Transformer in generating dialogue
1.0.0
Kode ini merupakan implementasi dari Paper Attention yang Anda perlukan untuk mengerjakan tugas-tugas pembuatan dialog seperti: Chatbot , Pembuatan Teks , dan sebagainya.
Terima kasih kepada setiap teman yang telah mengangkat masalah dan membantu menyelesaikannya. Kontribusi Anda sangat penting untuk kemajuan proyek ini. Karena terbatasnya dukungan 'mode grafik statis' dalam pengkodean, kami memutuskan untuk memindahkan fitur ke versi 2.0.0-beta1. Namun jika Anda khawatir tentang masalah pembuatan buruh pelabuhan dan pembuatan layanan dengan masalah versi, kami masih menyimpan kode versi lama yang ditulis dengan mode bersemangat menggunakan versi tensorflow 1.12.x sebagai referensi.
|-- root/
|-- data/
|-- src-train.csv
|-- src-val.csv
|-- tgt-train.csv
`-- tgt-val.csv
|-- old_version/
|-- data_loader.py
|-- eval.py
|-- make_dic.py
|-- modules.py
|-- params.py
|-- requirements.txt
`-- train.py
|-- tf1.12.0-eager/
|-- bleu.py
|-- main.ipynb
|-- modules.py
|-- params.py
|-- requirements.txt
`-- utils.py
|-- images/
|-- bleu.py
|-- main-v2.ipynb
|-- modules-v2.py
|-- params.py
|-- requirements.txt
`-- utils-v2.py
Seperti kita ketahui Sistem Penerjemahan dapat digunakan dalam mengimplementasikan model percakapan hanya dengan mengganti paris dua kalimat berbeda menjadi tanya jawab. Bagaimanapun, model percakapan dasar bernama "Sequence-to-Sequence" dikembangkan dari sistem terjemahan. Oleh karena itu, mengapa kita tidak meningkatkan efisiensi model percakapan dalam menghasilkan dialog?
Dengan berkembangnya model berbasis BERT, semakin banyak tugas nlp yang terus disegarkan. Namun, model bahasa tersebut tidak terdapat dalam tugas sumber terbuka BERT. Tidak ada keraguan bahwa perjalanan kita masih panjang.
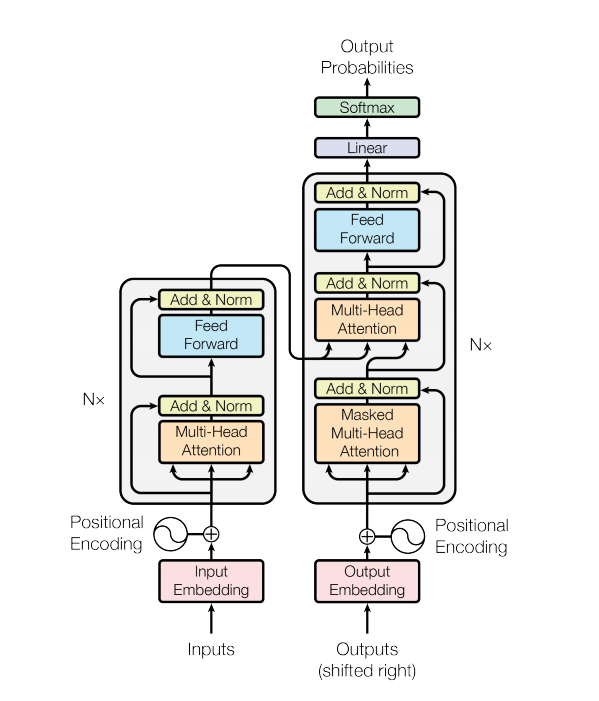
Model transformator menangani masukan berukuran variabel menggunakan tumpukan lapisan perhatian mandiri, bukan RNN atau CNN. Arsitektur umum ini memiliki sejumlah keunggulan dan keunggulan khusus. Sekarang mari kita keluarkan:
Dalam versi terbaru kode kami , kami melengkapi detail yang dijelaskan di kertas.
