LLaMA_MPS
1.0.0
Jalankan inferensi LLaMA (dan Stanford-Alpaca) pada GPU Apple Silicon.
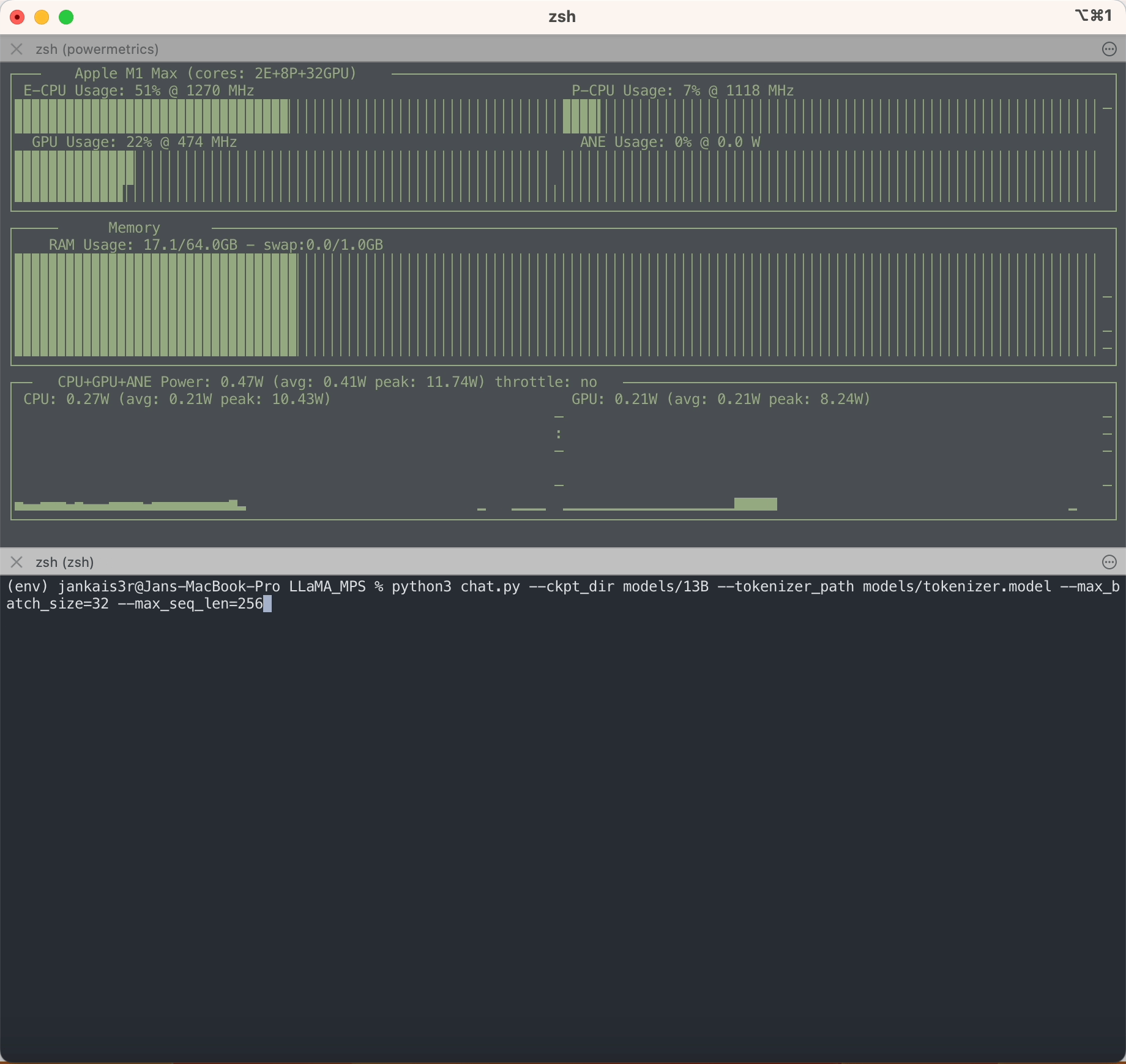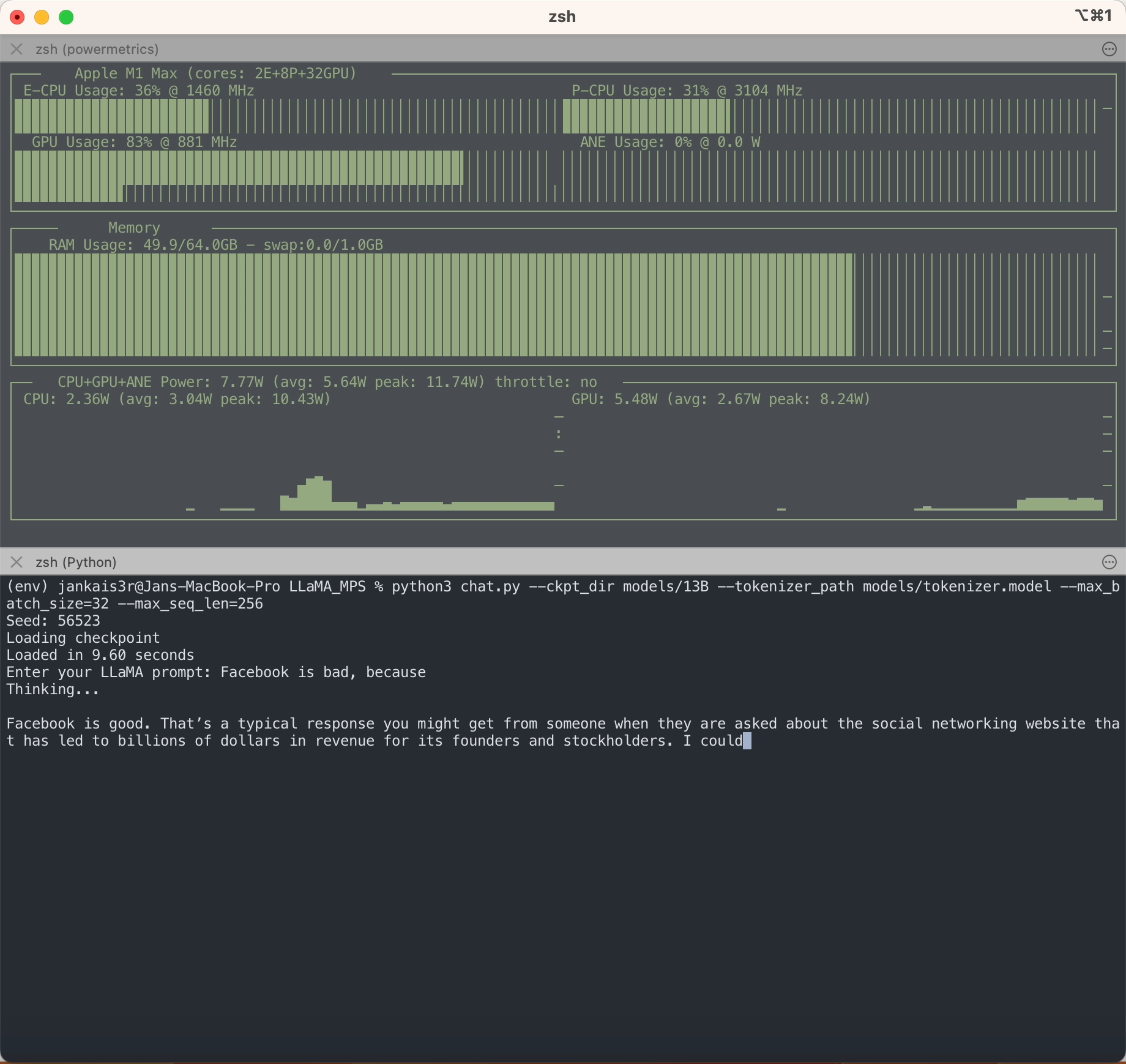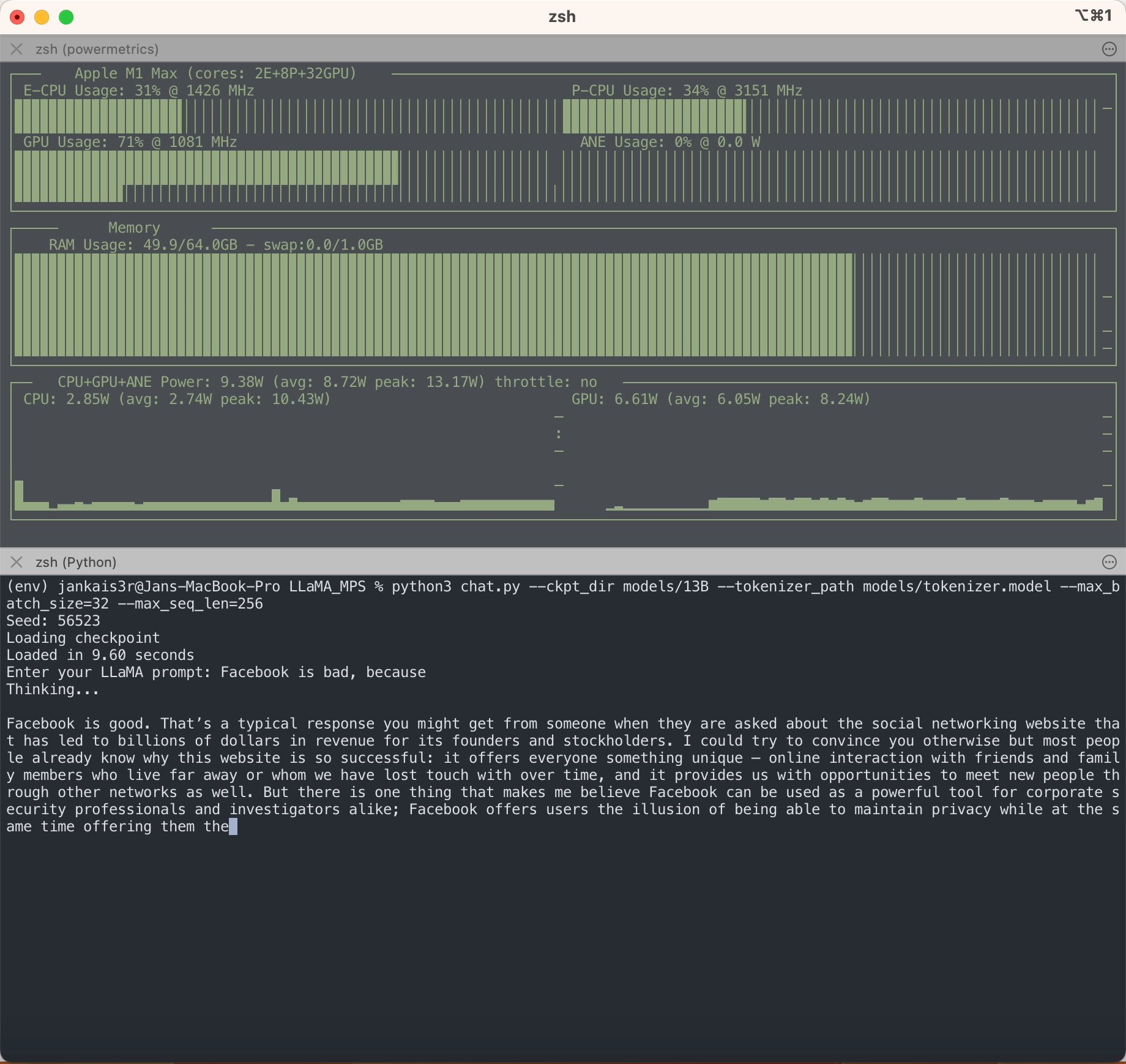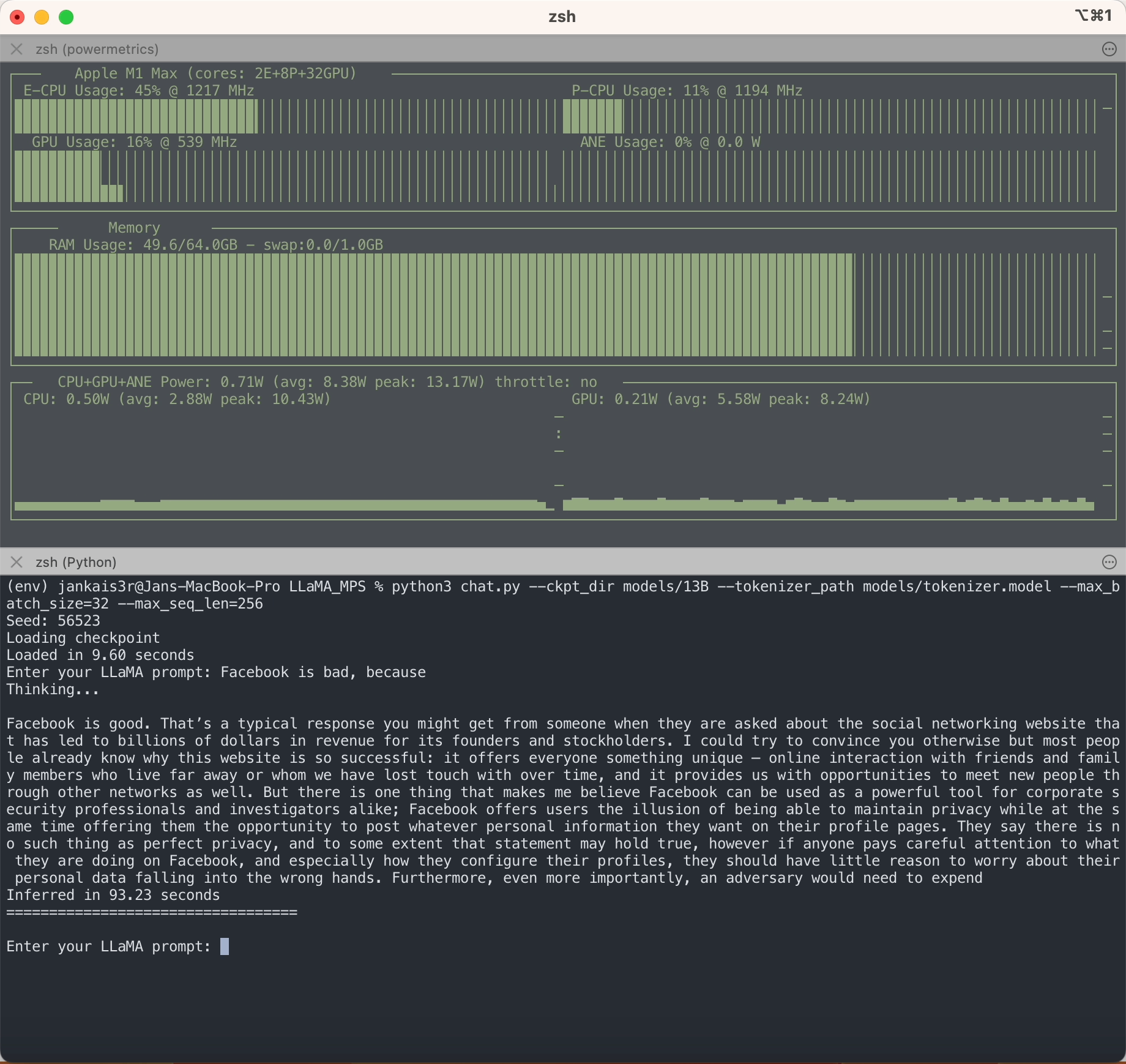
Seperti yang Anda lihat, tidak seperti LLM lainnya, LLaMA tidak bias dalam hal apa pun?
1. Kloning repo ini
git clone https://github.com/jankais3r/LLaMA_MPS
2. Instal dependensi Python
cd LLaMA_MPS
pip3 install virtualenv
python3 -m venv env
source env/bin/activate
pip3 install -r requirements.txt
pip3 install -e . 3. Unduh bobot model dan masukkan ke dalam folder bernama models (misalnya, LLaMA_MPS/models/7B )
4. (Opsional) Ulangi bobot model (13B/30B/65B)
Karena kita menjalankan inferensi pada satu GPU, kita perlu menggabungkan bobot model yang lebih besar ke dalam satu file.
mv models/13B models/13B_orig
mkdir models/13B
python3 reshard.py 1 models/13B_orig models/13B5. Jalankan inferensi
python3 chat.py --ckpt_dir models/13B --tokenizer_path models/tokenizer.model --max_batch_size 8 --max_seq_len 256
Langkah-langkah di atas memungkinkan Anda menjalankan inferensi pada model LLaMA mentah dalam mode 'pelengkapan otomatis'.
