah elemen sintaks prompt yang diperlukan:
- () = pengubah x1.05
- [] = pengubah /1.05
- (kata:1.05) == (kata)
- (kata:1.1025) == ((kata))
- (kata:.952) == [kata]
- (kata:.907) == [[kata]]
- Kata kunci AND memungkinkan Anda meminta dua perintah terpisah sekaligus untuk menggabungkannya; bagus agar segala sesuatunya tidak saling bertabrakan di ruang laten
- Misalnya,
1girl standing on grass in front of castle AND castle in background
Model NovelAI
Model standarnya cukup rapi tetapi, seperti yang biasanya terjadi dalam sejarah, seks mendorong banyak hal. NovelAI (NAI) adalah layanan pembuatan konten SD yang berfokus pada anime dan model utamanya telah bocor. Sebagian besar gambar anime pria dan wanita buatan SD yang Anda lihat (NSFW atau tidak) berasal dari model yang bocor ini.
Bagaimanapun, ini sangat bagus dalam menghasilkan orang dan sebagian besar model atau LoRA yang akan Anda mainkan dengan penggabungan kompatibel dengannya karena mereka dilatih tentang gambar anime. Selain itu, manusia menghadirkan kasus penggunaan awal yang sangat baik untuk menyempurnakan LoRA yang ingin Anda gunakan untuk tujuan profesional. Anda akan memecahkan banyak masalah dan sebagian besar panduan di luar sana ditujukan untuk gambar wanita. Nanti kita akan membahas variabel auto-encoder (VAE), yang menghadirkan realisme sejati pada model.
- Ikuti Panduan Speedrun NovelAI
- Anda harus melakukan Torrent pada model yang bocor atau menemukannya di tempat lain
- Setelah Anda memasukkan file ke dalam folder untuk WebUI,
stable-diffusion-webuimodelsStable-diffusion , dan memilih model di sana, Anda harus menunggu beberapa menit sementara CLI memuat bobot VAE- Jika Anda mengalami masalah di sini, salin file config.yaml dari folder tempat model berada dan ikuti skema penamaan yang sama (seperti dalam panduan ini)
- Ini penting... Buat ulang gambar Asuka dengan tepat, mengacu pada panduan pemecahan masalah jika tidak cocok
- Temukan model SD dan LoRA baru
- CivitAI
- wajah berpelukan
- Model SDG
- Beban Utama Model SDG (NSFW)
- Beban Utama SDG LoRA (NSFW)
- Banyak model populer (juga panduan petunjuk dari sebelumnya) (NSFW)
LoRA
Adaptasi Tingkat Rendah (LoRA) memungkinkan penyesuaian untuk model tertentu. Info lebih lanjut tentang LoRA di sini. Di WebUI, Anda dapat menambahkan LoRA ke model seperti lapisan gula pada kue. Melatih LoRA baru juga cukup mudah. Ada cara lain yang bersifat "nenek moyang" untuk melakukan penyesuaian (misalnya, inversi tekstual dan hypernetwork), namun LoRA adalah yang paling canggih.
- ZTZ99A Tank - tank militer LoRA (tank tertentu)
- Jet Tempur - jet tempur LoRA
- epi_noiseoffset - LoRA yang membuat gambar menonjol, meningkatkan kontras
Saya akan menggunakan tangki LoRA sepanjang panduan ini. Harap dicatat bahwa ini bukan LoRA yang sangat bagus, karena dimaksudkan untuk gambar bergaya anime, tetapi tidak masalah untuk dimainkan.
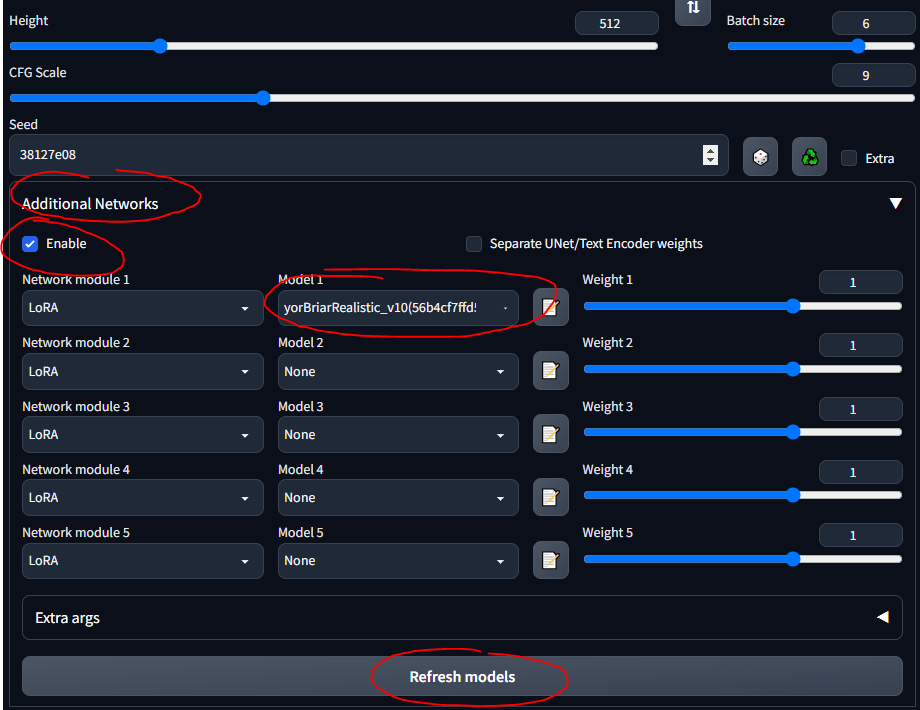
- Ikuti panduan cepat ini untuk menginstal ekstensi
- Anda sekarang akan melihat bagian "Jaringan Tambahan" di UI
- Masukkan LoRA Anda ke
stable-diffusion-webuiextensionssd-webui-additional-networksmodelslora - Pilih dan pergi
- PASTIKAN ANDA MEMERIKSA 'AKTIFKAN'
- Ketahuilah bahwa LoRA apa pun yang Anda unduh mungkin memiliki info yang menjelaskan cara menggunakannya... seperti "gunakan kata kunci tangki" atau semacamnya; pastikan dari mana pun Anda mendownloadnya (misalnya, CivitAI), Anda membaca deskripsinya
Bermain dengan Model
Berdasarkan bagian sebelumnya... model yang berbeda memiliki data pelatihan dan kata kunci pelatihan yang berbeda... jadi menggunakan tag booru pada beberapa model tidak berfungsi dengan baik. Di bawah ini adalah beberapa model yang saya mainkan dan "instruksinya" untuk model tersebut.
