self instruct
1.0.0
Repositori ini berisi kode dan data untuk makalah Self-Instruct, sebuah metode untuk menyelaraskan model bahasa yang telah dilatih sebelumnya dengan instruksi.
Self-Instruct adalah kerangka kerja yang membantu model bahasa meningkatkan kemampuannya untuk mengikuti instruksi bahasa alami. Hal ini dilakukan dengan menggunakan generasi model itu sendiri untuk membuat kumpulan data instruksional dalam jumlah besar. Dengan Self-Instruct, dimungkinkan untuk meningkatkan kemampuan mengikuti instruksi model bahasa tanpa bergantung pada anotasi manual yang ekstensif.
Dalam beberapa tahun terakhir, terdapat peningkatan minat dalam membangun model yang dapat mengikuti instruksi bahasa alami untuk melakukan berbagai tugas. Model-model ini, yang dikenal sebagai model bahasa yang "disesuaikan dengan instruksi", telah menunjukkan kemampuan untuk menggeneralisasi tugas-tugas baru. Namun, kinerja mereka sangat bergantung pada kualitas dan kuantitas data instruksi tertulis yang digunakan untuk melatih mereka, yang mungkin terbatas pada keragaman dan kreativitas. Untuk mengatasi keterbatasan ini, penting untuk mengembangkan pendekatan alternatif untuk mengawasi model yang disesuaikan dengan instruksi dan meningkatkan kemampuan mengikuti instruksi mereka.
Proses Self-Instruct adalah algoritma bootstrap berulang yang dimulai dengan sekumpulan instruksi yang ditulis secara manual dan menggunakannya untuk meminta model bahasa untuk menghasilkan instruksi baru dan contoh input-output yang sesuai. Generasi ini kemudian difilter untuk menghapus generasi berkualitas rendah atau serupa, dan data yang dihasilkan ditambahkan kembali ke kumpulan tugas. Proses ini dapat diulang beberapa kali, sehingga menghasilkan kumpulan data instruksional dalam jumlah besar yang dapat digunakan untuk menyempurnakan model bahasa agar dapat mengikuti instruksi dengan lebih efektif.
Berikut ini ikhtisar Instruksi Mandiri:
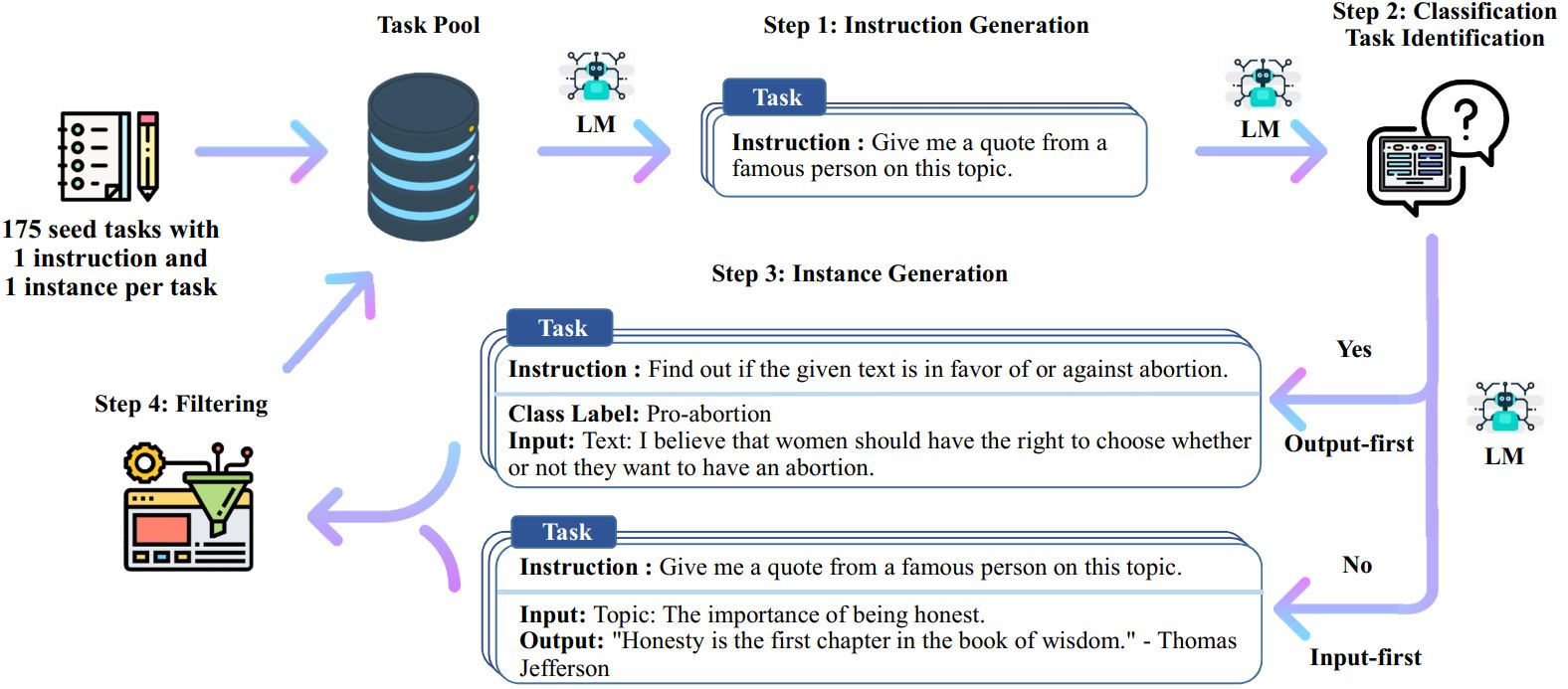
* Pekerjaan ini masih dalam proses. Kami dapat memperbarui kode dan data seiring kemajuan kami. Harap berhati-hati tentang kontrol versi.
