CDial GPT
1.0.0
Proyek ini menyediakan kumpulan data percakapan bahasa Mandarin berskala besar dan model pra-pelatihan percakapan bahasa Mandarin (model GPT bahasa Mandarin) pada kumpulan data ini.
Kode proyek ini dimodifikasi dari TransferTransfo dan menggunakan pustaka Transformers versi HuggingFace Pytorch, yang dapat digunakan untuk pra-pelatihan dan penyesuaian.
from datasets import load_dataset
dataset = load_dataset ( "lccc" , "base" ) # or "large" Kumpulan data LCCC (Percakapan Cina Bersih Skala Besar) yang kami sediakan terutama terdiri dari dua bagian: LCCC-base (Baidu Netdisk, Google Drive) dan LCCC-large (Baidu Netdisk, Google Drive). memastikan kualitas data percakapan dalam kumpulan data ini. Proses pemfilteran data ini mencakup serangkaian aturan manual dan beberapa pengklasifikasi berdasarkan algoritma pembelajaran mesin. Kebisingan yang kami filter meliputi: kata-kata kotor, karakter khusus, ekspresi wajah, kalimat yang salah tata bahasa, dialog yang tidak relevan dengan konteks, dll.
Statistik kumpulan data ini ditunjukkan pada tabel di bawah. Diantaranya, kami menyebut dialog yang hanya berisi dua kalimat sebagai "dialog satu putaran", dan kami menyebut dialog yang berisi lebih dari dua kalimat sebagai "dialog multi-putaran". Gunakan segmentasi kata Jieba saat menghitung ukuran daftar kata.
| Basis LCCC (Disk Awan Baidu, Google Drive) | percakapan satu putaran | Dialog beberapa putaran |
|---|---|---|
| dialog total berubah | 3.354.232 | 3.466.274 |
| Jumlah kalimat dialog | 6.708.464 | 13.365.256 |
| Jumlah karakter | 68.559.367 | 163.690.569 |
| Ukuran kosakata | 372.063 | 666.931 |
| Jumlah rata-rata kata dalam kalimat percakapan | 6.79 | 8.32 |
| Jumlah rata-rata kalimat per putaran percakapan | 2 | 3.86 |
Perhatikan bahwa proses pembersihan dataset berbasis LCCC lebih ketat dibandingkan dengan LCCC-besar, sehingga ukurannya juga lebih kecil.
| LCCC-besar (Disk Awan Baidu, Google Drive) | percakapan satu putaran | Dialog beberapa putaran |
|---|---|---|
| dialog total berubah | 7.273.804 | 4.733.955 |
| Jumlah kalimat dialog | 14.547.608 | 18.341.167 |
| Jumlah karakter | 162.301.556 | 217.776.649 |
| Ukuran kosakata | 662.514 | 690.027 |
| Jumlah kata evaluasi untuk kalimat percakapan | 7.45 | 8.14 |
| Jumlah rata-rata kalimat per putaran percakapan | 2 | 3.87 |
Data percakapan asli dalam kumpulan data berbasis LCCC berasal dari percakapan Weibo, dan data percakapan asli dalam kumpulan data besar LCCC diintegrasikan dengan kumpulan data percakapan sumber terbuka lainnya berdasarkan percakapan Weibo berikut:
| Kumpulan data | dialog total berubah | Contoh percakapan |
|---|---|---|
| Korpus Weibo | 79M | Q: Saya makan hot pot tujuh atau delapan kali di Chengdu, Chongqing. A: Hahahaha! Maka mulutku mungkin membusuk! |
| Korpus Gosip PTT | 0,4 juta | T: Mengapa penduduk desa selalu menindas siswa sekolah menengah? QQ A: Jika Anda berpikir bahwa jika Anda memilih mata pelajaran yang bagus, Anda akan menjadi Bill Gates, sebaiknya Anda putus sekolah. |
| Subjudul Corpus | 2,74 juta | T: Orang-orang di opera Beijing tidak bebas. A: Mereka mengurung orang. |
| Korpus Xiaohuangji | 0,45 juta | Q: Pernahkah kamu jatuh cinta? A: Pernahkah kamu jatuh cinta? Oh, jangan sebutkan itu, aku sedih... |
| Korps Tieba | 2,32 juta | Q: Barisan depan, semua fans Lu bangun kan? A: Judulnya mengatakan assist, tapi setelah menonton bola itu, itu benar-benar sebuah ironi yang hidup. |
| Korps Qingyun | 0,1 juta | Q: Sepertinya kamu sangat menyukai uang. A: Oh, benarkah? Maka Anda hampir sampai |
