ChatLM mini Chinese
1.0.0
Cina |. Inggris
Model bahasa besar saat ini cenderung memiliki parameter yang lebih besar, dan komputer tingkat konsumen lebih lambat dalam melakukan inferensi sederhana, apalagi melatih model dari awal. Tujuan dari proyek ini adalah untuk melatih model bahasa generatif dari awal, termasuk pembersihan data, pelatihan tokenizer, pra-pelatihan model, penyempurnaan instruksi SFT, pengoptimalan RLHF, dll.
ChatLM-mini-Chinese adalah model dialog berbahasa Mandarin kecil dengan hanya parameter model 0,2B (sekitar 210M termasuk bobot bersama). Model ini dapat dilatih sebelumnya pada mesin dengan memori video minimal 4GB ( batch_size=1 , fp16 atau bf16 ), dan pemuatan dan inferensi float16 memerlukan setidaknya Membutuhkan memori video 512MB.
Huggingface NLP, termasuk transformers , accelerate , trl , peft , dll.trainer yang diterapkan sendiri mendukung pra-pelatihan dan penyempurnaan SFT pada satu mesin dengan satu kartu atau dengan beberapa kartu pada satu mesin. Ini mendukung berhenti di posisi mana pun selama pelatihan dan melanjutkan pelatihan di posisi apa pun.Text-to-Text end-to-end dan pra-pelatihan prediksi non- mask .sentencepiece dan huggingface tokenizers ;batch_size=1, max_len=320 , pra-pelatihan didukung pada mesin dengan memori minimal 16 GB + memori video 4 GB;trainer yang diterapkan sendiri mendukung penyesuaian perintah yang cepat dan mendukung breakpoint apa pun untuk melanjutkan pelatihan;sequence to sequence penyempurnaan Huggingface trainer ;peft lora untuk optimasi preferensi;Lora adapter dapat digabungkan ke dalam model asli.Jika Anda perlu melakukan pengambilan generasi yang ditingkatkan (RAG) berdasarkan model kecil, Anda dapat merujuk ke proyek saya yang lain Phi2-mini-Chinese. Untuk kodenya, lihat rag_with_langchain.ipynb
? Pembaruan terkini
Semua kumpulan data berasal dari kumpulan data percakapan satu putaran yang dipublikasikan di Internet. Setelah data dibersihkan dan diformat, data tersebut disimpan sebagai file parket. Untuk proses pemrosesan data, lihat utils/raw_data_process.py . Kumpulan data utama meliputi:
Belle_open_source_1M , train_2M_CN , dan train_3.5M_CN yang memiliki jawaban singkat, tidak mengandung struktur tabel yang rumit, dan tugas terjemahan (tidak ada daftar kosakata bahasa Inggris), total 3,7 juta baris, dan 3,38 juta baris tersisa setelah dibersihkan.N kata pertama dari ensiklopedia adalah jawabannya. Data ensiklopedia 202309 digunakan, dan 1,19 juta petunjuk dan jawaban entri tetap ada setelah dibersihkan. Unduhan wiki: zhwiki, konversikan file bz2 yang diunduh ke referensi wiki.txt: WikiExtractor. Jumlah total kumpulan data adalah 10,23 juta: kumpulan pra-pelatihan Text-to-Text: 9,3 juta, kumpulan evaluasi: 25.000 (karena penguraiannya lambat, kumpulan evaluasi tidak disetel terlalu besar). Set tes: 900.000. Kumpulan data penyempurnaan SFT dan pengoptimalan DPO ditunjukkan di bawah ini.
Model T5 (Transformator Transfer Teks-ke-Teks), untuk detailnya lihat makalah: Menjelajahi Batasan Pembelajaran Transfer dengan Transformator Teks-ke-Teks Terpadu.
Kode sumber model berasal dari huggingface, lihat: T5ForConditionalGeneration.
Lihat model_config.json untuk konfigurasi model. encoder layer dan decoder layer T5-base resmi keduanya terdiri dari 12 lapisan.
