ComfyUI N Nodes
1.0.0
Serangkaian node khusus untuk ComfyUI yang mencakup node variabel Integer, string dan float, node GPT, dan node video.
Penting
Node ini diuji terutama di Windows di lingkungan default yang disediakan oleh ComfyUI dan di lingkungan yang dibuat oleh notebook untuk paperspace khusus dengan gambar buruh pelabuhan cyberes/gradient-base-py3.10:latest. Lingkungan lain mana pun belum diuji.
Kloning repositori: git clone https://github.com/Nuked88/ComfyUI-N-Nodes.git
ke direktori custom_nodes ComfyUI Anda
PENTING: Jika Anda ingin node GPT di GPU, Anda harus menjalankan install_dependency bat files . Ada 2 versi: install_dependency_ggml_models.bat untuk model ggmlv3 lama dan install_dependency_gguf_models.bat untuk semua model baru (GGUF). ANDA HANYA BISA MENGGUNAKAN SALAH SATU SATU SATU! Karena llama-cpp-python perlu dikompilasi dari kode sumber agar dapat menggunakan GPU, Anda harus terlebih dahulu menginstal CUDA dan visual studio 2019 atau 2022 (dalam kasus kelelawar saya) untuk mengkompilasinya. Untuk detail dan panduan lengkapnya Anda bisa buka DI SINI.
Jika Anda ingin menggunakan GPTLoaderSimple dengan model Moondream, Anda harus menjalankan skrip 'install_extra.bat', yang akan menginstal transformator versi 4.36.2.
Nyalakan ulang ComfyUI
Jika Anda perlu mengembalikan perubahan ini (karena ketidakcocokan dengan node lain), Anda dapat menggunakan skrip 'remove_extra.bat'.
ComfyUI akan secara otomatis memuat semua skrip dan node khusus saat startup.
Catatan
Instalasi llama-cpp-python akan dilakukan secara otomatis oleh skrip. Jika Anda memiliki GPU NVIDIA TIDAK PERLU BUILD CUDA LAGI berkat repo jllllll. Saya juga menghentikan dukungan untuk model GGMLv3 karena semua model terkenal seharusnya sudah beralih ke versi terbaru GGUF sekarang.
Catatan
Sejak 14/02/2024, node tersebut telah mengalami penulisan ulang besar-besaran, yang juga menyebabkan perubahan semua nama node untuk menghindari konflik dengan ekstensi lain di masa mendatang (atau setidaknya saya berharap demikian). Akibatnya, alur kerja lama tidak lagi kompatibel dan memerlukan penggantian setiap node secara manual. Untuk menghindari hal ini, saya telah membuat alat yang memungkinkan penggantian otomatis. Di Windows, cukup seret alur kerja *.json apa pun ke file migrasi.bat yang terletak di (custom_nodes/ComfyUI-N-Nodes), dan alur kerja lain dengan akhiran _migrated akan dibuat di folder yang sama dengan alur kerja saat ini. Di Linux, Anda dapat menggunakan skrip dengan cara berikut: python libs/migrate.py path/to/original/workflow/. Demi alasan keamanan, alur kerja asli tidak akan dihapus." Untuk menginstal versi terakhir repositori ini sebelum perubahan ini dari Comfyui-N-Suite, jalankan git checkout 29b2e43baba81ee556b2930b0ca0a9c978c47083
ComfyUI-N-Nodes di custom_nodescomfyui-n-nodes di ComfyUIwebextensionsn-styles.csv dan n-styles.csv.backup di ComfyUIstylesGPTcheckpoints di ComfyUImodelscustom_nodes/ComfyUI-N-Nodesgit pull
Node LoadVideoAdvanced memungkinkan memuat file video dan mengekstraksi frame darinya. Nama telah diubah dari LoadVideo menjadi LoadVideoAdvanced untuk menghindari konflik dengan node animasi LoadVideo .
