FlagEmbedding
1.3.2


Berita | Instalasi | Mulai Cepat | Komunitas | Proyek | Daftar Model | Kontributor | Kutipan | Lisensi
Bahasa Inggris | tidak
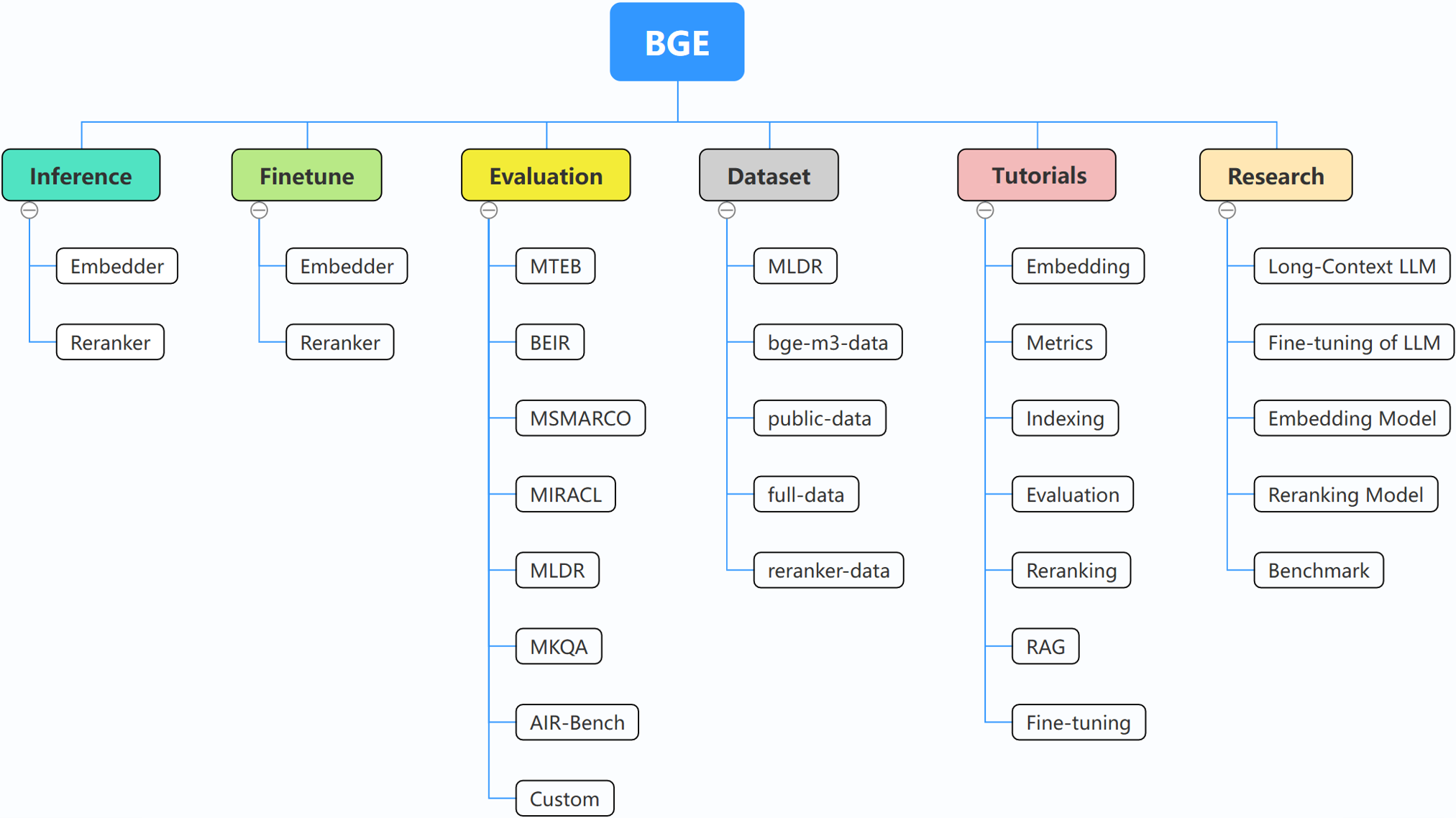
BGE (BAAI General Embedding) berfokus pada LLM yang ditambah pengambilan, yang saat ini terdiri dari proyek-proyek berikut:
29/10/2024: ? Kami membuat grup WeChat untuk BGE. Pindai kode QR untuk bergabung dengan obrolan grup! Untuk mendapatkan pesan langsung tentang pembaruan dan rilis baru kami, atau memiliki pertanyaan atau ide, bergabunglah dengan kami sekarang!

22/10/2024: Kami merilis model menarik lainnya: OmniGen, yang merupakan model pembuatan gambar terpadu yang mendukung berbagai tugas. OmniGen dapat menyelesaikan tugas pembuatan gambar yang kompleks tanpa memerlukan plugin tambahan seperti ControlNet, IP-Adapter, atau model tambahan seperti deteksi pose dan deteksi wajah.
