AttackVLM
1.0.0
[Halaman Proyek] | [Slide] | [arXiv] | [Repositori Data]
In this research, we evaluate the adversarial robustness of recent large vision-language (generative) models (VLMs), under the most realistic and challenging setting with threat model of black-box access and targeted goal.
Our proposed method aims for the targeted response generation over large VLMs such as MiniGPT-4, LLaVA, Unidiffuser, BLIP/2, Img2Prompt, etc.
In other words, we mislead and let the VLMs say what you want, regardless of the content of the input image query.

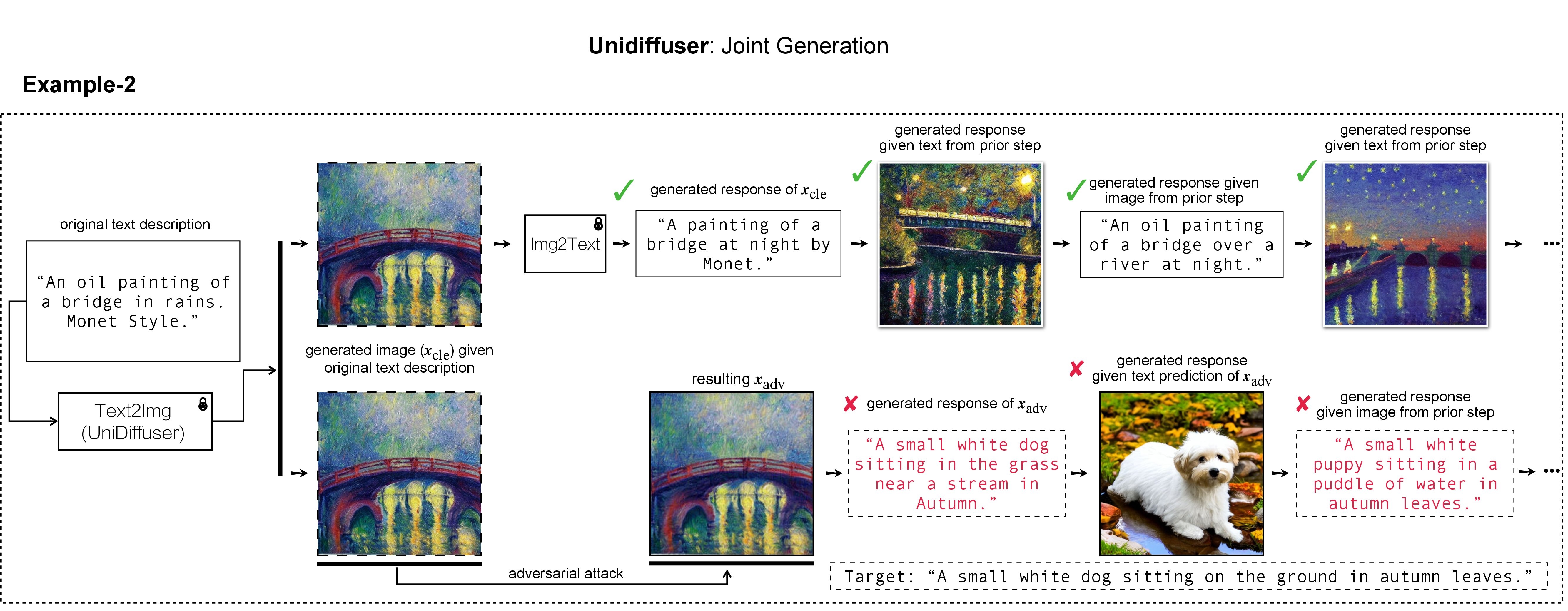
Dalam pekerjaan kami, kami menggunakan DALL-E, Midjourney, dan Difusi Stabil untuk pembuatan dan demonstrasi gambar target. Untuk eksperimen skala besar, kami menerapkan Difusi Stabil untuk menghasilkan gambar target. Untuk menginstal Difusi Stabil, kami memulai lingkungan conda kami dengan mengikuti Model Difusi Laten. Lingkungan conda dasar yang sesuai bernama ldm dapat dibuat dan diaktifkan dengan:
conda env create -f environment.yaml
conda activate ldm
Perhatikan bahwa untuk model korban yang berbeda, kami akan mengikuti implementasi resmi dan lingkungan conda mereka.
