Multi Modality Arena
1.0.0
Multi-Modality Arena adalah platform evaluasi untuk model multi-modalitas besar. Setelah Fastchat, dua model anonim dibandingkan secara berdampingan dalam tugas menjawab pertanyaan visual. Kami merilis Demo dan menyambut partisipasi semua orang dalam inisiatif evaluasi ini.
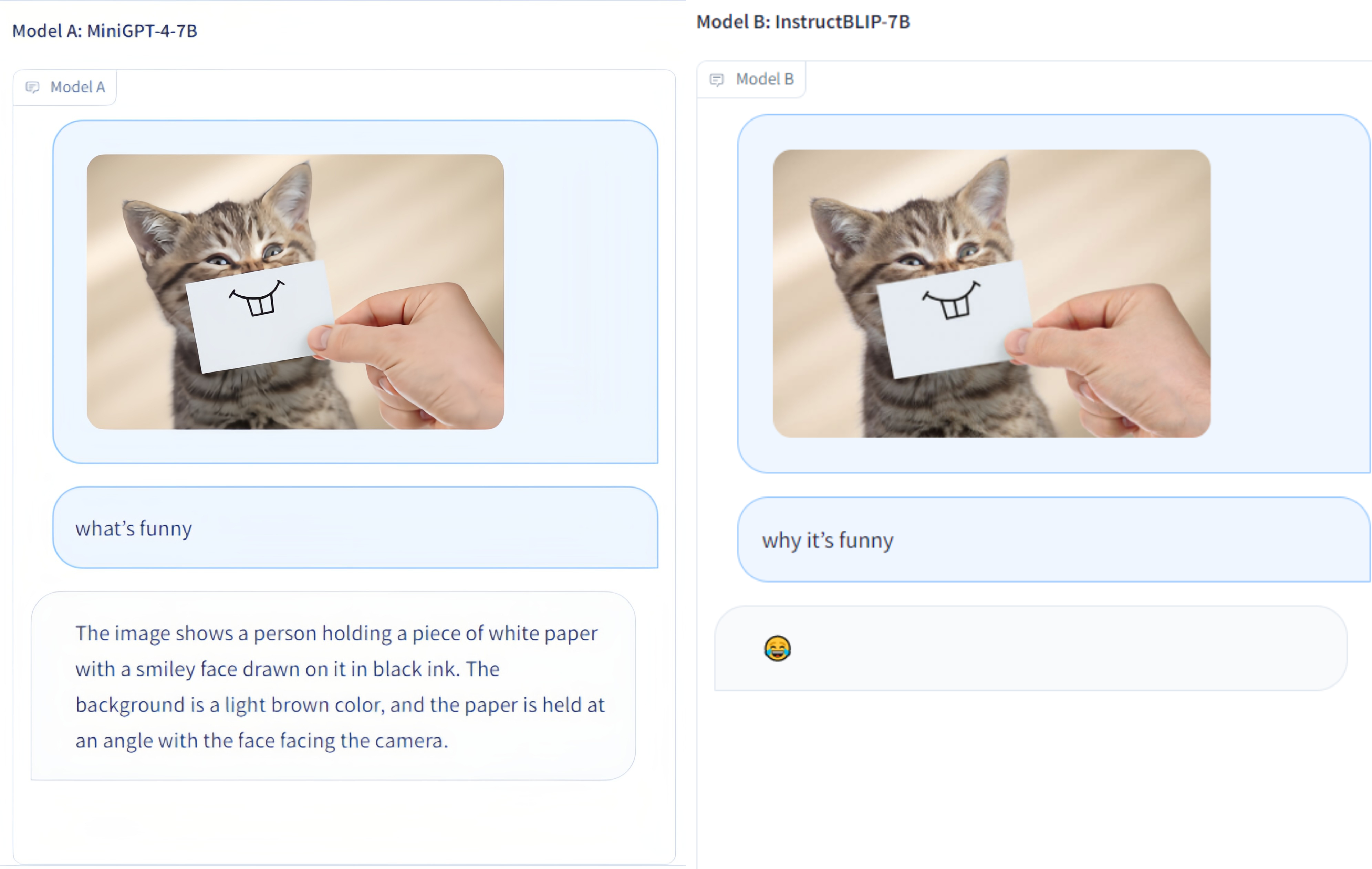
Kumpulan data OmniMedVQA: berisi 118.010 gambar dengan 127.995 item QA, mencakup 12 modalitas berbeda dan merujuk pada lebih dari 20 wilayah anatomi manusia. Dataset dapat diunduh dari Sini.