SDG Model Motherload, digunakan untuk mendapatkan sebagian besar model, saya hanya merangkum instruksi di sini untuk referensi cepat; sebagian besar modelnya ditujukan untuk pornografi literal, saya fokus pada model yang realistis. Ikuti tautan untuk melihat contoh petunjuk, gambar, dan catatan mendetail tentang penggunaan masing-masing petunjuk tersebut.
- Model SD default (1.5, dari langkah penyiapan; Anda dapat bermain dengan SD versi 2.x tetapi sejujurnya, itu jelek)
- Model NovelAI (dari panduan pertama)
- Apa pun v3 - model anime tujuan umum
- Dreamshaper - realisme, serba guna
- Disengaja - realisme, fantasi, lukisan, pemandangan
- Neverending Dream - realisme, fantasi, baik untuk manusia dan hewan
- Menggunakan sistem tag booru
- Difusi Epik - ultra-realisme, dimaksudkan untuk menggantikan SD asli
- AbyssOrangeMix (AOM) - anime, realisme, artistik, lukisan, sangat umum dan bagus untuk pengujian
- Kotosmix - tujuan umum, realisme, anime, pemandangan, orang, DPM++ 2M Karras sampler direkomendasikan
CivitAI digunakan untuk mendapatkan yang lainnya. Anda perlu membuat akun jika tidak, Anda tidak akan dapat melihat barang-barang NSFW, termasuk senjata dan peralatan militer. Di CivitAI, beberapa model (pos pemeriksaan) menyertakan VAE; jika dinyatakan demikian, unduh juga dan letakkan di samping model.
- ChilloutMix - ultra-realisme, potret, salah satu yang paling populer
- Protogen x3.4 - ultra-realisme
- Gunakan kata-kata pemicu: gaya modelshoot, gaya analog, gaya mdjrny-v4, robot nousr
- Dreamlike Photoreal 2.0 - ultra-realisme
- Gunakan kata pemicu: fotorealistik
- Perangkat SPYBG untuk Seniman Digital - realisme, seni konsep
- Gunakan kata pemicu: tk-char, tk-env
VAE
Autoencoder Variabel membuat gambar terlihat lebih baik, lebih tajam, dan tidak terlalu pecah-pecah. Beberapa juga memperbaiki tangan dan wajah. Tapi itu sebagian besar soal saturasi dan bayangan. Dijelaskan di sini dan di sini (NSFW). NovelAI / Anything VAE biasanya digunakan. Ini pada dasarnya merupakan tambahan pada model Anda, seperti LoRA.
Temukan VAE di Daftar VAE:
- NAI / Apapun - untuk model anime
- Dilengkapi dengan model NAI secara default saat Anda memasukkannya ke dalam folder model
- SD 1.5 - untuk model realistis
- Unduh VAE
- Ikuti bagian singkat panduan ini untuk menyiapkan VAE di WebUI
- Pastikan untuk meletakkannya di
stable-diffusion-webuimodelsVAE
- Bermain-main dengan membuat gambar dengan dan tanpa VAE Anda, untuk melihat perbedaannya
Gabungkan semuanya
Berikut adalah beberapa catatan umum dan hal-hal bermanfaat yang saya pelajari selama ini yang belum tentu sesuai dengan alur kronologis panduan ini.
Proses SD Umum
Cara yang baik untuk mempelajarinya adalah dengan menelusuri gambar keren di CivitAI, AIbooru atau situs SD lainnya (4chan, Reddit, dll.), buka apa yang Anda suka dan salin parameter pembuatan ke WebUI. Pengungkapan penuh: membuat ulang gambar secara persis tidak selalu memungkinkan, seperti yang dijelaskan di sini. Tapi biasanya Anda bisa cukup dekat. Untuk benar-benar bermain-main, turunkan CFG agar model menjadi lebih kreatif. Cobalah batch dan menjauhlah dari komputer untuk kembali ke banyak hal untuk dipilih.
