Facebook Messenger Bot
1.0.0
Chatbot FB Messenger yang saya latih untuk berbicara seperti saya. Postingan blog terkait.
Untuk proyek ini, saya ingin melatih model Sequence To Sequence pada log percakapan saya sebelumnya dari berbagai situs media sosial. Anda dapat membaca lebih lanjut tentang motivasi di balik pendekatan ini, detail model ML, dan tujuan setiap skrip Python di postingan blog, namun saya ingin menggunakan README ini untuk menjelaskan bagaimana Anda dapat melatih chatbot Anda sendiri untuk berbicara seperti Anda .
Untuk menjalankan skrip ini, Anda memerlukan perpustakaan berikut.
Unduh dan ekstrak seluruh repositori ini dari GitHub, baik secara interaktif, atau dengan memasukkan yang berikut ini di Terminal Anda.
git clone https://github.com/adeshpande3/Facebook-Messenger-Bot.gitArahkan ke direktori teratas repo di mesin Anda
cd Facebook-Messenger-BotTugas pertama kami adalah mengunduh semua data percakapan Anda dari berbagai situs media sosial. Bagi saya, saya menggunakan Facebook, Google Hangouts, dan LinkedIn. Jika Anda memiliki situs lain tempat Anda mendapatkan data, tidak apa-apa. Anda hanya perlu membuat metode baru di createDataset.py.
Data Facebook : Unduh data Anda dari sini. Setelah diunduh, Anda akan memiliki file yang cukup besar bernama messages.htm . Ini akan menjadi file yang cukup besar (lebih dari 190 MB bagi saya). Kita perlu menguraikan file besar ini, dan mengekstrak semua percakapan. Untuk melakukan ini, kami akan menggunakan alat yang bersumber terbuka dari Dillon Dixon. Anda akan melanjutkan dan menginstal alat itu dengan menjalankannya
pip install fbchat-archive-parserdan kemudian berjalan:
fbcap ./messages.htm > fbMessages.txtIni akan memberi Anda semua percakapan Facebook Anda dalam satu file teks yang cukup terpadu. Terima kasih Dillon! Silakan simpan file itu di folder Facebook-Messenger-Bot Anda.
Data LinkedIn : Unduh data Anda dari sini. Setelah diunduh, Anda akan melihat file inbox.csv . Kami tidak perlu mengambil langkah lain apa pun di sini, kami hanya ingin menyalinnya ke folder kami.
Data Google Hangouts : Unduh formulir data Anda di sini. Setelah diunduh, Anda akan mendapatkan file JSON yang perlu kami uraikan. Untuk melakukan ini, kami akan menggunakan parser yang ditemukan melalui postingan blog fenomenal ini. Kami ingin menyimpan data ke dalam file teks, dan kemudian menyalin folder tersebut ke folder kami.