9/10/2024: Memperkenalkan MemoRAG , sebuah langkah maju menuju RAG 2.0 selain penemuan pengetahuan yang terinspirasi dari memori (repo: https://github.com/qhjqhj00/MemoRAG, makalah: https://arxiv.org/pdf/ 2409.05591v1)
9/2/2024: Mulai memelihara tutorialnya. Konten di dalamnya akan diperbarui dan didengarkan secara aktif, pantau terus!
26/07/2024: Merilis model penyematan baru bge-en-icl, model penyematan yang menggabungkan kemampuan pembelajaran dalam konteks, yang, dengan memberikan contoh respons kueri yang relevan dengan tugas, dapat menyandikan kueri yang lebih kaya secara semantik, sehingga semakin meningkatkan semantik kemampuan representasi dari embeddings.
26/07/2024: Merilis model penyematan baru bge-multilingual-gemma2, model penyematan multibahasa berdasarkan gemma-2-9b, yang mendukung banyak bahasa dan beragam tugas hilir, mencapai SOTA baru pada tolok ukur multibahasa (MIRACL, MTEB-fr , dan MTEB-pl).
26/07/2024: Merilis reranker ringan baru bge-reranker-v2.5-gemma2-lightweight, reranker ringan berdasarkan gemma-2-9b, yang mendukung kompresi token dan operasi ringan berlapis, masih dapat memastikan kinerja yang baik sambil menghemat sejumlah besar sumber daya.
BAAI/bge-reranker-base dan BAAI/bge-reranker-large , yang lebih kuat daripada model penyematan. Kami merekomendasikan untuk menggunakan/menyempurnakannya untuk mengurutkan ulang dokumen-dokumen teratas yang dikembalikan dengan menyematkan model.bge-*-v1.5 untuk mengatasi masalah distribusi kesamaan, dan meningkatkan kemampuan pengambilannya tanpa instruksi.bge-large-* (kependekan dari BAAI General Embedding), peringkat 1 pada benchmark MTEB dan C-MTEB! ? ?Jika Anda tidak ingin menyempurnakan model, Anda dapat menginstal paket tanpa ketergantungan finetune:
pip install -U FlagEmbedding
Jika Anda ingin menyempurnakan model, Anda dapat menginstal paket dengan ketergantungan finetune:
pip install -U FlagEmbedding[finetune]
Kloning repositori dan instal
git clone https://github.com/FlagOpen/FlagEmbedding.git
cd FlagEmbedding
# If you do not want to finetune the models, you can install the package without the finetune dependency:
pip install .
# If you want to finetune the models, you can install the package with the finetune dependency:
# pip install .[finetune]
Untuk pengembangan dalam mode yang dapat diedit:
# If you do not want to finetune the models, you can install the package without the finetune dependency:
pip install -e .
# If you want to finetune the models, you can install the package with the finetune dependency:
# pip install -e .[finetune]
Pertama, muat salah satu model penyematan BGE:
from FlagEmbedding import FlagAutoModel
model = FlagAutoModel.from_finetuned('BAAI/bge-base-en-v1.5',
query_instruction_for_retrieval="Represent this sentence for searching relevant passages:",
use_fp16=True)
Kemudian, masukkan beberapa kalimat ke model dan dapatkan penyematannya:
sentences_1 = ["I love NLP", "I love machine learning"]
sentences_2 = ["I love BGE", "I love text retrieval"]
embeddings_1 = model.encode(sentences_1)
embeddings_2 = model.encode(sentences_2)
Setelah kita mendapatkan embeddingsnya, kita dapat menghitung kesamaan berdasarkan produk dalam:
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
Untuk lebih jelasnya, Anda dapat merujuk pada inferensi penyematan, inferensi reranker, penyempurnaan penyematan, fintune reranker, evaluasi.
Jika Anda tidak terbiasa dengan konsep terkait apa pun, silakan lihat tutorialnya. Jika tidak ada, beri tahu kami.
Untuk topik lebih menarik terkait BGE, lihat penelitiannya.
Kami secara aktif memelihara komunitas BGE dan FlagEmbedding. Beri tahu kami jika Anda memiliki saran atau ide!