| Korpus Percakapan Douban | 0,5 juta | Q: Belajar bahasa Inggris murni dengan menonton film berbahasa Inggris asli A: Aku suka Friends dan sudah menontonnya berkali-kali Q: Aku hampir kelelahan menonton CD yang sama A: Kalau begitu, seharusnya bahasa Inggrismu sudah cukup bagus sekarang |
| Korpus Percakapan E-komersial | 0,5 juta | Q: Apakah ini akan menjadi penawaran yang bagus? A: Belum. Q: Apakah ini akan tersedia di masa depan? A: Tidak yakin. |
| Corpus Obrolan Cina | 0,5 juta | Q: Kakiku tidak berguna hari ini. Kalian sedang merayakan liburan, jadi aku akan memindahkan batu bata. A: Ini kerja keras. Aku bahkan ingin menghasilkan banyak uang di hari Natal belum punya pacar, jadi liburan apa pun sama saja. |
Kami juga menyediakan serangkaian model pra-pelatihan Tiongkok (model GPT Tiongkok). Proses pra-pelatihan model ini dibagi menjadi dua langkah, pertama pra-pelatihan pada data novel Tiongkok, dan kemudian pra-pelatihan pada data LCCC. mengatur.
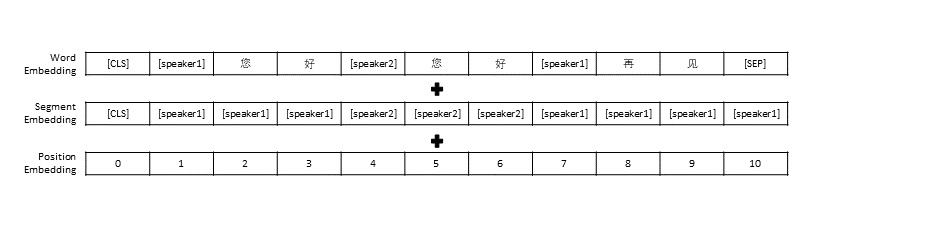
Kami mengikuti pengaturan prapemrosesan data di TransferTransfo, yang menggabungkan seluruh riwayat percakapan menjadi satu kalimat, lalu menggunakan kalimat ini sebagai masukan model untuk memprediksi balasan percakapan. Selain representasi vektor setiap kata, masukan model kami juga mencakup representasi vektor pembicara dan representasi vektor posisi.
| Model terlatih | Jumlah parameter | Data yang digunakan untuk pra-pelatihan | menggambarkan |
|---|---|---|---|
| Novel GPT | 95,5 juta | Data baru Tiongkok | Model GPT terlatih berbahasa Mandarin yang dibuat berdasarkan data baru berbahasa Mandarin (data baru mencakup total 1,3 miliar kata) |
| CDial-GPT berbasis LCCC | 95,5 juta | Basis LCCC | Berdasarkan Novel GPT, gunakan model GPT terlatih Tiongkok yang dilatih oleh basis LCCC |
| Basis LCCC CDial-GPT2 | 95,5 juta | Basis LCCC | Berdasarkan Novel GPT, gunakan model GPT2 terlatih Tiongkok yang dilatih dengan basis LCCC |
| CDial-GPT LCCC-besar | 95,5 juta | LCCC-besar | Berdasarkan Novel GPT , gunakan model GPT terlatih Tiongkok yang dilatih oleh LCCC-large |
Instal langsung dari sumber:
git clone https://github.com/thu-coai/CDial-GPT.git
cd CDial-GPT
pip install -r requirements.txt
Langkah 1: Siapkan kumpulan data yang diperlukan untuk model pra-pelatihan dan penyempurnaan (seperti kumpulan data STC atau data mainan "data/toy_data.json" di direktori proyek. Harap dicatat bahwa jika data berisi bahasa Inggris, maka harus dipisahkan dengan huruf, seperti: halo)
# 下载 STC 数据集 中的训练集和验证集 并将其解压至 "data_path" 目录 (如果微调所使用的数据集为 STC)
git lfs install
git clone https://huggingface.co/thu-coai/CDial-GPT_LCCC-large # 您可自行下载模型或者OpenAIGPTLMHeadModel.from_pretrained("thu-coai/CDial-GPT_LCCC-large")
ps: Anda dapat menggunakan tautan berikut untuk mengunduh set pelatihan dan set verifikasi STC (Baidu Cloud Disk, Google Drive)
Langkah 2: Latih modelnya
python train.py --pretrained --model_checkpoint thu-coai/CDial-GPT_LCCC-large --data_path data/STC.json --scheduler linear # 使用单个GPU进行训练
atau
python -m torch.distributed.launch --nproc_per_node=8 train.py --pretrained --model_checkpoint thu-coai/CDial-GPT_LCCC-large --data_path data/STC.json --scheduler linear # 以分布式的方式在8块GPU上训练
Parameter train_path juga disediakan dalam skrip pelatihan kami, yang memungkinkan pengguna membaca file teks biasa dalam irisan. Jika Anda menggunakan sistem dengan memori terbatas, pertimbangkan untuk menggunakan parameter ini untuk membaca data pelatihan. Jika Anda menggunakan train_path Anda harus membiarkan data_path kosong.
