Seq2seqChatbots
1.0.0
Pembungkus tensor2tensor untuk melatih, berinteraksi, dan menghasilkan data secara fleksibel untuk chatbot saraf.
Wiki berisi catatan dan ringkasan saya dari lebih dari 150 publikasi terbaru terkait dengan pemodelan dialog saraf.
? Jalankan pelatihan Anda sendiri atau bereksperimen dengan model yang telah dilatih sebelumnya
✅ 4 kumpulan data dialog berbeda terintegrasi dengan tensor2tensor
? Tampaknya berfungsi dengan model atau hyperparameter apa pun yang disetel di tensor2tensor
Kelas dasar yang mudah diperluas untuk masalah dialog
Jalankan setup.py yang menginstal paket yang diperlukan dan memandu Anda mengunduh data tambahan:
python setup.py
Anda dapat mengunduh semua model terlatih yang digunakan dalam makalah ini dari sini. Setiap pelatihan berisi dua pos pemeriksaan, satu untuk minimum kerugian validasi dan satu lagi setelah 150 epoch. Data dan struktur folder pelatihan sama persis.
python t2t_csaky/main.py --mode=train
Argumen mode dapat berupa salah satu dari empat argumen berikut: {generate_data, train, decode, eksperimen} . Dalam mode eksperimen , Anda dapat menentukan apa yang harus dilakukan di dalam fungsi eksperimen pada file yang dijalankan . Penjelasan rinci diberikan di bawah ini, untuk fungsi masing-masing mode.
Anda dapat mengontrol flag dan parameter setiap mode secara langsung di file ini. Untuk setiap proses yang Anda mulai, file ini akan disalin ke direktori yang sesuai, sehingga Anda dapat dengan cepat mengakses parameter proses apa pun. Ada beberapa flag yang harus Anda atur untuk setiap mode (kamus FLAGS di file konfigurasi):
t2t_usr_dir : Jalur ke direktori tempat kode saya berada. Anda tidak perlu mengubahnya, kecuali Anda mengganti nama direktori.
data_dir : Jalur ke direktori tempat Anda ingin membuat pasangan sumber dan target, serta data lainnya. Kumpulan data akan diunduh satu tingkat lebih tinggi dari direktori ini ke dalam folder raw_data .
problem : Ini adalah nama masalah terdaftar yang dibutuhkan tensor2tensor. Dirinci di bagian generate_data di bawah. Semua jalur harus berasal dari root repo.
Mode ini akan mengunduh dan memproses data terlebih dahulu serta menghasilkan pasangan sumber dan target. Saat ini terdapat 6 masalah terdaftar yang dapat Anda gunakan selain yang diberikan oleh tensor2tensor:
persona_chat_chatbot : Masalah ini mengimplementasikan dataset Persona-Chat (tanpa menggunakan persona).
daily_dialog_chatbot : Masalah ini mengimplementasikan kumpulan data DailyDialog (tanpa menggunakan topik, tindakan dialog, atau emosi).
opensubtitles_chatbot : Masalah ini dapat digunakan untuk bekerja dengan dataset OpenSubtitles.
cornell_chatbot_basic : Masalah ini mengimplementasikan Cornell Movie-Dialog Corpus.
cornell_chatbot_separate_names : Soal ini menggunakan korpus Cornell yang sama, namun nama penutur dan penerima setiap ujaran ditambahkan, sehingga menghasilkan sumber ujaran seperti di bawah ini.
BIANCA_m0 barang bagus apa? KAMERA_m0
character_chatbot : Ini adalah masalah berbasis karakter umum yang dapat digunakan dengan kumpulan data apa pun. Sebelum menggunakan ini, file .txt yang dihasilkan oleh salah satu masalah di atas harus ditempatkan di dalam direktori data, dan setelah itu masalah ini dapat digunakan untuk menghasilkan file data berbasis karakter tensor2tensor.
