RLAIF V
1.0.0

Menyelaraskan MLLM melalui Umpan Balik AI Sumber Terbuka untuk Kepercayaan Super GPT-4V
中文 | Bahasa inggris
[26.11.2024] Kami mendukung pelatihan LoRA sekarang!
[28/05/2024] Makalah kami dapat diakses di arXiv sekarang!
[2024.05.20] Kumpulan Data RLAIF-V kami digunakan untuk melatih MiniCPM-Llama3-V 2.5, yang mewakili MLLM level GPT-4V sisi akhir pertama!
[20.05.2024] Kami membuat kode, bobot (7B, 12B) dan data RLAIF-V menjadi sumber terbuka!
Kami memperkenalkan RLAIF-V, kerangka kerja baru yang menyelaraskan MLLM dalam paradigma sumber terbuka sepenuhnya untuk kepercayaan super GPT-4V. RLAIF-V memanfaatkan umpan balik sumber terbuka secara maksimal dari dua perspektif utama, termasuk data umpan balik berkualitas tinggi dan algoritma pembelajaran umpan balik online. Fitur penting dari RLAIF-V meliputi:
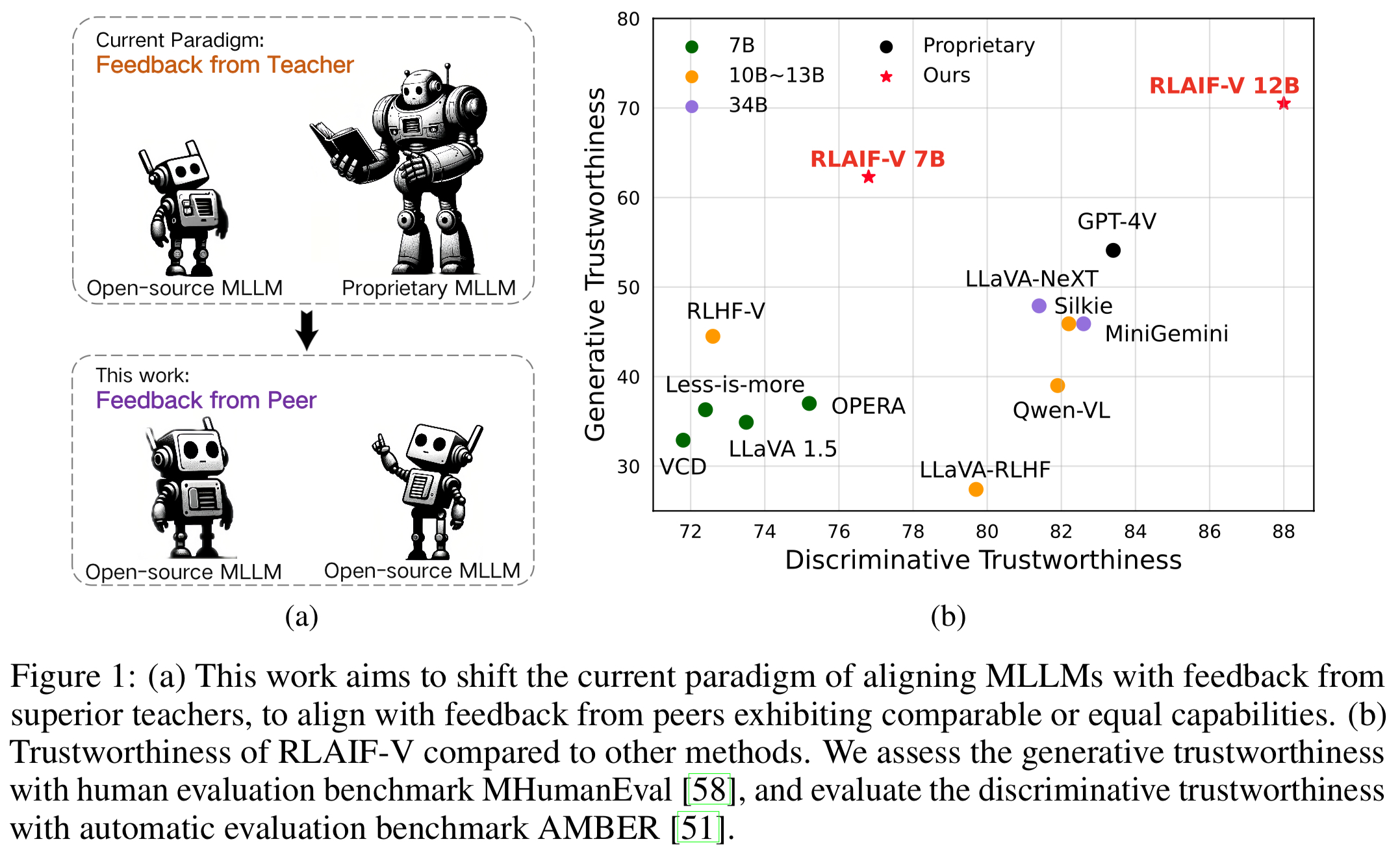
Kepercayaan Super GPT-4V melalui Masukan Sumber Terbuka . Dengan belajar dari masukan AI sumber terbuka, RLAIF-V 12B mencapai tingkat kepercayaan super GPT-4V dalam tugas generatif dan diskriminatif.
