Seq2seq Chatbot for Keras
1.0.0
Repositori ini berisi model chatbot generatif baru berdasarkan pemodelan seq2seq. Rincian lebih lanjut tentang model ini dapat ditemukan di Bagian 3 makalah Pembelajaran Adversarial End-to-end untuk Agen Percakapan Generatif. Dalam hal publikasi menggunakan ide atau potongan kode dari repositori ini, silakan mengutip makalah ini.
Model terlatih yang tersedia di sini menggunakan kumpulan data kecil yang terdiri dari ~8 ribu pasang konteks (dua ucapan terakhir dalam dialog hingga saat ini) dan tanggapan masing-masing. Data dikumpulkan dari dialog kursus bahasa Inggris online. Model terlatih ini dapat disesuaikan menggunakan kumpulan data domain tertutup untuk aplikasi dunia nyata.
Model seq2seq kanonik menjadi populer dalam terjemahan mesin saraf, sebuah tugas yang memiliki distribusi probabilitas sebelumnya yang berbeda untuk kata-kata yang termasuk dalam rangkaian masukan dan keluaran, karena ucapan masukan dan keluaran ditulis dalam bahasa yang berbeda. Arsitektur yang disajikan di sini mengasumsikan distribusi sebelumnya yang sama untuk kata masukan dan keluaran. Oleh karena itu, ia berbagi lapisan penyematan (penyematan kata yang telah dilatih sebelumnya di Glove) antara proses pengkodean dan penguraian kode melalui penerapan model baru. Untuk meningkatkan sensitivitas konteks, vektor pemikiran (yaitu keluaran pembuat enkode) mengkodekan dua ucapan terakhir percakapan hingga titik saat ini. Untuk menghindari lupa konteks selama pembuatan jawaban, vektor pemikiran digabungkan menjadi vektor padat yang mengkodekan jawaban tidak lengkap yang dihasilkan hingga saat ini. Vektor yang dihasilkan diberikan ke lapisan padat yang memprediksi token jawaban saat ini. Lihat Bagian 3.1 makalah kami untuk pemahaman yang lebih baik tentang keunggulan model kami.
Algoritme melakukan iterasi dengan memasukkan token yang diprediksi ke dalam jawaban yang tidak lengkap dan memasukkannya kembali ke lapisan masukan sisi kanan model yang ditunjukkan di bawah.
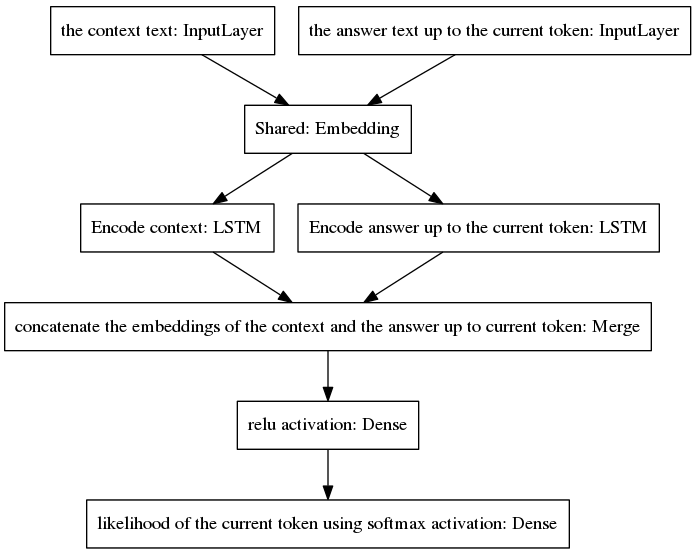
Seperti dapat dilihat pada gambar di atas, kedua LSTM disusun secara paralel, sedangkan seq2seq kanonik memiliki lapisan encoder dan decoder berulang yang disusun secara seri. Lapisan berulang dibuka selama propagasi mundur sepanjang waktu, menghasilkan sejumlah besar fungsi bersarang dan, oleh karena itu, risiko hilangnya gradien yang lebih tinggi, yang diperburuk oleh rangkaian lapisan berulang model seq2seq kanonik, bahkan dalam kasus arsitektur yang terjaga keamanannya seperti LSTM. Saya yakin ini adalah salah satu alasan mengapa model saya berperilaku lebih baik selama pelatihan dibandingkan seq2seq kanonik.