Langkah 3: Hasilkan teks
# YOUR_MODEL_PATH: 你要使用的模型的路径,每次微调后的模型目录保存在./runs/中
python infer.py --model_checkpoint YOUR_MODEL_PATH --datapath data/STC_test.json --out_path STC_result.txt # 在测试数据上生成回复
python interact.py --model_checkpoint YOUR_MODEL_PATH # 在命令行中与模型进行交互
ps: Anda dapat menggunakan tautan berikut untuk mengunduh set tes STC (Baidu Cloud Disk, Google Drive)
Parameter skrip pelatihan
| parameter | jenis | nilai bawaan | menggambarkan |
|---|---|---|---|
| model_pos pemeriksaan | str | "" | Jalur atau URL file model (Direktori model pra-pelatihan dan file konfigurasi/vocab) |
| terlatih | bodoh | PALSU | Jika Salah, latih modelnya dari awal |
| jalur_data | str | "" | Jalur kumpulan data |
| kumpulan data_cache | str | default="kumpulan data_cache" | Jalur atau url cache kumpulan data |
| jalur_kereta | str | "" | Jalur kumpulan pelatihan untuk kumpulan data terdistribusi |
| jalur_valid | str | "" | Jalur kumpulan validasi untuk kumpulan data terdistribusi |
| log_file | str | "" | Keluaran log ke file di bawah jalur ini |
| jumlah_pekerja | ke dalam | 1 | Jumlah subproses untuk memuat data |
| n_zaman | ke dalam | 70 | Jumlah periode pelatihan |
| train_batch_size | ke dalam | 8 | Ukuran batch untuk pelatihan |
| valid_batch_size | ke dalam | 8 | Ukuran batch untuk validasi |
| max_history | ke dalam | 15 | Jumlah pertukaran sebelumnya yang perlu disimpan dalam sejarah |
| penjadwal | str | "noam" | Metode pengoptimal |
| n_emd | ke dalam | 768 | Jumlah n_emd di file konfigurasi (untuk noam) |
| eval_before_start | bodoh | PALSU | Jika benar, mulailah evaluasi sebelum pelatihan |
| pemanasan_langkah | ke dalam | 5000 | Langkah pemanasan |
| langkah_valid | ke dalam | 0 | Lakukan validasi setiap X langkah, jika bukan 0 |
| gradien_akumulasi_langkah | ke dalam | 64 | Akumulasi gradien pada beberapa langkah |
| max_norm | mengambang | 1.0 | Memotong norma gradien |
| perangkat | str | "cuda" jika torch.cuda.is_available() lain "cpu" | Perangkat (cuda atau cpu) |
| fp16 | str | "" | Atur ke O0, O1, O2 atau O3 untuk pelatihan fp16 (lihat dokumentasi apex) |
| peringkat_lokal | ke dalam | -1 | Peringkat lokal untuk pelatihan terdistribusi (-1: tidak terdistribusi) |
Kami mengevaluasi model pra-pelatihan dialog yang disempurnakan menggunakan kumpulan data STC (set pelatihan/set validasi (Baidu Netdisk, Google Drive), set pengujian (Baidu Netdisk, Google Drive)). Semua respons diambil sampelnya menggunakan Nucleus Sampling (p=0,9, suhu=0,7).