video : Pilih file video yang akan dimuat.framerate : Pilih apakah akan mempertahankan framerate asli atau mengurangi kecepatan menjadi setengah atau seperempat.resize_by : Pilih cara mengubah ukuran bingkai - 'tidak ada', 'tinggi', atau 'lebar'.size : Ukuran target jika diubah ukurannya berdasarkan tinggi atau lebar.images_limit : Batasi jumlah frame yang akan diekstraksi.batch_size : Ukuran batch untuk frame pengkodean.starting_frame : Pilih frame mana yang akan dimulai.autoplay : Pilih apakah akan memutar video secara otomatis.use_ram : Gunakan RAM sebagai pengganti disk untuk mendekompresi frame video. IMAGES : Gambar bingkai yang diekstraksi sebagai tensor PyTorch.LATENT : Mengosongkan vektor laten.METADATA : Metadata video - FPS dan jumlah frame.WIDTH: Lebar bingkai.HEIGHT : Tinggi bingkai.META_FPS : Kecepatan bingkai.META_N_FRAMES : Jumlah frame.Node mengekstrak frame dari video input pada framerate yang ditentukan. Ini mengubah ukuran bingkai jika dipilih dan mengembalikannya sebagai kumpulan tensor gambar PyTorch bersama dengan vektor laten, metadata, dan dimensi bingkai.
Node SaveVideo mengambil frame yang diekstraksi dan menyimpannya kembali sebagai file video.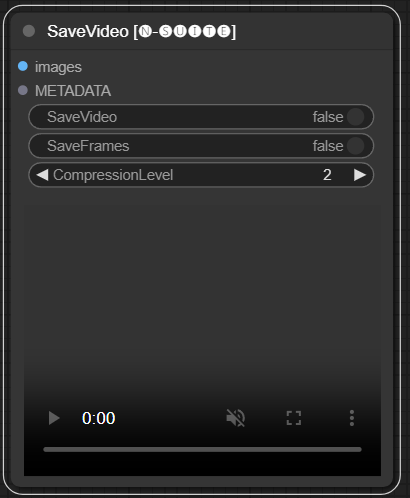
images : Membingkai gambar sebagai tensor.METADATA : Metadata dari node LoadVideo.SaveVideo : Beralih menyimpan file video keluaran.SaveFrames : Beralih menyimpan bingkai ke folder.CompressionLevel : Tingkat kompresi PNG untuk menyimpan bingkai. Menyimpan file video keluaran dan/atau bingkai yang diekstraksi.
Node mengambil frame dan metadata yang diekstraksi dan dapat menyimpannya sebagai file video baru dan/atau gambar frame individual. Kompresi video dan kompresi bingkai PNG dapat dikonfigurasi. CATATAN: Jika Anda menggunakan LoadVideo sebagai sumber frame, audio file asli akan dipertahankan tetapi hanya jika images_limit dan starting_frame sama dengan Nol.
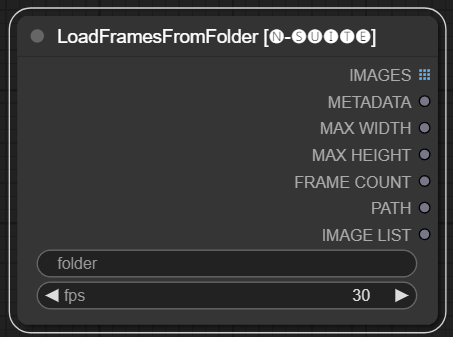
Node LoadFramesFromFolder memungkinkan memuat bingkai gambar dari folder dan mengembalikannya sebagai batch.
folder : Jalur ke folder yang berisi gambar bingkai. Harus berformat png, diberi nama dengan nomor (mis. 1.png atau bahkan 0001.png).Gambar akan dimuat secara berurutan.fps : Bingkai per detik untuk ditetapkan ke bingkai yang dimuat. IMAGES : Kumpulan gambar bingkai yang dimuat sebagai tensor PyTorch.METADATA : Metadata berisi nilai FPS yang ditetapkan.MAX_WIDTH : Lebar bingkai maksimum.MAX_HEIGHT : Tinggi bingkai maksimum.FRAME COUNT : Jumlah frame dalam folder.PATH : Jalur ke folder yang berisi gambar bingkai.IMAGE LIST : Daftar gambar bingkai dalam folder (bukan daftar sebenarnya hanya string dibagi n).Node memuat semua file gambar dari folder yang ditentukan, mengonversinya menjadi tensor PyTorch, dan mengembalikannya sebagai tensor batch bersama dengan metadata sederhana yang berisi nilai FPS yang ditetapkan.
