[Kertas] [Halaman Proyek ] [Model miniFLUX ] [Model SD3 ⚡️] [demo ?]
Ini adalah gudang resmi untuk Pyramid Flow, metode Pembuatan Video Autoregresif yang efisien dalam pelatihan berdasarkan Pencocokan Aliran . Dengan hanya berlatih pada kumpulan data sumber terbuka , ini dapat menghasilkan video berdurasi 10 detik berkualitas tinggi pada resolusi 768p dan 24 FPS, dan tentu saja mendukung pembuatan gambar-ke-video.
| 10dtk, 768p, 24fps | 5 detik, 768p, 24fps | Gambar-ke-video |
|---|---|---|
kembang api.mp4 | trailer.mp4 | minggu.mp4 |
2024.11.13 Kami merilis pos pemeriksaan miniFLUX 768p (hingga 10 detik).
Kami telah mengganti struktur model dari SD3 ke mini FLUX untuk memperbaiki masalah struktur manusia, silakan coba pos pemeriksaan gambar 1024p, pos pemeriksaan video 384p (hingga 5 detik) dan pos pemeriksaan video 768p (hingga 10 detik). Model miniflux baru menunjukkan peningkatan besar pada struktur manusia dan stabilitas gerakan
2024.10.29 ⚡️⚡️⚡️ Kami merilis kode pelatihan untuk VAE, kode penyetelan untuk DiT, dan pos pemeriksaan model baru dengan struktur FLUX yang dilatih dari awal.
2024.10.13 Inferensi multi-GPU dan pembongkaran CPU didukung. Gunakan dengan memori GPU kurang dari 8 GB , dengan kecepatan luar biasa pada banyak GPU.
2024.10.11 ??? Demo Memeluk Wajah tersedia. Terima kasih @multimodalart atas komitmennya!
2024.10.10 Kami merilis laporan teknis, halaman proyek, dan pos pemeriksaan model Pyramid Flow.
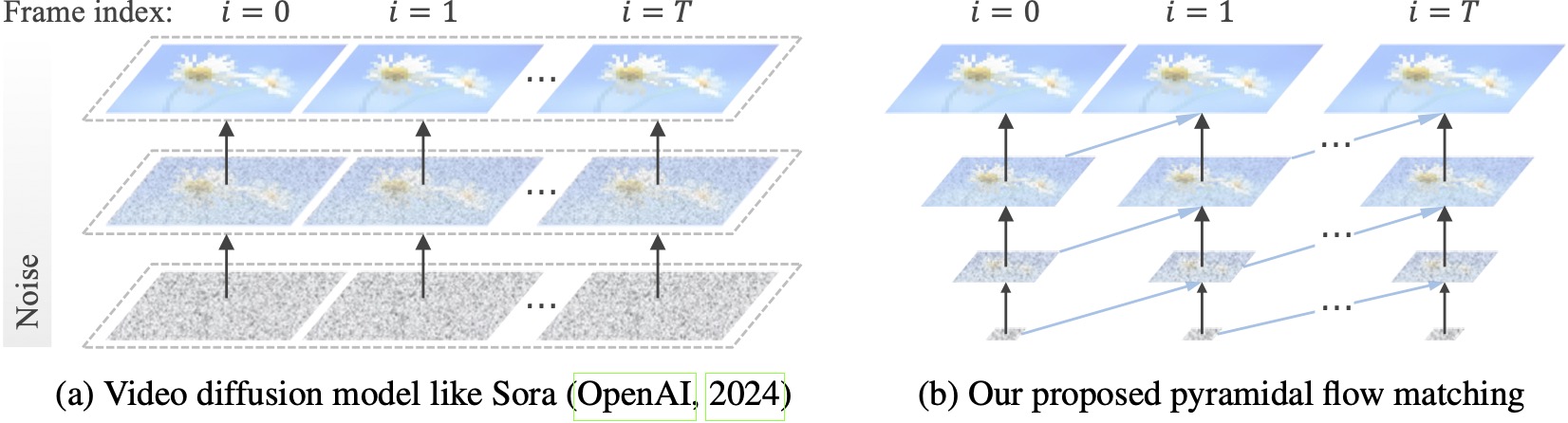
Model difusi video yang ada beroperasi pada resolusi penuh, menghabiskan banyak komputasi pada mode laten yang sangat bising. Sebaliknya, metode kami memanfaatkan fleksibilitas pencocokan aliran (Lipman et al., 2023; Liu et al., 2023; Albergo & Vanden-Eijnden, 2023) untuk melakukan interpolasi antara laten dengan resolusi dan tingkat kebisingan yang berbeda, sehingga memungkinkan pembangkitan dan dekompresi konten visual dengan efisiensi komputasi yang lebih baik. Seluruh kerangka kerja dioptimalkan secara menyeluruh dengan satu DiT (Peebles & Xie, 2023), menghasilkan video berdurasi 10 detik berkualitas tinggi pada resolusi 768p dan 24 FPS dalam 20,7 ribu jam pelatihan GPU A100.