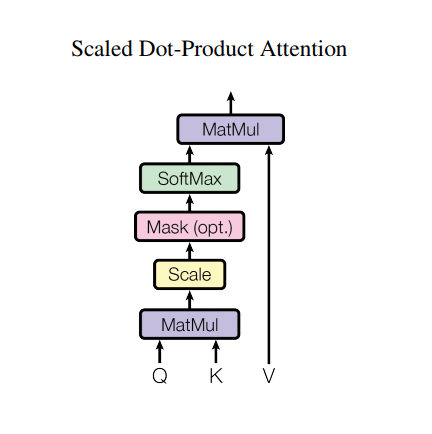
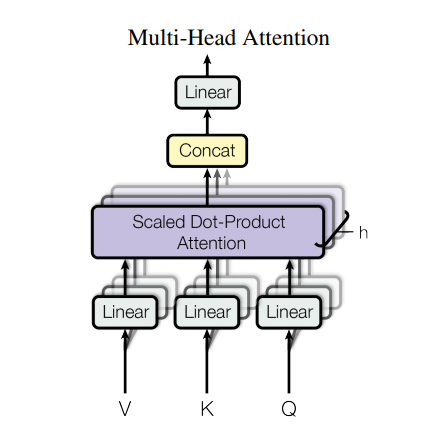
Namun, arsitektur yang kuat masih memiliki beberapa kelemahan:
data/ .params.py jika Anda mau.make_dic.py untuk menghasilkan file kosakata ke folder baru bernama dictionary .train.py untuk membuat model. Checkpoint akan disimpan di folder checkpoint sedangkan file event tensorflow dapat ditemukan di logdir .eval.py untuk mengevaluasi hasil dengan data pengujian. Hasilnya akan disimpan di folder Results .GPU untuk mempercepat pemrosesan pelatihan, harap atur perangkat Anda dalam kode. (Ini mendukung pelatihan multi-pekerja) - Source: 肥 宅 初 夜 可 以 賣 多 少 `
- Ground Truth: 肥 宅 還 是 去 打 手 槍 吧
- Predict: 肥 宅 還 是 去 打 手 槍 吧
- Source: 兇 的 女 生 484 都 很 胸
- Ground Truth: 我 看 都 是 醜 的 比 較 凶
- Predict: 我 看 都 是 醜 的 比 較 <UNK>
- Source: 留 髮 不 留 頭
- Ground Truth: 還 好 我 早 就 禿 頭 了
- Predict: 還 好 我 早 就 禿 頭 了
- Source: 當 人 好 痛 苦 R 的 八 卦
- Ground Truth: 去 中 國 就 不 用 當 人 了
- Predict: 去 中 國 就 不 會 有 了 -
- Source: 有 沒 有 今 天 捷 運 的 八 卦
- Ground Truth: 有 - 真 的 有 多
- Predict: 有 - 真 的 有 多
- Source: 2016 帶 走 了 什 麼 `
- Ground Truth: HellKitty 麥 當 勞 歡 樂 送 開 門 -
- Predict: <UNK> 麥 當 勞 歡 樂 送 開 門 -
- Source: 有 沒 有 多 益 很 賺 的 八 卦
- Ground Truth: 比 大 型 包 裹 貴
- Predict: 比 大 型 包 <UNK> 貴
- Source: 邊 緣 人 收 到 地 震 警 報 了
- Ground Truth: 都 跑 到 窗 邊 了 才 來
- Predict: 都 跑 到 <UNK> 邊 了 才 來
- Source: 車 震
- Ground Truth: 沒 被 刪 版 主 是 有 眼 睛 der
- Predict: 沒 被 刪 版 主 是 有 眼 睛 der
- Source: 在 家 跌 倒 的 八 卦 `
- Ground Truth: 傷 到 腦 袋 - 可 憐
- Predict: 傷 到 腦 袋 - 可 憐
- Source: 大 家 很 討 厭 核 核 嗎 `
- Ground Truth: 核 核 欠 幹 阿
- Predict: 核 核 欠 幹 阿
- Source: 館 長 跟 黎 明 打 誰 贏 -
- Ground Truth: 我 愛 黎 明 - 我 愛 黎 明 -
- Predict: 我 愛 <UNK> 明 - 我 愛 <UNK> 明 -
- Source: 嘻 嘻 打 打
- Ground Truth: 媽 的 智 障 姆 咪 滾 喇 幹
- Predict: 媽 的 智 障 姆 咪 滾 喇 幹
- Source: 經 典 電 影 台 詞
- Ground Truth: 超 時 空 要 愛 裡 滿 滿 的 梗
- Predict: 超 時 空 要 愛 裡 滿 滿 滿 的
- Source: 2B 守 得 住 街 亭 嗎 `
- Ground Truth: 被 病 毒 滅 亡 真 的 會 -
- Predict: <UNK> 守 得 住
Jika Anda mencoba menggunakan AutoGraph untuk mempercepat proses pelatihan Anda, pastikan kumpulan data diisi dengan panjang yang tetap. Karena operasi pembangunan kembali grafik akan diaktifkan selama pelatihan, yang dapat mempengaruhi kinerja. Kode kami hanya memastikan kinerja versi 2.0, dan kode di bawahnya dapat mencoba merujuknya.
Terima kasih untuk Transformer dan Tensorflow