Parameter model: 0,2B. Ukuran daftar kata: 29298, hanya mencakup bahasa Mandarin dan sedikit bahasa Inggris.
perangkat keras:
# 预训练阶段:
CPU: 28 vCPU Intel(R) Xeon(R) Gold 6330 CPU @ 2.00GHz
内存:60 GB
显卡:RTX A5000(24GB) * 2
# sft及dpo阶段:
CPU: Intel(R) i5-13600k @ 5.1GHz
内存:32 GB
显卡:NVIDIA GeForce RTX 4060 Ti 16GB * 1 Pelatihan Tokenizer : Pustaka pelatihan tokenizer yang ada memiliki masalah OOM ketika menghadapi korpus besar. Oleh karena itu, korpus lengkap digabungkan dan dibangun berdasarkan frekuensi kata sesuai dengan metode yang mirip dengan BPE , yang memerlukan waktu setengah hari untuk dijalankan.
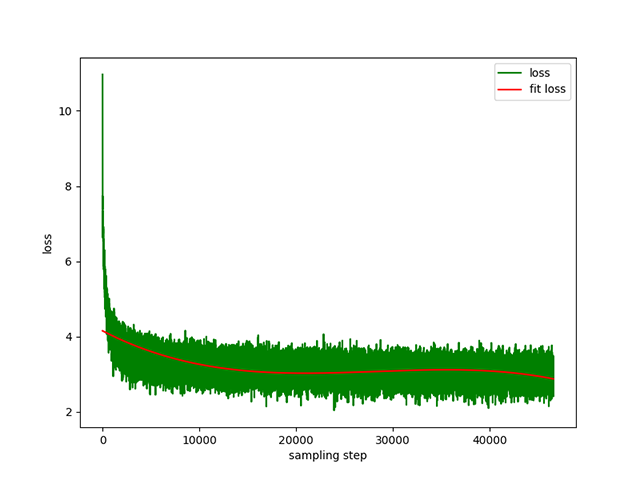
Pra-pelatihan Text-to-Text : kecepatan pembelajaran dinamis 1e-4 hingga 5e-3 , dan waktu pra-pelatihan 8 hari. Kerugian pelatihan:
belle (panjang instruksi dan jawaban di bawah 512), kecepatan pembelajaran adalah kecepatan pembelajaran dinamis dari 1e-7 hingga 5e-5 , dan waktu penyesuaian adalah 2 hari. Kerugian penyesuaian: 
chosen . Pada langkah 2 , kumpulan model SFT generate petunjuk dalam kumpulan data dan mendapatkan teks rejected untuk mengoptimalkan preferensi penuh dpo dan belajar. Tarifnya le-5 , setengah presisi fp16 , total 2 epoch , dan membutuhkan waktu 3 jam. kerugian dpo: 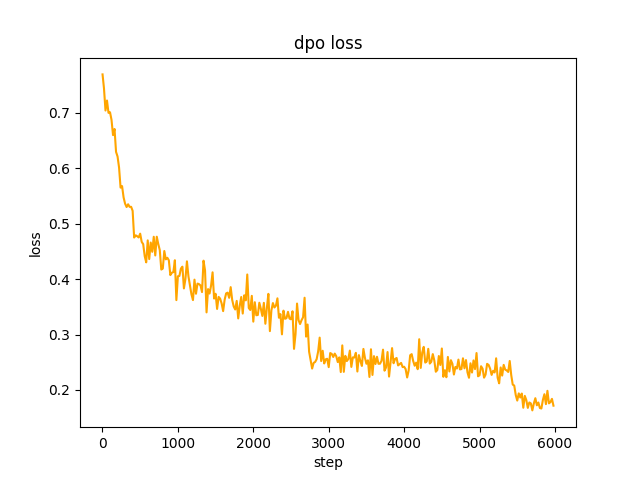
Secara default, TextIteratorStreamer dari huggingface transformers digunakan untuk mengimplementasikan dialog streaming, yang hanya mendukung greedy search . Jika Anda memerlukan metode pembangkitan lain seperti beam sample , harap ubah parameter stream_chat dari cli_demo.py menjadi False . 

Ada masalah: kumpulan data pra-pelatihan hanya memiliki lebih dari 9 juta, dan parameter model hanya 0,2B. Tidak dapat mencakup semua aspek, dan akan ada situasi di mana jawabannya salah dan generatornya tidak masuk akal.