Proses umum untuk alur kerja WebUI adalah:
find/pick models/LoRAs -> txt2img (repeat, change params, etc.) -> img2img -> inpainting -> extra ->
- txt2img - meminta dan mendapatkan gambar
- img2img - mengedit gambar dan menghasilkan gambar serupa
- inpainting - mengedit bagian gambar (akan dibahas nanti)
- ekstra - pengeditan gambar akhir (akan dibahas nanti)
Menyimpan Anjuran
Terkadang Anda ingin kembali ke perintah tanpa menempelkan gambar atau menulisnya dari awal. Anda dapat menyimpan perintah untuk menggunakannya kembali di WebUI.
- Tulis perintah positif dan/atau negatif
- Di bawah tombol Hasilkan, klik tombol di sebelah kanan untuk menyimpan "gaya" Anda
- Masukkan nama dan simpan
- Pilih kapan saja dengan mengeklik tarik-turun Gaya
Pengaturan txt2img
Bagian ini kurang lebih merupakan intisari dari informasi panduan ini.
- Lebih banyak langkah pengambilan sampel umumnya berarti lebih akurat (kecuali untuk sampel "a", seperti Euler a, yang sering berubah)
- Mainkan dan matikan ini; secara umum, jika diaktifkan, itu benar-benar membuat wajah terlihat bagus
- Tinggi. perbaikan bagus untuk gambar di atas 512x512; berguna jika ada lebih dari satu orang dalam satu gambar
- CFG paling baik pada nilai rendah-menengah, seperti 5-10
Meregenerasi Gambar yang Dibuat Sebelumnya
Untuk bekerja dari gambar yang dihasilkan SD yang sudah ada; mungkin seseorang mengirimkannya kepada Anda atau Anda ingin membuat ulang yang Anda buat:
- Di WebUI, buka tab Info PNG
- Seret dan lepas gambar yang Anda minati ke UI
- Mereka disimpan di
stable-diffusion-webuioutputstxt2img-images<date>
- Lihat parameter yang digunakan di sebelah kanan
- Berfungsi karena PNG dapat menyimpan metadata
- Anda dapat mengirimkannya langsung ke halaman txt2img dengan tombol yang sesuai
- Mungkin harus memeriksa bolak-balik untuk memastikan model, VAE, dan parameter lainnya terisi secara otomatis dengan benar
Hati-hati, beberapa situs menghapus metadata PNG saat gambar diunggah (misalnya, 4chan), jadi carilah URL ke gambar lengkap atau gunakan situs yang mempertahankan metadata SD, seperti CivitAI atau AIbooru.
Mengatasi Masalah Kesalahan
Saya mendapat beberapa kesalahan sesekali. Sebagian besar kesalahan kehabisan memori (VRAM) yang diperbaiki dengan menurunkan nilai pada beberapa parameter. Terkadang wajah Pemulihan dan Karyawan. pengaturan perbaikan dapat menyebabkan hal ini. Dalam file stable-diffusion-webuiwebui-user.bat , pada baris set COMMANDLINE_ARGS= , Anda dapat meletakkan beberapa tanda yang memperbaiki kesalahan umum.
- Kesalahan NaN, sesuatu seperti "VAE menghasilkan sesuatu NaN", tambahkan parameter
--disable-nan-check - Jika Anda mendapatkan gambar hitam, tambahkan
--no-half - Jika Anda terus kehabisan VRAM, tambahkan
--medvram atau untuk komputer kentang, --lowvram - Perbaikan wajah Codeformer diperbaiki di sini (jika rusak, coba reset Internet Anda terlebih dahulu)
- Pemuatan model yang lambat (saat beralih ke yang baru) mungkin karena file .safetensors dimuat dengan lambat jika ada yang tidak dikonfigurasi dengan benar. Thread ini membahasnya.
Salah satu masalah yang sangat umum berasal dari versi Python atau versi Torch yang salah. Anda akan mendapatkan kesalahan seperti "tidak dapat menginstal Torch" atau "Torch tidak dapat menemukan GPU". Perbaikan paling sederhana adalah:
- Copot pemasangan versi Python apa pun yang telah Anda perbarui, karena SD WebUI mengharapkan 3.10.6 (Saya telah menggunakan 3.11.5 dan mengabaikan kesalahan awal, tetapi 3.10.6 tampaknya berfungsi paling baik) (Anda juga dapat menggunakan manajer versi jika Anda sudah cukup mahir)
- Instal Python 3.10.6, pastikan untuk menambahkannya ke PATH Anda (folder
Python dan folder Python/Scripts ) - Hapus folder
venv di folder stable-diffusion-webui Anda - Jalankan
stable-diffusion-webuiwebui-user.bat dan biarkan venv dibangun kembali dengan benar - Menikmati
Semua argumen baris perintah dapat ditemukan di sini.
