thumb
1.0.0
Pustaka pengujian cepat sederhana untuk LLM.
pip install thumb
import os
import thumb
# Set your API key: https://platform.openai.com/account/api-keys
os . environ [ "OPENAI_API_KEY" ] = "YOUR_API_KEY_HERE"
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke"
prompt_b = "tell me a family friendly joke"
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ])Setiap perintah dijalankan 10 kali secara asinkron secara default, yaitu sekitar 9x lebih cepat daripada menjalankannya secara berurutan. Di Notebook Jupyter, antarmuka pengguna sederhana ditampilkan untuk respons penilaian buta (Anda tidak melihat permintaan mana yang menghasilkan respons).
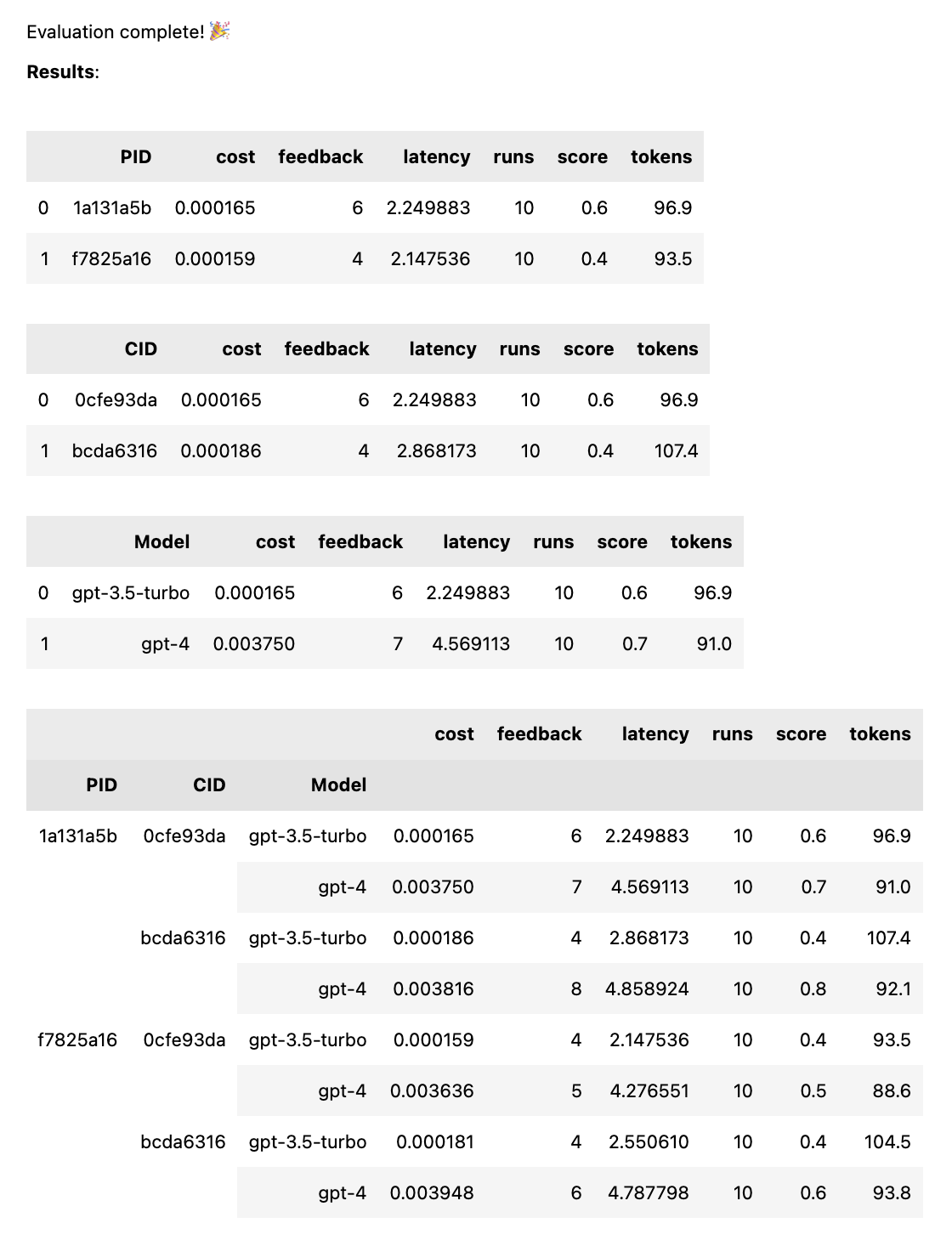
Setelah semua tanggapan diberi peringkat, statistik kinerja berikut dihitung dan dikelompokkan berdasarkan templat cepat:
avg_score umpan balik positif sebagai persentase dari semua prosesavg_tokens : berapa banyak token yang digunakan pada prompt dan responsavg_cost : perkiraan berapa rata-rata biaya operasional yang cepat Laporan sederhana ditampilkan di buku catatan, dan data lengkap disimpan ke file CSV thumb/ThumbTest-{TestID}.csv .