Jika pelukan tidak dapat dihubungkan, gunakan modelscope.snapshot_download untuk mengunduh file model dari modelscope.
from transformers import AutoTokenizer , AutoModelForSeq2SeqLM
import torch
model_id = 'charent/ChatLM-mini-Chinese'
# 如果无法连接huggingface,打开以下两行代码的注释,将从modelscope下载模型文件,模型文件保存到'./model_save'目录
# from modelscope import snapshot_download
# model_id = snapshot_download(model_id, cache_dir='./model_save')
device = torch . device ( 'cuda' if torch . cuda . is_available () else 'cpu' )
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForSeq2SeqLM . from_pretrained ( model_id , trust_remote_code = True ). to ( device )
txt = '如何评价Apple这家公司?'
encode_ids = tokenizer ([ txt ])
input_ids , attention_mask = torch . LongTensor ( encode_ids [ 'input_ids' ]), torch . LongTensor ( encode_ids [ 'attention_mask' ])
outs = model . my_generate (
input_ids = input_ids . to ( device ),
attention_mask = attention_mask . to ( device ),
max_seq_len = 256 ,
search_type = 'beam' ,
)
outs_txt = tokenizer . batch_decode ( outs . cpu (). numpy (), skip_special_tokens = True , clean_up_tokenization_spaces = True )
print ( outs_txt [ 0 ])Apple是一家专注于设计和用户体验的公司,其产品在设计上注重简约、流畅和功能性,而在用户体验方面则注重用户的反馈和使用体验。作为一家领先的科技公司,苹果公司一直致力于为用户提供最优质的产品和服务,不断推陈出新,不断创新和改进,以满足不断变化的市场需求。
在iPhone、iPad和Mac等产品上,苹果公司一直保持着创新的态度,不断推出新的功能和设计,为用户提供更好的使用体验。在iPad上推出的iPad Pro和iPod touch等产品,也一直保持着优秀的用户体验。
此外,苹果公司还致力于开发和销售软件和服务,例如iTunes、iCloud和App Store等,这些产品在市场上也获得了广泛的认可和好评。
总的来说,苹果公司在设计、用户体验和产品创新方面都做得非常出色,为用户带来了许多便利和惊喜。
Peringatan
Model proyek ini adalah model TextToText . Di bidang prompt , response , dan lainnya di fase pra-pelatihan, SFT, dan RLFH, pastikan untuk menambahkan tanda akhir urutan [EOS] .
git clone --depth 1 https://github.com/charent/ChatLM-mini-Chinese.git
cd ChatLM-mini-Chinese Disarankan untuk menggunakan python 3.10 untuk proyek ini. Versi python yang lebih lama mungkin tidak kompatibel dengan perpustakaan pihak ketiga tempat bergantungnya.
instalasi pip:
pip install -r ./requirements.txtJika pip menginstal pytorch versi CPU, Anda dapat menginstal pytorch versi CUDA dengan perintah berikut:
# pip 安装torch + cu118
pip3 install torch --index-url https://download.pytorch.org/whl/cu118instalasi conda:
conda install --yes --file ./requirements.txt Gunakan perintah git untuk mengunduh bobot model dan file konfigurasi dari Hugging Face Hub . Anda perlu menginstal Git LFS terlebih dahulu, lalu menjalankan:
# 使用git命令下载huggingface模型,先安装[Git LFS],否则下载的模型文件不可用
git clone --depth 1 https://huggingface.co/charent/ChatLM-mini-Chinese
# 如果无法连接huggingface,请从modelscope下载
git clone --depth 1 https://www.modelscope.cn/charent/ChatLM-mini-Chinese.git
mv ChatLM-mini-Chinese model_save Anda juga dapat mendownloadnya secara manual langsung dari gudang Hugging Face Hub ChatLM-Chinese-0.2B dan memindahkan file download ke direktori model_save .
Persyaratan korpus harus selengkap mungkin. Disarankan untuk menambahkan beberapa korpus, seperti ensiklopedia, kode, makalah, blog, percakapan, dll.