 Seperti yang dibahas dalam makalah kami, untuk mencapai serangan bertarget yang fleksibel, kami memanfaatkan model text-to-image yang telah dilatih sebelumnya untuk menghasilkan gambar target dengan satu keterangan sebagai teks target. Akibatnya, dengan cara ini Anda dapat menentukan sendiri teks yang ditargetkan untuk diserang!
Seperti yang dibahas dalam makalah kami, untuk mencapai serangan bertarget yang fleksibel, kami memanfaatkan model text-to-image yang telah dilatih sebelumnya untuk menghasilkan gambar target dengan satu keterangan sebagai teks target. Akibatnya, dengan cara ini Anda dapat menentukan sendiri teks yang ditargetkan untuk diserang!
Kami menggunakan Difusi Stabil, DALL-E, atau Midjourney sebagai generator teks-ke-gambar dalam eksperimen kami. Di sini, kami menggunakan Difusi Stabil untuk demonstrasi (terima kasih atas sumber terbukanya!).
git clone https://github.com/CompVis/stable-diffusion.git
cd stable-diffusion
kemudian, siapkan teks lengkap yang ditargetkan dari MS-COCO, atau unduh versi kami yang telah diproses dan dibersihkan:
https://drive.google.com/file/d/19tT036LBvqYonzI7PfU9qVi3jVGApKrg/view?usp=sharing
dan pindahkan ke ./stable-diffusion/ . Dalam eksperimen, seseorang dapat secara acak mengambil sampel subset keterangan COCO (misalnya, 10 , 100 , 1K , 10K , 50K ) untuk serangan permusuhan. Sebagai contoh, mari kita asumsikan kita telah secara acak mengambil sampel 10K teks COCO sebagai teks target c_tar dan menyimpannya dalam file berikut:
https://drive.google.com/file/d/1e5W3Yim7ZJRw3_C64yqVZg_Na7dOawaF/view?usp=sharing
Gambar yang ditargetkan h_ξ(c_tar) dapat diperoleh melalui Difusi Stabil dengan membaca perintah teks dari sampel keterangan COCO, dengan skrip di bawah ini dan txt2img_coco.py (harap pindahkan txt2img_coco.py ke ./stable-diffusion/ , perhatikan bahwa hyperparameter dapat berupa disesuaikan dengan preferensi Anda):
python txt2img_coco.py
--ddim_eta 0.0
--n_samples 10
--n_iter 1
--scale 7.5
--ddim_steps 50
--plms
--skip_grid
--ckpt ./_model_pool/sd-v1-4-full-ema.ckpt
--from-file './name_of_your_coco_captions_file.txt'
--outdir './path_of_your_targeted_images'
dimana ckptnya disediakan oleh Stable Diffusion v1 dan dapat didownload disini: sd-v1-4-full-ema.ckpt.
Detail implementasi tambahan pembuatan teks-ke-gambar dengan Difusi Stabil dapat ditemukan DI SINI.