Pada akhir semua ini, Anda akan memiliki struktur direktori yang terlihat seperti ini. Pastikan Anda mengganti nama folder dan nama file jika milik Anda berbeda.
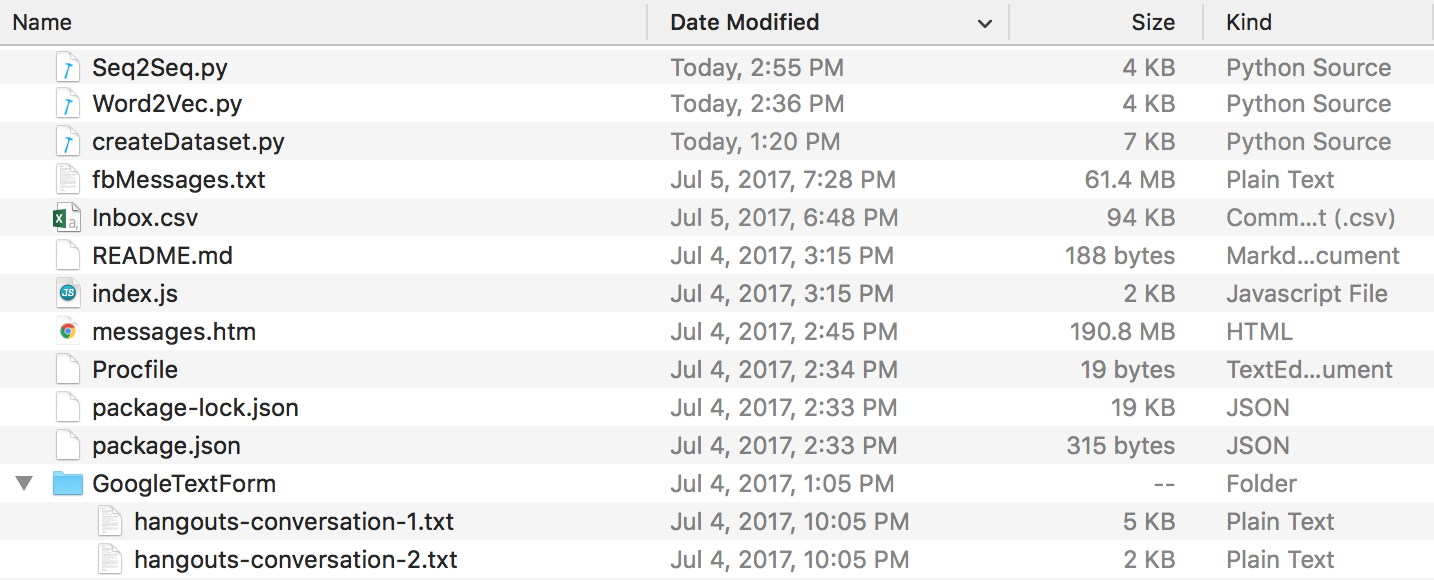
Data Perselisihan : Anda dapat mengekstrak log obrolan perselisihan Anda dengan menggunakan DiscordChatExporter luar biasa yang dibuat oleh Tyrrrz. Ikuti dokumentasinya untuk mengekstrak log obrolan tunggal yang Anda inginkan dalam format .txt (ini penting). Anda kemudian dapat meletakkan semuanya dalam folder bernama DiscordChatLogs di direktori repo.
Data WhatsApp : Pastikan Anda memiliki ponsel dan masukkan dalam format tanggal AS jika belum (ini akan menjadi penting nanti ketika Anda mengurai file log ke .csv). Anda tidak dapat menggunakan web WhatsApp untuk tujuan ini. Buka obrolan yang ingin Anda kirim, ketuk tombol menu, ketuk lainnya, lalu klik "Email Obrolan". Kirim email ke diri Anda sendiri dan unduh ke komputer Anda. Ini akan memberi Anda file .txt, untuk menguraikannya, kami akan mengonversinya menjadi .csv. Untuk melakukan ini, buka tautan ini dan masukkan semua teks di file log Anda. Klik ekspor, unduh file csv dan simpan saja di folder Facebook-Messenger-Bot Anda dengan nama "whatsapp_chats.csv".
CATATAN : Parser yang disediakan pada tautan di atas tampaknya telah dihapus. Jika Anda masih memiliki file .csv dalam format yang benar , Anda masih dapat menggunakannya. Jika tidak, unduh log obrolan whatsapp Anda sebagai file .txt dan letakkan semuanya di folder bernama WhatsAppChatLogs di direktori repo. createDataset.py akan bekerja dengan file-file ini jika, dan hanya jika, TIDAK menemukan file .csv bernama whatsapp_chats.csv .
Jika Anda menggunakan log obrolan .txt , perhatikan bahwa format yang diharapkan adalah-
[20.06.19, 15:58:57] Loris: Welcome to the chat example
[20.06.19, 15:59:07] John: Thanks
(ATAU)
12/28/19, 21:43 - Loris: Welcome to the chat example
12/28/19, 21:43 - John: Thanks
Sekarang kita memiliki semua log percakapan dalam format yang bersih, kita dapat melanjutkan dan membuat kumpulan data. Di direktori kami, mari jalankan:
python createDataset.pyAnda kemudian akan diminta untuk memasukkan nama Anda (sehingga skrip mengetahui siapa yang harus dicari), dan situs media sosial mana yang datanya Anda miliki. Script ini akan membuat file bernama percakapanDictionary.npy yang merupakan objek Numpy yang berisi pasangan berupa (FRIENDS_MESSAGE, RESPONSE ANDA). File bernama percakapanData.txt juga akan dibuat. Ini hanyalah sebuah file teks besar data kamus dalam bentuk terpadu.