Kasus pengujian adalah saat Anda ingin menguji templat prompt dengan variabel masukan berbeda. Misalnya, jika Anda ingin menguji template prompt yang menyertakan variabel untuk nama komedian, Anda dapat menyiapkan kasus pengujian untuk komedian yang berbeda.
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke in the style of {comedian}"
prompt_b = "tell me a family friendly joke in the style of {comedian}"
# set test cases with different input variables
cases = [
{ "comedian" : "chris rock" },
{ "comedian" : "ricky gervais" },
{ "comedian" : "robin williams" }
]
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ], cases )Setiap kasus uji akan dijalankan terhadap setiap template prompt, jadi dalam contoh ini Anda akan mendapatkan 6 kombinasi (3 kasus uji x 2 template prompt), yang masing-masing akan dijalankan 10 kali (total 60 panggilan ke OpenAI). Setiap kasus uji harus menyertakan nilai untuk setiap variabel dalam template prompt.
Perintah mungkin memiliki beberapa variabel di setiap kasus uji. Misalnya, jika Anda ingin menguji template prompt yang menyertakan variabel untuk nama komedian dan topik lelucon, Anda dapat menyiapkan kasus pengujian untuk komedian dan topik berbeda.
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke about {subject} in the style of {comedian}"
prompt_b = "tell me a family friendly joke about {subject} in the style of {comedian}"
# set test cases with different input variables
cases = [
{ "subject" : "joe biden" , "comedian" : "chris rock" },
{ "subject" : "joe biden" , "comedian" : "ricky gervais" },
{ "subject" : "donald trump" , "comedian" : "chris rock" },
{ "subject" : "donald trump" , "comedian" : "ricky gervais" },
]
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ], cases )Setiap kasus diuji terhadap setiap prompt, untuk mendapatkan perbandingan yang adil terhadap kinerja setiap prompt dengan data masukan yang sama. Dengan 4 kasus uji dan 2 perintah, Anda akan mendapatkan 8 kombinasi (4 kasus uji x 2 templat perintah), yang masing-masing akan dijalankan 10 kali (total 80 panggilan ke OpenAI).
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke"
prompt_b = "tell me a family friendly joke"
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ], models = [ "gpt-4" , "gpt-3.5-turbo" ])Ini akan menjalankan setiap perintah terhadap setiap model, untuk mendapatkan perbandingan yang adil atas kinerja setiap perintah dengan data masukan yang sama. Dengan 2 perintah dan 2 model, Anda akan mendapatkan 4 kombinasi (2 perintah x 2 model), yang masing-masing akan dijalankan 10 kali (total 40 panggilan ke OpenAI).
# set up a prompt templates for the a/b test
system_message = "You are the comedian {comedian}"
prompt_a = [ system_message , "tell me a funny joke about {subject}" ]
prompt_b = [ system_message , "tell me a hillarious joke {subject}" ]
cases = [{ "subject" : "joe biden" , "comedian" : "chris rock" },
{ "subject" : "donald trump" , "comedian" : "chris rock" }]
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ], cases ) Prompt dapat berupa string atau array string. Jika perintahnya adalah array, string pertama digunakan sebagai pesan sistem, dan perintah lainnya bergantian antara pesan Manusia dan Asisten ( [system, human, ai, human, ai, ...] ). Hal ini berguna untuk menguji perintah yang menyertakan pesan sistem, atau yang menggunakan pra-pemanasan (memasukkan pesan sebelumnya ke dalam obrolan untuk memandu AI menuju perilaku yang diinginkan).
# set up a prompt templates for the a/b test
system_message = "You are the comedian {comedian}"
prompt_a = [ system_message , # system
"tell me a funny joke about {subject}" , # human
"Sorry, as an AI language model, I am not capable of humor" , # assistant
"That's fine just try your best" ] # human
prompt_b = [ system_message , # system
"tell me a hillarious joke about {subject}" , # human
"Sorry, as an AI language model, I am not capable of humor" , # assistant
"That's fine just try your best" ] # human
cases = [{ "subject" : "joe biden" , "comedian" : "chris rock" },
{ "subject" : "donald trump" , "comedian" : "chris rock" }]
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ], cases )Saat pengujian selesai, Anda mendapatkan laporan evaluasi lengkap, yang dikelompokkan berdasarkan PID, CID, dan model, serta laporan keseluruhan yang dikelompokkan berdasarkan semua kombinasi. Jika Anda hanya menguji satu model atau satu kasus, pengelompokan ini akan dihilangkan. Laporan menunjukkan kunci di bagian bawah untuk melihat ID mana yang sesuai dengan permintaan atau kasus tertentu.