Hal ini memungkinkan dengan mudah memuat sekumpulan frame yang diekstraksi dan disimpan sebelumnya, misalnya, untuk memuat ulang dan memprosesnya lagi. Dengan mengatur nilai FPS, frame dapat diinterpretasikan dengan tepat sebagai rangkaian video.
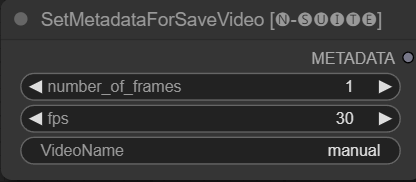
Node SetMetadataForSaveVideo memungkinkan pengaturan metadata untuk node SaveVideo.
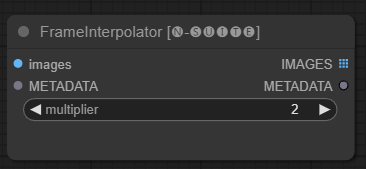
Node FrameInterpolator memungkinkan interpolasi antara frame video yang diekstraksi untuk meningkatkan kecepatan frame dan gerakan halus.
images : Gambar bingkai yang diekstraksi sebagai tensor.METADATA : Metadata dari video - FPS dan jumlah frame.multiplier : Faktor yang digunakan untuk meningkatkan kecepatan bingkai. IMAGES : Bingkai yang diinterpolasi sebagai tensor gambar.METADATA : Metadata yang diperbarui dengan frame rate baru.Node mengambil frame dan metadata yang diekstraksi sebagai masukan. Ia menggunakan model interpolasi (RIFE) untuk menghasilkan frame tambahan di antara frame pada kecepatan frame yang lebih tinggi.
Kecepatan bingkai asli dalam metadata dikalikan dengan nilai multiplier untuk mendapatkan kecepatan bingkai baru yang diinterpolasi.
Bingkai yang diinterpolasi dikembalikan sebagai kumpulan tensor gambar, bersama dengan metadata yang diperbarui yang berisi kecepatan bingkai baru.
Hal ini memungkinkan peningkatan kecepatan bingkai video yang ada untuk mencapai gerakan yang lebih halus dan pemutaran yang lebih lambat. Model interpolasi menciptakan kerangka realistis baru untuk mengisi kesenjangan, bukan hanya menduplikasi kerangka yang sudah ada.
Kode asli diambil dari SINI
Karena node primitif memiliki batasan dalam tautan (misalnya pada saat saya menulis Anda tidak dapat menghubungkan "start_at_step" dan "steps" dari ksampler lain secara bersamaan), saya memutuskan untuk membuat variabel node sederhana ini untuk melewati batasan ini. Node- variabelnya adalah:
Node khusus ini dirancang untuk meningkatkan kemampuan kerangka ConfyUI dengan mengaktifkan pembuatan teks menggunakan model GGUF GPT. README ini memberikan gambaran umum tentang dua node khusus dan penggunaannya dalam ConfyUI.
Anda dapat menambahkan di extra_model_paths.yaml jalur tempat model GGUF Anda berada dengan cara ini (contoh):
other_ui: base_path: I:\text-generation-webui GPTcheckpoints: models/
Jika tidak, folder GPTcheckpoints akan dibuat di folder model ComfyUI tempat Anda dapat menempatkan model .gguf Anda.
Dua folder juga telah dibuat dalam direktori 'Llava' di folder 'GPTcheckpoints' untuk model LLava:
clips : Folder ini ditujukan untuk menyimpan klip untuk model LLava Anda (biasanya, file yang dimulai dengan mm di repositori). models : Folder ini ditujukan untuk menyimpan model LLava.