Proyek ini terutama didasarkan pada ensiklopedia wiki Cina. Cara mendapatkan korpus wiki berbahasa Mandarin: Alamat pengunduhan Wiki berbahasa Mandarin: zhwiki, unduh file zhwiki-[存档日期]-pages-articles-multistream.xml.bz2 , sekitar 2,7 GB, ubah file bz2 yang diunduh menjadi referensi wiki.txt: WikiExtractor, Kemudian gunakan pustaka OpenCC python untuk mengonversinya ke bahasa Mandarin Sederhana, dan terakhir letakkan wiki.simple.txt yang diperoleh di direktori data direktori root proyek. Silakan gabungkan sendiri beberapa corpora menjadi satu file txt .
Karena tokenizer pelatihan menghabiskan banyak memori, jika korpus Anda sangat besar (file txt yang digabungkan melebihi 2G), disarankan untuk mengambil sampel korpus menurut kategori dan proporsi untuk mengurangi waktu pelatihan dan konsumsi memori. Melatih file txt 1,7 GB membutuhkan memori sekitar 48 GB (perkiraan saya hanya punya 32 GB, swap sering dipicu, komputer macet lama T_T), dan CPU 13600k membutuhkan waktu sekitar 1 jam.
Perbedaan antara char level dan byte level adalah sebagai berikut (silakan cari informasi sendiri untuk perbedaan penggunaan tertentu). Tokenizer melatih char level secara default. Jika byte level diperlukan, cukup setel token_type='byte' di train_tokenizer.py .
# 原始文本
txt = '这是一段中英混输的句子, (chinese and English, here are words.)'
tokens = charlevel_tokenizer . tokenize ( txt )
print ( tokens )
# char level tokens输出
# ['▁这是', '一段', '中英', '混', '输', '的', '句子', '▁,', '▁(', '▁ch', 'inese', '▁and', '▁Eng', 'lish', '▁,', '▁h', 'ere', '▁', 'are', '▁w', 'ord', 's', '▁.', '▁)']
tokens = bytelevel_tokenizer . tokenize ( txt )
print ( tokens )
# byte level tokens输出
# ['Ġè¿Ļæĺ¯', 'ä¸Ģ段', 'ä¸Ńèĭ±', 'æ··', 'è¾ĵ', 'çļĦ', 'åı¥åŃIJ', 'Ġ,', 'Ġ(', 'Ġch', 'inese', 'Ġand', 'ĠEng', 'lish', 'Ġ,', 'Ġh', 'ere', 'Ġare', 'Ġw', 'ord', 's', 'Ġ.', 'Ġ)']Mulai pelatihan:
# 确保你的训练语料`txt`文件已经data目录下
python train_tokenizer . py {
"prompt" : "对于花园街,你有什么了解或看法吗? " ,
"response" : "花园街(是香港油尖旺区的一条富有特色的街道,位于九龙旺角东部,北至界限街,南至登打士街,与通菜街及洗衣街等街道平行。现时这条街道是香港著名的购物区之一。位于亚皆老街以南的一段花园街,也就是"波鞋街"整条街约150米长,有50多间售卖运动鞋和运动用品的店舖。旺角道至太子道西一段则为排档区,售卖成衣、蔬菜和水果等。花园街一共分成三段。明清时代,花园街是芒角村栽种花卉的地方。此外,根据历史专家郑宝鸿的考证:花园街曾是1910年代东方殷琴拿烟厂的花园。纵火案。自2005年起,花园街一带最少发生5宗纵火案,当中4宗涉及排档起火。2010年。2010年12月6日,花园街222号一个卖鞋的排档于凌晨5时许首先起火,浓烟涌往旁边住宅大厦,消防接报4 "
}jupyter-lab atau buku catatan jupyter:
Lihat file train.ipynb . Disarankan untuk menggunakan jupyter-lab untuk menghindari mempertimbangkan situasi di mana proses terminal terhenti setelah memutuskan sambungan dari server.
Menghibur:
Pelatihan konsol perlu mempertimbangkan bahwa proses akan dihentikan setelah koneksi terputus. Disarankan untuk menggunakan alat daemon proses Supervisor atau screen untuk membuat sesi koneksi.