| Model | Ukuran model | PPL | BIRU-2 | BIRU-4 | Distrik-1 | Distrik-2 | Pencocokan Serakah | Rata-rata Penyematan |
|---|---|---|---|---|---|---|---|---|
| Attn-Seq2seq | 73M | 34.20 | 3.93 | 0,90 | 8.5 | 11.91 | 65.84 | 83.38 |
| Transformator | 113M | 22.10 | 6.72 | 3.14 | 8.8 | 13.97 | 66.06 | 83,55 |
| GPT2-ngobrol | 88M | - | 2.28 | 0,54 | 10.3 | 16.25 | 61.54 | 78,94 |
| Novel GPT | 95,5 juta | 21.27 | 5.96 | 2.71 | 8.0 | 11.72 | 66.12 | 83.34 |
| berbasis GPT LCCC | 95,5 juta | 18.38 | 6.48 | 3.08 | 8.3 | 12.68 | 66.21 | 83.54 |
| Basis GPT2 LCCC | 95,5 juta | 22.76 | 5.69 | 2.50 | 7.7 | 10.87 | 66.24 | 83.46 |
| GPT LCCC-besar | 95,5 juta | 18.23 | 6.63 | 3.20 | 8.3 | 12.71 | 66.25 | 83.63 |
Kami mengambil sampel 200 respons untuk setiap model dan mengundang tiga anotator di platform outsourcing untuk mengevaluasi respons ini secara manual. Dimensi evaluasinya adalah kelancaran percakapan, relevansi kontekstual, dan keragaman respons. Kisaran penilaian untuk setiap dimensi adalah 2/1/0. Silakan merujuk ke makalah kami untuk lebih jelasnya.
| Model | +2 | +1 | +0 | Kappa |
|---|---|---|---|---|
| Attn-Seq2Seq | 27,1% | 21,4% | 51,4% | 0,4544 |
| Transformator | 42,4% | 23,6% | 34,0% | 0,4429 |
| GPT2-ngobrol | 24,3% | 19,1% | 56,6% | 0,3941 |
| berbasis GPT LCCC | 46,7% | 21,8% | 31,5% | 0,3954 |
| GPT LCCC-besar | 48,6% | 24,5% | 27,0% | 0,4203 |
Kami secara acak mengambil sampel 1.000 balasan percakapan dan menghitung balasan buruk di antara balasan berikut:
| Berisi pernyataan berulang | Berisi kata-kata makian | Balasan buruk lainnya |
|---|---|---|
| dua puluh tiga | 9 | 2 |
Kami menyempurnakan parameter model besar GPT LCCC pada kumpulan data STC, dan menggunakan model yang disempurnakan ini untuk menghasilkan contoh percakapan berikut:
| Pos | Tanggapan |
|---|---|
| Ini sebenarnya Beijing, bukan Harbin. | Cuaca di Harbin tampaknya lebih baik daripada di Beijing. Hujan ringan di sini dan angin kencang di siang hari. |
| Kompetisi periklanan kampus operator sangat menyenangkan! Ha ha ha. | Saya pikir itu iklan Jack Ma. |
| Gaun pengantin seri warna permen Delsa S posa, pink, biru, merah dan ungu, ceria dan segar, apakah Anda menyukainya? | Yang terakhir sangat indah, sangat indah! |
Kami juga menggunakan model yang disempurnakan di atas untuk mendapatkan hasil interaksi berikut:
| Roel | Tanggapan |
|---|---|
| Pengguna | Jangan mencintaiku dengan sia-sia |
| Bot | Cinta tanpa hasil sungguh menyakitkan. |
| Pengguna | Tapi tidak apa-apa jika Anda menyukainya |
| Bot | Terkadang, cinta adalah sebuah permainan. |
| Pengguna | Saya selalu kalah |
| Bot | Aku mencintaimu sama seperti aku mencintaimu. |
| Pengguna | Bisakah kamu menariknya? |
| Bot | Anda bisa menariknya. |
| Pengguna | Jangan meniru saya |
| Bot | Apa yang saya katakan adalah Anda tidak bisa melakukannya. |
| Pengguna | Anda memaksa saya untuk melakukannya, bukan? |
| Bot | Tidak, saya memaksamu untuk berbicara, bukan? |
Yida Wang, Pei Ke, Yinhe Zheng, Kaili Huang, Yong Jiang, Xiaoyan Zhu, Minlie Huang
Zuoxian Ye, Yao Wang, Yifan Pan
Kumpulan data LCCC dan model dialog terlatih yang disediakan oleh proyek ini hanya untuk tujuan penelitian ilmiah. Percakapan dalam kumpulan data LCCC dikumpulkan dari berbagai sumber. Meskipun kami telah merancang proses pembersihan data yang ketat, kami tidak menjamin bahwa semua konten yang tidak pantas telah disaring. Semua konten dan opini yang terkandung dalam data ini adalah independen dari penulis proyek ini. Model dan kode yang disediakan dalam proyek ini hanyalah komponen dari keseluruhan sistem dialog. Skrip decoding yang kami sediakan hanya untuk tujuan penelitian ilmiah. Semua konten dialog yang dihasilkan menggunakan model dan skrip dalam proyek ini tidak ada hubungannya dengan penulis proyek ini.