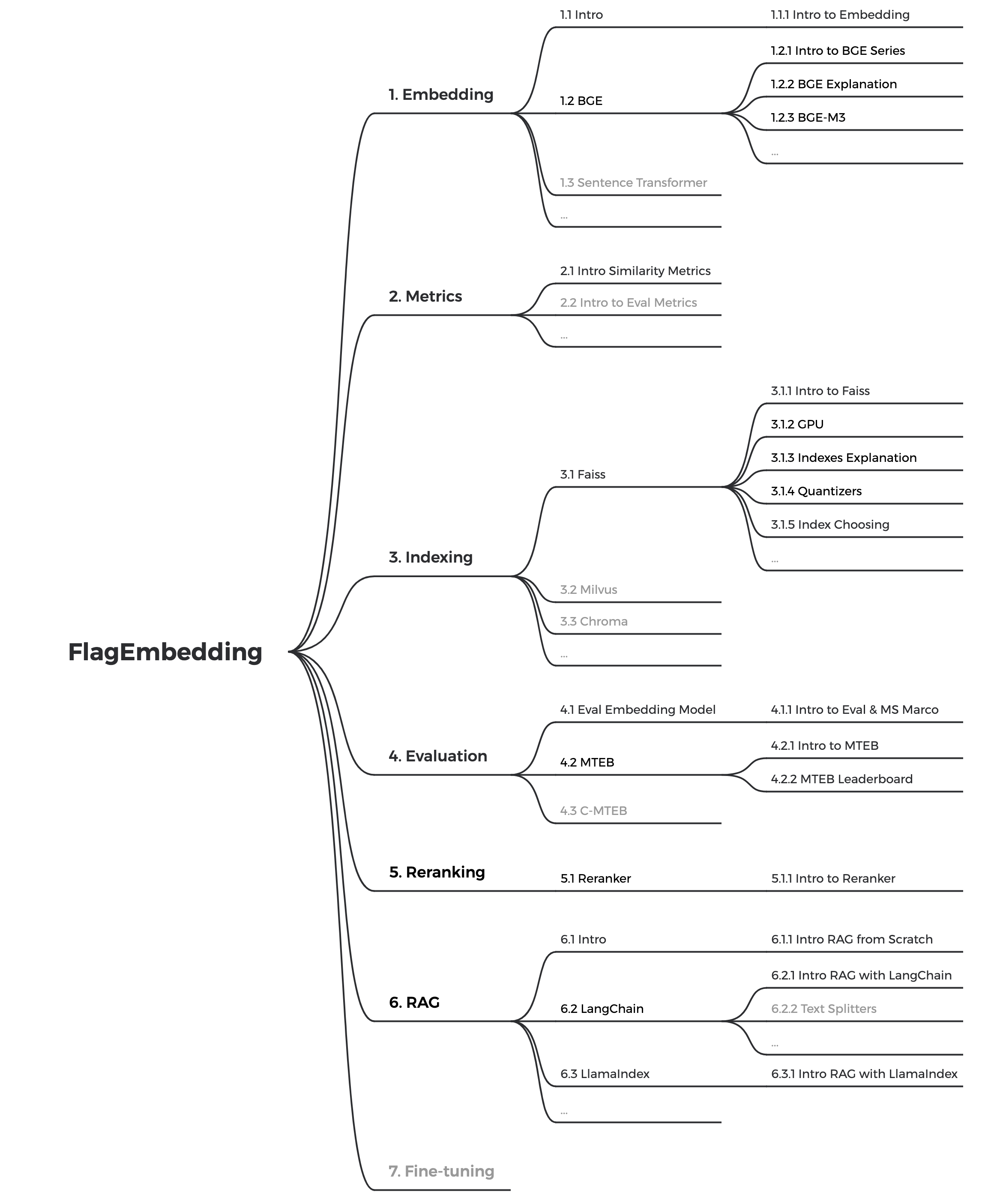
Saat ini kami sedang mengupdate tutorialnya, kami bertujuan untuk membuat tutorial yang komprehensif dan detail untuk pemula tentang pengambilan teks dan RAG. Pantau terus!
Konten berikut akan dirilis dalam beberapa minggu mendatang:
bge adalah kependekan dari BAAI general embedding .
