Kosmos X
0.0.1

pip3 install --upgrade kosmosx import torch
from kosmosx . model import Kosmos
# Create a sample text token tensor
text_tokens = torch . randint ( 0 , 32002 , ( 1 , 50 ), dtype = torch . long )
# Create a sample image tensor
images = torch . randn ( 1 , 3 , 224 , 224 )
# Instantiate the model
model = Kosmos ()
text_tokens = text_tokens . long ()
# Pass the sample tensors to the model's forward function
output = model . forward (
text_tokens = text_tokens ,
images = images
)
# Print the output from the model
print ( f"Output: { output } " ) Tetapkan konfigurasi Anda dengan: accelerate config lalu: accelerate launch train.py
KOSMOS-1 menggunakan arsitektur Transformer khusus decoder berdasarkan Magneto (Foundation Transformers), yaitu arsitektur yang menggunakan pendekatan sub-LN di mana normalisasi lapisan ditambahkan sebelum modul perhatian (pra-ln) dan setelahnya (pasca-ln) ln) menggabungkan keunggulan masing-masing pendekatan untuk pemodelan bahasa dan pemahaman gambar. Model ini juga diinisialisasi berdasarkan metrik tertentu yang juga dijelaskan dalam makalah, memungkinkan pelatihan yang lebih stabil dengan kecepatan pembelajaran yang lebih tinggi.
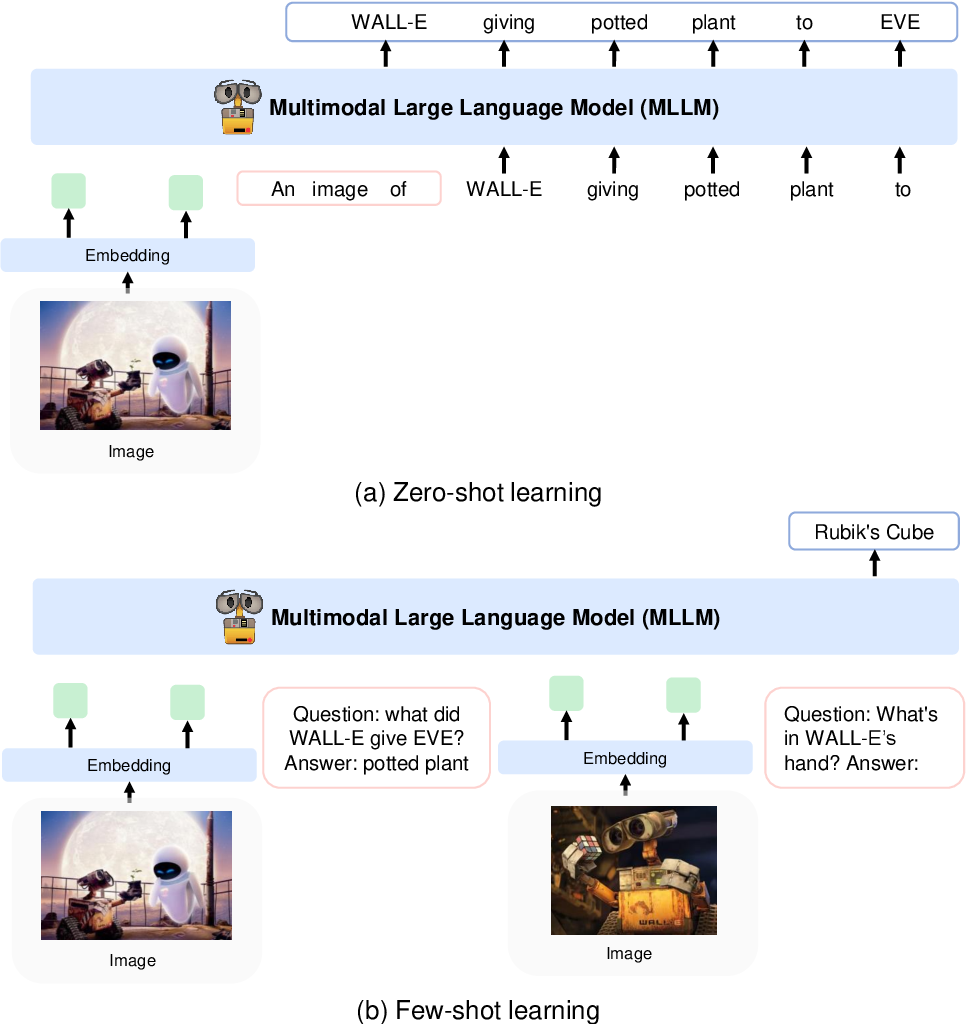
Mereka mengkodekan gambar ke fitur gambar menggunakan model CLIP VIT-L/14 dan menggunakan resampler persepsi yang diperkenalkan di Flamingo untuk menggabungkan fitur gambar dari 256 -> 64 token. Fitur gambar digabungkan dengan penyematan token dengan menambahkannya ke urutan masukan yang dikelilingi oleh token khusus <image> dan </image> . Contohnya adalah <s> <image> image_features </image> text </s> . Hal ini memungkinkan gambar terjalin dengan teks dalam urutan yang sama.