Menjadi Nyaman
Beberapa ekstensi dapat membuat penggunaan WebUI menjadi lebih baik. Dapatkan tautan Github, buka tab Ekstensi, instal dari URL; opsional, di Tab Ekstensi, klik Tersedia, lalu Muat Dari dan Anda dapat menelusuri ekstensi secara lokal, ini mencerminkan ekstensi wiki Github.
- Tag Completer - merekomendasikan dan melengkapi tag booru secara otomatis saat Anda mengetik
- Status UI Web Difusi Stabil - mempertahankan status UI bahkan setelah memulai ulang
- Uji Perintah Saya - skrip yang dapat Anda jalankan untuk menghapus setiap kata dari perintah Anda untuk melihat pengaruhnya terhadap pembuatan gambar
- Model-Keyword - mengisi otomatis kata kunci yang terkait dengan beberapa model dan LoRA, cukup terpelihara dengan baik dan terkini pada April 2023
- Pemeriksa NSFW - menghitamkan gambar NSFW; berguna jika Anda bekerja di kantor, karena banyak model bagus yang mengizinkan konten NSFW dan Anda mungkin tidak ingin melihatnya di tempat kerja
- HATI-HATI: ekstensi ini dapat mengacaukan pengecatan atau bahkan pembuatan dengan menghitamkan gambar NSFW (tidak sementara, ekstensi ini justru menghasilkan gambar hitam), jadi pastikan untuk mematikannya sesuai kebutuhan
- Gelbooru Prompt - menarik tag dan membuat prompt otomatis dari gambar Gelbooru mana pun menggunakan hashnya
- booru2prompt - mirip dengan Gelbooru Prompt tetapi fungsinya lebih banyak
- Prompt Dinamis - bahasa templat untuk pembuatan prompt yang memungkinkan Anda menjalankan perintah acak atau kombinatorial untuk menghasilkan berbagai gambar (menggunakan wildcard)
- Dijelaskan lebih lanjut di sini
- Toolkit model - ekstensi populer yang membantu Anda mengelola, mengedit, dan membuat model
- Pengonversi Model - berguna untuk mengonversi model, mengubah presisi, dll., saat Anda melatih model Anda sendiri
Pengujian
Jadi sekarang Anda memiliki beberapa model, LoRA, dan petunjuknya... bagaimana Anda dapat menguji untuk melihat mana yang terbaik? Di bawah panel Jaringan Tambahan, ada dropdown Script. Di sini, klik plot X/Y/Z. Pada tipe X, pilih Nama pos pemeriksaan; di nilai X, klik tombol di sebelah kanan untuk menempelkan semua model Anda. Pada tipe Y, coba skala VAE, atau mungkin seed, atau CFG. Atribut apa pun yang Anda pilih, tempelkan (atau masukkan) nilai yang ingin Anda buat grafiknya. Misalnya, jika Anda memiliki 5 model dan 5 VAE, Anda akan membuat kisi berisi 25 gambar, membandingkan keluaran setiap model dengan setiap VAE. Ini sangat serbaguna dan dapat membantu Anda memutuskan apa yang akan digunakan. Berhati-hatilah jika sumbu X atau Y Anda adalah model VAE, maka harus memuat model atau bobot VAE untuk setiap kombinasi, sehingga dapat memakan waktu cukup lama.
Sumber yang sangat bagus tentang perbandingan SD dapat ditemukan di sini (NSFW). Ada banyak tautan untuk diikuti. Anda dapat mulai memahami bagaimana berbagai model, VAE, LoRA, nilai parameter, dan sebagainya memengaruhi pembuatan gambar.
Saya mengadopsi test prompt dari sini dan menggunakan tangki LoRA untuk membuat grid X/Y ini. Anda dapat melihat bagaimana berbagai model dan sampler bekerja satu sama lain. Dari pengujian ini, kita dapat mengevaluasi bahwa:
- Model ChilloutMix, Deliberate, Dreamlike Photoreal, dan Epic Diffusion tampaknya menghasilkan gambar tangki yang paling "realistis"
- Dalam pengujian independen selanjutnya, ditemukan bahwa Protogen X34 Photorealism dan SpyBGs Toolkit juga cukup bagus dalam menangani tank.
- Sampler yang paling menjanjikan di sini tampaknya adalah DPM++ SDE atau sampler Karras lainnya.

Parameter pasti yang digunakan (tidak termasuk model atau sampler) untuk setiap gambar tangki diberikan di bawah (sekali lagi, diambil dari sini):
- Perintah positif: tank, bf2042, Kualitas terbaik, mahakarya, resolusi sangat tinggi, (fotorealistik: 1.4), kulit mendetail, pencahayaan sinematik, sinematik sangat detail, penuh warna, Foto modern, sekelompok tentara di medan perang, ledakan medan perang di mana-mana, jet tempur dan helikopter terbang di langit, dua tank di tanah, Di daerah gurun, bangunan terbakar dan satu kendaraan lapis baja militer ditinggalkan di latar belakang
- Perintah negatif: telanjang, (kualitas terburuk:2), (kualitas rendah:2), (kualitas normal:2), gambar rendah, anatomi buruk, tangan jelek, kualitas normal, ((monokrom)), ((skala abu-abu)), roboh eyeshadow, beberapa eyeblow, rambut merah muda, lubang di payudara, ng_deepnegative_v1_75t, nsfw, puting, jari ekstra, ((lengan ekstra)), (kaki ekstra), tangan bermutasi, (jari menyatu), (jari terlalu banyak), (leher panjang: 1.3)
- Langkah-langkah: 22
- Skala CFG: 7,5
- Benih: 1656460887
- Ukuran: 480x480
- Lewati klip: 2
- AddNet Diaktifkan: Benar, Modul AddNet 1: LoRA, Model AddNet 1: ztz99ATank_ztz99ATank(82a1a1085b2b), Berat AddNet A 1:1, Berat AddNet B 1:1
WebUI Lanjutan
Di bagian ini adalah hal-hal lebih lanjut yang dapat Anda lakukan setelah Anda memahami penggunaan model, LoRA, VAE, prompt, parameter, skrip, dan ekstensi di tab txt2image di WebUI.