Jika Anda merasa proyek kami bermanfaat, silakan kutip makalah kami:
@inproceedings{wang2020chinese,
title={A Large-Scale Chinese Short-Text Conversation Dataset},
author={Wang, Yida and Ke, Pei and Zheng, Yinhe and Huang, Kaili and Jiang, Yong and Zhu, Xiaoyan and Huang, Minlie},
booktitle={NLPCC},
year={2020},
url={https://arxiv.org/abs/2008.03946}
}
Proyek ini menyediakan kumpulan data percakapan berbahasa Mandarin berskala besar dan model GPT berbahasa Mandarin yang telah dilatih sebelumnya pada kumpulan data ini. Silakan merujuk ke makalah kami untuk detail selengkapnya.
Kode yang kami gunakan untuk pra-pelatihan diadaptasi dari model TransferTransfo berdasarkan perpustakaan Transformers. Kode yang digunakan untuk pra-pelatihan dan penyesuaian disediakan di repositori ini.
Kami mempersembahkan korpus Percakapan Cina Bersih Berskala Besar (LCCC) yang berisi: LCCC-base (Baidu Netdisk, Google Drive) dan LCCC-large (Baidu Netdisk, Google Drive). corpus. Pipeline ini melibatkan seperangkat aturan dan beberapa filter berbasis pengklasifikasi. Suara-suara seperti kata-kata yang menyinggung atau sensitif, simbol khusus, emoji, kalimat yang salah secara tata bahasa, dan percakapan yang tidak koheren tersaring.
Statistik korpus kami disajikan di bawah ini. Dialog dengan hanya dua ucapan dianggap sebagai "Satu putaran", dan dialog dengan lebih dari tiga ucapan dianggap sebagai "Banyak putaran". Ukuran kosakata dihitung dalam tingkat kata, dan Jieba digunakan untuk menandai setiap ucapan menjadi kata-kata.
| Basis LCCC (Baidu Netdisk, Google Drive) | Putaran tunggal | Multi-putaran |
|---|---|---|
| Sesi | 3.354.382 | 3.466.607 |
| Ucapan | 6.708.554 | 13.365.268 |
| Karakter | 68.559.727 | 163.690.614 |
| Kosakata | 372.063 | 666.931 |
| Rata-rata kata per ucapan | 6.79 | 8.32 |
| Rata-rata ucapan per sesi | 2 | 3.86 |
Perhatikan bahwa basis LCCC dibersihkan menggunakan aturan yang lebih ketat dibandingkan dengan basis LCCC besar.