Kami merekomendasikan pengaturan lingkungan dengan conda. Basis kode saat ini menggunakan Python 3.8.10 dan PyTorch 2.1.2 (panduan), dan kami secara aktif berupaya mendukung versi yang lebih luas.
git clone https://github.com/jy0205/Pyramid-Flow
cd Pyramid-Flow
# create env using conda
conda create -n pyramid python==3.8.10
conda activate pyramid
pip install -r requirements.txtKemudian download modelnya dari Huggingface (ada dua varian: miniFLUX atau SD3). Model miniFLUX mendukung pembuatan gambar 1024p, video 384p dan 768p, dan model berbasis SD3 mendukung pembuatan video 768p dan 384p. Pos pemeriksaan 384p menghasilkan video berdurasi 5 detik pada 24FPS, sedangkan pos pemeriksaan 768p menghasilkan video hingga 10 detik pada 24FPS.
from huggingface_hub import snapshot_download
model_path = 'PATH' # The local directory to save downloaded checkpoint
snapshot_download ( "rain1011/pyramid-flow-miniflux" , local_dir = model_path , local_dir_use_symlinks = False , repo_type = 'model' )Untuk memulai, instal Gradio terlebih dahulu, atur jalur model Anda di #L36, lalu jalankan di mesin lokal Anda:
python app.pyDemo Gradio akan dibuka di browser. Terima kasih kepada @tpc2233 yang melakukan commit, lihat #48 untuk detailnya.
Atau, cobalah dengan mudah di Hugging Face Space? dibuat oleh @multimodalart. Karena keterbatasan GPU, demo online ini hanya dapat menghasilkan 25 frame (diekspor pada 8FPS atau 24FPS). Gandakan ruang untuk menghasilkan video yang lebih panjang.
Untuk segera mencoba Pyramid Flow di Google Colab, jalankan kode di bawah ini:
# Setup
!git clone https://github.com/jy0205/Pyramid-Flow
%cd Pyramid-Flow
!pip install -r requirements.txt
!pip install gradio
# This code downloads miniFLUX
from huggingface_hub import snapshot_download
model_path = '/content/Pyramid-Flow'
snapshot_download("rain1011/pyramid-flow-miniflux", local_dir=model_path, local_dir_use_symlinks=False, repo_type='model')
# Start
!python app.py
Untuk menggunakan model kami, ikuti kode inferensi di video_generation_demo.ipynb di tautan ini. Kami sangat menyarankan Anda untuk mencoba piramida-miniflux terbaru yang diterbitkan, yang menunjukkan peningkatan besar pada struktur manusia dan stabilitas gerak. Setel parameter model_name ke pyramid_flux yang akan digunakan. Kami selanjutnya menyederhanakannya menjadi prosedur dua langkah berikut. Pertama, muat model yang diunduh:
import torch
from PIL import Image
from pyramid_dit import PyramidDiTForVideoGeneration
from diffusers . utils import load_image , export_to_video
torch . cuda . set_device ( 0 )
model_dtype , torch_dtype = 'bf16' , torch . bfloat16 # Use bf16 (not support fp16 yet)
model = PyramidDiTForVideoGeneration (
'PATH' , # The downloaded checkpoint dir
model_name = "pyramid_flux" ,
model_dtype ,
model_variant = 'diffusion_transformer_768p' ,
)
model . vae . enable_tiling ()
# model.vae.to("cuda")
# model.dit.to("cuda")
# model.text_encoder.to("cuda")
# if you're not using sequential offloading bellow uncomment the lines above ^
model . enable_sequential_cpu_offload ()Kemudian, Anda dapat mencoba pembuatan teks-ke-video sesuai permintaan Anda sendiri. Perhatikan bahwa versi 384p sekarang hanya mendukung 5 (setel suhu hingga 16)!