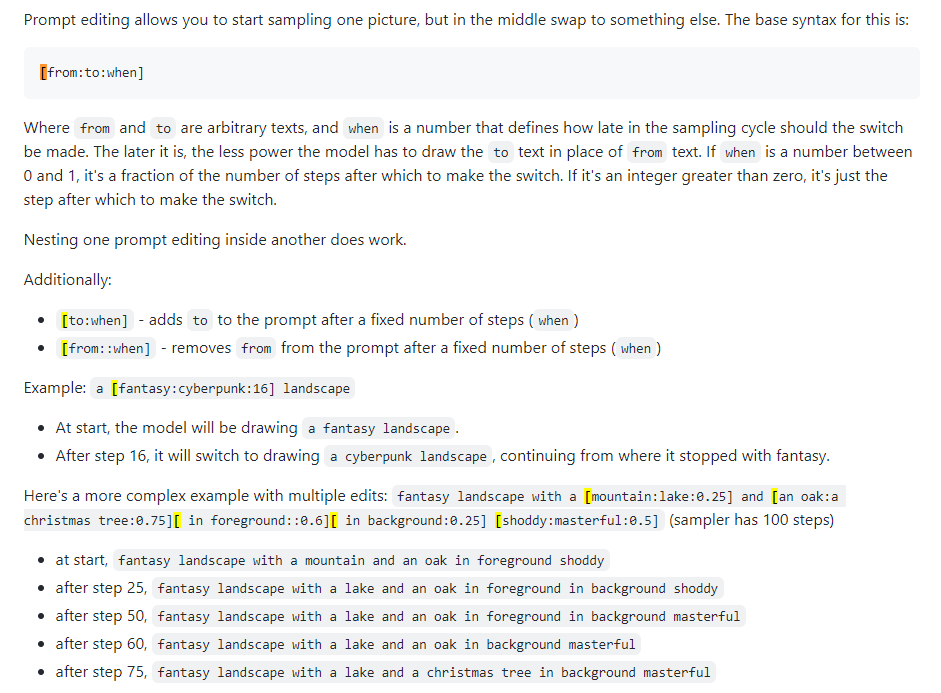
Pengeditan Cepat
Juga dikenal sebagai pencampuran cepat. Pengeditan cepat memungkinkan Anda membuat model mengubah perintahnya pada langkah-langkah tertentu. Gambar di bawah ini diambil dari postingan 4chan dan menjelaskan tekniknya. Misalnya, seperti yang dinyatakan dalam panduan ini, pengeditan cepat dapat digunakan untuk memadukan wajah.
Xformer
Xformers, atau lapisan perhatian silang. Cara untuk mempercepat pembuatan gambar (diukur dalam detik/iterasi, atau s/it) pada GPU Nvidia, menurunkan penggunaan VRAM tetapi menyebabkan non-determinisme. Pertimbangkan ini hanya jika Anda memiliki GPU yang kuat; secara realistis Anda membutuhkan Quadro.
img2img
Tidak terlalu banyak digunakan, semacam tab yang membingungkan. Dapat digunakan untuk menghasilkan gambar yang diberikan sketsa, seperti di Huggingface Image to Image SD Playground. Tab ini memiliki sub-tab, inpainting, yang merupakan subjek bagian selanjutnya dan kemampuan WebUI yang sangat penting. Meskipun Anda dapat menggunakan bagian ini untuk menghasilkan gambar yang diubah berdasarkan gambar yang sudah Anda buat (output ke stable-diffusion-webuioutputsimg2img-images ), bagi saya fungsinya tidak stabil... tampaknya menggunakan jumlah memori yang sangat besar dan Saya hampir tidak bisa membuatnya berfungsi. Lanjutkan ke bagian berikutnya di bawah.
melukis
Di sinilah letak kekuasaan pembuat konten atau seseorang yang tertarik dengan gangguan gambar. Outputnya ada di stable-diffusion-webuioutputsimg2img-images .
