Desain tabel kumulatif adalah alat rekayasa data yang sangat canggih yang harus diketahui oleh semua teknisi data.
Desain ini menghasilkan tabel yang dapat memberikan analisis efisien pada kerangka waktu yang sangat besar (hingga ribuan hari).
Berikut diagram desain jalur pipa tingkat tinggi untuk pola ini:
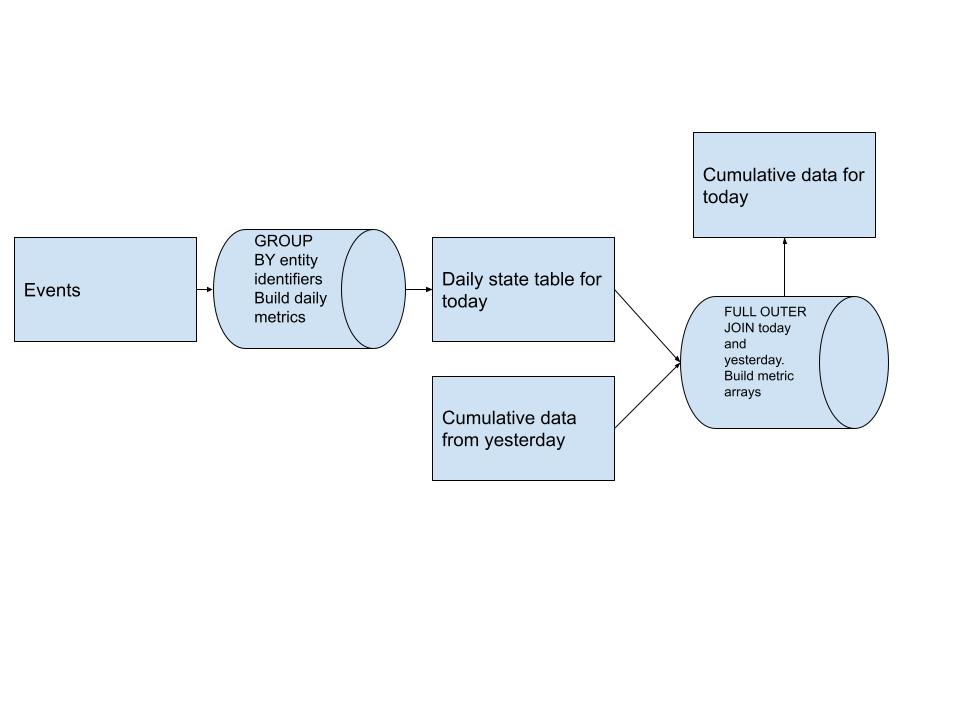
Kami awalnya membuat tabel metrik harian berdasarkan apa pun entitas kami. Data ini berasal dari sumber peristiwa apa pun yang kami miliki di bagian hulu.
Setelah kita memiliki metrik harian, kita FULL OUTER JOIN tabel kumulatif kemarin dengan data harian hari ini dan membuat susunan metrik untuk setiap pengguna. Hal ini memungkinkan kami memasukkan riwayat baru tanpa harus memindai semuanya. (peningkatan kinerja yang besar)
Array metrik ini memungkinkan kita dengan mudah menjawab pertanyaan tentang riwayat semua pengguna menggunakan hal-hal seperti ARRAY_SUM untuk menghitung metrik apa pun yang kita inginkan pada jangka waktu apa pun yang dimungkinkan oleh array.
Semakin lama jangka waktu analisis Anda, semakin kritis pola ini!!
Semua sintaks kueri menggunakan sintaks dan fungsi Presto/Trino. Contoh ini perlu dimodifikasi untuk varian SQL lainnya!
Kami akan menggunakan tanggal:
- 01-01-2022 seperti hari ini dalam istilah Aliran Udara adalah
{{ ds }}- 31-12-2021 seperti kemarin dalam istilah templat Airflow, ini adalah
{{ yesterday_ds}}
Dalam contoh ini, kita akan melihat cara membuat desain ini untuk menghitung pengguna aktif harian, mingguan, dan bulanan serta jumlah suka, komentar, dan pembagian pengguna.
Tabel sumber kami dalam hal ini adalah events .
event_type yaitu like , comment , share , atau viewSangat menggoda untuk berpikir bahwa solusi untuk hal ini adalah dengan menjalankan saluran pipa
SELECT
COUNT(DISTINCT user_id) as num_monthly_active_users,
COUNT(CASE WHEN event_type = 'like' THEN 1 END) as num_likes_30d,
COUNT(CASE WHEN event_type = 'comment' THEN 1 END) as num_comments_30d,
COUNT(CASE WHEN event_type = 'share' THEN 1 END) as num_shares_30d,
...
FROM events
WHERE event_date BETWEEN DATE_SUB('2022-01-01', 30), AND '2022-01-01'
Masalahnya adalah kami memindai data peristiwa selama 30 hari setiap hari untuk menghasilkan angka-angka ini. Saluran pipa yang cukup boros namun sederhana. Seharusnya ada cara dimana kita hanya perlu memindai data kejadian satu kali dan menggabungkannya dengan hasil dari 29 hari sebelumnya, bukan? Bisakah kita membuat struktur data di mana data scientist dapat menanyakan data kita dan dengan mudah mengetahui jumlah tindakan yang dilakukan pengguna dalam N hari terakhir?
Desain ini cukup sederhana hanya dengan 3 langkah:
GROUP BY user_id dan kemudian hitung mereka sebagai aktif harian jika ada acaraCOUNT(CASE WHEN event_type = 'like' THEN 1 END) untuk mengetahui jumlah suka, komentar, dan pembagian harian jugaFULL OUTER JOIN dua kumpulan data ini pada today.user_id = yesterday.user_idCOALESCE(today.user_id, yesterday.user_id) as user_id untuk melacak semua penggunaactivity_array . Kami hanya ingin activity_array menyimpan data 30 hari terakhirCARDINALITY(activity_array) < 30 untuk memahami apakah kita bisa menambahkan nilai hari ini ke depan array atau apakah kita perlu memotong elemen dari akhir array sebelum menambahkan nilai hari ini ke depanCOALESCE(t.is_active_today, 0) untuk memasukkan nilai nol ke dalam array ketika pengguna tidak aktifactivity_array tetapi juga untuk suka, komentar, dan berbagi!CASE WHEN ARRAY_SUM(activity_array) > 0 THEN 1 ELSE 0 END memberi kita aktivitas bulanan karena kita membatasi ukuran array hingga 30CASE WHEN ARRAY_SUM(SLICE(activity_array, 1, 7)) > 0 THEN 1 ELSE 0 END memberi kita aktif mingguan karena kita hanya memeriksa 7 elemen pertama dari array (yaitu 7 hari terakhir)ARRAY_SUM(SLICE(like_array, 1, 7)) as num_likes_7d memberi kita jumlah suka yang dilakukan pengguna ini dalam 7 hari terakhirARRAY_SUM(like_array) as num_likes_30d memberi kita jumlah suka yang dilakukan pengguna ini dalam 30 hari terakhir sejak array ditetapkan ke ukuran tersebutdepends_on_past: True