| Model | Bahasa | Keterangan | instruksi kueri untuk pengambilan |
|---|---|---|---|
| BAAI/bge-en-icl | Bahasa inggris | Model penyematan berbasis LLM dengan kemampuan pembelajaran dalam konteks, yang dapat sepenuhnya memanfaatkan potensi model berdasarkan beberapa contoh contoh | Berikan instruksi dan contoh singkat secara bebas berdasarkan tugas yang diberikan. |
| BAAI/bge-multibahasa-gemma2 | Multibahasa | Model penyematan multibahasa berbasis LLM, dilatih dalam beragam bahasa dan tugas. | Memberikan instruksi berdasarkan tugas yang diberikan. |
| BAAI/bge-m3 | Multibahasa | Multi-Fungsi (pengambilan padat, pengambilan jarang, multi-vektor (colbert)), Multi-Bahasa, dan Multi-Granularitas (8192 token) | |
| LM-Koktail | Bahasa inggris | model yang disempurnakan (Llama dan BGE) yang dapat digunakan untuk mereproduksi hasil LM-Cocktail | |
| BAAI/llm-penyemat | Bahasa inggris | model penyematan terpadu untuk mendukung beragam kebutuhan augmentasi pengambilan untuk LLM | Lihat README |
| BAAI/bge-reranker-v2-m3 | Multibahasa | model cross-encoder yang ringan, memiliki kemampuan multibahasa yang kuat, mudah diterapkan, dengan inferensi cepat. | |
| BAAI/bge-reranker-v2-gemma | Multibahasa | model cross-encoder yang cocok untuk konteks multibahasa, berkinerja baik dalam kemahiran bahasa Inggris dan kemampuan multibahasa. | |
| BAAI/bge-reranker-v2-minicpm-berlapis-lapis | Multibahasa | model cross-encoder yang sesuai untuk konteks multibahasa, berkinerja baik dalam kemahiran bahasa Inggris dan Mandarin, memungkinkan kebebasan memilih lapisan untuk keluaran, memfasilitasi inferensi yang dipercepat. | |
| BAAI/bge-reranker-v2.5-gemma2-ringan | Multibahasa | model cross-encoder yang cocok untuk konteks multibahasa, berkinerja baik dalam kemahiran bahasa Inggris dan Mandarin, memberikan kebebasan untuk memilih lapisan, rasio kompresi dan kompresi lapisan untuk keluaran, memfasilitasi inferensi yang dipercepat. | |
| BAAI/bge-reranker-besar | Cina dan Inggris | model cross-encoder yang lebih akurat tetapi kurang efisien | |
| BAAI/bge-reranker-base | Cina dan Inggris | model cross-encoder yang lebih akurat tetapi kurang efisien | |
| BAAI/bge-large-en-v1.5 | Bahasa inggris | versi 1.5 dengan distribusi kesamaan yang lebih masuk akal | Represent this sentence for searching relevant passages: |
| BAAI/bge-base-en-v1.5 | Bahasa inggris | versi 1.5 dengan distribusi kesamaan yang lebih masuk akal | Represent this sentence for searching relevant passages: |
| BAAI/bge-kecil-en-v1.5 | Bahasa inggris | versi 1.5 dengan distribusi kesamaan yang lebih masuk akal | Represent this sentence for searching relevant passages: |
| BAAI/bge-besar-zh-v1.5 | Cina | versi 1.5 dengan distribusi kesamaan yang lebih masuk akal | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-base-zh-v1.5 | Cina | versi 1.5 dengan distribusi kesamaan yang lebih masuk akal | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-kecil-zh-v1.5 | Cina | versi 1.5 dengan distribusi kesamaan yang lebih masuk akal | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-besar-en | Bahasa inggris | Embedding Model yang memetakan teks ke dalam vektor | Represent this sentence for searching relevant passages: |
| BAAI/bge-base-en | Bahasa inggris | model skala dasar tetapi dengan kemampuan serupa dengan bge-large-en | Represent this sentence for searching relevant passages: |
| BAAI/bge-kecil-en | Bahasa inggris | model skala kecil tetapi dengan kinerja kompetitif | Represent this sentence for searching relevant passages: |
| BAAI/bge-besar-zh | Cina | Embedding Model yang memetakan teks ke dalam vektor | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-base-zh | Cina | model skala dasar tetapi dengan kemampuan serupa dengan bge-large-zh | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-kecil-zh | Cina | model skala kecil tetapi dengan kinerja kompetitif | 为这个句子生成表示以用于检索相关文章: |
Terima kasih kepada semua kontributor kami atas upaya mereka dan sambut hangat anggota baru untuk bergabung!
Jika Anda merasa repositori ini bermanfaat, mohon pertimbangkan untuk memberikan bintang dan kutipan
@misc{bge_m3,
title={BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation},
author={Chen, Jianlv and Xiao, Shitao and Zhang, Peitian and Luo, Kun and Lian, Defu and Liu, Zheng},
year={2023},
eprint={2309.07597},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{cocktail,
title={LM-Cocktail: Resilient Tuning of Language Models via Model Merging},
author={Shitao Xiao and Zheng Liu and Peitian Zhang and Xingrun Xing},
year={2023},
eprint={2311.13534},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{llm_embedder,
title={Retrieve Anything To Augment Large Language Models},
author={Peitian Zhang and Shitao Xiao and Zheng Liu and Zhicheng Dou and Jian-Yun Nie},
year={2023},
eprint={2310.07554},
archivePrefix={arXiv},
primaryClass={cs.IR}
}
@misc{bge_embedding,
title={C-Pack: Packaged Resources To Advance General Chinese Embedding},
author={Shitao Xiao and Zheng Liu and Peitian Zhang and Niklas Muennighoff},
year={2023},
eprint={2309.07597},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
FlagEmbedding dilisensikan di bawah Lisensi MIT.