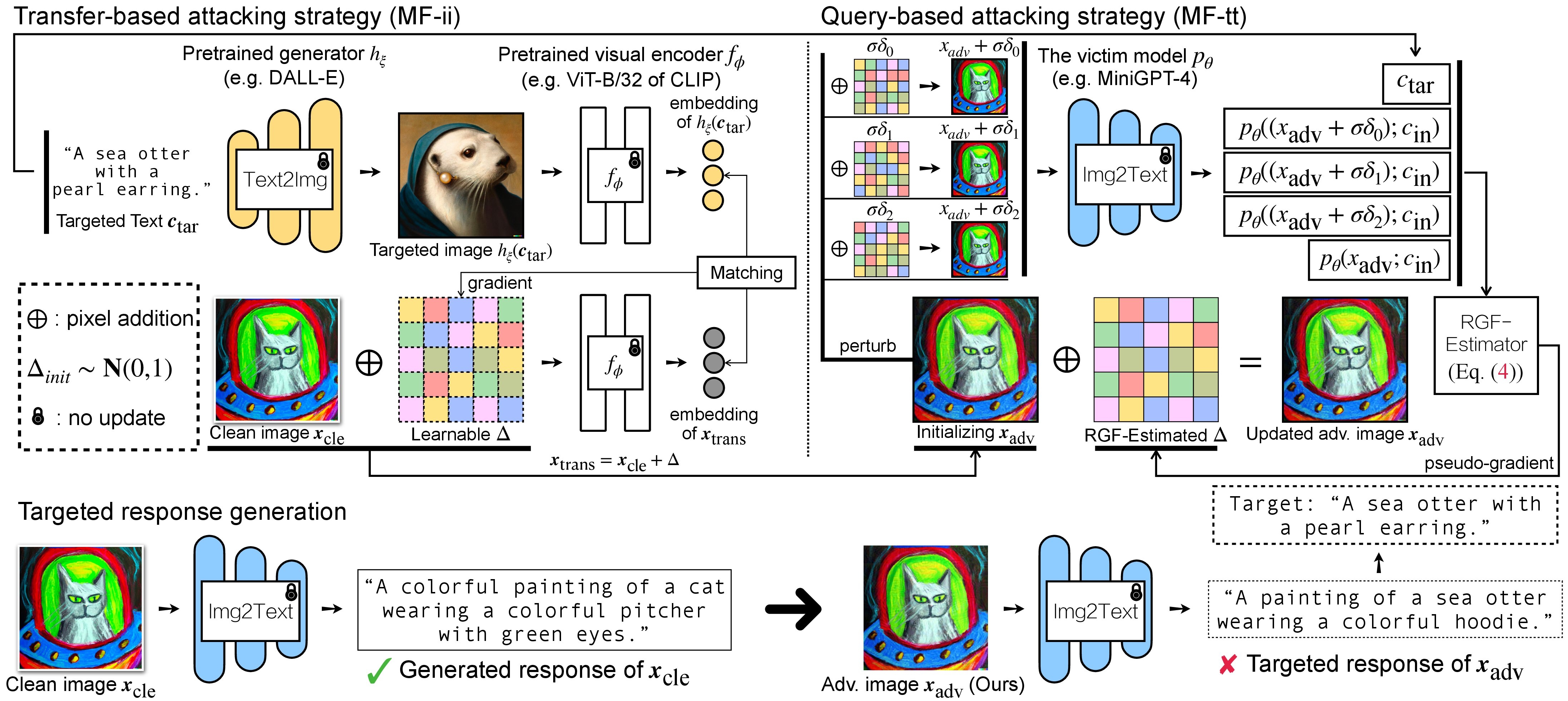
Ada dua langkah serangan permusuhan untuk VLM: (1) strategi serangan berbasis transfer dan (2) strategi serangan berbasis kueri menggunakan (1) sebagai inisialisasi. Untuk Model BLIP/BLIP-2/Img2Prompt, silakan merujuk ke ./LAVIS_tool . Di sini, kami menggunakan Unidiffuser sebagai contoh.
git clone https://github.com/thu-ml/unidiffuser.git
cd unidiffuser
cp ../unidff_tool/* ./
kemudian, buat lingkungan conda yang sesuai bernama unidiffuser dengan mengikuti langkah-langkah DI SINI, dan siapkan bobot model yang sesuai (kami menggunakan uvit_v1.pth sebagai bobot U-ViT).
conda activate unidiffuser
bash _train_adv_img_trans.sh
gambar adv yang dibuat x_trans akan disimpan dalam dir of white-box transfer images yang ditentukan dalam --output . Kemudian, kami melakukan gambar-ke-teks dan menyimpan respons yang dihasilkan dari x_trans. Hal ini dapat dicapai dengan:
python _eval_i2t_dataset.py
--batch_size 100
--mode i2t
--img_path 'dir of white-box transfer images'
--output 'dir of white-box transfer captions'
dimana tanggapan yang dihasilkan akan disimpan dalam dir of white-box transfer captions dalam format .txt . Kami akan menggunakannya untuk estimasi gradien semu melalui penduga RGF.