prompt = "A movie trailer featuring the adventures of the 30 year old space man wearing a red wool knitted motorcycle helmet, blue sky, salt desert, cinematic style, shot on 35mm film, vivid colors"
# used for 384p model variant
# width = 640
# height = 384
# used for 768p model variant
width = 1280
height = 768
with torch . no_grad (), torch . cuda . amp . autocast ( enabled = True , dtype = torch_dtype ):
frames = model . generate (
prompt = prompt ,
num_inference_steps = [ 20 , 20 , 20 ],
video_num_inference_steps = [ 10 , 10 , 10 ],
height = height ,
width = width ,
temp = 16 , # temp=16: 5s, temp=31: 10s
guidance_scale = 7.0 , # The guidance for the first frame, set it to 7 for 384p variant
video_guidance_scale = 5.0 , # The guidance for the other video latent
output_type = "pil" ,
save_memory = True , # If you have enough GPU memory, set it to `False` to improve vae decoding speed
)
export_to_video ( frames , "./text_to_video_sample.mp4" , fps = 24 )Sebagai model autoregresif, model kami juga mendukung pembuatan gambar-ke-video (yang dikondisikan teks):
# used for 384p model variant
# width = 640
# height = 384
# used for 768p model variant
width = 1280
height = 768
image = Image . open ( 'assets/the_great_wall.jpg' ). convert ( "RGB" ). resize (( width , height ))
prompt = "FPV flying over the Great Wall"
with torch . no_grad (), torch . cuda . amp . autocast ( enabled = True , dtype = torch_dtype ):
frames = model . generate_i2v (
prompt = prompt ,
input_image = image ,
num_inference_steps = [ 10 , 10 , 10 ],
temp = 16 ,
video_guidance_scale = 4.0 ,
output_type = "pil" ,
save_memory = True , # If you have enough GPU memory, set it to `False` to improve vae decoding speed
)
export_to_video ( frames , "./image_to_video_sample.mp4" , fps = 24 )Kami juga mendukung dua jenis pembongkaran CPU untuk mengurangi kebutuhan memori GPU. Perhatikan bahwa mereka mungkin mengorbankan efisiensi.
cpu_offloading=True ke fungsi generate memungkinkan inferensi dengan memori GPU kurang dari 12 GB . Fitur ini disumbangkan oleh @Ednaordinary, lihat #23 untuk detailnya.model.enable_sequential_cpu_offload() sebelum prosedur di atas memungkinkan inferensi dengan memori GPU kurang dari 8 GB . Fitur ini disumbangkan oleh @rodjjo, lihat #75 untuk detailnya. Terima kasih kepada @niw, pengguna Apple Silicon (misalnya MacBook Pro dengan M2 24GB) juga dapat mencoba model kami menggunakan backend MPS! Silakan lihat #113 untuk detailnya.
Untuk pengguna dengan banyak GPU, kami menyediakan skrip inferensi yang menggunakan paralelisme urutan untuk menghemat memori pada setiap GPU. Hal ini juga menghadirkan peningkatan yang luar biasa, hanya membutuhkan 2,5 menit untuk menghasilkan video 5 detik, 768p, 24fps pada 4 GPU A100 (vs. 5,5 menit pada satu GPU A100). Jalankan pada 2 GPU dengan perintah berikut:
CUDA_VISIBLE_DEVICES=0,1 sh scripts/inference_multigpu.shSaat ini mendukung 2 atau 4 GPU (Untuk Versi SD3), dengan lebih banyak konfigurasi tersedia dalam skrip asli. Anda juga dapat meluncurkan demo multi-GPU Gradio yang dibuat oleh @tpc2233, lihat #59 untuk detailnya.