Pertama, Anda perlu mengonfigurasi accelerate , jalankan perintah berikut, dan pilih sesuai petunjuk. Lihat accelerate.yaml Catatan: DeepSpeed lebih merepotkan untuk diinstal di Windows .
accelerate config Mulai pelatihan. Jika Anda ingin menggunakan konfigurasi yang disediakan oleh proyek, tambahkan parameter --config_file ./accelerate.yaml setelah perintah berikut: accelerate launch .
Ada dua skrip untuk pra-pelatihan. Pelatih yang diterapkan dalam proyek ini sesuai dengan train.py , dan pelatih yang diterapkan dengan huggingface sesuai dengan pre_train.py . Pelatih yang diterapkan dalam proyek ini menampilkan informasi pelatihan yang lebih indah dan memudahkan untuk mengubah detail pelatihan (seperti fungsi kerugian, catatan log, dll.). Semua titik henti dukungan untuk melanjutkan pelatihan breakpoint di posisi mana pun. Tekan ctrl+c akan menyimpan informasi breakpoint saat keluar dari skrip.
Mesin tunggal dan kartu tunggal:
# 本项目实现的trainer
accelerate launch ./train.py train
# 或者使用 huggingface trainer
python pre_train.py Mesin tunggal dengan banyak kartu: 2 adalah jumlah kartu grafis, harap modifikasi sesuai dengan situasi Anda yang sebenarnya.
# 本项目实现的trainer
accelerate launch --multi_gpu --num_processes 2 ./train.py train
# 或者使用 huggingface trainer
accelerate launch --multi_gpu --num_processes 2 pre_train.pyLanjutkan pelatihan dari breakpoint:
# 本项目实现的trainer
accelerate launch --multi_gpu --num_processes 2 ./train.py train --is_keep_training=True
# 或者使用 huggingface trainer
# 需要在`pre_train.py`中的`train`函数添加`resume_from_checkpoint=True`
accelerate launch --multi_gpu --num_processes 2 pre_train.pyKumpulan data SFT semuanya berasal dari kontribusi bos BELLE, terima kasih. Kumpulan data SFT adalah: generate_chat_0.4M, train_0.5M_CN, dan train_2M_CN, dengan sekitar 1,37 juta baris tersisa setelah dibersihkan. Contoh menyempurnakan kumpulan data dengan perintah sft:
{
"prompt" : "解释什么是欧洲启示录" ,
"response" : "欧洲启示录(The Book of Revelation)是新约圣经的最后一卷书,也被称为《启示录》、《默示录》或《约翰默示录》。这本书从宗教的角度描述了世界末日的来临,以及上帝对世界的审判和拯救。 书中的主题包括来临的基督的荣耀,上帝对人性的惩罚和拯救,以及魔鬼和邪恶力量的存在。欧洲启示录是一个充满象征和暗示的文本,对于解读和理解有许多不同的方法和观点。 "
} Buat kumpulan data Anda sendiri dengan mengacu pada contoh file parquet di direktori data . Format kumpulan datanya adalah: File parquet dibagi menjadi dua kolom, satu kolom teks prompt , yang mewakili prompt, dan satu kolom teks response , yang mewakili keluaran model yang diharapkan. Untuk detail penyempurnaan, lihat metode train di bawah model/trainer.py . Jika is_finetune disetel ke True , penyempurnaan akan dilakukan. Penyempurnaan akan membekukan lapisan penyematan dan lapisan encoder secara default, dan hanya melatih dekoder lapisan. Jika Anda perlu membekukan parameter lain, silakan sesuaikan sendiri kodenya.
Jalankan penyempurnaan SFT:
# 本项目实现的trainer, 添加参数`--is_finetune=True`即可, 参数`--is_keep_training=True`可从任意断点处继续训练
accelerate launch --multi_gpu --num_processes 2 ./train.py --is_finetune=True
# 或者使用 huggingface trainer, 多GPU请用accelerate launch --multi_gpu --num_processes gpu个数 sft_train.py
python sft_train.pyBerikut adalah dua metode umum yang disukai: PPO dan DPO. Silakan cari di makalah dan blog untuk penerapan spesifik.