Kamus PROBLEM_HPARAMS di file konfigurasi berisi parameter khusus masalah yang dapat Anda atur sebelum membuat data:
num_train_shards / num_dev_shards : Jika Anda ingin data kereta atau dev yang dihasilkan dipecah menjadi beberapa file.
kosa kata_ukuran : Ukuran kosa kata yang ingin kita gunakan untuk soal. Kata-kata di luar kosakata ini akan diganti dengan token.
dataset_size : Jumlah pasangan ucapan, jika kita tidak ingin menggunakan dataset lengkap (ditentukan oleh 0).
dataset_split : Tentukan pemisahan train-val-test untuk masalah tersebut.
dataset_version : Ini hanya relevan untuk dataset opensubtitles, karena dataset ini ada beberapa versi, Anda dapat menentukan tahun dataset yang ingin Anda download.
name_vocab_size : Ini hanya relevan untuk masalah cornell dengan nama terpisah. Anda dapat mengatur ukuran kosakata yang hanya berisi persona.
Mode ini memungkinkan Anda melatih model dengan masalah dan hyperparameter tertentu. Kode tersebut hanya memanggil skrip pelatihan tensor2tensor, sehingga model apa pun yang ada di tensor2tensor dapat digunakan. Selain itu, ada juga model subkelas dengan sedikit modifikasi:
gradien_checkpointed_seq2seq : Modifikasi kecil pada model seq2seq berbasis lstm, sehingga hpams sendiri dapat digunakan seluruhnya. Sebelum menghitung softmax unit tersembunyi LSTM diproyeksikan menjadi 2048 unit linier seperti di sini. Akhirnya, saya mencoba mengimplementasikan titik pemeriksaan gradien pada model ini, tetapi saat ini sudah dihapus karena tidak memberikan hasil yang baik.
Ada beberapa flag tambahan yang dapat Anda tentukan untuk menjalankan pelatihan di kamus FLAGS pada file konfigurasi, beberapa di antaranya adalah:
train_dir : Nama direktori tempat file pos pemeriksaan pelatihan akan disimpan.
model : Nama model: salah satu model di atas atau model yang ditentukan tensor2tensor.
hparams : Tentukan hparams_set yang terdaftar, atau biarkan kosong jika Anda ingin mendefinisikan hparams di file konfigurasi. Untuk menentukan hparams untuk model seq2seq atau transformator , Anda dapat menggunakan kamus SEQ2SEQ_HPARAMS dan TRANSFORMER_HPARAMS di file konfigurasi (periksa untuk lebih jelasnya).
Dengan mode ini Anda dapat memecahkan kode dari model yang dilatih. Parameter berikut mempengaruhi decoding (dalam kamus FLAGS di file konfigurasi):
decode_mode : Dapat bersifat interaktif , di mana Anda dapat mengobrol dengan model menggunakan baris perintah. mode file memungkinkan Anda menentukan file dengan ucapan sumber yang akan menghasilkan respons, dan mode himpunan data akan secara acak mengambil sampel data validasi yang diberikan dan mengeluarkan respons.
decode_dir : Direktori tempat Anda dapat menyediakan file untuk didekode, dan respons yang dihasilkan akan disimpan di sini.
input_file_name : Nama file yang harus Anda berikan dalam mode file (ditempatkan di decode_dir ).
output_file_name : Nama file, di dalam decode_dir , tempat respons keluaran akan disimpan.
beam_size : Ukuran balok, saat menggunakan pencarian balok.
return_beams : Jika False hanya mengembalikan balok atas, jika tidak, kembalikan jumlah balok_ukuran balok.
Berikut hasil dari kedua makalah tersebut.