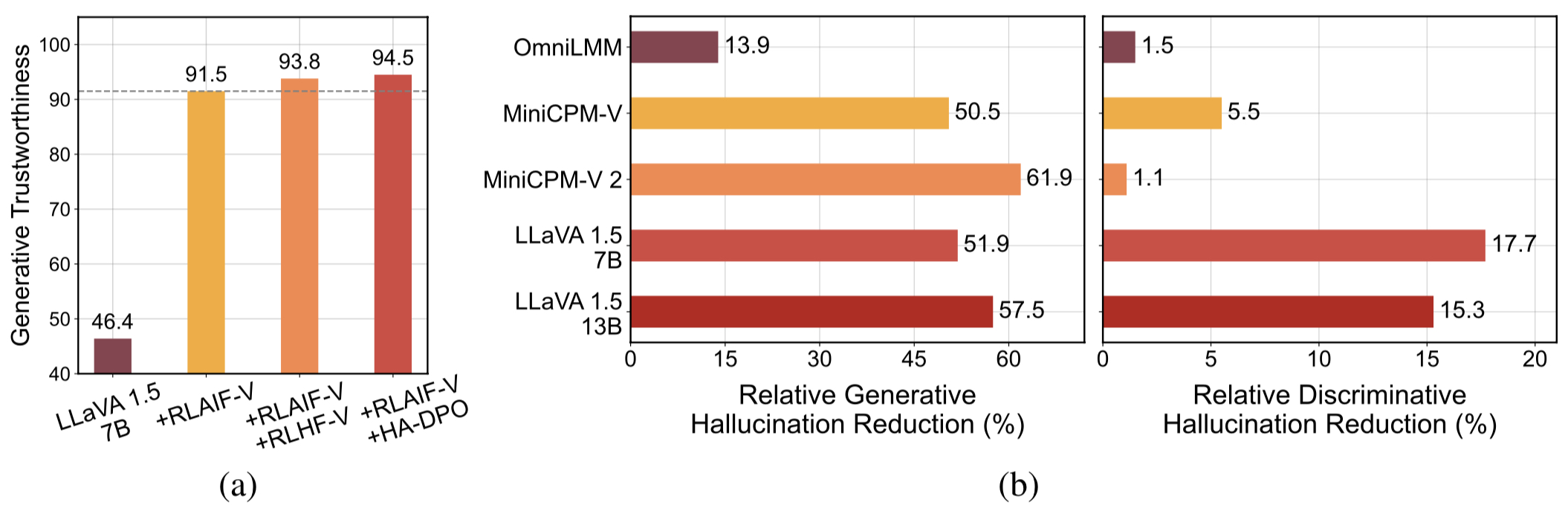
Data Umpan Balik yang Dapat Digeneralisasikan Berkualitas Tinggi . Data umpan balik yang digunakan oleh RLAIF-V secara efektif mengurangi halusinasi MLLM yang berbeda .