Jika Anda ingin mencoba mode 'instruksi-respons' yang mirip dengan ChatGPT menggunakan bobot Stanford Alpaca yang telah disesuaikan, lanjutkan penyiapan dengan langkah-langkah berikut:
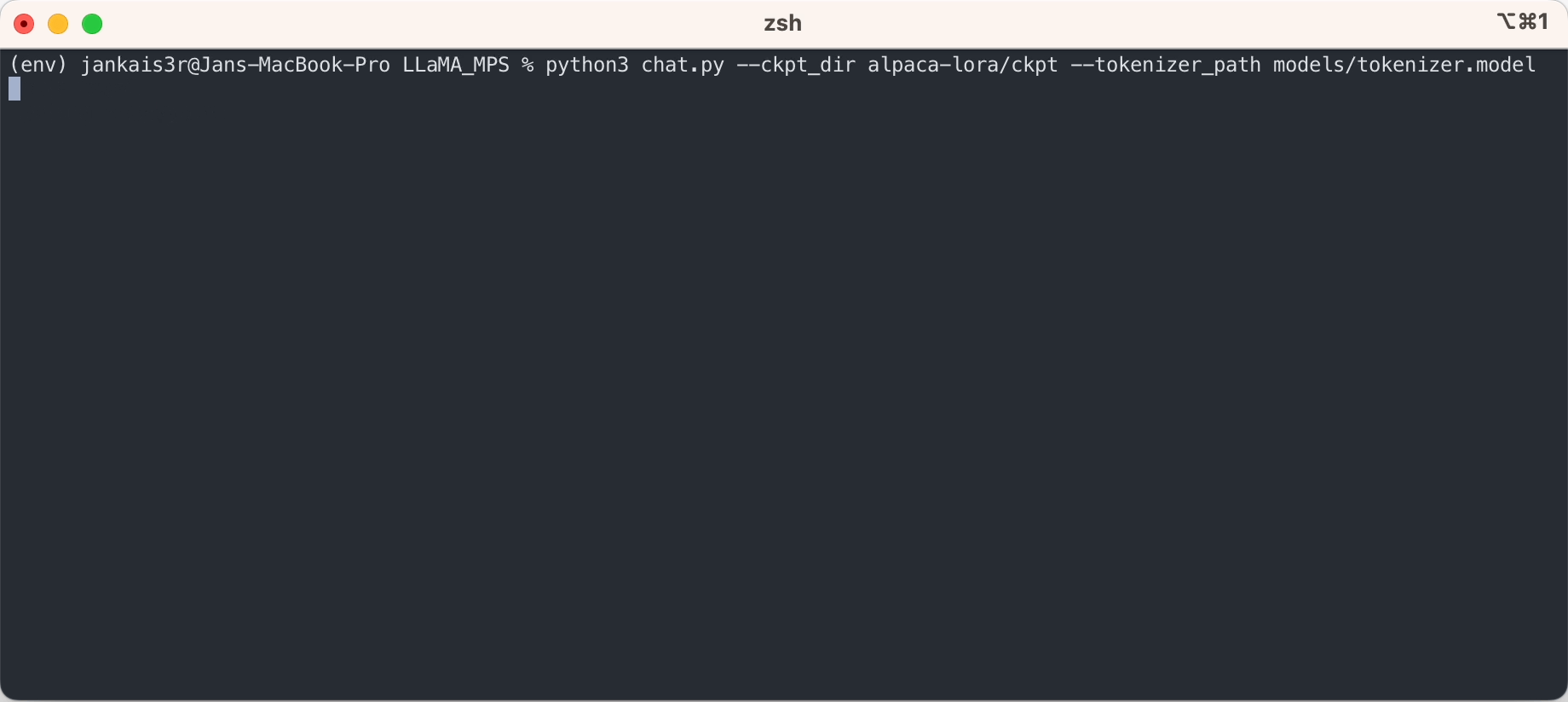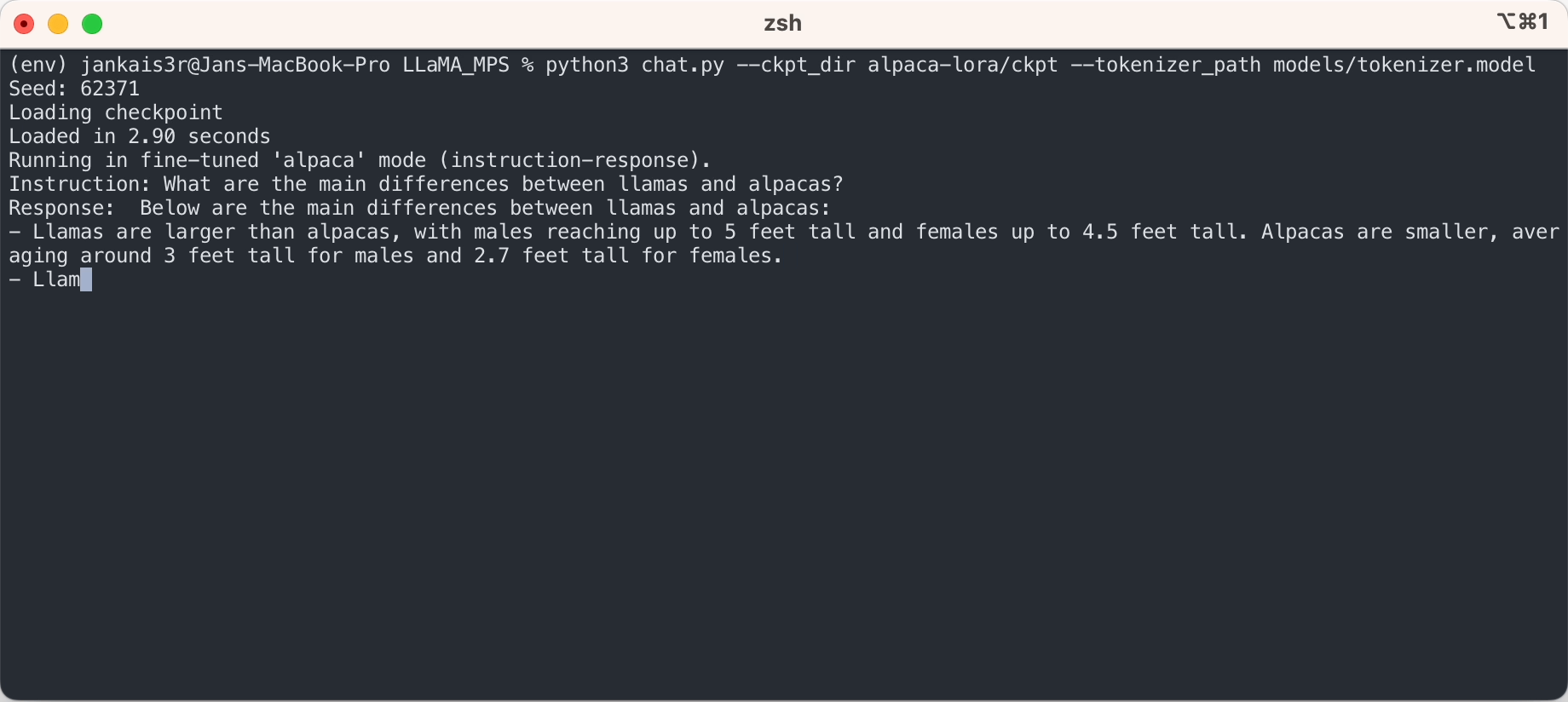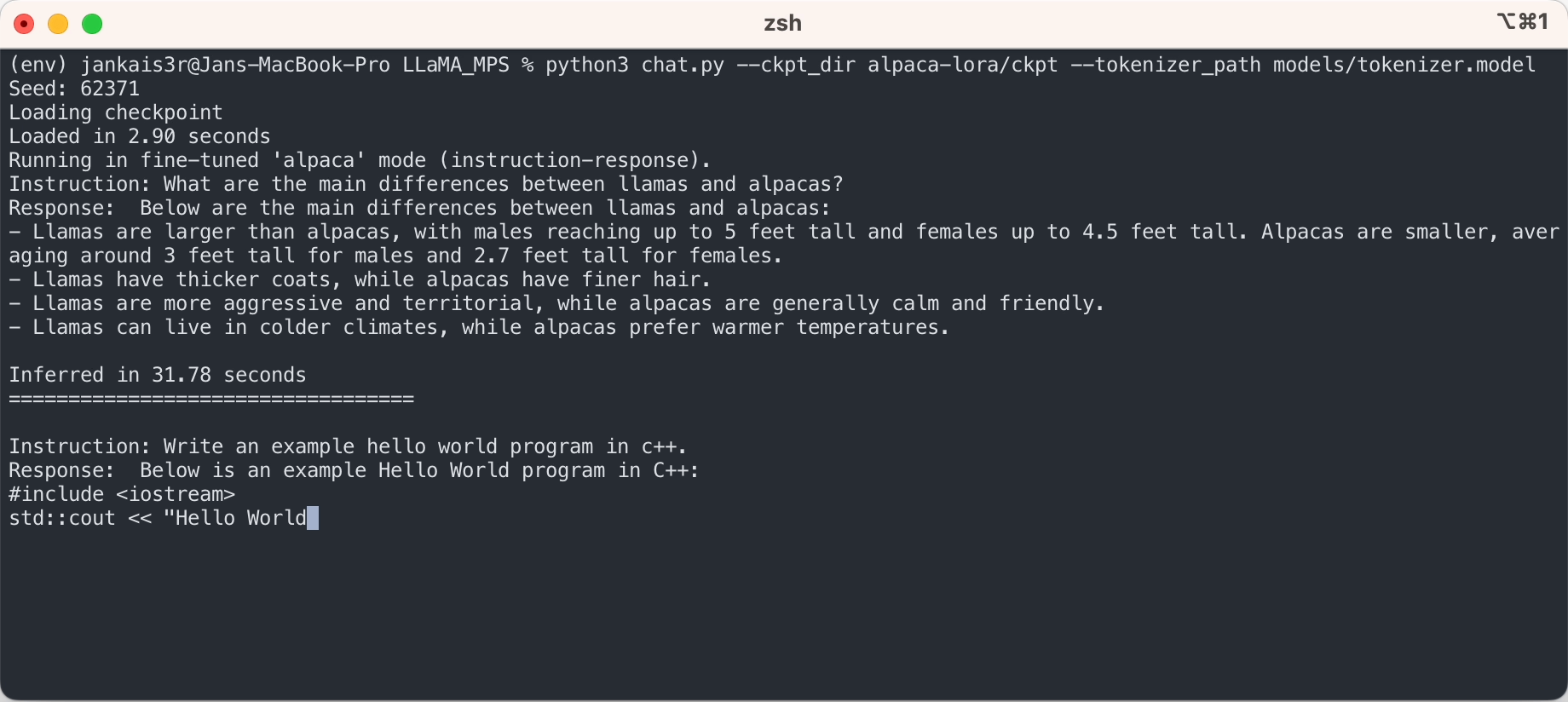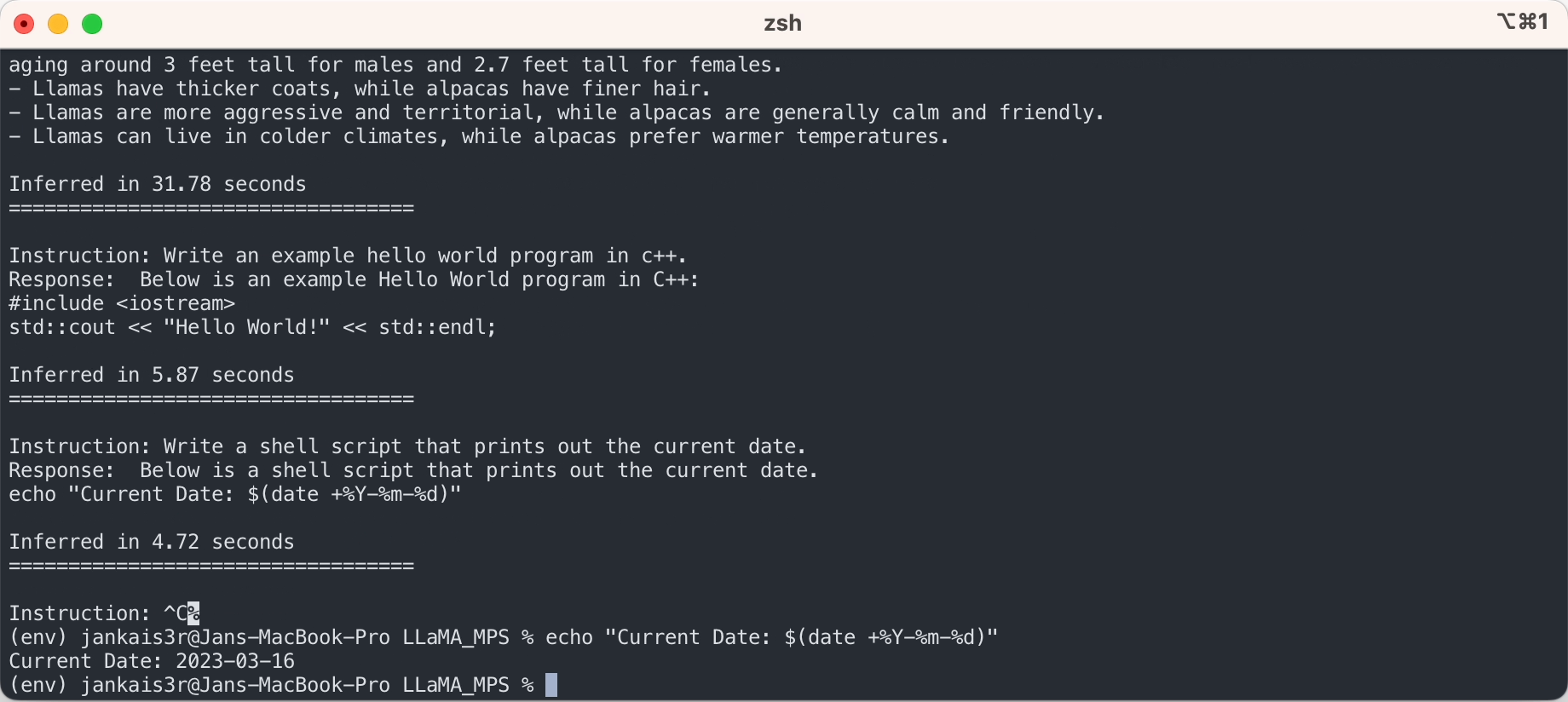
3. Unduh bobot yang telah disesuaikan (tersedia untuk 7B/13B)
python3 export_state_dict_checkpoint.py 7B
python3 clean_hf_cache.py4. Jalankan inferensi
python3 chat.py --ckpt_dir models/7B-alpaca --tokenizer_path models/tokenizer.model --max_batch_size 8 --max_seq_len 256