Node ini sebenarnya mendukung 4 model berbeda:
Model GGUF dapat diunduh dari Huggingface Hub
DI SINI video contoh cara menggunakan model GGUF oleh boricuapab
Berikut daftar kecil model yang didukung oleh node ini:
LlaVa 1.5 7B LlaVa 1.5 13B LlaVa 1.6 Mistral 7B BakLLaVa Nous Hermes 2 Visi
####Contoh dengan model Llava: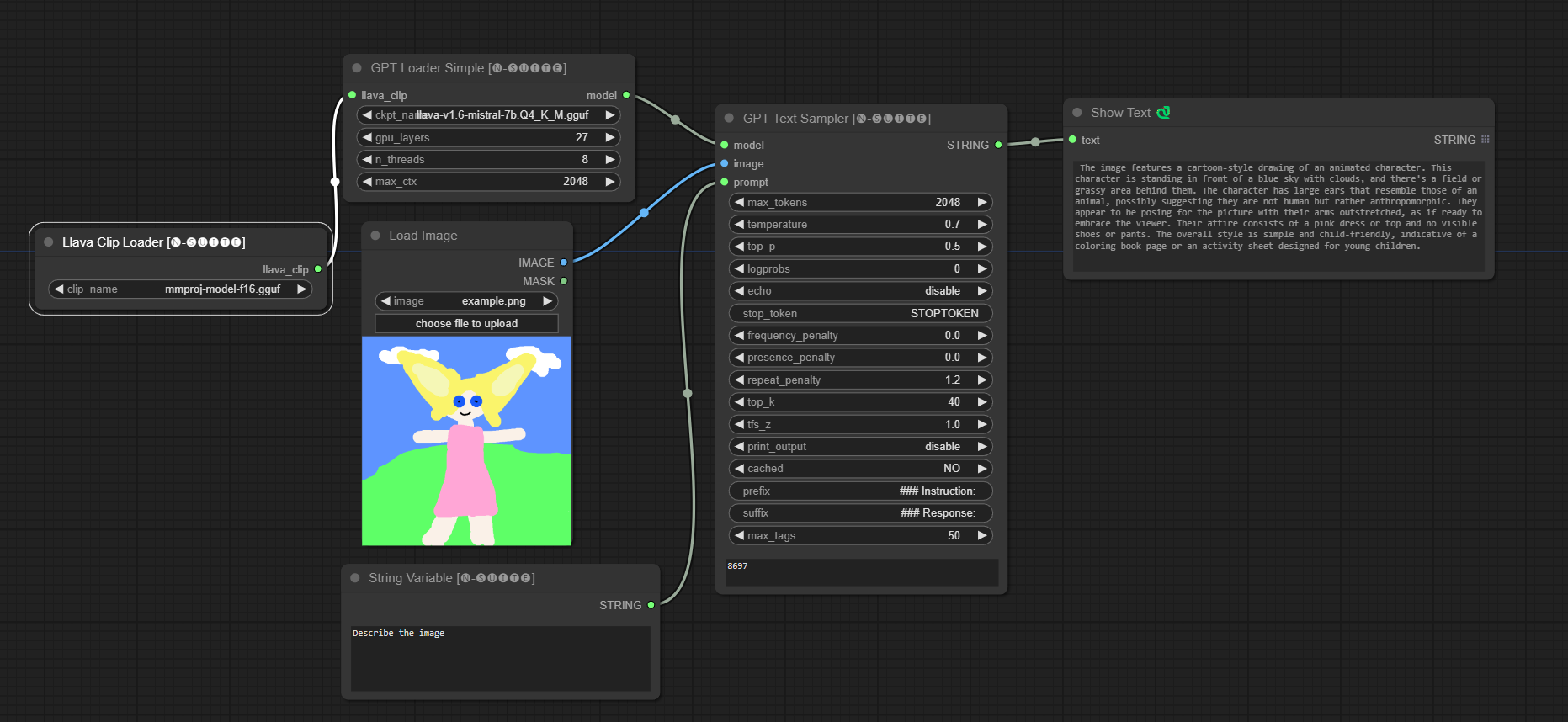