Sekarang kita memiliki 2 file tersebut, kita dapat mulai membuat vektor kata melalui model Word2Vec. Langkah ini sedikit berbeda dari yang lain. Fungsi Tensorflow yang kita lihat nanti (di seq2seq.py) sebenarnya juga menangani bagian penyematan. Jadi Anda dapat memutuskan untuk melatih vektor Anda sendiri atau meminta fungsi seq2seq melakukannya bersama-sama, itulah yang akhirnya saya lakukan. Jika Anda ingin membuat vektor kata Anda sendiri melalui Word2Vec, ucapkan y saat diminta (setelah menjalankan perintah berikut). Jika tidak, tidak apa-apa, balas n dan fungsi ini hanya akan membuat wordList.txt.
python Word2Vec.pyJika Anda menjalankan word2vec.py secara keseluruhan, ini akan menghasilkan 4 file berbeda. Word2VecXTrain.npy dan Word2VecYTrain.npy adalah matriks pelatihan yang akan digunakan Word2Vec. Kami menyimpannya di folder kami, jika kami perlu melatih model Word2Vec kami lagi dengan hyperparameter yang berbeda. Kami juga menyimpan wordList.txt , yang berisi semua kata unik di korpus kami. File terakhir yang disimpan adalah embeddingMatrix.npy yang merupakan matriks Numpy yang berisi semua vektor kata yang dihasilkan.
Sekarang, kita dapat menggunakan buat dan latih model Seq2Seq kita.
python Seq2Seq.pyIni akan membuat 3 atau lebih file berbeda. Seq2SeqXTrain.npy dan Seq2SeqYTrain.npy adalah matriks pelatihan yang akan digunakan Seq2Seq. Sekali lagi, kami menyimpannya untuk berjaga-jaga jika kami ingin membuat perubahan pada arsitektur model kami, dan kami tidak ingin menghitung ulang set pelatihan kami. File terakhir adalah file .ckpt yang menyimpan model Seq2Seq yang kita simpan. Model akan disimpan pada periode waktu yang berbeda dalam loop pelatihan. Ini akan digunakan dan diterapkan setelah kita membuat chatbot.
Sekarang kita telah menyimpan modelnya, sekarang mari kita buat chatbot Facebook kita. Untuk melakukannya, saya sarankan mengikuti tutorial ini. Anda tidak perlu membaca apa pun di bawah bagian "Sesuaikan apa yang dikatakan bot". Model Seq2Seq kami akan menangani bagian itu. PENTING - Tutorial ini akan meminta Anda untuk membuat folder baru tempat proyek Node berada. Perlu diingat folder ini akan berbeda dengan folder kita. Anda dapat menganggap folder ini sebagai tempat prapemrosesan data dan pelatihan model kami, sementara folder lainnya dikhususkan untuk aplikasi Express (EDIT: Saya yakin Anda dapat mengikuti langkah-langkah tutorial di dalam folder kami dan cukup membuat proyek Node, File Procfile, dan index.js di sini jika Anda mau). Tutorialnya sendiri sudah cukup, tapi berikut ringkasan langkah-langkahnya.
Setelah mengikuti langkah-langkah dengan benar, Anda seharusnya dapat mengirim pesan ke chatbot, dan mendapatkan tanggapan balik.
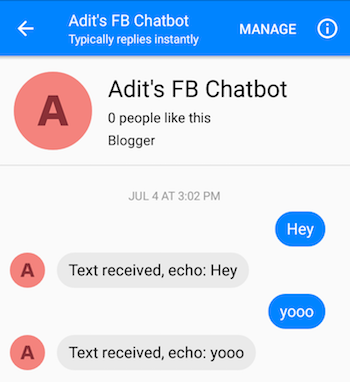
Ah, kamu hampir selesai! Sekarang, kita harus membuat server Flask tempat kita dapat menerapkan model Seq2Seq yang kita simpan. Saya memiliki kode untuk server itu di sini. Mari kita bicara tentang struktur umumnya. Server Flask biasanya memiliki satu file .py utama tempat Anda menentukan semua titik akhir. Ini akan menjadi app.py dalam kasus kami. Di sinilah kita memuat model kita. Anda harus membuat folder bernama 'model', dan mengisinya dengan 4 file (file pos pemeriksaan, file data, file indeks, dan file meta). Ini adalah file yang dibuat saat Anda menyimpan model Tensorflow.

Dalam file app.py ini, kami ingin membuat rute (/prediksi dalam kasus saya) di mana masukan ke rute akan dimasukkan ke dalam model simpanan kami, dan keluaran dekoder adalah string yang dikembalikan. Silakan lihat lebih dekat app.py jika itu masih agak membingungkan. Sekarang setelah Anda memiliki app.py dan model Anda (dan file pembantu lainnya jika Anda membutuhkannya), Anda dapat menerapkan server Anda. Kami akan menggunakan Heroku lagi. Ada banyak tutorial berbeda tentang penerapan server Flask ke Heroku, tapi saya sangat menyukai yang ini (Tidak memerlukan bagian Foreman dan Logging).