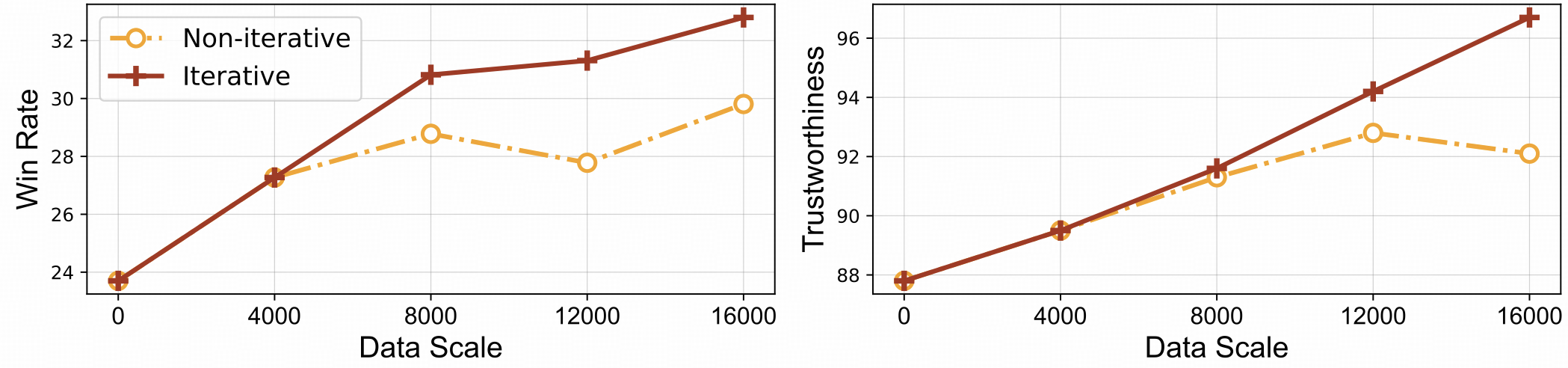
⚡️ Pembelajaran Umpan Balik yang Efisien dengan Penyelarasan Iteratif. RLAIF-V menunjukkan efisiensi pembelajaran yang lebih baik dan kinerja yang lebih tinggi dibandingkan dengan pendekatan non-iteratif.
Kumpulan data
Memasang
Bobot Model
Kesimpulan
Pembuatan Data
Kereta
Evaluasi
Objek HalBench
Bangku MMHal
Perombakan MB
Kutipan
Kami menyajikan Kumpulan Data RLAIF-V, yang merupakan kumpulan data preferensi yang dihasilkan AI yang mencakup beragam tugas dan domain. Kumpulan data preferensi multimodal sumber terbuka ini berisi 83.132 pasangan perbandingan berkualitas tinggi . Kumpulan data berisi pasangan preferensi yang dihasilkan di setiap iterasi pelatihan model yang berbeda, termasuk LLaVA 1.5 7B, OmniLMM 12B, dan MiniCPM-V.
Kloning repositori ini dan navigasikan ke folder RLAIF-V
git klon https://github.com/RLHF-V/RLAIF-V.gitcd RLAIF-V
Instal paket
conda buat -n rlaifv python=3.10 -y conda aktifkan rlaifv instalasi pip -e .
Instal model spaCy yang diperlukan
dapatkan https://github.com/explosion/spacy-models/releases/download/en_core_web_trf-3.7.3/en_core_web_trf-3.7.3.tar.gz pip instal en_core_web_trf-3.7.3.tar.gz
| Model | Keterangan | Unduh |
|---|---|---|
| RLAIF-V 7B | Varian paling tepercaya di LLaVA 1.5 | ? |
| RLAIF-V 12B | Berdasarkan OmniLMM-12B, mencapai tingkat kepercayaan super GPT-4V. | ? |
Kami memberikan contoh sederhana untuk menunjukkan cara menggunakan RLAIF-V.
dari chat import RLAIFVChat, img2base64chat_model = RLAIFVChat('openBMB/RLAIF-V-7B') # atau 'openBMB/RLAIF-V-12B'image_path="./examples/test.jpeg"msgs = "Jelaskan secara detail orang-orang di gambar."inputs = {"image": image_path, "question": pesan}jawaban = chat_model.chat(masukan)cetak(jawaban)Anda juga dapat menjalankan contoh ini dengan menjalankan skrip berikut:
python obrolan.py

Pertanyaan:
Mengapa mobil di gambar berhenti?
Output yang diharapkan:
Dalam gambar tersebut, sebuah mobil berhenti di jalan karena adanya seekor domba di jalan tersebut. Mobil tersebut kemungkinan besar berhenti agar domba dapat menyingkir dengan aman atau menghindari potensi kecelakaan dengan hewan tersebut. Situasi ini menyoroti pentingnya berhati-hati dan penuh perhatian saat mengemudi, terutama di daerah di mana hewan mungkin berkeliaran di dekat jalan raya.