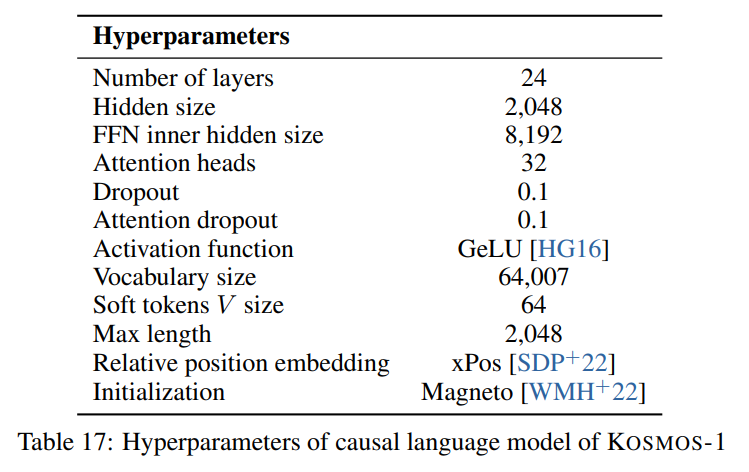
Kami mengikuti hyperparameter yang dijelaskan di makalah yang terlihat pada gambar berikut:
Kami menggunakan implementasi torchscale dari arsitektur Transformer khusus dekoder dari Foundation Transformers:
from torchscale . architecture . config import DecoderConfig
from torchscale . architecture . decoder import Decoder
config = DecoderConfig (
decoder_layers = 24 ,
decoder_embed_dim = 2048 ,
decoder_ffn_embed_dim = 8192 ,
decoder_attention_heads = 32 ,
dropout = 0.1 ,
activation_fn = "gelu" ,
attention_dropout = 0.1 ,
vocab_size = 32002 ,
subln = True , # sub-LN approach
xpos_rel_pos = True , # rotary positional embeddings
max_rel_pos = 2048
)
decoder = Decoder (
config ,
embed_tokens = embed ,
embed_positions = embed_positions ,
output_projection = output_projection
)Untuk model gambar (CLIP VIT-L/14) kami menggunakan model OpenClip yang telah dilatih sebelumnya:
from transformers import CLIPModel
clip_model = CLIPModel . from_pretrained ( "laion/CLIP-ViT-L-14-laion2B-s32B-b82K" ). vision_model
# projects image to [batch_size, 256, 1024]
features = clip_model ( pixel_values = images )[ "last_hidden_state" ]Kami mengikuti hyperparam default untuk resampler persepsi karena tidak ada hyperparam yang diberikan di makalah:
from flamingo_pytorch import PerceiverResampler
perceiver = PerceiverResampler (
dim = 1024 ,
depth = 2 ,
dim_head = 64 ,
heads = 8 ,
num_latents = 64 ,
num_media_embeds = 256
)
# projects image features to [batch_size, 64, 1024]
self . perceive ( images ). squeeze ( 1 ) Karena model mengharapkan dimensi tersembunyi sebesar 2048 , kami menggunakan lapisan nn.Linear untuk memproyeksikan fitur gambar ke dimensi yang benar dan menginisialisasinya sesuai dengan skema inisialisasi Magneto:
image_proj = torch . nn . Linear ( 1024 , 2048 , bias = False )
torch . nn . init . normal_ (
image_proj . weight , mean = 0 , std = 2048 ** - 0.5
)
scaled_image_features = image_proj ( image_features ) Makalah ini menjelaskan SentencePiece dengan kosakata 64007 token. Untuk mempermudah (karena kami tidak memiliki korpus pelatihan), kami menggunakan alternatif sumber terbuka terbaik berikutnya yaitu tokenizer besar T5 yang telah dilatih sebelumnya dari HuggingFace. Tokenizer ini memiliki kosakata 32002 token.