Fungsi thumb.test mengambil parameter berikut:
None )10 )gpt-3.5-turbo ])True ) Jika Anda memiliki 10 pengujian yang dijalankan dengan 2 templat prompt dan 3 kasus pengujian, itu berarti 10 x 2 x 3 = 60 panggilan ke OpenAI. Hati-hati: khususnya dengan GPT-4, biayanya bisa bertambah dengan cepat!
Pelacakan Langchain ke LangSmith secara otomatis diaktifkan jika LANGCHAIN_API_KEY ditetapkan sebagai variabel lingkungan (opsional).
fungsi .test() mengembalikan objek ThumbTest . Anda dapat menambahkan lebih banyak perintah atau kasus ke pengujian, atau menjalankannya beberapa kali. Anda juga dapat membuat, mengevaluasi, dan mengekspor data pengujian kapan saja.
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke"
prompt_b = "tell me a family friendly joke"
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ])
# add more prompts
test . add_prompts ([ "tell me a knock knock joke" , "tell me a knock knock joke about {subject}" ])
# add more cases
test . add_cases ([{ "subject" : "joe biden" }, { "subject" : "donald trump" }])
# run each prompt and case 5 more times
test . add_runs ( 5 )
# generate the responses
test . generate ()
# rate the responses
test . evaluate ()
# export the test data for analysis
test . export_to_csv () Setiap template prompt mendapatkan data masukan yang sama dari setiap kasus uji, namun prompt tidak perlu menggunakan semua variabel dalam kasus uji. Seperti pada contoh di atas, prompt tell me a knock knock joke tidak menggunakan variabel subject , namun tetap dihasilkan satu kali (tanpa variabel) untuk setiap kasus uji.
Data pengujian di-cache dalam file JSON lokal thumb/.cache/{TestID}.json setelah setiap rangkaian proses dihasilkan untuk kombinasi prompt dan case. Jika pengujian Anda terganggu, atau Anda ingin menambahkannya, Anda dapat menggunakan fungsi thumb.load untuk memuat data pengujian dari cache.
# load a previous test
test_id = "abcd1234" # replace with your test id
test = thumb . load ( f"thumb/.cache/ { test_id } .json" )
# run each prompt and case 2 more times
test . add_runs ( 2 )
# generate the responses
test . generate ()
# rate the responses
test . evaluate ()
# export the test data for analysis
test . export_to_csv () Setiap proses untuk setiap kombinasi prompt dan case disimpan dalam objek (dan cache), dan oleh karena itu pemanggilan test.generate() lagi tidak akan menghasilkan respons baru apa pun jika prompt, case, atau proses lainnya tidak ditambahkan. Demikian pula, memanggil test.evaluate() lagi tidak akan menilai ulang respons yang telah Anda nilai, dan hanya akan menampilkan ulang hasilnya jika tes telah berakhir.
Perbedaan antara orang yang hanya bermain-main dengan ChatGPT dan mereka yang menggunakan AI dalam produksi adalah evaluasi. LLM merespons secara non-deterministik, sehingga penting untuk menguji seperti apa hasilnya ketika diperluas ke berbagai skenario. Tanpa kerangka evaluasi, Anda hanya akan menebak-nebak apa saja yang sesuai dengan perintah Anda (atau tidak).
Insinyur yang serius dan cepat sedang menguji dan mempelajari masukan mana yang menghasilkan keluaran yang berguna atau diinginkan, secara andal dan dalam skala besar. Proses ini disebut optimasi cepat, dan tampilannya seperti ini:
Pengujian jempol mengisi kesenjangan antara mekanisme evaluasi profesional berskala besar, dan dorongan membabi buta melalui trial and error. Jika Anda mentransisikan perintah ke lingkungan produksi, menggunakan thumb untuk menguji perintah Anda dapat membantu Anda mengetahui kasus-kasus yang sulit, dan mendapatkan masukan awal dari pengguna atau tim mengenai hasilnya.
Orang-orang ini membangun thumb untuk bersenang-senang di waktu luang mereka. ?
palu-mt |