Model akan diunduh secara otomatis saat Anda menjalankannya pertama kali. Bagaimanapun, tersedia DI SINI Kode diambil dari repositori ini
####Contoh dengan model Moondream: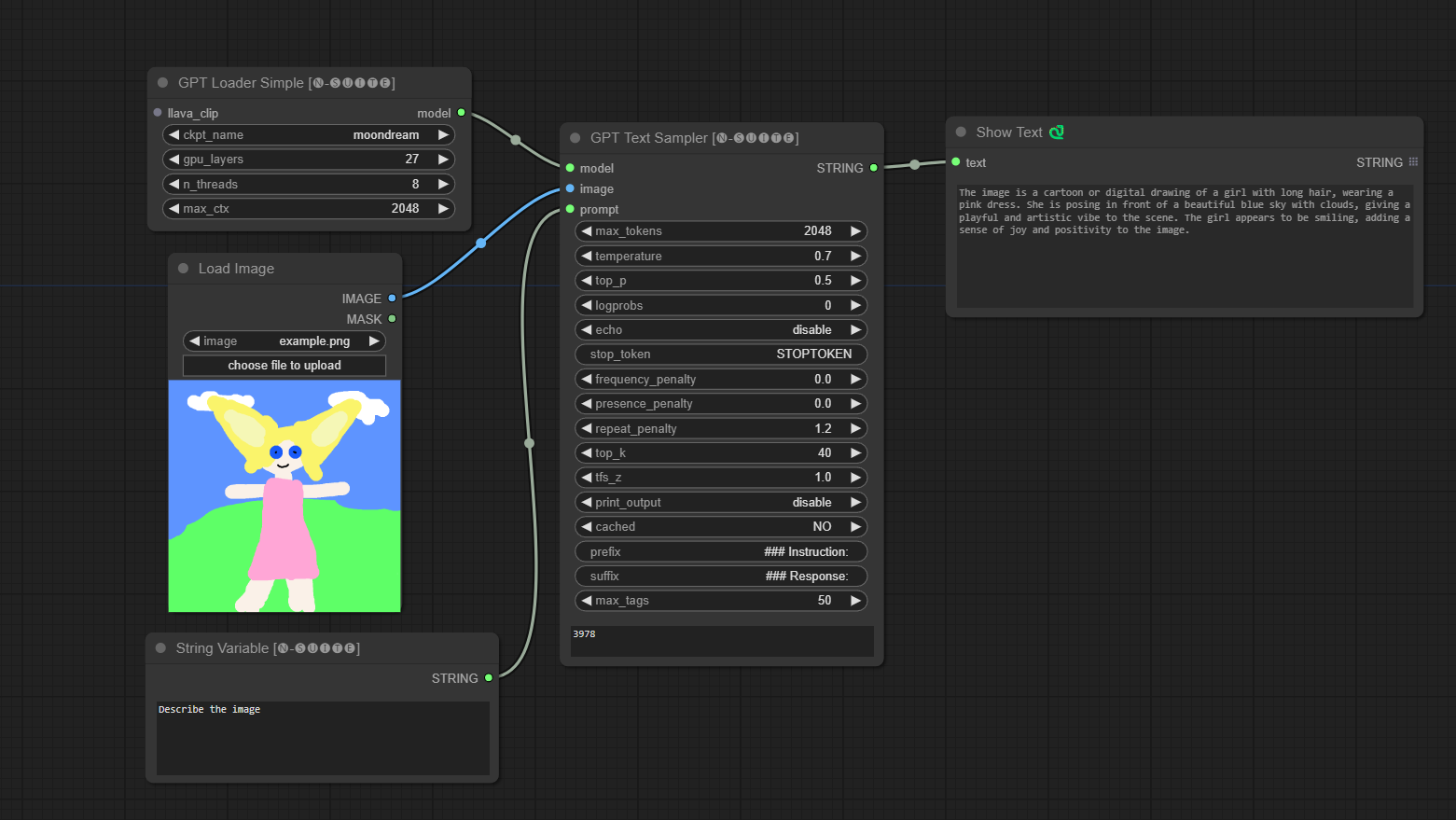
Model akan diunduh secara otomatis saat Anda menjalankannya pertama kali. Bagaimanapun, tersedia DI SINI Kode diambil dari repositori ini