Pengaturan Lingkungan
Kami menyediakan model OmniLMM 12B dan model MiniCPM-Llama3-V 2.5 untuk menghasilkan umpan balik. Jika Anda ingin menggunakan MiniCPM-Llama3-V 2.5 untuk memberikan umpan balik, harap konfigurasikan lingkungan inferensinya sesuai dengan petunjuk di repositori GitHub MiniCPM-V.
Silakan unduh model Llama3 8B kami yang telah disempurnakan: model terpisah dan model transformasi pertanyaan, dan simpan masing-masing di folder ./models/llama3_split dan folder ./models/llama3_changeq .
Umpan Balik Model OmniLMM 12B
Skrip berikut menunjukkan penggunaan model LLaVA-v1.5-7b untuk menghasilkan jawaban kandidat dan model OmniLMM 12B untuk memberikan umpan balik.
mkdir ./hasil pesta ./script/data_gen/run_data_pipeline_llava15_omni.sh
Umpan Balik Model MiniCPM-Llama3-V 2.5
Skrip berikut menunjukkan penggunaan model LLaVA-v1.5-7b untuk menghasilkan jawaban kandidat dan model MiniCPM-Llama3-V 2.5 untuk memberikan masukan. Pertama, ganti minicpmv_python di ./script/data_gen/run_data_pipeline_llava15_minicpmv.sh dengan jalur Python dari lingkungan MiniCPM-V yang Anda buat.
mkdir ./hasil pesta ./script/data_gen/run_data_pipeline_llava15_minicpmv.sh
Siapkan data (Opsional)
Jika Anda dapat mengakses dataset pelukan, Anda dapat melewati langkah ini, kami akan secara otomatis mendownload Dataset RLAIF-V.
Jika Anda sudah mengunduh kumpulan data, Anda dapat mengganti 'openbmb/RLAIF-V-Dataset' ke jalur kumpulan data Anda di sini di Baris 38.
Pelatihan
Di sini kami menyediakan skrip pelatihan untuk melatih model dalam 1 iterasi . Parameter max_step harus disesuaikan dengan jumlah data Anda.
Penyempurnaan Sepenuhnya
Jalankan perintah berikut untuk memulai penyempurnaan sepenuhnya.
pesta ./script/train/llava15_train.sh
LoRA
Jalankan perintah berikut untuk memulai pelatihan lora.
pip instal peft pesta ./script/train/llava15_train_lora.sh
Penyelarasan berulang
Untuk mereproduksi proses pelatihan berulang di makalah, Anda perlu melakukan langkah-langkah berikut sebanyak 4 kali:
S1. Pembuatan data.
Ikuti instruksi dalam pembuatan data untuk menghasilkan pasangan preferensi untuk model dasar. Konversikan file jsonl yang dihasilkan menjadi parket huggingface.
S2. Ubah konfigurasi pelatihan.
Dalam kode kumpulan data, ganti 'openbmb/RLAIF-V-Dataset' di sini dengan jalur data Anda.
Dalam skrip pelatihan, ganti --data_dir dengan direktori baru, ganti --model_name_or_path dengan jalur model dasar, setel --max_step ke jumlah langkah untuk 4 epoch, setel --save_steps ke jumlah langkah untuk 1/4 epoch .
S3. Lakukan pelatihan DPO.
Jalankan skrip pelatihan untuk melatih model dasar.
S4. Pilih model dasar untuk iterasi berikutnya.
Evaluasi setiap checkpoint pada Object HalBench dan MMHal Bench, pilih checkpoint dengan kinerja terbaik sebagai model dasar pada iterasi berikutnya.
Siapkan anotasi COCO2014
Evaluasi Object HalBench bergantung pada keterangan dan anotasi segmentasi dari dataset COCO2014. Silakan unduh terlebih dahulu dataset COCO2014 dari situs resmi dataset COCO.
mkdir coco2014cd coco2014 dapatkan http://images.cocodataset.org/annotations/annotations_trainval2014.zip buka zip annotations_trainval2014.zip
Inferensi, evaluasi, dan ringkasan
Harap ganti {YOUR_OPENAI_API_KEY} dengan kunci api OpenAI yang valid.
Catatan: Evaluasi didasarkan pada gpt-3.5-turbo-0613 .
# cd RLAIF-Vbash ./script/eval/eval_rlaifv_objhal.sh ./RLAIF-V_weight ./results/RLAIF-V ./coco2014/annotations {YOUR_OPENAI_API_KEY}Siapkan Data MMHal
Silakan unduh data evaluasi MMHal di sini, dan simpan file di eval/data .