12 model: 8 LVLM domain umum dan 4 LVLM khusus medis.
Kumpulan data kecil: hanya 50 sampel yang dipilih secara acak untuk setiap kumpulan data, yaitu 42 tolok ukur visual terkait teks dan total 2,1 ribu sampel untuk kemudahan penggunaan.
Lebih banyak model: 4 model lainnya, yaitu total 12 model, termasuk Google Bard .
Evaluasi Ensemble ChatGPT : peningkatan kesesuaian dengan evaluasi manusia dibandingkan pendekatan pencocokan kata sebelumnya.
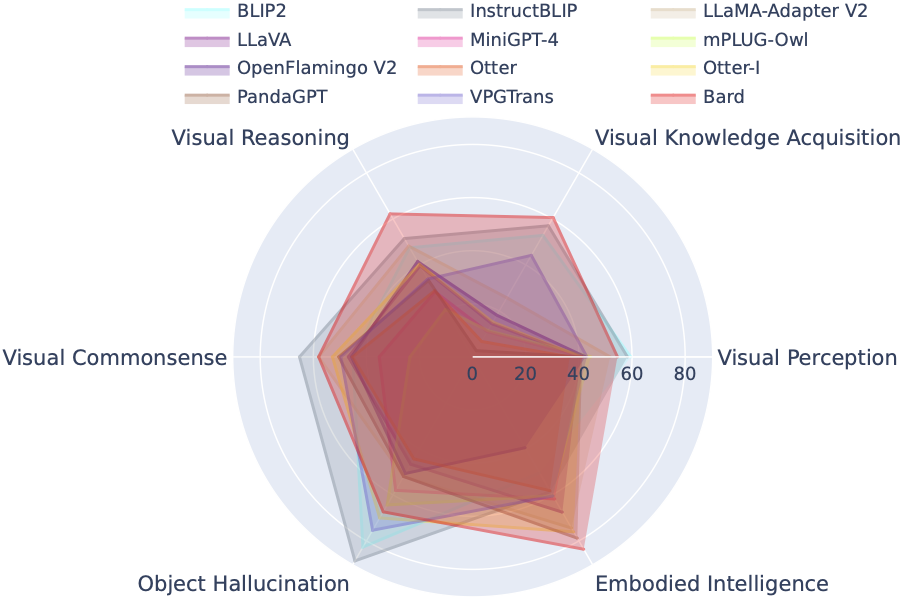
LVLM-eHub adalah tolok ukur evaluasi komprehensif untuk model multimodal besar (LVLM) yang tersedia untuk umum. Ini mengevaluasi secara ekstensif
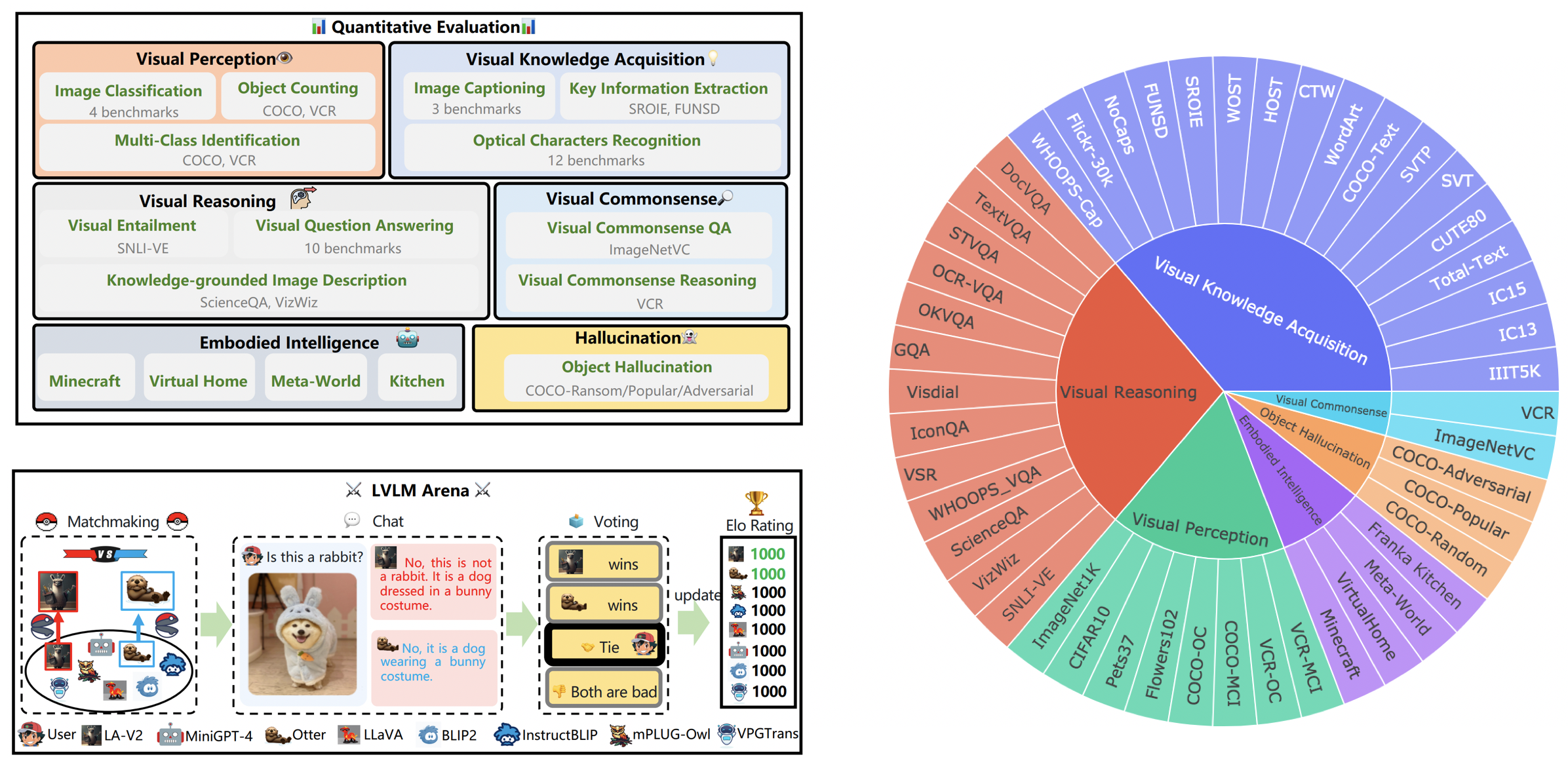
Papan Peringkat LVLM secara sistematis mengkategorikan kumpulan data yang ditampilkan dalam Evaluasi LVLM Kecil sesuai dengan kemampuan spesifik yang ditargetkan termasuk persepsi visual, penalaran visual, akal sehat visual, perolehan pengetahuan visual, dan halusinasi objek. Papan peringkat ini mencakup model-model yang baru dirilis untuk meningkatkan kelengkapannya.
Anda dapat mengunduh benchmark dari sini, dan detail lebih lanjut dapat ditemukan di sini.
| Pangkat | Model | Versi | Skor |
|---|---|---|---|
| 1 | MagangVL | InternVL-Obrolan | 327.61 |