####Contoh dengan model Joytag: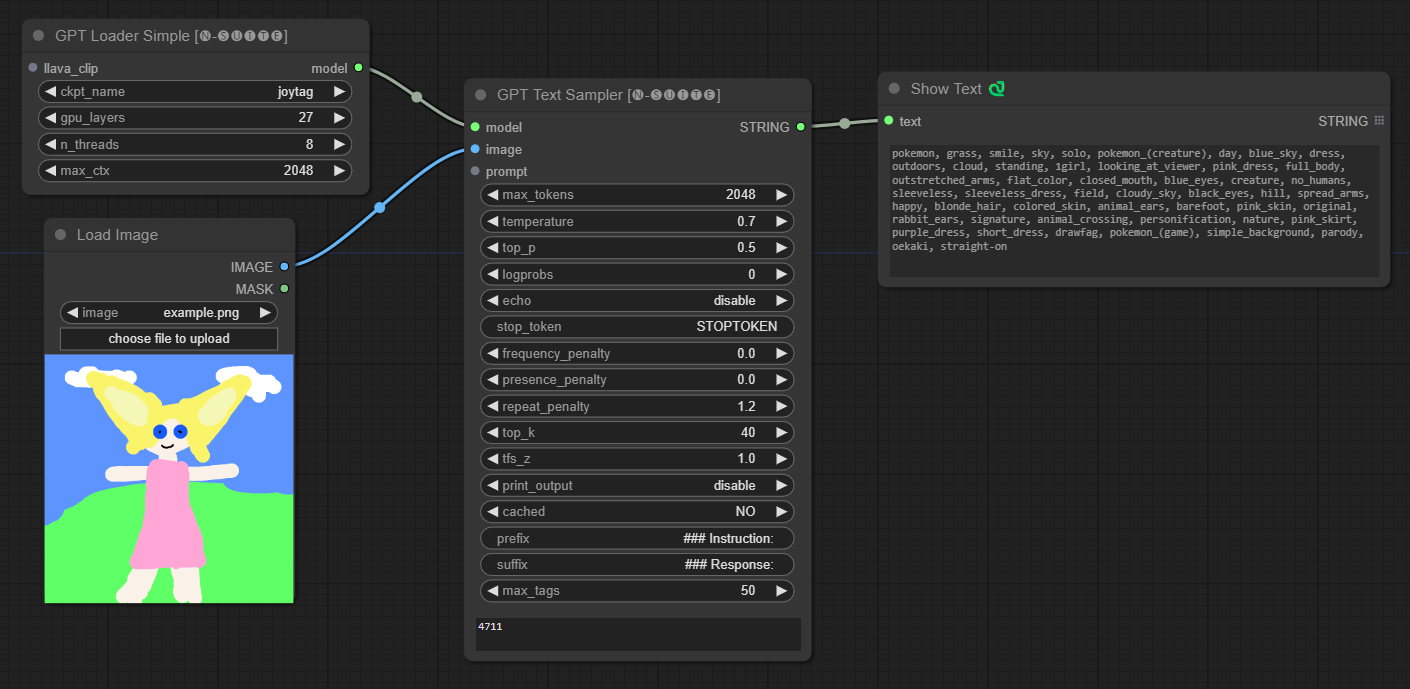
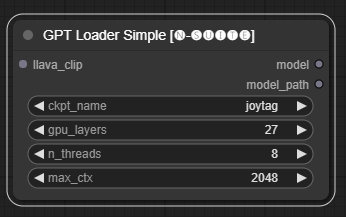
Node GPTLoaderSimple bertanggung jawab untuk memuat pos pemeriksaan model GPT dan membuat instance perpustakaan Llama untuk pembuatan teks. Ini menyediakan antarmuka untuk mengonfigurasi lapisan GPU, jumlah thread, dan konteks maksimum untuk pembuatan teks.