Pseudocode berikut menjelaskan algoritmanya.

Pelatihan model baru ini terjadi dalam beberapa periode. Dengan menggunakan kumpulan data contoh pelatihan 8K kami, hanya diperlukan 100 epoch untuk mencapai kehilangan cross-entropy kategoris sebesar 0,0318, dengan biaya 139 dtk/epoch yang dijalankan pada GPU GTX980. Performa model terlatih ini (disediakan dalam repositori ini) tampak sama meyakinkannya dengan performa model vanilla seq2seq yang dilatih pada ~300 ribu contoh pelatihan Cornell Movie Dialogs Corpus, namun memerlukan upaya komputasi yang jauh lebih sedikit untuk melatihnya.
Untuk mengobrol dengan model terlatih:
Unduh file python "conversation.py", file kosakata "vocabulary_movie", dan bobot bersih "my_model_weights20", yang dapat ditemukan di sini;
Jalankan percakapan.py.
Untuk mengobrol dengan model baru yang dilatih oleh algoritme pelatihan baru berbasis GAN kami:
Unduh file python "conversation_discriminator.py", file kosakata "vocabulary_movie", dan bobot bersih "my_model_weights20.h5", "my_model_weights.h5", dan "my_model_weights_discriminator.h5", yang dapat ditemukan di sini;
Jalankan percakapan_diskriminator.py.
Model ini memiliki performa yang lebih baik dengan menggunakan data pelatihan yang sama. Diskriminator model berbasis GAN digunakan untuk memilih jawaban terbaik antara dua model, satu dilatih oleh pemaksaan guru dan satu lagi dilatih dengan metode pelatihan mirip GAN kami yang baru, yang detailnya dapat ditemukan di makalah ini.
Untuk melatih model baru atau menyempurnakan data Anda sendiri:
Jika Anda ingin berlatih dari awal, hapus file my_model_weights20.h5. Untuk menyempurnakan data Anda, simpan file ini;
Unduh folder Glove 'glove.6B' dan sertakan folder ini di direktori chatbot (Anda dapat menemukan folder ini di sini). Algoritme ini menerapkan pembelajaran transfer dengan menggunakan penyematan kata yang telah dilatih sebelumnya, yang disesuaikan selama pelatihan;
Jalankan split_qa.py untuk membagi konten data pelatihan Anda menjadi dua file: 'context' dan 'answers' dan get_train_data.py untuk menyimpan kalimat yang diisi ke dalam file 'Padded_context' dan 'Padded_answers';
Jalankan train_bot.py untuk melatih chatbot (disarankan menggunakan GPU, untuk melakukannya ketik: THEANO_FLAGS=mode=FAST_RUN,device=gpu,floatX=float32,Exception_verbosity=high python train_bot.py);
Beri nama data pelatihan Anda sebagai "data.txt". File ini harus berisi satu ucapan dialog per baris. Jika kumpulan data Anda besar, setel variabel num_subsets (pada baris 29 dari train_bot.py) ke angka yang lebih besar.
Weights_file = 'my_model_weights20.h5' Weights_file_GAN = 'My_model_weights.h5' Weights_file_discrim = 'My_model_weights_discriminator.h5'
Ikhtisar bagus tentang implementasi model percakapan saraf saat ini untuk kerangka kerja yang berbeda (bersama dengan beberapa hasil) dapat ditemukan di sini.
Model kami dapat diterapkan pada tugas NLP lainnya, seperti peringkasan teks, lihat misalnya Alternatif 2: Model Rekursif A. Kami mendorong penerapan model kami dalam tugas lain, dalam hal ini, kami dengan hormat meminta Anda untuk mengutip karya kami sebaik mungkin. dapat dilihat pada dokumen ini, didaftarkan pada bulan Juli 2017.
Kode-kode ini dapat dijalankan di Ubuntu 14.04.3 LTS, Python 2.7.6, Theano 0.9.0, dan Keras 2.0.4. Penggunaan konfigurasi lain mungkin memerlukan beberapa adaptasi kecil.