Kami merilis kumpulan data yang berisi 52 ribu instruksi, dipasangkan dengan 82 ribu input dan output instans. Data instruksi ini dapat digunakan untuk melakukan penyesuaian instruksi pada model bahasa dan membuat model bahasa mengikuti instruksi dengan lebih baik. Seluruh data yang dihasilkan model dapat diakses di data/gpt3-generations/batch_221203/all_instances_82K.jsonl . Data ini (+ 175 tugas awal) yang diformat ulang dalam format penyempurnaan GPT3 yang bersih (cepat + penyelesaian) dimasukkan ke dalam data/finetuning/self_instruct_221203 . Anda dapat menggunakan skrip di ./scripts/finetune_gpt3.sh untuk menyempurnakan GPT3 pada data ini.
Catatan : Data ini dihasilkan oleh model bahasa (GPT3) dan pasti mengandung beberapa kesalahan atau bias. Kami menganalisis kualitas data pada 200 instruksi acak di makalah kami, dan menemukan bahwa 46% titik data mungkin mengalami masalah. Kami mendorong pengguna untuk menggunakan data ini dengan hati-hati dan mengusulkan metode baru untuk menyaring atau memperbaiki ketidaksempurnaan.
Kami juga merilis serangkaian 252 tugas baru yang ditulis oleh pakar dan instruksinya yang dimotivasi oleh aplikasi berorientasi pengguna (bukan tugas NLP yang dipelajari dengan baik). Data ini digunakan di bagian evaluasi manusia pada makalah instruksi mandiri. Silakan lihat README evaluasi manusia untuk lebih jelasnya.
Untuk menghasilkan data Instruksi Mandiri menggunakan tugas awal Anda sendiri atau model lain, kami membuat skrip kami menjadi sumber terbuka untuk keseluruhan alur di sini. Kode kami saat ini hanya diuji pada model GPT3 yang dapat diakses melalui OpenAI API.
Berikut skrip untuk menghasilkan data:
# 1. Hasilkan instruksi dari tugas awal./scripts/generate_instructions.sh# 2. Identifikasi apakah instruksi mewakili tugas klasifikasi atau tidak./scripts/is_clf_or_not.sh# 3. Hasilkan instance untuk setiap instruksi./scripts/generate_instances. sh# 4. Memfilter, memproses, dan memformat ulang./scripts/prepare_for_finetuning.sh
Jika Anda menggunakan kerangka atau data Self-Instruct, jangan ragu untuk mengutip kami.
@misc{selfinstruct, title={Instruksi Mandiri: Menyelaraskan Model Bahasa dengan Instruksi yang Dihasilkan Sendiri}, author={Wang, Yizhong dan Kordi, Yeganeh dan Mishra, Swaroop dan Liu, Alisa dan Smith, Noah A. dan Khashabi, Daniel dan Hajishirzi, Hannaneh}, jurnal={arXiv preprint arXiv:2212.10560}, tahun={2022}} 