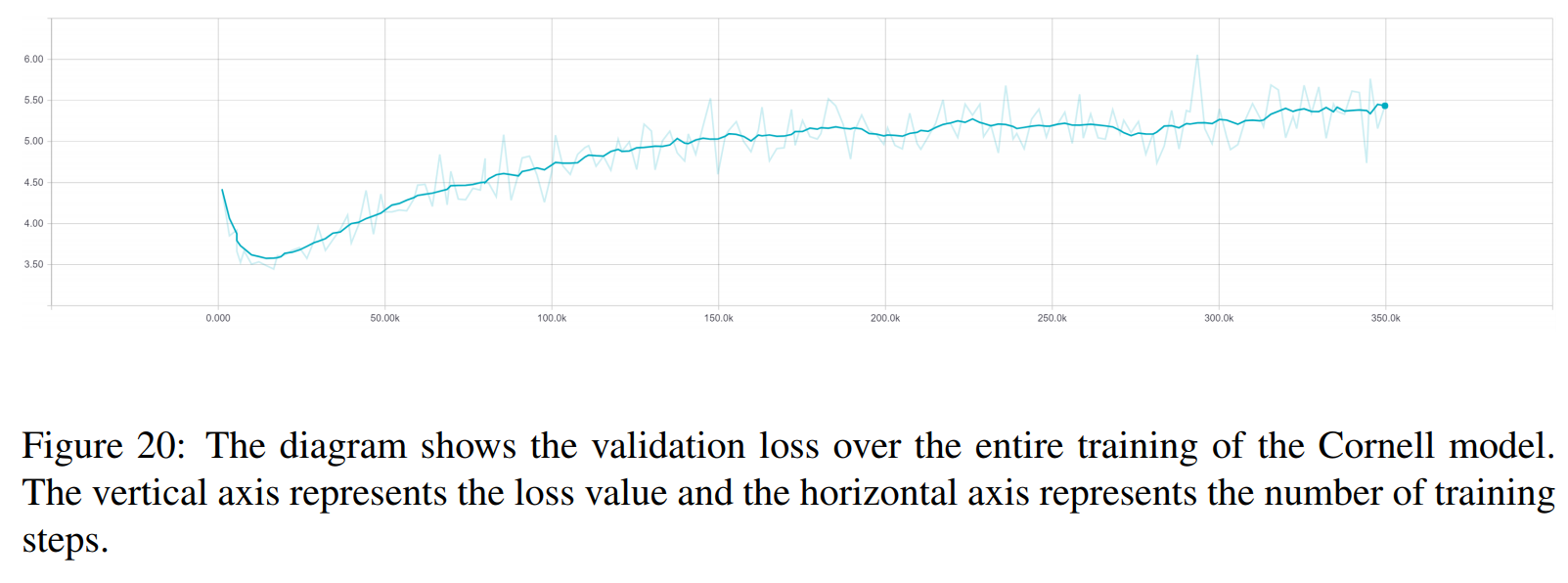

TRF adalah model Transformer, sedangkan RT berarti respons yang dipilih secara acak dari set pelatihan dan GT berarti respons kebenaran dasar. Untuk penjelasan tentang metrik, lihat makalah.
S2S adalah model seq2seq sederhana dengan LSTM yang dilatih di Cornell, yang lainnya adalah model Transformer. Opensubtitles F telah dilatih sebelumnya tentang Opensubtitles dan disempurnakan di Cornell. 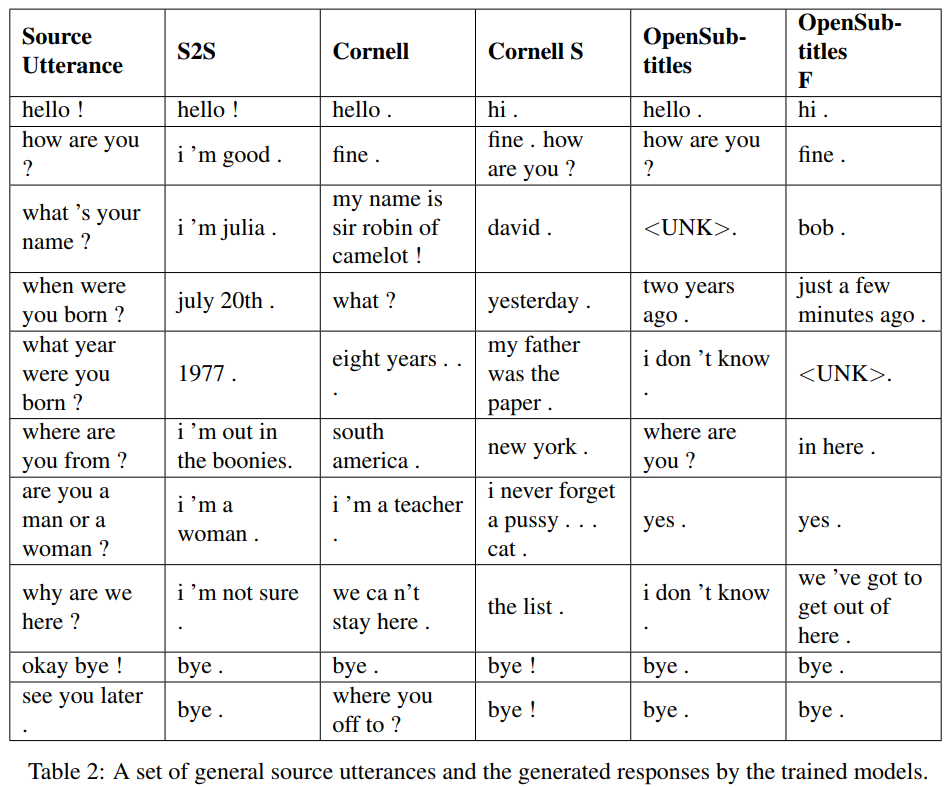
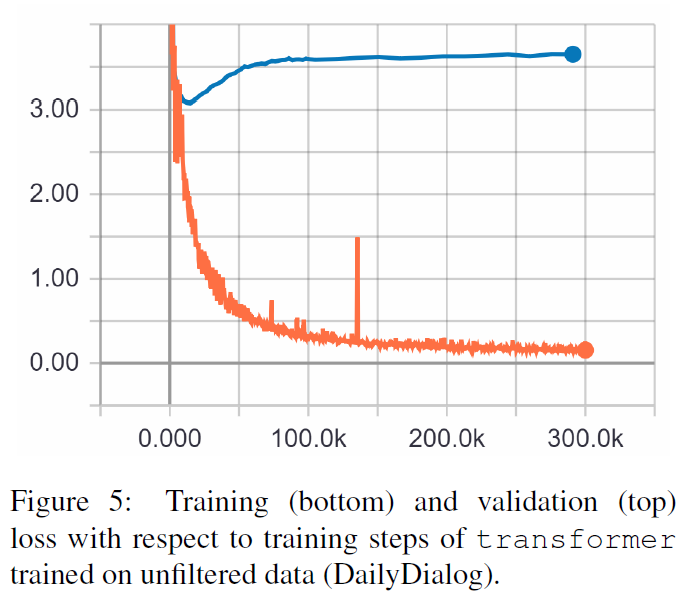

TRF adalah model Transformer, sedangkan RT berarti respons yang dipilih secara acak dari set pelatihan dan GT berarti respons kebenaran dasar. Untuk penjelasan tentang metrik, lihat makalah.
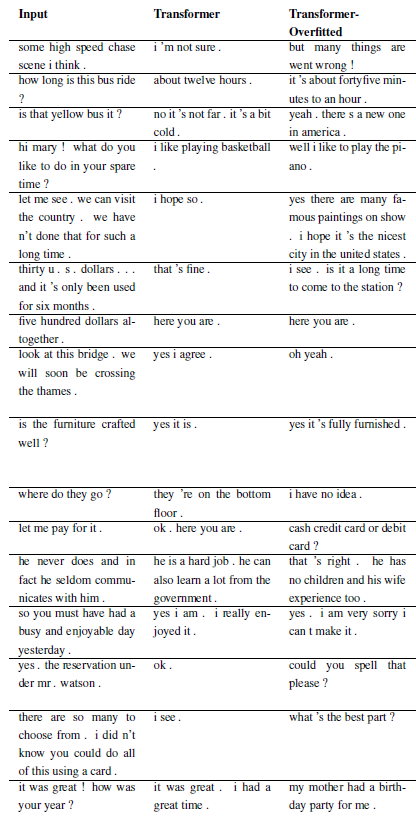
Masalah baru dapat didaftarkan dengan mensubkelaskan WordChatbot, atau bahkan lebih baik lagi dengan mensubkelaskan CornellChatbotBasic atau OpensubtitleChatbot, karena keduanya mengimplementasikan beberapa fungsi tambahan. Biasanya cukup dengan mengganti fungsi preprocess dan create_data . Periksa dokumentasi untuk detail selengkapnya dan lihat daily_dialog_chatbot sebagai contoh.
Model dan hyperparameter baru dapat ditambahkan dengan mengikuti tutorial tensor2tensor.
Richard Csaky (Jika Anda memerlukan bantuan dalam menjalankan kode: [email protected])
Proyek ini dilisensikan di bawah Lisensi MIT - lihat file LISENSI untuk detailnya.
Harap sertakan tautan ke repo ini jika Anda menggunakannya dalam pekerjaan Anda dan pertimbangkan untuk mengutip makalah berikut:
@InProceedings{Csaky:2017,
title = {Deep Learning Based Chatbot Models},
author = {Csaky, Richard},
year = {2019},
publisher={National Scientific Students' Associations Conference},
url ={https://tdk.bme.hu/VIK/DownloadPaper/asdad},
note={https://tdk.bme.hu/VIK/DownloadPaper/asdad}
} 