| Model | Memulai memori selama inferensi | Memori puncak selama konversi pos pemeriksaan | Memori puncak selama pembuatan ulang |
|---|---|---|---|
| 7B | 16 GB | 14 GB | T/A |
| 13B | 32 GB | 37 GB | 45 GB |
| 30B | 66 GB | 76 GB | 125 GB |
| 65B | ?? GB | ?? GB | ?? GB |
Spesifikasi minimum per model (lambat karena pertukaran):
Spesifikasi yang direkomendasikan per model:
- ukuran_batch_maks
Jika Anda memiliki memori cadangan (misalnya, saat menjalankan model 13B pada Mac 64 GB), Anda dapat meningkatkan ukuran batch dengan menggunakan argumen --max_batch_size=32 . Nilai defaultnya adalah 1 .
- max_seq_len
Untuk menambah/mengurangi panjang maksimum teks yang dihasilkan, gunakan argumen --max_seq_len=256 . Nilai defaultnya adalah 512 .
- use_repetition_penalty
Contoh skrip menghukum model karena menghasilkan konten yang berulang. Hal ini akan menghasilkan keluaran dengan kualitas lebih tinggi, namun sedikit memperlambat inferensi. Jalankan skrip dengan argumen --use_repetition_penalty=False untuk menonaktifkan algoritma penalti.
Alternatif terbaik untuk LLaMA_MPS untuk pengguna Apple Silicon adalah llama.cpp, yang merupakan implementasi ulang C/C++ yang menjalankan inferensi murni pada bagian CPU SoC. Karena kode C yang dikompilasi jauh lebih cepat daripada Python, kode ini sebenarnya dapat mengalahkan implementasi MPS ini dalam hal kecepatan, namun dengan mengorbankan daya dan efisiensi panas yang jauh lebih buruk.
Lihat perbandingan di bawah saat memutuskan implementasi mana yang lebih sesuai dengan kasus penggunaan Anda.
| Pelaksanaan | Total waktu berjalan - 256 token | Token/dtk | Penggunaan memori puncak | Suhu puncak SoC | Konsumsi Daya SoC Puncak | Token per 1 Wh |
|---|---|---|---|---|---|---|
| LLAMA_MPS (13B fp16) | 75 detik | 3.41 | 30 GB | 79 °C | 10 watt | 1.228,80 |
| llama.cpp (13B fp16) | 70 detik | 3.66 | 25 GB | 106 °C | 35 watt | 376.16 |