Metode PPO (perkiraan optimasi preferensi, Optimasi Kebijakan Proksimal)
Langkah 1: Gunakan kumpulan data penghalusan untuk melakukan penghalusan yang diawasi (SFT, Supervised Finetuning).
Langkah 2: Gunakan kumpulan data preferensi (sebuah prompt berisi setidaknya 2 respons, satu respons yang diinginkan dan satu respons yang tidak diinginkan. Beberapa respons dapat diurutkan berdasarkan skor, dan respons yang paling diinginkan memiliki skor tertinggi) untuk melatih model penghargaan (RM , Model Hadiah). Anda dapat menggunakan perpustakaan peft untuk membuat model hadiah Lora dengan cepat.
Langkah 3: Gunakan RM untuk melakukan pelatihan PPO yang diawasi pada model SFT sehingga model tersebut memenuhi preferensi.
Gunakan fine-tuning DPO (Direct Preference Optimization) ( proyek ini menggunakan metode fine-tuning DPO, yang menghemat memori video ). Berdasarkan perolehan model SFT, tidak perlu melatih model reward untuk mendapatkan jawaban positif ( dipilih) dan jawaban negatif (ditolak) untuk memulai penyesuaian. Teks chosen yang disempurnakan berasal dari kumpulan data asli alpaca-gpt4-data-zh, dan teks rejected berasal dari keluaran model setelah penyesuaian SFT selama 1 periode. Dua kumpulan data lainnya: huozi_rlhf_data_json dan rlhf-reward-. single-round-trans_chinese, setelah penggabungan Total 80.000 data dpo.
Untuk proses pemrosesan kumpulan data dpo, lihat utils/dpo_data_process.py .
Contoh kumpulan data pengoptimalan preferensi DPO:
{
"prompt" : "为给定的产品创建一个创意标语。,输入:可重复使用的水瓶。 " ,
"chosen" : " "保护地球,从拥有可重复使用的水瓶开始! " " ,
"rejected" : " "让你的水瓶成为你的生活伴侣,使用可重复使用的水瓶,让你的水瓶成为你的伙伴" "
}Jalankan pengoptimalan preferensi:
# 多GPU请用accelerate launch --multi_gpu --num_processes gpu个数 dpo_train.py
python dpo_train.py Pastikan ada file berikut di direktori model_save . File ini dapat ditemukan di gudang Hugging Face Hub ChatLM-Chinese-0.2B:
ChatLM-mini-Chinese
├─model_save
| ├─config.json
| ├─configuration_chat_model.py
| ├─generation_config.json
| ├─model.safetensors
| ├─modeling_chat_model.py
| ├─special_tokens_map.json
| ├─tokenizer.json
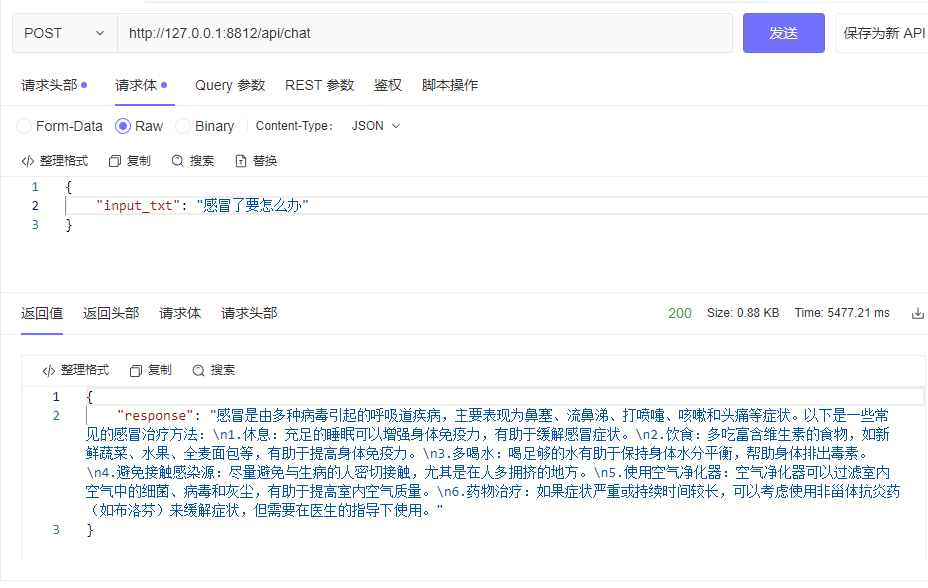
| └─tokenizer_config.jsonpython cli_demo.pypython api_demo.pyContoh panggilan API:
curl --location ' 127.0.0.1:8812/api/chat '
--header ' Content-Type: application/json '
--header ' Authorization: Bearer Bearer '
--data ' {
"input_txt": "感冒了要怎么办"
} ' 
Di sini kami mengambil informasi triplet dalam teks sebagai contoh untuk melakukan penyesuaian hilir. Untuk metode ekstraksi pembelajaran mendalam tradisional untuk tugas ini, lihat gudang pytorch_IE_model. Ekstrak semua rangkap tiga dalam sebuah teks, seperti kalimat 《写生随笔》是冶金工业2006年出版的图书,作者是张来亮, ekstrak rangkap tiga (写生随笔,作者,张来亮) dan (写生随笔,出版社,冶金工业) .