| LCCC-besar (Baidu Netdisk, Google Drive) | Putaran tunggal | Multi-putaran |
|---|---|---|
| Sesi | 7.273.804 | 4.733.955 |
| Ucapan | 14.547.608 | 18.341.167 |
| Karakter | 162.301.556 | 217.776.649 |
| Kosakata | 662.514 | 690.027 |
| Rata-rata kata per ucapan | 7.45 | 8.14 |
| Rata-rata ucapan per sesi | 2 | 3.87 |
Dialog mentah untuk LCCC-base berasal dari Weibo Corpus yang kami jelajahi dari Weibo, dan dialog mentah untuk LCCC-large dibuat dengan menggabungkan beberapa kumpulan data percakapan selain Weibo Corpus:
| Kumpulan data | Sesi | Mencicipi |
|---|---|---|
| Korpus Weibo | 79M | Q: Saya makan hot pot tujuh atau delapan kali di Chengdu, Chongqing. A: Hahahaha! Maka mulutku mungkin membusuk! |
| Korpus Gosip PTT | 0,4 juta | T: Mengapa penduduk desa selalu menindas siswa sekolah menengah? QQ A: Jika Anda berpikir bahwa jika Anda memilih mata pelajaran yang bagus, Anda akan menjadi Bill Gates, sebaiknya Anda putus sekolah. |
| Subjudul Corpus | 2,74 juta | T: Orang-orang di opera Beijing tidak bebas. A: Mereka mengurung orang. |
| Korpus Xiaohuangji | 0,45 juta | Q: Pernahkah kamu jatuh cinta? A: Pernahkah kamu jatuh cinta? Oh, jangan sebutkan itu, aku sedih... |
| Korps Tieba | 2,32 juta | Q: Barisan depan, semua fans Lu bangun kan? A: Judulnya mengatakan assist, tapi setelah menonton bola itu, itu benar-benar sebuah ironi yang hidup. |
| Korps Qingyun | 0,1 juta | Q: Sepertinya kamu sangat menyukai uang. A: Oh, benarkah? Maka Anda hampir sampai |
| Korpus Percakapan Douban | 0,5 juta | Q: Belajar bahasa Inggris murni dengan menonton film berbahasa Inggris asli A: Aku suka Friends dan sudah menontonnya berkali-kali Q: Aku hampir kelelahan menonton CD yang sama A: Kalau begitu, seharusnya bahasa Inggrismu sudah cukup bagus sekarang |
| Korpus Percakapan E-komersial | 0,5 juta | Q: Apakah ini akan menjadi penawaran yang bagus? A: Belum. Q: Apakah ini akan tersedia di masa depan? A: Tidak yakin. |
| Corpus Obrolan Cina | 0,5 juta | Q: Kakiku tidak berguna hari ini. Kalian sedang merayakan liburan, jadi aku akan memindahkan batu bata. A: Ini kerja keras. Aku bahkan ingin menghasilkan banyak uang di hari Natal belum punya pacar, jadi liburan apa pun sama saja. |
Kami juga menyajikan serangkaian model GPT Tiongkok yang pertama kali dilatih sebelumnya pada kumpulan data baru Tiongkok dan kemudian dilatih pasca pada kumpulan data LCCC kami.
Mirip dengan TransferTransfo, kami menggabungkan semua riwayat dialog ke dalam satu kalimat konteks, dan menggunakan kalimat ini untuk memprediksi respons. Masukan model kami terdiri dari penyematan kata, penyematan pembicara, dan penyematan posisi setiap kata.
| Model | Ukuran Parameter | Kumpulan Data Pra-pelatihan | Keterangan |
|---|---|---|---|
| Novel GPT | 95,5 juta | Novel Cina | Model GPT yang telah dilatih sebelumnya pada kumpulan data Novel China (1,3 miliar kata, perhatikan bahwa kami tidak memberikan detail model ini) |
| CDial-GPT berbasis LCCC | 95,5 juta | Basis LCCC | Model GPT pasca pelatihan tentang kumpulan data berbasis LCCC dari GPT Novel |
| Basis LCCC CDial-GPT2 | 95,5 juta | Basis LCCC | Model GPT2 pasca pelatihan tentang kumpulan data berbasis LCCC dari GPT Novel |
| CDial-GPT LCCC-besar | 95,5 juta | LCCC-besar | Model GPT pasca pelatihan pada kumpulan data besar LCCC dari GPT Novel |
Instal dari kode sumber:
git clone https://github.com/thu-coai/CDial-GPT.git
cd CDial-GPT
pip install -r requirements.txt
Langkah 1: Siapkan data untuk penyesuaian (Misalnya, kumpulan data STC atau "data/toy_data.json" di repositori kami) dan model pra-uji coba:
# Download the STC dataset and unzip into "data_path" dir (fine-tuning on STC)
git lfs install
git clone https://huggingface.co/thu-coai/CDial-GPT_LCCC-large # or OpenAIGPTLMHeadModel.from_pretrained("thu-coai/CDial-GPT_LCCC-large")
ps: Anda dapat mendownload train dan split STC yang valid dari link berikut: (Baidu Netdisk, Google Drive)
Langkah 2: Latih modelnya
python train.py --pretrained --model_checkpoint thu-coai/CDial-GPT_LCCC-large --data_path data/STC.json --scheduler linear # Single GPU training
atau
python -m torch.distributed.launch --nproc_per_node=8 train.py --pretrained --model_checkpoint thu-coai/CDial-GPT_LCCC-large --data_path data/STC.json --scheduler linear # Training on 8 GPUs
Catatan: Kami juga telah menyediakan argumen train_path dalam skrip pelatihan untuk membaca kumpulan data dalam teks biasa, yang akan dipotong dan ditangani secara terdistribusi. Anda dapat mempertimbangkan untuk menggunakan argumen ini jika kumpulan data terlalu besar untuk memori sistem Anda (juga, ingatlah untuk membiarkan argumen data_path kosong jika Anda menggunakan train_path ).
