SDV
v1.17.2 - 2024-11-18
Repositori ini merupakan bagian dari The Synthetic Data Vault Project, sebuah proyek dari DataCebo.



Gudang Data Sintetis (SDV) adalah pustaka Python yang dirancang untuk menjadi toko serba ada untuk membuat data sintetis tabular. SDV menggunakan berbagai algoritme pembelajaran mesin untuk mempelajari pola dari data nyata Anda dan menirunya dalam data sintetis.
? Buat data sintetis menggunakan pembelajaran mesin. SDV menawarkan berbagai model, mulai dari metode statistik klasik (GaussianCopula) hingga metode pembelajaran mendalam (CTGAN). Hasilkan data untuk tabel tunggal, beberapa tabel terhubung, atau tabel berurutan.
Evaluasi dan visualisasikan data. Bandingkan data sintetis dengan data nyata dengan berbagai ukuran. Diagnosis masalah dan hasilkan laporan berkualitas untuk mendapatkan lebih banyak wawasan.
Proses awal, anonimkan, dan tentukan batasan. Kontrol pemrosesan data untuk meningkatkan kualitas data sintetis, pilih dari berbagai jenis anonimisasi, dan tentukan aturan bisnis dalam bentuk batasan logis.
| Tautan Penting | |
|---|---|
 Tutorial Tutorial | Dapatkan pengalaman langsung dengan SDV. Luncurkan buku catatan tutorial dan jalankan kodenya sendiri. |
| dokumen | Pelajari cara menggunakan perpustakaan SDV dengan panduan pengguna dan referensi API. |
| ? blog | Dapatkan lebih banyak wawasan tentang penggunaan SDV, penerapan model, dan komunitas data sintetis kami. |
 Masyarakat Masyarakat | Bergabunglah dengan ruang kerja Slack kami untuk pengumuman dan diskusi. |
| Situs web | Kunjungi situs web SDV untuk informasi lebih lanjut tentang proyek ini. |
SDV tersedia untuk umum di bawah Lisensi Sumber Bisnis. Instal SDV menggunakan pip atau conda. Kami menyarankan penggunaan lingkungan virtual untuk menghindari konflik dengan perangkat lunak lain di perangkat Anda.