Jalankan skrip berikut untuk menghasilkan MMHal Bench:
Catatan: Evaluasi didasarkan pada gpt-4-1106-preview .
# cd RLAIF-Vbash ./script/eval/eval_rlaifv_mmhal.sh ./RLAIF-V_weight ./results/RLAIF-V {YOUR_OPENAI_API_KEY}Persiapan
Untuk menggunakan evaluasi GPT-4, jalankan terlebih dahulu pip install openai==0.28 untuk menginstal paket openai. Selanjutnya, ubah openai.base dan openai.api_key di eval/gpt4.py ke pengaturan Anda sendiri.
Data evaluasi untuk set dev dapat ditemukan di eval/data/RefoMB_dev.jsonl . Anda perlu mengunduh setiap gambar dari kunci image_url di setiap baris.
Evaluasi untuk skor keseluruhan
Simpan jawaban model Anda di kunci answer file data masukan eval/data/RefoMB_dev.jsonl , misalnya:
{
"image_url": "https://thunlp.oss-cn-qingdao.aliyuncs.com/multimodal_openmme_test_20240319__20.jpg",
"question": "What is the background of the image?",
"type": "Coarse Perception",
"split": "dev",
"answer": "The background of the image features trees, suggesting that the scene takes place outdoors.",
"gt_description": "......"
}Jalankan skrip berikut untuk mengevaluasi hasil model Anda:
save_dir="YOUR SAVING DIR" model_ans_path="YOUR MODEL ANSWER PATH" model_name="YOUR MODEL NAME" bash ./script/eval/run_refobm_overall.sh $save_dir $model_ans_path $model_name
Evaluasi skor halusinasi
Setelah mengevaluasi skor keseluruhan, akan dibuat file hasil evaluasi dengan nama A-GPT-4V_B-${model_name}.json . Menggunakan file hasil evaluasi ini untuk menghitung skor halusinasi sebagai berikut:
eval_result="EVAL RESULT FILE PATH, e.g. 'A-GPT-4V_B-${model_name}'"
# Do not include ".json" in your file path!
bash ./script/eval/run_refomb_hall.sh $eval_resultCatatan: Untuk stabilitas yang lebih baik, kami menyarankan Anda mengevaluasi lebih dari 3 kali dan menggunakan skor rata-rata sebagai skor model akhir.
Pemberitahuan Penggunaan dan Lisensi : Data, kode, dan pos pemeriksaan dimaksudkan dan dilisensikan hanya untuk penggunaan penelitian. Mereka juga dibatasi untuk penggunaan yang mengikuti perjanjian lisensi LLaMA, Vicuna, dan Chat GPT. Kumpulan datanya adalah CC BY NC 4.0 (hanya mengizinkan penggunaan non-komersial) dan model yang dilatih menggunakan kumpulan data tersebut tidak boleh digunakan di luar tujuan penelitian.
RLHF-V: Basis kode yang kami bangun.
LLaVA: Model instruksi dan model pelabel RLAIF-V-7B.
MiniCPM-V: Model instruksi dan model pelabel RLAIF-V-12B.
Jika menurut Anda model/kode/data/kertas kami bermanfaat, harap pertimbangkan untuk mengutip makalah kami dan memberi bintang pada kami ️!
@article{yu2023rlhf, title={Rlhf-v: Menuju mllm yang dapat dipercaya melalui penyelarasan perilaku dari umpan balik manusia yang sangat teliti}, author={Yu, Tianyu dan Yao, Yuan dan Zhang, Haoye dan He, Taiwen dan Han, Yifeng dan Cui, Ganqu dan Hu, Jinyi dan Liu, Zhiyuan dan Zheng, Hai-Tao dan Sun, Maosong dan lainnya}, journal={arXiv preprint arXiv:2312.00849}, year={2023}}@article{yu2024rlaifv, title={RLAIF-V: Menyelaraskan MLLM melalui Masukan AI Sumber Terbuka untuk Kepercayaan Super GPT-4V}, author={Yu, Tianyu dan Zhang, Haoye dan Yao, Yuan dan Dang, Yunkai dan Chen, Da dan Lu, Xiaoman dan Cui, Ganqu dan He, Taiwen dan Liu, Zhiyuan dan Chua, Tat-Seng dan Sun, Maosong}, journal={arXiv preprint arXiv:2405.17220}, tahun={2024},
} 