- Panduan pengecatan dan pengecatan luar
- Lukisan 4chan (NSFW)
- Panduan inpainting yang pasti
- Ambil gambar yang Anda sukai tetapi gambar tersebut tidak sempurna, ada yang tidak beres - gambar tersebut perlu diubah
- Atau buat satu dan klik Kirim ke inpaint (semua pengaturan akan terisi secara otomatis)
- Anda sekarang berada di sub-tab img2img -> inpaint
- Gambar (dengan mouse Anda) pada gambar tempat yang ingin Anda ubah
- Setel mode mask ke "inpaint masked", konten yang di-mask ke "asli" dan area inpaint ke "only masked"
- Di area prompt di atas, tulis prompt baru untuk mengubah titik tersebut pada gambar; lakukan perintah negatif jika Anda mau
- Hasilkan gambar (idealnya, lakukan 4 gambar atau lebih)
- Apapun yang Anda suka, klik Kirim ke inpaint dan ulangi hingga Anda mendapatkan gambar jadi
Lukisan luar
Pengecatan ulang adalah proses semantik yang agak rumit. Outpainting memungkinkan Anda mengambil gambar dan memperluasnya sebanyak yang Anda inginkan, pada dasarnya memperluas batas gambar tersebut. Prosesnya dijelaskan di sini. Anda memperluas gambar hanya 64 piksel dalam satu waktu. Ada dua alat UI untuk ini (yang dapat saya temukan):
- Alpha Canvas (dibangun ke dalam WebUI sebagai ekstensi/skrip)
- Hua (aplikasi web untuk inpainting/outpainting)
Ekstra
Tab WebUI ini khusus untuk upscaling. Jika Anda mendapatkan gambar yang sangat Anda sukai, Anda dapat meningkatkannya di sini di akhir alur kerja Anda. Gambar yang ditingkatkan disimpan di stable-diffusion-webuioutputsextras-images . Beberapa masalah memori yang terkait dengan peningkatan dengan peningkatan yang lebih kuat selama pembuatan di tab txt2img (misalnya, yang 4x+) tidak terjadi di sini karena Anda tidak membuat gambar baru, Anda hanya meningkatkan gambar statis.
Jaringan Kontrol
Cara terbaik untuk memahami apa yang dilakukan ControlNet adalah seperti mengatakan "melukis dengan steroid". Anda memberinya gambar masukan (dihasilkan SD atau tidak) dan itu dapat mengubah semuanya. Juga dimungkinkan dengan ControlNets adalah pose. Anda dapat memberikan pose referensi untuk seseorang dan menghasilkan gambar yang sesuai dengan perintah khas Anda. Awal yang baik untuk memahami ControlNets ada di sini.
- Instal ekstensi ControlNet, sd-webui-controlnet di WebUI
- Pastikan untuk memuat ulang UI, dengan mengklik tombol Muat Ulang UI di tab pengaturan
- Verifikasi bahwa tombol ControlNet sekarang ada di tab txt2img (dan img2img), di bawah Jaringan Tambahan (tempat Anda meletakkan LoRA)
- Aktifkan multi model ControlNet: Pengaturan -> ControlNet -> Slider Mutli ControlNet -> 2+
- Muat ulang UI dan di area ControlNet Anda akan melihat beberapa tab model
- Anda dapat menggabungkan ControlNets (misalnya Canny dan OpenPose) seperti menggunakan beberapa LoRA
- Dapatkan model ControlNet
- Model Canny adalah model deteksi tepi; gambar diubah menjadi gambar tepi hitam-putih, yang tepinya memberi tahu SD, secara kasar, seperti apa tampilan gambar Anda
- Model OpenPose mengambil gambar seseorang dan mengubahnya menjadi model pose untuk digunakan pada gambar selanjutnya
- Masih banyak model lain yang bisa diselidiki di sana juga
- Mari ambil model Canny dan OpenPose
- Masukkan ke dalam
stable-diffusion-webuiextensionssd-webui-controlnetmodels - Dapatkan gambar apa pun yang Anda minati, atau buat gambar baru; di sini, saya akan menggunakan gambar tank yang saya buat sebelumnya

- Pengaturan di txt2img: metode pengambilan sampel "DDIM", langkah pengambilan sampel 20, lebar/tinggi sama dengan gambar yang Anda pilih
- Pengaturan di tab ControlNet: centang Aktifkan, Praprosesor "Canny", Model "control_canny-fp16", lebar/tinggi kanvas sama dengan gambar yang Anda pilih (semua pengaturan lainnya default)
- Ubah perintah Anda dan klik hasilkan; Saya mencoba mengubah gambar tank saya menjadi gambar di Mars

- Prompt positifnya adalah: pemandangan di mars, luar angkasa, luar angkasa, alam semesta, ((latar belakang ruang galaksi)), bintang, pangkalan bulan, futuristik, latar belakang hitam, latar belakang gelap, bintang di langit, (waktu malam) pasir merah, ((bintang di latar belakang)), tank, bf2042, Kualitas terbaik, mahakarya, resolusi sangat tinggi, (fotorealistik: 1.4), kulit mendetail, pencahayaan sinematik, sinematik sangat detail, penuh warna, Foto modern, sekelompok tentara di medan perang, ledakan medan perang di mana-mana, jet tempur dan helikopter terbang di langit, dua tank di tanah, Di daerah gurun, bangunan terbakar dan satu kendaraan lapis baja militer ditinggalkan di latar belakang, pohon, hutan, langit
- Ambil gambar dengan orang-orang di dalamnya dan Anda dapat melakukan model Canny di Control Model - 0 dan model OpenPose di Control Model - 1 untuk benar-benar bersenang-senang dengannya
- Sekali lagi, tonton video ini untuk mengetahui lebih dalam tentang Canny dan OpenPose
Membuat Barang Baru
Semuanya baik-baik saja, tetapi terkadang Anda memerlukan model atau LoRA yang lebih baik untuk kasus penggunaan profesional. Karena sebagian besar konten SD secara harfiah dimaksudkan untuk menghasilkan perempuan atau pornografi, model dan LoRA tertentu mungkin perlu dilatih.