pip install sdvconda install -c pytorch -c conda-forge sdvMuat kumpulan data demo untuk memulai. Kumpulan data ini adalah tabel tunggal yang menggambarkan tamu yang menginap di hotel fiksi.
from sdv . datasets . demo import download_demo
real_data , metadata = download_demo (
modality = 'single_table' ,
dataset_name = 'fake_hotel_guests' )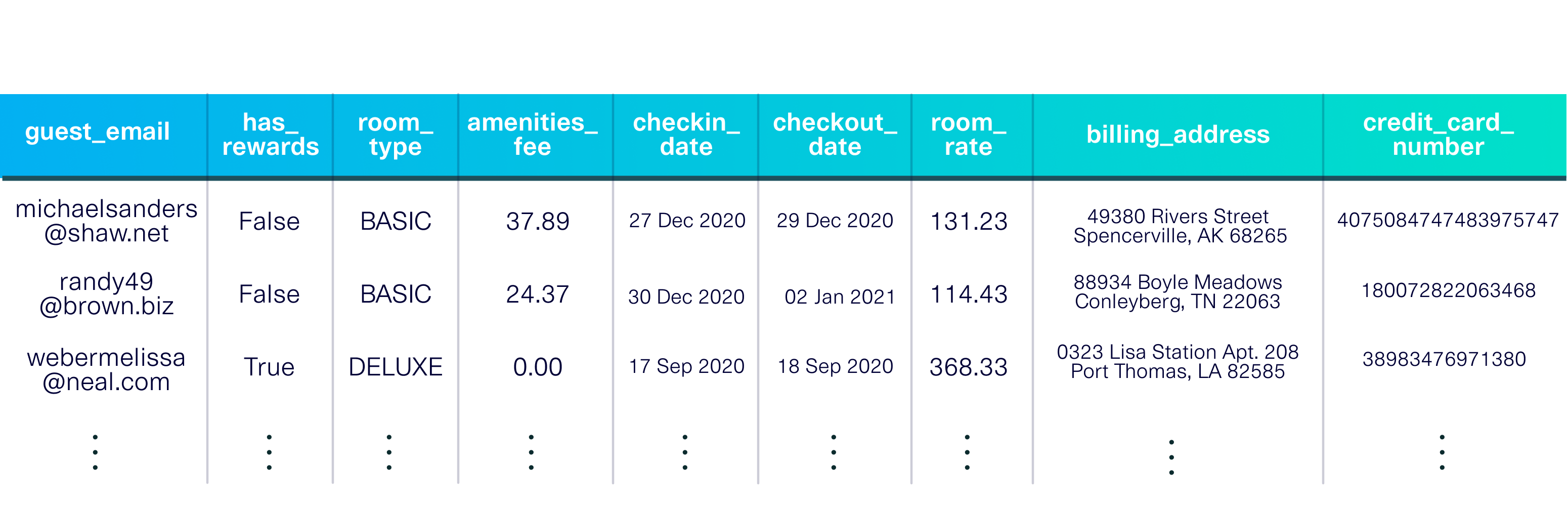
Demo ini juga mencakup metadata , deskripsi kumpulan data, termasuk tipe data di setiap kolom dan kunci utama ( guest_email ).
Selanjutnya, kita dapat membuat synthesizer SDV , sebuah objek yang dapat Anda gunakan untuk membuat data sintetis. Ia mempelajari pola dari data nyata dan mereplikasinya untuk menghasilkan data sintetis. Mari kita gunakan GaussianCopulaSynthesizer.
from sdv . single_table import GaussianCopulaSynthesizer
synthesizer = GaussianCopulaSynthesizer ( metadata )
synthesizer . fit ( data = real_data )Dan sekarang synthesizer siap membuat data sintetik!
synthetic_data = synthesizer . sample ( num_rows = 500 )Data sintetis akan memiliki properti berikut:
Pustaka SDV memungkinkan Anda mengevaluasi data sintetis dengan membandingkannya dengan data sebenarnya. Mulailah dengan membuat laporan berkualitas.
from sdv . evaluation . single_table import evaluate_quality
quality_report = evaluate_quality (
real_data ,
synthetic_data ,
metadata ) Generating report ...
(1/2) Evaluating Column Shapes: |████████████████| 9/9 [00:00<00:00, 1133.09it/s]|
Column Shapes Score: 89.11%
(2/2) Evaluating Column Pair Trends: |██████████████████████████████████████████| 36/36 [00:00<00:00, 502.88it/s]|
Column Pair Trends Score: 88.3%
Overall Score (Average): 88.7%
Objek ini menghitung skor kualitas keseluruhan pada skala 0 hingga 100% (100 adalah yang terbaik) serta rinciannya. Untuk mendapatkan wawasan lebih lanjut, Anda juga dapat memvisualisasikan data sintetis vs. data nyata.