from transformers import T5Tokenizer
tokenizer = T5Tokenizer . from_pretrained (
"t5-large" ,
additional_special_tokens = [ "<image>" , "</image>" ],
extra_ids = 0 ,
model_max_length = 1984 # 2048 - 64 (image features)
) Kami kemudian menyematkan token dengan lapisan nn.Embedding . Kami sebenarnya menggunakan bnb.nn.Embedding dari bitandbytes yang memungkinkan kami menggunakan AdamW 8-bit nanti.
import bitsandbytes as bnb
embed = bnb . nn . Embedding (
32002 , # Num embeddings
2048 , # Embedding dim
padding_idx
)Untuk penyematan posisi, kami menggunakan:
from torchscale . component . embedding import PositionalEmbedding
embed_positions = PositionalEmbedding (
2048 , # Num embeddings
2048 , # Embedding dim
padding_idx
)Selain itu, kami menambahkan lapisan proyeksi keluaran untuk memproyeksikan dimensi tersembunyi ke ukuran kosakata dan menginisialisasinya sesuai dengan skema inisialisasi Magneto:
output_projection = torch . nn . Linear (
2048 , 32002 , bias = False
)
torch . nn . init . normal_ (
output_projection . weight , mean = 0 , std = 2048 ** - 0.5
) Saya harus membuat sedikit perubahan pada dekoder agar dapat menerima fitur yang sudah tertanam di forward pass. Hal ini diperlukan untuk memungkinkan urutan masukan yang lebih kompleks seperti dijelaskan di atas. Perubahannya terlihat pada perbedaan berikut pada baris 391 torchscale/architecture/decoder.py :
+ if kwargs.get("passed_x", None) is None:
+ x, _ = self.forward_embedding(
+ prev_output_tokens, token_embeddings, incremental_state
+ )
+ else:
+ x = kwargs["passed_x"]
- x, _ = self.forward_embedding(
- prev_output_tokens, token_embeddings, incremental_state
- )Berikut adalah tabel penurunan harga dengan metadata untuk kumpulan data yang disebutkan di makalah:
| Kumpulan data | Keterangan | Ukuran | Link |
|---|---|---|---|
| Tumpukan | Korpus teks bahasa Inggris yang beragam | 800GB | wajah berpelukan |
| Perayapan Umum | Data perayapan web | - | Perayapan Umum |
| LAION-400M | Pasangan gambar-teks dari Common Crawl | 400 juta pasang | wajah berpelukan |
| LAION-2B | Pasangan gambar-teks dari Common Crawl | pasangan 2B | ArXiv |
| COYO | Pasangan gambar-teks dari Common Crawl | 700 juta pasang | Github |
| Keterangan Konseptual | Pasangan teks gambar-alt | 15 juta pasang | ArXiv |
| Data CC yang disisipkan | Teks dan gambar dari Common Crawl | 71 juta dokumen | Kumpulan data khusus |
| CeritaCloze | Alasan yang masuk akal | 16k contoh | Antologi ACL |
| HellaSwag | NLI yang masuk akal | 70 ribu contoh | ArXiv |
| Skema Winograd | Ambiguitas kata | 273 contoh | PKRR 2012 |
| Winogrande | Ambiguitas kata | 1,7 ribu contoh | AAAI 2020 |
| PIQA | QA akal sehat fisik | 16k contoh | AAAI 2020 |
| BoolQ | QA | 15k contoh | ACL 2019 |
| CB | Inferensi bahasa alami | 250 contoh | Sinn dan Bedeutung 2019 |
| KOPA | Alasan kausal | 1k contoh | Simposium Musim Semi AAAI 2011 |
| Ukuran Relatif | Alasan yang masuk akal | 486 pasang | ArXiv 2016 |
| Warna Memori | Alasan yang masuk akal | 720 contoh | ArXiv 2021 |
| Ketentuan Warna | Alasan yang masuk akal | 320 contoh | ACL 2012 |
| Tes IQ | Alasan nonverbal | 50 contoh | Kumpulan data khusus |
| Keterangan COCO | Keterangan gambar | 413 ribu gambar | PAM 2015 |
| Flickr30k | Keterangan gambar | 31 ribu gambar | TACL 2014 |
| VQAv2 | QA visual | 1 juta pasangan QA | CVPR 2017 |
| VizWiz | QA visual | 31k pasangan QA | CVPR 2018 |
| WebSRC | QA Web | 1.4k contoh | EMNLP 2021 |
| GambarNet | Klasifikasi gambar | 1,28 juta gambar | CVPR 2009 |
| ANAK | Klasifikasi gambar | 200 spesies burung | TOG 2011 |
APACHE