Langkah 3: Mode inferensi
# YOUR_MODEL_PATH: the model path used for generation
python infer.py --model_checkpoint YOUR_MODEL_PATH --datapath data/STC_test.json --out_path STC_result.txt # Do Inference on a corpus
python interact.py --model_checkpoint YOUR_MODEL_PATH # Interact on the terminal
ps: Anda dapat mendownload test split STC dari link berikut: (Baidu Netdisk, Google Drive)
Argumen Pelatihan
| Argumen | Jenis | Nilai bawaan | Keterangan |
|---|---|---|---|
| model_pos pemeriksaan | str | "" | Jalur atau URL file model (Direktori model pra-pelatihan dan file konfigurasi/vocab) |
| terlatih | bodoh | PALSU | Jika Salah, latih modelnya dari awal |
| jalur_data | str | "" | Jalur kumpulan data |
| kumpulan data_cache | str | default="kumpulan data_cache" | Jalur atau url cache kumpulan data |
| jalur_kereta | str | "" | Jalur kumpulan pelatihan untuk kumpulan data terdistribusi |
| jalur_valid | str | "" | Jalur kumpulan validasi untuk kumpulan data terdistribusi |
| log_file | str | "" | Keluaran log ke file di bawah jalur ini |
| jumlah_pekerja | ke dalam | 1 | Jumlah subproses untuk memuat data |
| n_zaman | ke dalam | 70 | Jumlah periode pelatihan |
| train_batch_size | ke dalam | 8 | Ukuran batch untuk pelatihan |
| valid_batch_size | ke dalam | 8 | Ukuran batch untuk validasi |
| max_history | ke dalam | 15 | Jumlah pertukaran sebelumnya yang perlu disimpan dalam sejarah |
| penjadwal | str | "noam" | Metode pengoptimal |
| n_emd | ke dalam | 768 | Jumlah n_emd di file konfigurasi (untuk noam) |
| eval_before_start | bodoh | PALSU | Jika benar, mulailah evaluasi sebelum pelatihan |
| pemanasan_langkah | ke dalam | 5000 | Langkah pemanasan |
| langkah_valid | ke dalam | 0 | Lakukan validasi setiap X langkah, jika bukan 0 |
| gradien_akumulasi_langkah | ke dalam | 64 | Akumulasi gradien pada beberapa langkah |
| max_norm | mengambang | 1.0 | Memotong norma gradien |
| perangkat | str | "cuda" jika torch.cuda.is_available() lain "cpu" | Perangkat (cuda atau cpu) |
| fp16 | str | "" | Atur ke O0, O1, O2 atau O3 untuk pelatihan fp16 (lihat dokumentasi apex) |
| peringkat_lokal | ke dalam | -1 | Peringkat lokal untuk pelatihan terdistribusi (-1: tidak terdistribusi) |
Evaluasi dilakukan terhadap hasil yang dihasilkan oleh model yang disempurnakan
Dataset STC (Train/Valid split (Baidu Netdisk, Google Drive), Test split (Baidu Netdisk, Google Drive)). Semua respons dihasilkan menggunakan skema Nucleus Sampling dengan ambang batas 0,9 dan suhu 0,7.
| Model | Ukuran Model | PPL | BIRU-2 | BIRU-4 | Distrik-1 | Distrik-2 | Pencocokan Serakah | Rata-rata Penyematan |
|---|---|---|---|---|---|---|---|---|
| Attn-Seq2seq | 73M | 34.20 | 3.93 | 0,90 | 8.5 | 11.91 | 65.84 | 83.38 |
| Transformator | 113M | 22.10 | 6.72 | 3.14 | 8.8 | 13.97 | 66.06 | 83,55 |
| GPT2-ngobrol | 88M | - | 2.28 | 0,54 | 10.3 | 16.25 | 61.54 | 78,94 |
| Novel GPT | 95,5 juta | 21.27 | 5.96 | 2.71 | 8.0 | 11.72 | 66.12 | 83.34 |
| berbasis GPT LCCC | 95,5 juta | 18.38 | 6.48 | 3.08 | 8.3 | 12.68 | 66.21 | 83.54 |
| Basis GPT2 LCCC | 95,5 juta | 22.76 | 5.69 | 2.50 | 7.7 | 10.87 | 66.24 | 83.46 |
| GPT LCCC-besar | 95,5 juta | 18.23 | 6.63 | 3.20 | 8.3 | 12.71 | 66.25 | 83.63 |
Kami juga mempekerjakan 3 anotator bersumber dari banyak orang untuk mengevaluasi 200 sampel dari setiap model tentang kelancaran, relevansi, dan keragaman berdasarkan skema skor 2/1/0. Lihat makalah kami untuk detail selengkapnya.