from sdv . evaluation . single_table import get_column_plot
fig = get_column_plot (
real_data = real_data ,
synthetic_data = synthetic_data ,
column_name = 'amenities_fee' ,
metadata = metadata
)
fig . show ()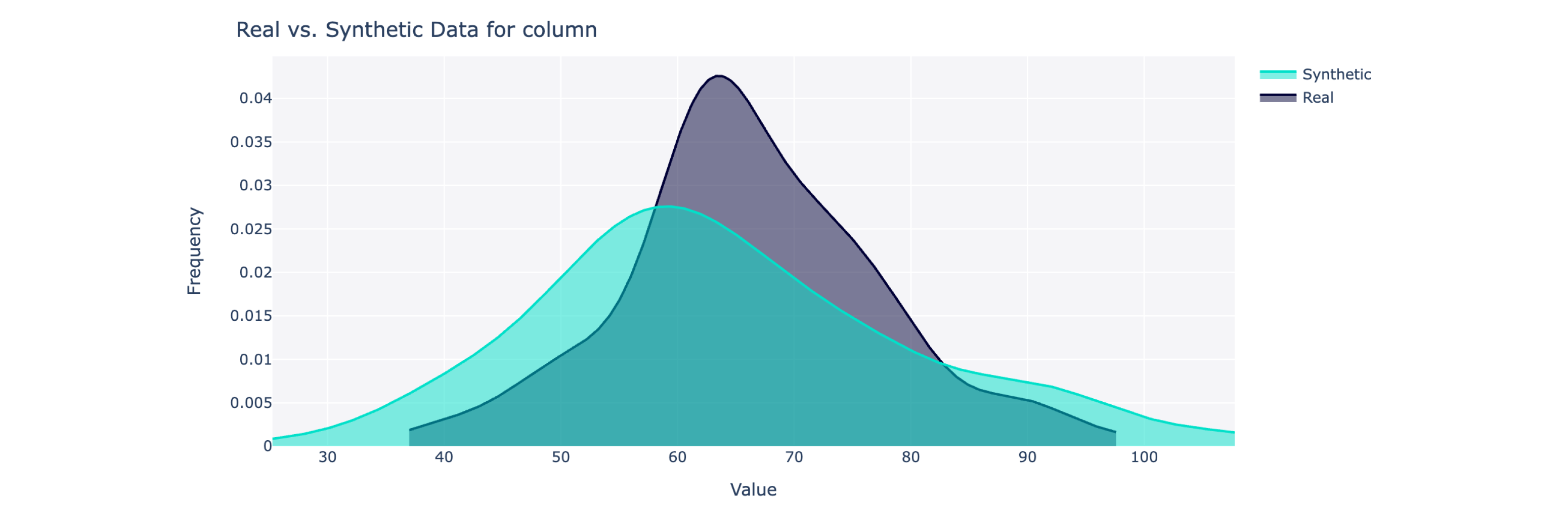
Menggunakan perpustakaan SDV, Anda dapat mensintesis tabel tunggal, multi tabel, dan data berurutan. Anda juga dapat menyesuaikan alur kerja data sintetis lengkap, termasuk prapemrosesan, anonimisasi, dan penambahan batasan.
Untuk mempelajari lebih lanjut, kunjungi halaman Demo SDV.
Terima kasih kepada tim kontributor kami yang telah membangun dan memelihara ekosistem SDV selama bertahun-tahun!
Lihat Kontributor
Jika Anda menggunakan SDV untuk penelitian Anda, harap kutip makalah berikut:
Neha Patki, Roy Wedge, Kalyan Veeramachaneni . Gudang Data Sintetis. IEEE DSAA 2016.
@inproceedings{
SDV,
title={The Synthetic data vault},
author={Patki, Neha and Wedge, Roy and Veeramachaneni, Kalyan},
booktitle={IEEE International Conference on Data Science and Advanced Analytics (DSAA)},
year={2016},
pages={399-410},
doi={10.1109/DSAA.2016.49},
month={Oct}
}
Proyek Gudang Data Sintetis pertama kali dibuat di Lab Data ke AI MIT pada tahun 2016. Setelah 4 tahun melakukan penelitian dan interaksi dengan perusahaan, kami membuat DataCebo pada tahun 2020 dengan tujuan mengembangkan proyek tersebut. Saat ini, DataCebo bangga menjadi pengembang SDV, ekosistem terbesar untuk pembuatan & evaluasi data sintetis. Ini adalah rumah bagi beberapa perpustakaan yang mendukung data sintetis, termasuk:
Mulai gunakan paket SDV -- solusi terintegrasi penuh dan toko serba ada untuk data sintetis. Atau, gunakan perpustakaan mandiri untuk kebutuhan spesifik.