- Telusuri setiap topik menarik di sini
- Pelatihan LoRA
- kereta LoRA
- Panduan pelatihan LoRA yang malas
- Panduan pelatihan LoRA yang baik dari CivitAI
- Panduan pelatihan LoRA lainnya
- Info LoRA yang lebih umum
- Menggabungkan model
- Pencampuran model
Melatih Model Baru
Lihat bagian di DreamBooth.
Penggabungan Pos Pemeriksaan
TODO
Tab penggabungan checkpoint di WebUI memungkinkan Anda menggabungkan dua model menjadi satu, seperti mencampurkan dua saus dalam panci, yang hasilnya adalah saus baru yang merupakan kombinasi keduanya.
Pelatihan LoRA
TODO
Melatih LoRA tidak selalu sulit, yang penting hanyalah mengumpulkan data yang cukup.
Penyiapan Google Colab
Ini adalah langkah penting jika Anda harus bekerja jauh dari rig Anda. Google Colab Pro berharga 10 dolar sebulan dan memberi Anda 89 GB RAM dan akses ke GPU yang bagus, sehingga Anda secara teknis dapat menjalankan perintah dari ponsel Anda dan membuatnya berfungsi untuk Anda di server di Timbuktu. Jika Anda tidak keberatan dengan sedikit biaya tambahan, Google Colab Pro+ berharga 50 dolar sebulan dan bahkan lebih baik lagi.
- Buka SD Colab bawaan ini
- Anda dapat mengkloningnya ke GDrive Anda atau hanya menggunakannya sebagaimana adanya sehingga selalu terbaru dari Github
- Jalankan 4 blok kode pertama (membutuhkan sedikit waktu)
- Lewati blok kode ControlNet
- Jalankan 'Start Stable-Diffusion' (membutuhkan sedikit waktu)
- Masukkan nama pengguna/kata sandi jika Anda mau (mungkin ide bagus karena Gradio bersifat publik)
- Klik tautan Gradio ('berjalan di URL publik')
- Gunakan WebUI seperti biasa
- Kirim tautan ke ponsel Anda dan Anda dapat menghasilkan gambar saat bepergian
- Untuk menambahkan model dan LoRA baru, Anda harus memiliki folder baru di Google Drive Anda:
gdrive/MyDrive/sd/stable-diffusion-webui , dan dari folder dasar ini Anda dapat menggunakan struktur folder yang sama dengan yang Anda lakukan di lokal UI Web- Lakukan instalasi ekstensi LoRA seperti sebelumnya dan struktur folder akan terisi otomatis seperti di desktop
- Sekarang setiap kali Anda ingin menggunakannya, Anda hanya perlu menjalankan blok kode 'Mulai Difusi Stabil' (tidak ada yang lain), dapatkan tautan gradio dan selesai
Google Colab selalu gratis dan Anda dapat menggunakannya selamanya, namun mungkin agak lambat. Mengupgrade ke Colab Pro seharga $10/bulan memberi Anda lebih banyak kekuatan. Namun Colab Pro+ seharga $50/bulan adalah tempat yang paling menyenangkan. Pro+ memungkinkan Anda menjalankan kode selama 24 jam bahkan setelah Anda menutup tab.
TODO Saya mendapatkan kesalahan aneh yang merusaknya dengan langganan Pro saya ketika saya mengatur runtime -> pengaturan notebook tipe runetime ke kelas GPU Premium dan RAM Tinggi. Itu karena xFormers tidak dibuat dengan dukungan CUDA. Ini dapat diselesaikan dengan menggunakan TPU atau menonaktifkan xFormers tetapi saya tidak memiliki kesabaran untuk itu saat ini. Coba masalah Colab.
Tengah perjalanan
MJ sangat bagus untuk artis. Ini sama sekali tidak dapat diperluas atau sekuat SD di WebUI (NSFW tidak mungkin), tetapi Anda dapat menghasilkan beberapa hal yang cukup mengagumkan. Anda dapat menggunakannya secara gratis di MJ Discord (mendaftar di situs mereka) untuk beberapa petunjuk atau membayar $8/bulan untuk paket dasar, setelah itu Anda dapat menggunakannya di server pribadi Anda. Semua perintah Discord dapat ditemukan di sini dan di sini. Struktur prompt untuk MJ adalah:
/imagine <optional image prompt> <prompt> --parameters
Parameter MJ
Ini untuk MJ V4, sebagian besar sama untuk MJ 5. Semua model dijelaskan di sini.