MF-ii + MF-tt (misalnya, 8 px) bash _train_trans_and_query_fixed_budget.sh
Di sisi lain, jika Anda ingin melakukan serangan berbasis transfer+query dengan anggaran gangguan terpisah , kami juga menyediakan skrip:
bash _train_trans_and_query_more_budget.sh
Di sini, kami menggunakan wandb untuk memantau secara dinamis rata-rata pergerakan skor CLIP (misalnya, RN50, ViT-B/32, ViT-L/14, dll.) untuk mengevaluasi kesamaan antara (a) respons yang dihasilkan (dari trans/ gambar kueri) dan (b) teks target yang telah ditentukan sebelumnya c_tar .
Contohnya ditunjukkan di bawah ini, di mana garis putus-putus menunjukkan rata-rata pergerakan skor CLIP (keterangan gambar) setelah kueri: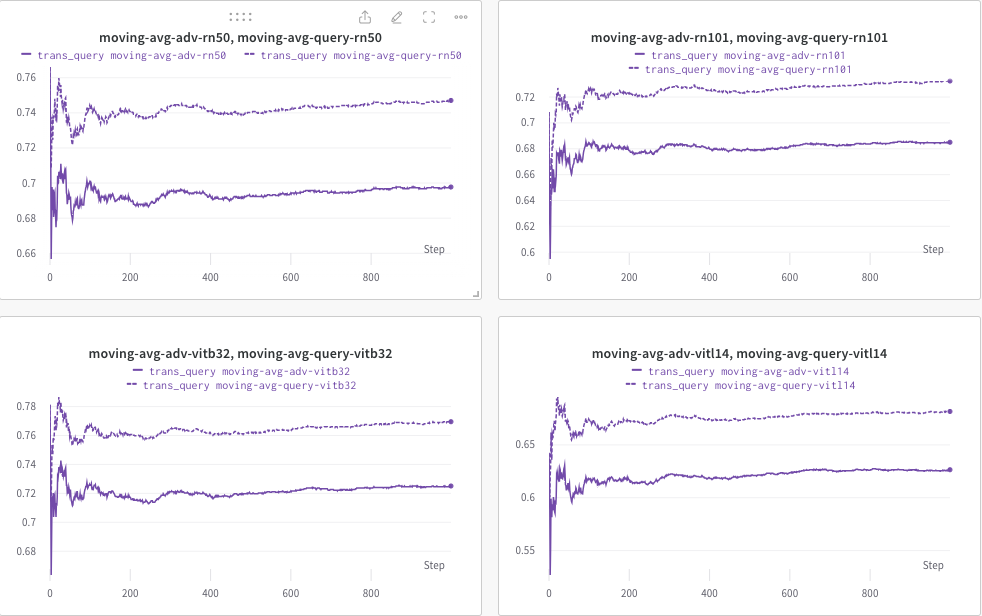
Sedangkan keterangan gambar setelah query akan disimpan dan direktori dapat ditentukan dengan --output .
Jika Anda merasa proyek ini bermanfaat dalam penelitian Anda, mohon pertimbangkan untuk mengutip makalah kami:
@inproceedings{zhao2023evaluate,
title={On Evaluating Adversarial Robustness of Large Vision-Language Models},
author={Zhao, Yunqing and Pang, Tianyu and Du, Chao and Yang, Xiao and Li, Chongxuan and Cheung, Ngai-Man and Lin, Min},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023}
}
Sementara itu, penelitian relevan yang bertujuan untuk Menanamkan Tanda Air pada Model Difusi (multi-modal):
@article{zhao2023recipe,
title={A Recipe for Watermarking Diffusion Models},
author={Zhao, Yunqing and Pang, Tianyu and Du, Chao and Yang, Xiao and Cheung, Ngai-Man and Lin, Min},
journal={arXiv preprint arXiv:2303.10137},
year={2023}
}
Kami menghargai implementasi dasar yang luar biasa dari MiniGPT-4, LLaVA, Unidiffuser, LAVIS, dan CLIP. Kami juga berterima kasih kepada @MetaAI karena telah membuka sumber pemeriksaan LLaMA mereka. Kami berterima kasih kepada SiSi karena telah memberikan beberapa gambar menyenangkan dan visual yang dihasilkan oleh @Midjourney dalam penelitian kami.