| 2 | MagangLM-XComposer-VL | MagangLM-XComposer-VL-7B | 322.51 |
| 3 | Penyair | Penyair | 319.59 |
| 4 | Qwen-VL-Obrolan | Qwen-VL-Obrolan | 316.81 |
| 5 | LLaVA-1.5 | Vicuna-7B | 307.17 |
| 6 | InstruksikanBLIP | Vicuna-7B | 300,64 |
| 7 | MagangLM-XComposer | MagangLM-XComposer-7B | 288.89 |
| 8 | BLIP2 | FlanT5xl | 284.72 |
| 9 | BLIVA | Vicuna-7B | 284.17 |
| 10 | Lynx | Vicuna-7B | 279.24 |
| 11 | Cheetah | Vicuna-7B | 258.91 |
| 12 | Adaptor LLaMA-v2 | LLaMA-7B | 229.16 |
| 13 | VPGTrans | Vicuna-7B | 218.91 |
| 14 | Gambar Berang-berang | Otter-9B-LA-Dalam Konteks | 216.43 |
| 15 | VisualGLM-6B | VisualGLM-6B | 211.98 |
| 16 | mPLUG-Burung Hantu | LLaMA-7B | 209.40 |
| 17 | LLaVA | Vicuna-7B | 200,93 |
| 18 | MiniGPT-4 | Vicuna-7B | 192.62 |
| 19 | Berang-berang | Berang-berang-9B | 180,87 |
| 20 | OFv2_4BI | RedPajama-INCITE-Instruksikan-3B-v1 | 176.37 |
| 21 | PandaGPT | Vicuna-7B | 174.25 |
| 22 | LaVIN | LLaMA-7B | 97.51 |
| 23 | mikrofon | FlanT5xl | 94.09 |
31 Maret 2024. Kami merilis OmniMedVQA, tolok ukur evaluasi komprehensif berskala besar untuk LVLM medis. Sementara itu, kami memiliki 8 LVLM domain umum dan 4 LVLM khusus medis. Untuk lebih jelasnya, silakan kunjungi MedicalEval.