Spoiler: Kami bahkan tidak menggunakan paralelisme urutan dalam pelatihan, berkat desain aliran piramida kami yang efisien.
guidance_scale mengontrol kualitas visual. Kami menyarankan penggunaan panduan dalam [7, 9] untuk pos pemeriksaan 768p selama pembuatan teks-ke-video, dan 7 untuk pos pemeriksaan 384p.video_guidance_scale mengontrol gerakan. Nilai yang lebih besar akan meningkatkan derajat dinamis dan mengurangi degradasi generasi autoregresif, sementara nilai yang lebih kecil akan menstabilkan video.Persyaratan hardware untuk pelatihan VAE minimal 8 GPU A100. Silakan merujuk ke dokumen ini. Ini adalah VAE 3D berkelanjutan seperti MAGVIT-v2, yang seharusnya cukup fleksibel. Jangan ragu untuk membuat model generatif video Anda sendiri pada bagian kode pelatihan VAE ini.
Persyaratan hardware untuk finetuning DiT minimal 8 GPU A100. Silakan merujuk ke dokumen ini. Kami memberikan instruksi untuk Pyramid Flow versi autoregresif dan non-autoregresif. Yang pertama lebih berorientasi pada penelitian dan yang kedua lebih stabil (tetapi kurang efisien tanpa piramida temporal).
Contoh video berikut dihasilkan pada 5s, 768p, 24fps. Untuk hasil lebih lanjut, silakan kunjungi halaman proyek kami.
tokyo.mp4 | eiffel.mp4 |
gelombang.mp4 | rel.mp4 |
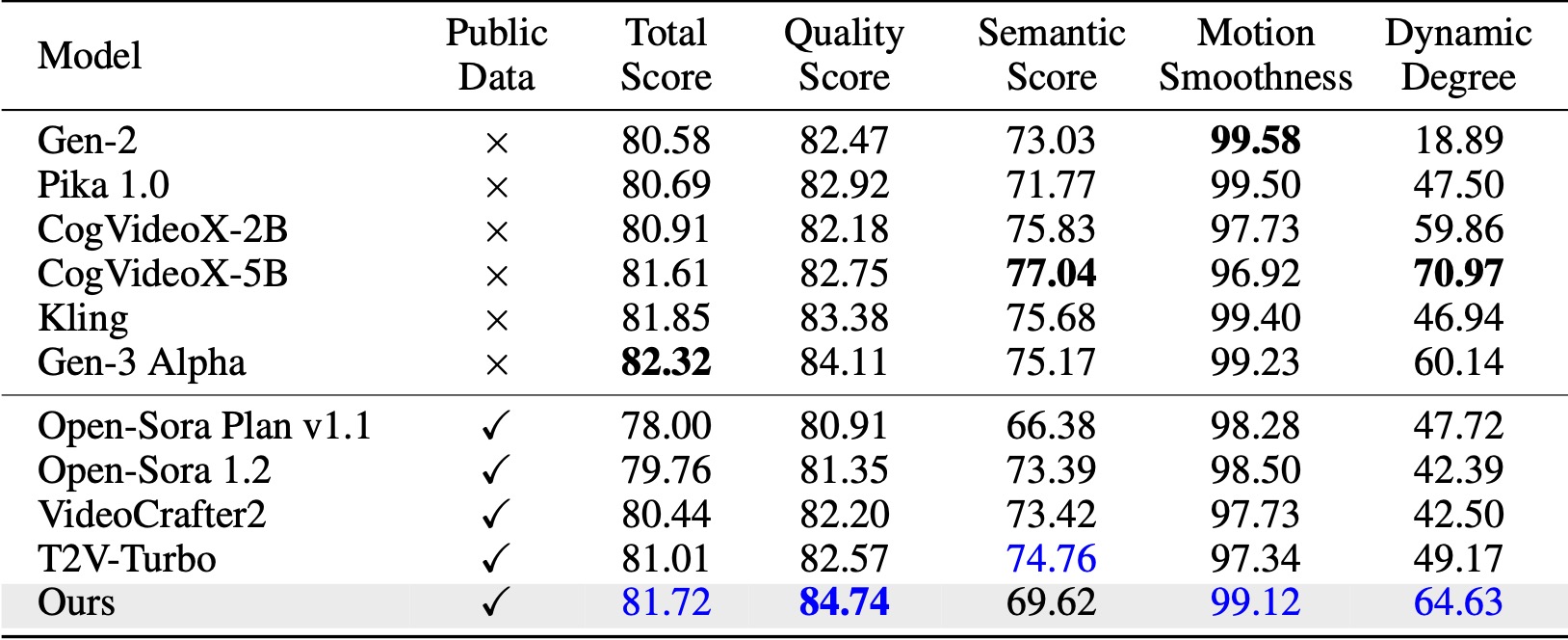
Di VBench (Huang et al., 2024), metode kami melampaui semua data dasar sumber terbuka yang dibandingkan. Bahkan hanya dengan data video publik, model ini mencapai performa yang sebanding dengan model komersial seperti Kling (Kuaishou, 2024) dan Gen-3 Alpha (Runway, 2024), terutama dalam skor kualitas (84,74 vs. 84,11 pada Gen-3) dan kehalusan gerakan .
