LipGER
Initial Release
Ini adalah implementasi resmi untuk makalah kami LipGER: Koreksi Kesalahan Generatif Berkondisi Visual untuk Pengenalan Ucapan Otomatis yang Kuat di InterSpeech 2024 yang dipilih untuk presentasi lisan .
Anda dapat mengunduh data LipHyp dari sini!
pip install -r requirements.txt
Pertama siapkan pos pemeriksaan menggunakan:
pip install huggingface_hub
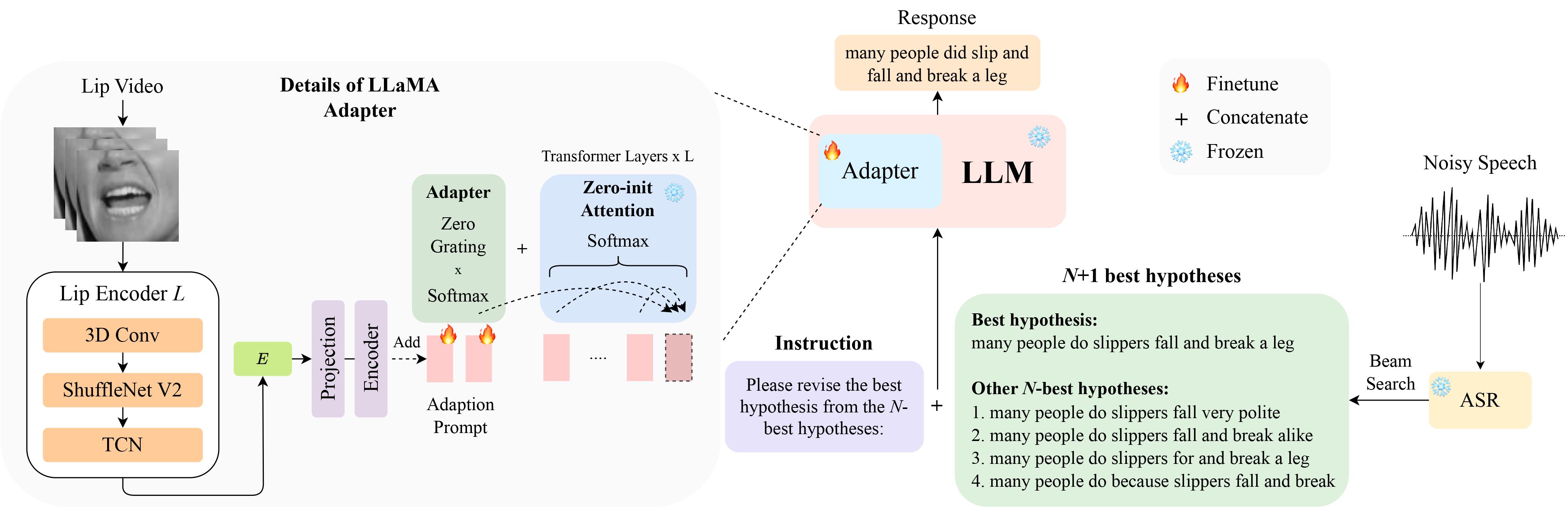
python scripts/download.py --repo_id meta-llama/Llama-2-7b-chat-hf --token your_hf_token
python scripts/convert_hf_checkpoint.py --checkpoint_dir checkpoints/meta-llama/Llama-2-7b-chat-hfUntuk melihat semua pos pemeriksaan yang tersedia, jalankan:
python scripts/download.py | grep Llama-2Untuk lebih jelasnya, Anda juga dapat merujuk ke tautan ini, di mana Anda juga dapat menyiapkan pos pemeriksaan lain untuk model lainnya. Secara khusus, kami menggunakan TinyLlama untuk eksperimen kami.
Pos pemeriksaan tersedia di sini. Setelah mengunduh, ubah jalur pos pemeriksaan di sini.
LipGER mengharapkan semua file train, val, dan test berada dalam format sample_data.json. Contoh dalam file terlihat seperti:
{
"Dataset": "dataset_name",
"Uid": "unique_id",
"Caption": "The ground truth transcription.",
"Noisy_Wav": "path_to_noisy_wav",
"Mouthroi": "path_to_mouth_roi_mp4",
"Video": "path_to_video_mp4",
"nhyps_base": [ list of N-best hypotheses ],
}
Anda perlu meneruskan file ucapan melalui model ASR terlatih yang mampu menghasilkan N hipotesis terbaik. Kami menyediakan 2 cara dalam repo ini untuk membantu Anda mencapai hal ini. Jangan ragu untuk menggunakan metode lain.
pip install whisper dan kemudian menjalankan nhyps.py dari folder data , Anda akan baik-baik saja! Perhatikan bahwa untuk kedua metode, yang pertama dalam daftar adalah hipotesis terbaik dan yang lainnya adalah N hipotesis terbaik (mereka diteruskan sebagai bidang daftar nhyps_base di JSON dan digunakan untuk membuat prompt di langkah berikutnya).
Selain itu, metode yang disediakan hanya menggunakan ucapan sebagai masukan. Untuk menghasilkan hipotesis N-terbaik audio-visual, kami menggunakan Auto-AVSR. Jika Anda memerlukan bantuan dengan kode ini, silakan ajukan masalah!
Dengan asumsi Anda memiliki video yang sesuai untuk semua file ucapan Anda, ikuti langkah-langkah berikut untuk memotong ROI dari video tersebut.
python crop_mouth_script.py
python covert_lip.py
Ini akan mengubah ROI mp4 menjadi hdf5, kode akan mengubah jalur ROI mp4 menjadi hdf5 ROI dalam file json yang sama. Anda dapat memilih dari detektor "mediapipe" dan "retinaface" dengan mengubah "detektor" di default.yaml
Setelah Anda memiliki N hipotesis terbaik, buat file JSON dalam format yang diperlukan. Kami tidak menyediakan kode spesifik untuk bagian ini karena persiapan data mungkin berbeda untuk setiap orang, namun kodenya harus sederhana. Sekali lagi, ajukan masalah jika Anda ragu!
Skrip pelatihan LipGER tidak menggunakan JSON untuk pelatihan atau evaluasi. Anda perlu mengonversinya menjadi file pt. Anda dapat menjalankan convert_to_pt.py untuk mencapai ini! Ubah model_name sesuai keinginan Anda di baris 27 dan tambahkan path ke JSON Anda di baris 58.
Untuk menyempurnakan LipGER, jalankan saja:
sh finetune.sh
di mana Anda perlu mengatur nilai data secara manual (dengan nama kumpulan data), --train_path dan --val_path (dengan jalur absolut untuk melatih dan file .pt yang valid).
Untuk inferensi, pertama-tama ubah jalur masing-masing di lipger.py ( exp_path dan checkpoint_dir ), lalu jalankan (dengan argumen jalur data pengujian yang sesuai):
sh infer.sh
Kode untuk memotong ROI mulut terinspirasi dari Visual_Speech_Recognition_for_Multiple_Languages.
Kode kami untuk LipGER terinspirasi dari RobustGER. Silakan kutip makalah mereka juga jika menurut Anda makalah atau kode kami berguna.
@inproceedings{ghosh23b_interspeech,
author={Sreyan Ghosh and Sonal Kumar and Ashish Seth and Purva Chiniya and Utkarsh Tyagi and Ramani Duraiswami and Dinesh Manocha},
title={{LipGER: Visually-Conditioned Generative Error Correction for Robust Automatic Speech Recognition}},
year=2024,
booktitle={Proc. INTERSPEECH 2024},
}


