llm data annotation
1.0.0
Kerangka kerja ini menggabungkan keahlian manusia dengan efisiensi Model Bahasa Besar (LLM) seperti GPT-3.5 OpenAI untuk menyederhanakan anotasi kumpulan data dan peningkatan model. Pendekatan berulang memastikan peningkatan kualitas data secara terus-menerus, dan akibatnya, performa model disempurnakan menggunakan data ini. Hal ini tidak hanya menghemat waktu tetapi juga memungkinkan pembuatan LLM khusus yang memanfaatkan anotator manusia dan presisi berbasis LLM.
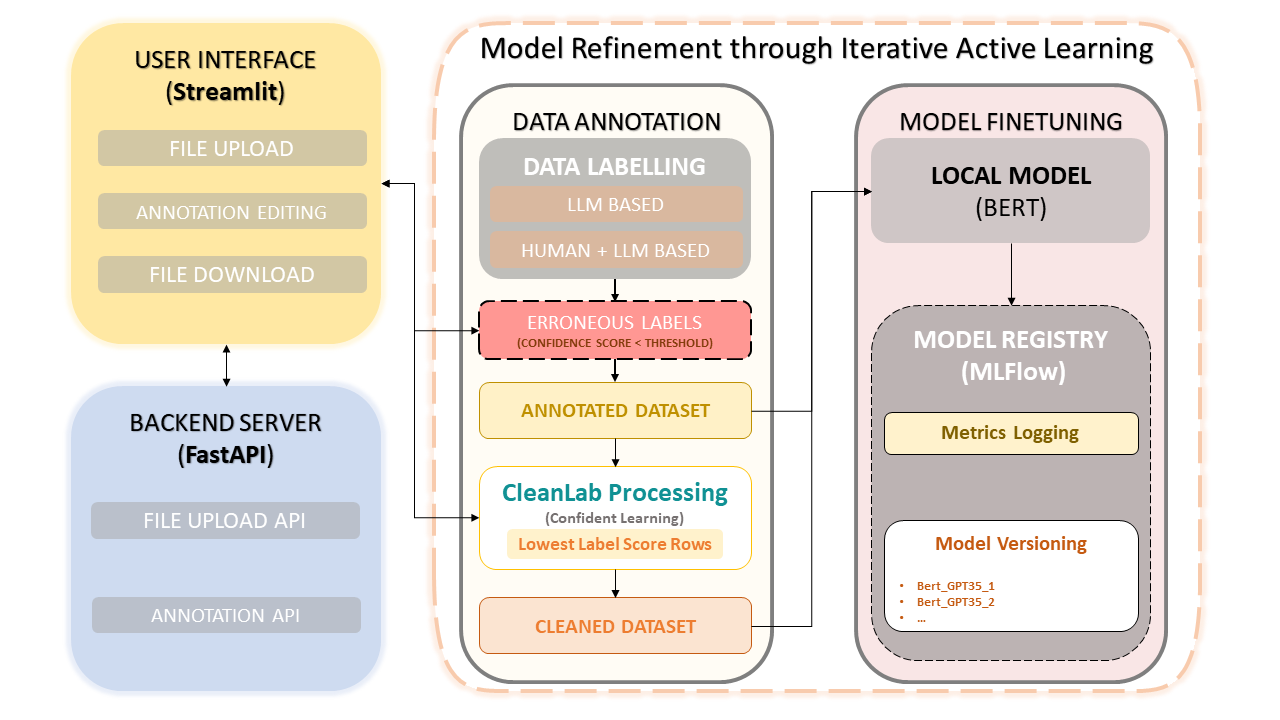
Pengunggahan dan Anotasi Kumpulan Data
Koreksi Anotasi Manual
CleanLab: Pendekatan Pembelajaran Percaya Diri
Pembuatan Versi dan Penyimpanan Data
Pelatihan Model
pip install -r requirements.txtMulai backend FastAPI :
uvicorn app:app --reloadJalankan aplikasi Streamlit :
streamlit run frontend.pyLuncurkan MLflow UI : Untuk melihat model, metrik, dan model terdaftar, Anda dapat mengakses MLflow UI dengan perintah berikut:
mlflow uiAkses tautan yang disediakan di browser web Anda :
http://127.0.0.1:5000 .Ikuti petunjuk di layar untuk mengunggah, memberi anotasi, mengoreksi, dan melatih kumpulan data Anda.
Pembelajaran yang percaya diri telah muncul sebagai teknik terobosan dalam pembelajaran yang diawasi dan pengawasan yang lemah. Hal ini bertujuan untuk mengkarakterisasi derau label, menemukan kesalahan label, dan belajar secara efisien dengan label yang derau. Dengan memangkas data yang bermasalah dan memberi peringkat contoh untuk dilatih dengan percaya diri, metode ini memastikan kumpulan data yang bersih dan andal, sehingga meningkatkan performa model secara keseluruhan.
Proyek ini bersumber terbuka di bawah Lisensi MIT.