ckpt_name : Pilih nama pos pemeriksaan GPT dari opsi yang tersedia (joytag dan moondream akan diunduh secara otomatis saat pertama kali digunakan).gpu_layers : Tentukan jumlah lapisan GPU yang akan digunakan (default: 27).n_threads : Tentukan jumlah thread untuk pembuatan teks (default: 8).max_ctx : Menentukan panjang konteks maksimum untuk pembuatan teks (default: 2048). Node mengembalikan sebuah instance dari perpustakaan Llama (MODEL) dan jalur ke pos pemeriksaan yang dimuat (STRING).
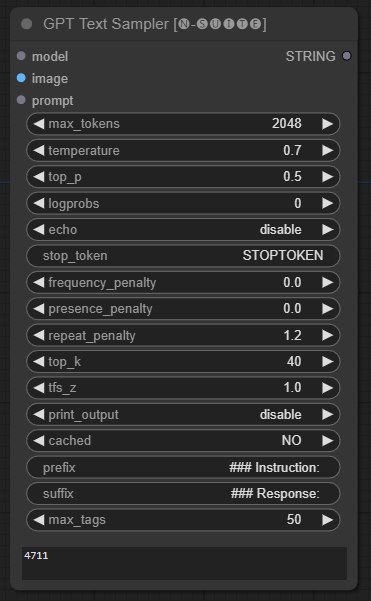
Node GPTSampler memfasilitasi pembuatan teks menggunakan model GPT berdasarkan perintah input dan berbagai parameter pembuatan. Ini memungkinkan Anda mengontrol aspek seperti suhu, pengambilan sampel teratas, penalti, dan banyak lagi.
prompt : Masukkan prompt input untuk pembuatan teks.image : Input gambar untuk model Joytag, moondream, dan llava.model : Pilih model GPT yang akan digunakan untuk pembuatan teks.max_tokens : Tetapkan jumlah maksimum token dalam teks yang dihasilkan (default: 128).temperature : Mengatur parameter suhu untuk keacakan (default: 0.7).top_p : Tetapkan probabilitas p-top untuk pengambilan sampel inti (default: 0,5).logprobs : Tentukan jumlah probabilitas log yang akan dikeluarkan (default: 0).echo : Mengaktifkan atau menonaktifkan pencetakan perintah masukan di samping teks yang dihasilkan.stop_token : Tentukan token tempat pembuatan teks berhenti.frequency_penalty , presence_penalty , repeat_penalty : Mengontrol penalti pembuatan kata.top_k : Tetapkan token teratas untuk dipertimbangkan selama pembuatan (default: 40).tfs_z : Mengatur faktor skala suhu untuk sampel paling sering (default: 1.0).print_output : Mengaktifkan atau menonaktifkan pencetakan teks yang dihasilkan ke konsol.cached : Pilih apakah akan menggunakan pembuatan cache (default: TIDAK).prefix , suffix : Menentukan teks yang akan ditambahkan dan ditambahkan ke prompt.max_tags : Ini hanya mempengaruhi jumlah maksimal tag yang dihasilkan oleh joydag. Node mengembalikan teks yang dihasilkan bersama dengan representasi ramah-UI.
