ssebowa
1.0.0
Ssebowa adalah pustaka Python sumber terbuka yang menyediakan model AI generatif, termasuk:
ssebowa-llm: Model bahasa besar (LLM) untuk pembuatan teks,ssebowa-vllm: Model bahasa visual (VLLM) untuk pemahaman visual,ssebowa-imagen: Pembuatan gambar dan model penyempurnaan yang disesuaikan,Ssebowa-vigen: Model pembuatan video.Dengan Ssebowa, Anda dapat dengan mudah membuat teks, menerjemahkan bahasa, menulis berbagai jenis konten kreatif, membuat gambar yang dipersonalisasi, dan menjawab pertanyaan Anda dengan cara yang informatif.
Untuk informasi penggunaan lebih rinci, silakan merujuk ke: dokumentasi teknis Ssebowa
Sebelum menjalankan skrip, pastikan perpustakaan yang diperlukan telah diinstal. Anda dapat melakukan ini dengan menjalankan perintah berikut:
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install .Kemudian instal Ssebowa
pip install ssebowaJika Anda menjalankan perintah ini di notebook colab atau jupyter, silakan gunakan ini,
! git clone https://github.com/huggingface/diffusers
! cd diffusers
! pip install .
! pip install ssebowaSekarang, Anda dapat mengakses berbagai model dengan mengimpornya dari perpustakaan:
Ssebowa-Imagen adalah model sintesis gambar sumber terbuka yang memanfaatkan kombinasi diffusion modeling dan generative adversarial networks (GANs) untuk menghasilkan gambar berkualitas tinggi dari text descriptions dan juga memungkinkan untuk mengubah beberapa foto Anda menjadi custom model yang mampu menghasilkan gambar menakjubkan dari chosen subject Anda. Teknologi ini memanfaatkan 100 billion dataset data gambar dan deskripsi teks, sehingga memungkinkannya menangkap secara akurat nuansa citra dunia nyata dan secara efektif menerjemahkan deskripsi teks menjadi representasi visual yang menarik.
10-20 high-quality (jpg or png) seperti milik Anda, teman, produk atau hewan peliharaan, dll dan letakkan di direktori tertentu.16GB or more . (Jika Anda menyempurnakan SDXL, Anda memerlukan VRAM 24 GB.) from ssebowa.dataset import LocalDataset
from ssebowa.model import SdSsebowaModel
from ssebowa.trainer import LocalTrainer
from ssebowa.utils.image_helpers import display_images
from ssebowa.utils.prompt_helpers import make_promptDATA_DIR = " data " # The directory where you put your prepared photos
OUTPUT_DIR = " models " dataset = LocalDataset(DATA_DIR)
dataset = dataset.preprocess_images(detect_face=True)SUBJECT_NAME = " <YOUR-NAME> "
CLASS_NAME = " person " model = SdSsebowaModel(subject_name=SUBJECT_NAME, class_name=CLASS_NAME)
trainer = LocalTrainer(output_dir=OUTPUT_DIR)
predictor = trainer.fit(model, dataset)
# Use the prompt helper to create an awesome AI avatar!
prompt = next(make_prompt(SUBJECT_NAME, CLASS_NAME))
images = predictor.predict(
prompt, height=768, width=512, num_images_per_prompt=2,
)
display_images(images, fig_size=10)
from ssebowa import Ssebowa_imgen
model = Ssebowa_imgen ()Seperti mari kita buat "Seekor kucing duduk di rak buku"
image = model.generate_image( " A cat sitting on a bookshelf " )image.save( " cat_on_bookshelf.jpg " )

Ssebowa-vllm adalah model bahasa visual besar (VLLM) sumber terbuka yang dikembangkan oleh Ssebowa AI. Ini adalah alat yang ampuh yang dapat digunakan untuk memahami gambar. Ssebowa-vllm memiliki 11 miliar parameter visual dan 7 miliar parameter bahasa, mendukung pemahaman gambar pada resolusi 1120*1120.
from ssebowa import ssebowa_vllm
model = ssebowa_vllm ()
response = model.understand(image_path, prompt)
print(response)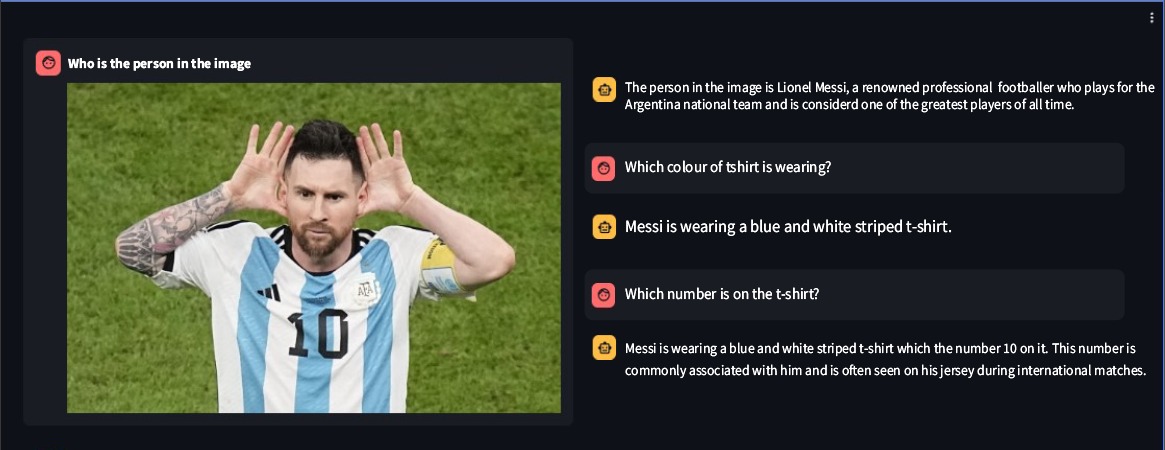
Ssebowa terbuka untuk berkontribusi! Pedoman sedang berjalan..
Ssebowa dirilis di bawah Lisensi Apache 2.0.
Jika Anda memiliki pertanyaan atau saran, jangan ragu untuk membuka masalah di GitHub atau hubungi kami di [email protected]