Kumpulan data asli adalah: Kumpulan data ekstraksi rangkap tiga Baidu. Contoh format kumpulan data yang telah diproses dan disempurnakan:
{
"prompt" : "请抽取出给定句子中的所有三元组。给定句子:《家乡的月亮》是宋雪莱演唱的一首歌曲,所属专辑是《久违的哥们》 " ,
"response" : " [(家乡的月亮,歌手,宋雪莱),(家乡的月亮,所属专辑,久违的哥们)] "
} Anda dapat langsung menggunakan skrip sft_train.py untuk menyempurnakan. Skrip finetune_IE_task.ipynb berisi proses decoding terperinci. Kumpulan data pelatihan memiliki sekitar 17000 item, kecepatan pembelajarannya 5e-5 , dan masa pelatihannya 5 . Kemampuan dialog tugas-tugas lain tidak hilang setelah penyesuaian.

Efek penyempurnaan: Gunakan kumpulan data dev yang diterbitkan百度三元组抽取数据集sebagai kumpulan pengujian untuk membandingkan dengan metode tradisional pytorch_IE_model.
| Model | skor F1 | Presisi P | Ingat R |
|---|---|---|---|
| Penyempurnaan ChatLM-Cina-0,2B | 0,74 | 0,75 | 0,73 |
| ChatLM-Cina-0.2B tanpa pra-pelatihan | 0,51 | 0,53 | 0,49 |
| Metode pembelajaran mendalam tradisional | 0,80 | 0,79 | 80.1 |
Catatan: ChatLM-Chinese-0.2B无预训练berarti langsung menginisialisasi parameter acak dan memulai pelatihan dengan kecepatan pembelajaran 1e-4 . Parameter lainnya konsisten dengan penyesuaian.
Model itu sendiri tidak dilatih menggunakan kumpulan data yang lebih besar, juga tidak disesuaikan dengan instruksi untuk menjawab pertanyaan pilihan ganda. Skor C-Eval pada dasarnya adalah tingkat dasar dan dapat digunakan sebagai referensi jika diperlukan. Kode evaluasi C-Eval lihat: eval/c_eavl.ipynb
| kategori | benar | pertanyaan_hitungan | ketepatan |
|---|---|---|---|
| Sastra | 63 | 257 | 24,51% |
| Lainnya | 89 | 384 | 23,18% |
| TANGKAI | 89 | 430 | 20,70% |
| Ilmu Sosial | 72 | 275 | 26,18% |
Jika menurut Anda proyek ini bermanfaat bagi Anda, silakan kutip.
@misc{Charent2023,
author={Charent Chen},
title={A small chinese chat language model with 0.2B parameters base on T5},
year={2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/charent/ChatLM-mini-Chinese}},
}
Proyek ini tidak menanggung risiko dan tanggung jawab atas keamanan data dan risiko opini publik yang disebabkan oleh model dan kode sumber terbuka, atau risiko dan tanggung jawab yang timbul dari model apa pun yang disesatkan, disalahgunakan, disebarluaskan, atau dieksploitasi secara tidak patut.