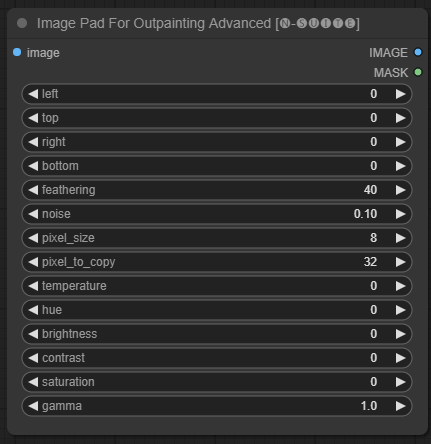
Node ImagePadForOutpaintingAdvanced adalah alternatif dari node ImagePadForOutpainting yang menerapkan teknik yang terlihat dalam video ini di bawah topeng outpainting. Bagian koreksi warna diambil dari node khusus dari Sipherxyz ini
image : masukan gambar.left : piksel untuk diperluas dari kiri,top : piksel untuk diperluas dari atas,right : piksel untuk diperluas dari kanan,bottom : piksel untuk memanjang dari bawah.feathering : kekuatan bulu-bulunoise : memadukan kekuatan dari noise dan batas yang disalinpixel_size : seberapa besar piksel dalam efek pixelatedpixel_to_copy : berapa banyak piksel yang akan disalin (dari setiap sisi)temperature : pengaturan koreksi warna yang hanya diterapkan pada bagian topeng.hue : pengaturan koreksi warna yang hanya diterapkan pada bagian topeng.brightness : pengaturan koreksi warna yang hanya diterapkan pada bagian topeng.contrast : pengaturan koreksi warna yang hanya diterapkan pada bagian topeng.saturation : pengaturan koreksi warna yang hanya diterapkan pada bagian topeng.gamma : pengaturan koreksi warna yang hanya diterapkan pada bagian topeng. Node mengembalikan gambar yang diproses dan topengnya.

Node DynamicPrompt menghasilkan perintah dengan menggabungkan perintah tetap dengan pilihan tag acak dari perintah variabel. Hal ini memungkinkan pembuatan cepat yang fleksibel dan dinamis untuk berbagai kasus penggunaan.
variable_prompt : Masukkan perintah variabel untuk pemilihan tag.cached : Pilih apakah akan menyimpan prompt yang dihasilkan dalam cache (default: TIDAK).number_of_random_tag : Pilih antara "Tetap" dan "Acak" untuk jumlah tag acak yang akan disertakan.fixed_number_of_random_tag : If number_of_random_tag if "Fixed" Tentukan jumlah tag acak yang akan disertakan (default: 1).fixed_prompt (Opsional): Masukkan prompt tetap untuk menghasilkan prompt terakhir. Node mengembalikan prompt yang dihasilkan, yang merupakan kombinasi dari prompt tetap dan tag acak yang dipilih.
variable_prompt dengan tag yang dipisahkan koma, fixed_prompt bersifat opsional 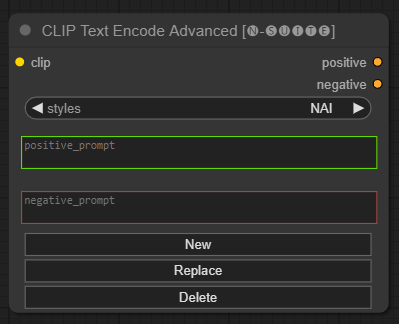
Node CLIP Text Encode Advanced adalah alternatif dari node CLIP Text Encode standar. Ini menawarkan dukungan untuk gaya Tambah/Ganti/Hapus, memungkinkan penyertaan perintah positif dan negatif dalam satu node.
File gaya dasar disebut n-styles.csv dan terletak di folder ComfyUIstyles . File style mengikuti format yang sama dengan file styles.csv saat ini yang digunakan di A1111 (pada saat penulisan).
CATATAN: catatan ini bersifat eksperimental dan masih memiliki banyak bug
clip : masukan klipstyle : secara otomatis akan mengisi petunjuk positif dan negatif berdasarkan gaya yang dipilih positive : kondisi positifnegative : kondisi negatif Jangan ragu untuk berkontribusi pada proyek ini dengan melaporkan masalah atau menyarankan perbaikan. Buka masalah atau kirimkan permintaan penarikan pada repositori GitHub.
Proyek ini dilisensikan di bawah Lisensi MIT. Lihat file LISENSI untuk detailnya.


