gutenberg dialog
1.0.0
Kode untuk mengunduh dan membuat Kumpulan Data Dialog Gutenberg versi Anda sendiri. Mudah diperluas dengan bahasa baru. Cobalah chatbot terlatih dalam berbagai bahasa di sini: https://ricsinaruto.github.io/chatbot.html.
| Tautan unduhan | Jumlah ucapan | Panjang ucapan rata-rata | Jumlah dialog | Panjang dialog rata-rata |
|---|---|---|---|---|
| Bahasa inggris | 14 773 741 | 22.17 | 2 526 877 | 5.85 |
| Jerman | 226 015 | 24.44 | 43 440 | 5.20 |
| Belanda | 129 471 | 24.26 | 23541 | 5.50 |
| Spanyol | 58 174 | 18.62 | 6 912 | 8.42 |
| Italia | 41388 | 19.47 | 6 664 | 6.21 |
| Hongaria | 18816 | 14.68 | 2 826 | 6.66 |
| Portugis | 16 228 | 21.40 | 2 233 | 7.27 |
? Hasilkan kumpulan data Anda sendiri dengan menyetel parameter yang memengaruhi trade-off ukuran-kualitas kumpulan data
Antarmuka modular memudahkan perluasan kumpulan data ke bahasa lain
? Anda dapat dengan mudah mengecualikan buku secara manual saat membuat kumpulan data
Jalankan setup.py yang menginstal paket yang diperlukan.
python setup.py
File utama harus dipanggil dari root repo. Perintah di bawah ini menjalankan alur pembuatan kumpulan data untuk bahasa yang dipisahkan koma yang diberikan sebagai argumen. Saat ini bahasa Inggris, Jerman, Belanda, Spanyol, Portugis, Italia, dan Hongaria didukung.
python code/main.py -l=en,de,nl,es,pt,it,hu -a
Semua argumen yang dapat diselesaikan dapat dilihat di bawah: 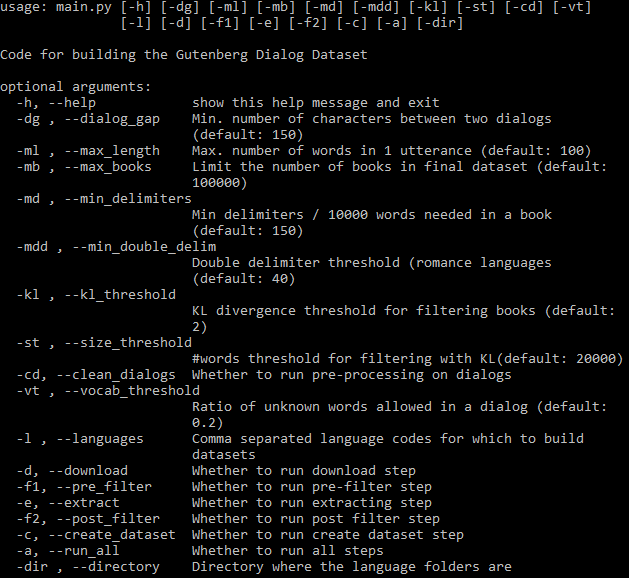
Bendera -a mengontrol apakah seluruh pipeline akan dijalankan secara otomatis. Jika -a dihilangkan, subset langkah harus ditentukan menggunakan flag (lihat bantuan di atas). Setelah suatu langkah selesai, outputnya dapat digunakan pada langkah berikutnya dan hanya dijalankan kembali jika parameter atau kode yang terkait dengan langkah tersebut diubah. Semua langkah dijalankan secara terpisah untuk setiap bahasa.
Unduh buku untuk bahasa tertentu.
Catatan: jika semua buku gagal diunduh dengan kesalahan "Tidak dapat mengunduh buku", kemungkinan besar penyebabnya adalah mirror default yang digunakan oleh paket gutenberg menjadi tidak dapat diakses. Jika hal ini terjadi, dimungkinkan untuk menggunakan salah satu mirror alternatif yang tercantum di https://www.gutenberg.org/MIRRORS.ALL melalui variabel lingkungan GUTENBERG_MIRROR . Misalnya:
export GUTENBERG_MIRROR="https://gutenberg.pglaf.org"
python code/main.py ...
Pra-pemfilteran menghilangkan beberapa buku lama dan kebisingan.
Dialog diambil dari buku. Saat memperluas kumpulan data ke bahasa baru (lihat bagian di bawah), ini adalah langkah yang dapat dimodifikasi, sehingga langkah sebelumnya dapat dilewati setelah selesai.
Langkah pemfilteran kedua menghapus beberapa dialog berdasarkan kosakata.
Menyatukan kumpulan data akhir dan membaginya menjadi data pelatihan/pengembangan/pengujian. Langkah terakhir membuat file author_and_title.txt di direktori keluaran yang berisi semua buku (ditambah judul dan penulis) yang digunakan untuk mengekstrak kumpulan data akhir. Pengguna dapat secara manual menyalin baris dari file ini ke banned_books.txt yang sesuai dengan buku yang tidak diizinkan dalam kumpulan data. Dalam menjalankan langkah apa pun selanjutnya, buku dalam file ini tidak akan diperhitungkan.
Kode dapat dengan mudah diperluas untuk memproses bahasa lain. File bernama <kode bahasa>.py harus dibuat di folder bahasa. Di sini kelas harus didefinisikan dengan nama kode bahasa huruf besar (misalnya En untuk Bahasa Inggris), dengan LANG atau subkelas lainnya sebagai induk. Dengan parameter konfigurasi self.cfg dapat diakses. Di dalam kelas ini 3 fungsi di bawah ini harus didefinisikan. Silakan lihat it.py sebagai contoh.
Statistik bahasa
Fungsi ini harus mengembalikan kamus yang kuncinya merupakan pembatas potensial. Untuk setiap pembatas, suatu fungsi harus didefinisikan (nilai dalam kamus), yang mengambil input sebuah baris dan mengembalikan sebuah angka. Angka ini misalnya dapat berupa jumlah pembatas, tanda apakah ada pembatas pada garis, dll. Biasanya penghitungan berbobot disarankan, bergantung pada pentingnya pembatas yang berbeda. Nilai tersebut akan digunakan untuk menentukan pembatas yang harus digunakan dalam masing-masing buku (diteruskan ke fungsi di bawah), dan untuk memfilter buku yang memiliki jumlah pembatas yang sedikit. en.py berisi contoh beberapa pembatas.
Fungsi ini harus mengekstrak dialog dari buku dan menambahkannya ke self.dialogs , yang merupakan daftar dialog, dan setiap dialog adalah daftar ucapan yang berurutan. Paragraph_list berisi buku sebagai daftar paragraf yang berurutan. pembatas adalah pembatas paling umum dalam file ini yang harus digunakan untuk mengekstrak dialog.
Fungsi ini digunakan untuk dialog pasca-pemrosesan (misalnya menghapus karakter tertentu). Dibutuhkan sebuah ucapan sebagai masukan. Harap dicatat bahwa tokenisasi kata nltk dijalankan secara otomatis.
Proyek ini dilisensikan di bawah Lisensi MIT - lihat file LISENSI untuk detailnya.
Harap sertakan tautan ke repo ini jika Anda menggunakan kumpulan data atau kode apa pun dalam pekerjaan Anda dan pertimbangkan untuk mengutip makalah berikut:
@inproceedings{Csaky:2021,
title = "The Gutenberg Dialogue Dataset",
author = "Cs{'a}ky, Rich{'a}rd and Recski, G{'a}bor",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics",
month = apr,
year = "2021",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/2004.12752",
}