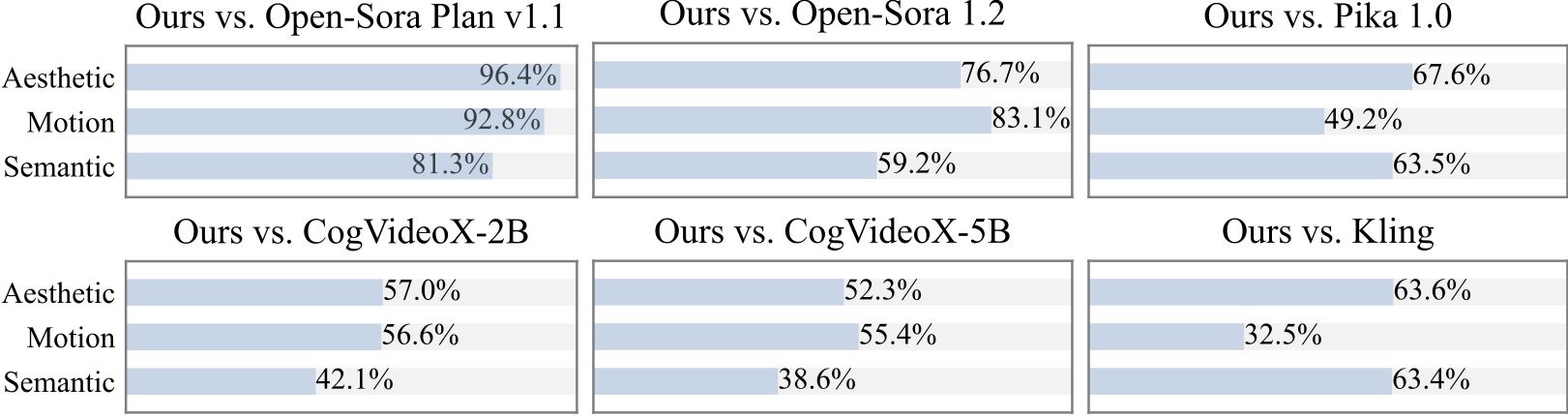
Kami melakukan studi pengguna tambahan dengan 20+ peserta. Seperti yang dapat dilihat, metode kami lebih disukai dibandingkan model sumber terbuka seperti Open-Sora dan CogVideoX-2B terutama dalam hal kelancaran gerakan.
Kami berterima kasih atas proyek luar biasa berikut saat mengimplementasikan Pyramid Flow:
Pertimbangkan untuk memberi bintang pada repositori ini dan mengutip Pyramid Flow dalam publikasi Anda jika itu membantu penelitian Anda.
@article{jin2024pyramidal,
title={Pyramidal Flow Matching for Efficient Video Generative Modeling},
author={Jin, Yang and Sun, Zhicheng and Li, Ningyuan and Xu, Kun and Xu, Kun and Jiang, Hao and Zhuang, Nan and Huang, Quzhe and Song, Yang and Mu, Yadong and Lin, Zhouchen},
jounal={arXiv preprint arXiv:2410.05954},
year={2024}
}