Ini dia. Anda seharusnya dapat mengirim pesan ke chatbot, dan melihat beberapa tanggapan menarik yang (mudah-mudahan) mirip dengan Anda.
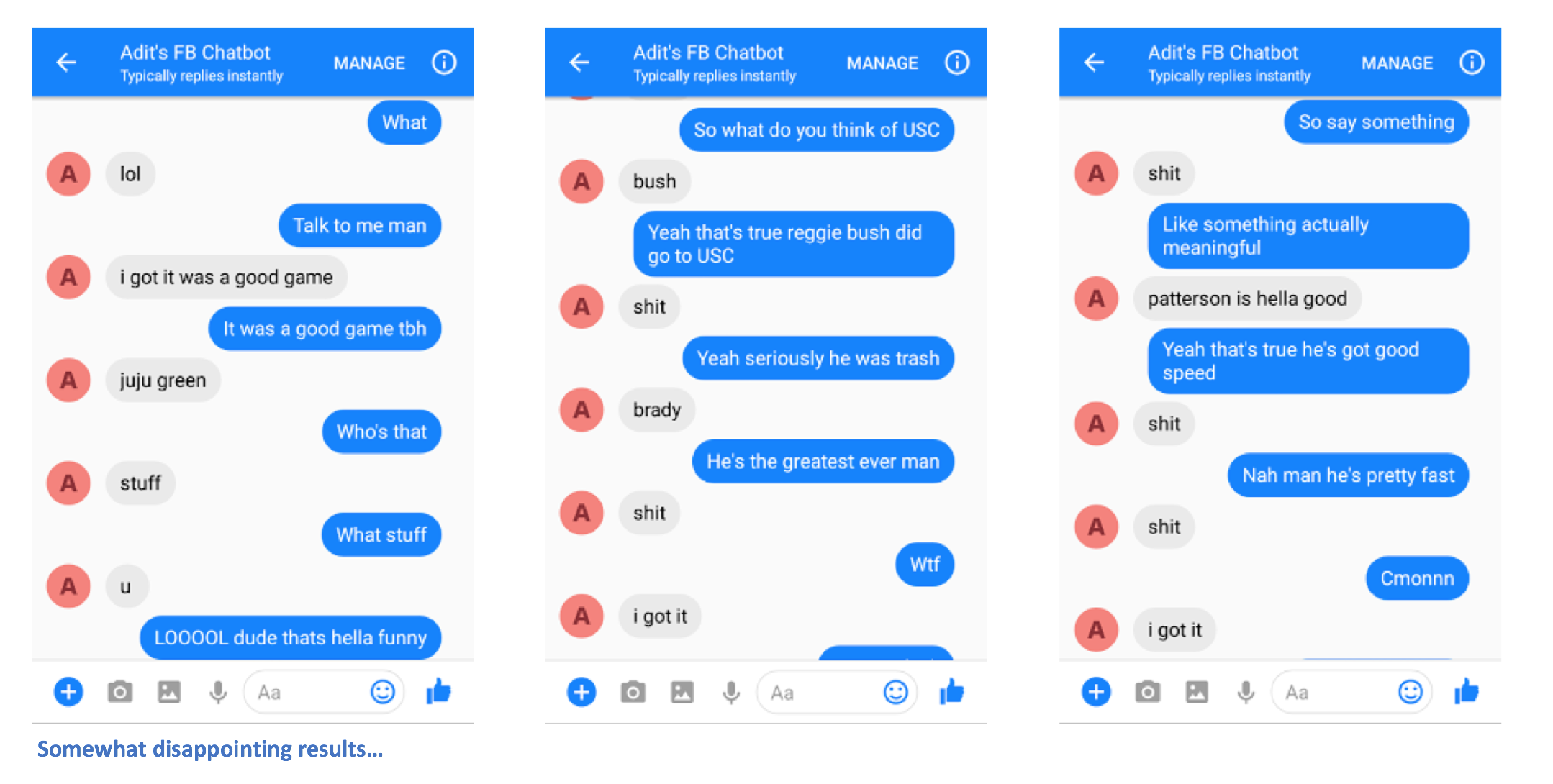
Tolong beri tahu saya jika Anda memiliki masalah atau jika Anda memiliki saran untuk menjadikan README ini lebih baik. Jika menurut Anda ada langkah tertentu yang tidak jelas, beri tahu saya dan saya akan berusaha sebaik mungkin mengedit README dan membuat klarifikasi.