- --ar 1.2-2.1: rasio aspek, defaultnya adalah 1:1
- --chaos 0-100: variasi dalam, defaultnya adalah 0
- --tidak ada tanaman: menghilangkan tanaman
- --q 0.0-2.0: waktu kualitas rendering, defaultnya adalah 1
- --seed: benih
- --stop 10-100: hentikan pekerjaan di tengah jalan untuk menghasilkan gambar yang lebih buram
- --gaya 4a/4b/4c: gaya MJ 4'
- --stylize 0-1000: seberapa kuat estetika MJ berjalan bebas, defaultnya adalah 100
- --uplight: gunakan upscaler "ringan", gambar kurang detail
- --upbeta: gunakan peningkatan beta, mendekati gambar asli
- --upanime: peningkatan untuk gambar anime
- --niji: model alternatif untuk gambar anime
- --hd: gunakan model sebelumnya yang menghasilkan gambar lebih besar, bagus untuk abstrak dan lanskap
- --Test: Gunakan model uji MJ khusus
- -TestP: Gunakan model uji fotografi MJ khusus
- --Tile: Hanya untuk MJ 5, menghasilkan gambar yang berulang
- --V 1/2/3/4/5: Versi MJ mana yang akan digunakan (5 adalah yang terbaik)
MJ Advanced Prompts
- Anda dapat menyuntikkan gambar (atau gambar) ke awal prompt untuk mempengaruhi gaya dan warnanya. Lihat dokumen ini. Unggah gambar ke server Discord Anda dan klik kanan untuk mendapatkan tautan.
- Remixing memungkinkan Anda membuat variasi gambar, mengubah model, subjek atau medium. Lihat dokumen ini.
- Multi prompt memungkinkan MJ mempertimbangkan dua atau lebih konsep terpisah secara individual. Versi MJ 1-4 dan Niji saja. Misalnya, "hot dog" akan membuat gambar makanan, "hot :: dog" akan membuat gambar anjing hangat. Anda juga dapat menambahkan bobot untuk diminta; Misalnya, "Hot :: 2 Dog" akan membuat gambar anjing terbakar. MJ 1/2/3 menerima bobot integer, MJ 4 dapat menerima desimal. Lihat dokumen ini.
- Blending memungkinkan Anda mengunggah 2-5 gambar untuk menggabungkannya menjadi gambar baru. Perintah /campuran dijelaskan di sini.
DreamStudio
TODO
DreamStudio (bukan Dreambooth) adalah platform andalan dari Stability AI Company. Situs mereka adalah platform, Dreambooth Studio, dari mana Anda dapat menghasilkan gambar. Ini semacam terletak di antara midjourney dan webui dalam hal fungsionalitas terbuka. Dreambooth Studio tampaknya dibangun di atas platform Invoke.ai, yang dapat Anda instal dan jalankan secara lokal seperti WebUI.
Gerombolan stabil
TODO
Gerombolan stabil adalah upaya komunitas untuk membuat difusi stabil gratis untuk semua orang. Ini pada dasarnya berfungsi seperti torrenting atau hashing bitcoin, di mana semua orang berkontribusi beberapa kekuatan GPU mereka untuk menghasilkan konten SD. Aplikasi Horde dapat diakses di sini.
Dreambooth
TODO
DreamBooth (bukan DreamStudio) adalah implementasi Google dari teknik fine-tuning model difusi yang stabil. Singkatnya: Anda dapat menggunakannya untuk melatih model dengan gambar Anda sendiri. Anda dapat menggunakannya langsung dari sini atau di sini. Ini lebih kompleks daripada hanya mengunduh model dan mengklik di webui, karena Anda sedang bekerja untuk benar -benar melatih dan membuat serialisasi model baru. Beberapa video merangkum cara melakukannya:
- Tutorial Dreambooth Easy
- Pelatihan Dreambooth 10 Menit
- Ekstensi Webui Dreambooth
Dan beberapa pemandu yang baik:
- Nasihat Dreambooth Lanjutan Reddit
- Dreambooth sederhana
- Dreambooth Dump (banyak info, gulir melalui tautan)
A Google Colab untuk DreamBooth:
- Thelastben Dreambooth Training Colab (penulis yang sama dengan SD Colab yang dijelaskan dalam pengaturan Google Colab)
Ada juga pelatih model yang disebut EveryDream. Perbandingan penuh antara Dreambooth dan EveryDream dapat ditemukan di sini.
Difusi video
TODO
Dimungkinkan pada Maret-ish 2023 untuk menggunakan difusi stabil untuk menghasilkan video. Saat ini (April 2023), fungsionalitas agak sederhana, karena video dihasilkan dari gambar yang sama, bingkai demi bingkai, memberikan video semacam tampilan "flipbook". Ada dua ekstensi utama untuk webui yang dapat Anda gunakan:
- Animator - lebih mudah
- Deforum - lebih banyak fungsionalitas
Tempat barang rongsokan
Hal -hal yang tidak banyak saya ketahui tetapi perlu diperhatikan
Ada proses yang bisa Anda ikuti untuk mendapatkan hasil yang baik berulang -ulang ... ini akan disempurnakan dari waktu ke waktu.
- TODO
- Perbaiki tinggi, di sini
- peningkatan, di seluruh tapi di sini kebanyakan
Integrasi chatgpt?
melampaui
Dall-E 2
Deforum https://deforum.github.io/