| Model | +2 | +1 | +0 | Kappa |
|---|---|---|---|---|
| Attn-Seq2Seq | 27,1% | 21,4% | 51,4% | 0,4544 |
| Transformator | 42,4% | 23,6% | 34,0% | 0,4429 |
| GPT2-ngobrol | 24,3% | 19,1% | 56,6% | 0,3941 |
| berbasis GPT LCCC | 46,7% | 21,8% | 31,5% | 0,3954 |
| GPT LCCC-besar | 48,6% | 24,5% | 27,0% | 0,4203 |
Kami secara acak memilih 1000 sampel yang dihasilkan, dan membuat statistik pembentukan racun:
| Pengulangan | Kata kotor | Kasus Buruk Lainnya |
|---|---|---|
| dua puluh tiga | 9 | 2 |
Contoh yang dihasilkan satu putaran dari kumpulan data STC (disesuaikan di STC):
| Pos | Tanggapan |
|---|---|
| Ini sebenarnya Beijing, bukan Harbin. | Cuaca di Harbin tampaknya lebih baik daripada di Beijing. Hujan ringan di sini dan angin kencang di siang hari. |
| Kompetisi periklanan kampus operator sangat menyenangkan! Ha ha ha. | Saya pikir itu iklan Jack Ma. |
| Gaun pengantin seri warna permen Delsa S posa, pink, biru, merah dan ungu, ceria dan segar, apakah Anda menyukainya? | Yang terakhir sangat indah, sangat indah! |
Contoh yang dihasilkan multi-putaran menggunakan skrip interaktif:
| Roel | Tanggapan |
|---|---|
| Pengguna | Jangan mencintaiku dengan sia-sia |
| Bot | Cinta tanpa hasil sungguh menyakitkan. |
| Pengguna | Tapi tidak apa-apa jika Anda menyukainya |
| Bot | Terkadang, cinta adalah sebuah permainan. |
| Pengguna | Saya selalu kalah |
| Bot | Aku mencintaimu sama seperti aku mencintaimu. |
| Pengguna | Bisakah kamu menariknya? |
| Bot | Anda bisa menariknya. |
| Pengguna | Jangan meniru saya |
| Bot | Apa yang saya katakan adalah Anda tidak bisa melakukannya. |
| Pengguna | Anda memaksa saya untuk melakukannya, bukan? |
| Bot | Tidak, saya memaksamu untuk berbicara, bukan? |
Yida Wang, Pei Ke, Yinhe Zheng, Kaili Huang, Yong Jiang, Xiaoyan Zhu, Minlie Huang
Zuoxian Ye, Yao Wang, Yifan Pan
Kumpulan data LCCC dan model terlatih bertujuan untuk memfasilitasi penelitian untuk menghasilkan percakapan. Kumpulan data LCCC yang disediakan dalam repositori ini berasal dari berbagai sumber. Meskipun proses pembersihan yang ketat telah dilakukan, tidak ada jaminan bahwa semua konten yang tidak pantas ada telah disaring sepenuhnya. Semua konten yang terdapat dalam kumpulan data ini tidak mewakili pendapat penulis. Repositori ini hanya berisi sebagian dari mesin pemodelan yang diperlukan untuk benar-benar menghasilkan model dialog . Kami tidak bertanggung jawab konten apa pun yang dihasilkan menggunakan model kami.
Silakan mengutip makalah kami jika Anda menggunakan kumpulan data atau model dalam penelitian Anda:
@inproceedings{wang2020chinese,
title={A Large-Scale Chinese Short-Text Conversation Dataset},
author={Wang, Yida and Ke, Pei and Zheng, Yinhe and Huang, Kaili and Jiang, Yong and Zhu, Xiaoyan and Huang, Minlie},
booktitle={NLPCC},
year={2020},
url={https://arxiv.org/abs/2008.03946}
}