16 Oktober 2023. Kami menyajikan pemisahan kumpulan data tingkat kemampuan yang berasal dari LVLM-eHub, dilengkapi dengan penyertaan delapan model yang baru dirilis. Untuk akses ke pemisahan kumpulan data, kode evaluasi, hasil inferensi model, dan tabel kinerja komprehensif, silakan kunjungi tiny_lvlm_evaluation ✅.
8 Agustus 2023. Kami merilis [Tiny LVLM-eHub] . Kode sumber evaluasi dan hasil inferensi model bersumber terbuka di bawah tiny_lvlm_evaluation.
15 Juni 2023. Kami merilis [LVLM-eHub] , tolok ukur evaluasi untuk model bahasa visi besar. Kode akan segera hadir.
8 Juni 2023. Terima kasih, Dr. Zhang, penulis VPGTrans, atas koreksinya. Penulis VPGTrans sebagian besar berasal dari NUS dan Universitas Tsinghua. Kami sebelumnya mengalami beberapa masalah kecil saat mengimplementasikan ulang VPGTrans, namun ternyata kinerjanya sebenarnya lebih baik. Untuk penulis model lainnya, silakan hubungi saya untuk berdiskusi di Email. Selain itu, harap ikuti daftar peringkat model kami, di mana hasil yang lebih akurat akan tersedia.
Mungkin. 22, 2023. Terima kasih, Dr. Ye, penulis mPLUG-Owl, atas koreksinya. Kami memperbaiki beberapa masalah kecil dalam penerapan mPLIG-Owl.
Model berikut sedang terlibat dalam pertempuran acak saat ini,
KAUST/MiniGPT-4
Tenaga Penjualan/BLIP2
Tenaga Penjualan/InstruksiBLIP
Akademi DAMO/mPLUG-Owl
NTU/Berang-berang
Universitas Wisconsin-Madison/LLaVA
Lab AI Shanghai/llama_adapter_v2
NUS/VPGTrans
Detail selengkapnya tentang model ini dapat ditemukan di ./model_detail/.model.jpg . Kami akan mencoba menjadwalkan sumber daya komputasi untuk menampung lebih banyak model multi-modalitas di arena.
Jika Anda tertarik dengan platform VLarena kami, silakan bergabung dengan grup WeChat.

Ciptakan lingkungan conda
conda buat -n arena python=3.10 conda mengaktifkan arena
Instal Paket yang diperlukan untuk menjalankan pengontrol dan server
pip install numpy gradio uvicorn fastapi
Kemudian untuk setiap model, mereka mungkin memerlukan versi paket python yang bertentangan, kami menyarankan untuk membuat lingkungan khusus untuk setiap model berdasarkan repo GitHub mereka.
Untuk melayani menggunakan UI web, Anda memerlukan tiga komponen utama: server web yang berinteraksi dengan pengguna, pekerja model yang menghosting dua model atau lebih, dan pengontrol untuk mengoordinasikan server web dan pekerja model.
Berikut adalah perintah yang harus diikuti di terminal Anda:
pengontrol python.py
Pengontrol ini mengelola pekerja yang didistribusikan.
python model_worker.py --nama-model SELECTED_MODEL --perangkat TARGET_DEVICE
Tunggu hingga proses memuat model selesai dan Anda melihat "Uvicorn running on...". Pekerja model akan mendaftarkan dirinya ke pengontrol. Untuk setiap pekerja model, Anda perlu menentukan model dan perangkat yang ingin Anda gunakan.
python server_demo.py
Ini adalah antarmuka pengguna tempat pengguna akan berinteraksi.
Dengan mengikuti langkah-langkah ini, Anda akan dapat menyajikan model Anda menggunakan UI web. Anda dapat membuka browser dan mengobrol dengan seorang model sekarang. Jika model tidak muncul, coba reboot server web gradio.
Kami sangat menghargai semua kontribusi yang bertujuan untuk meningkatkan kualitas evaluasi kami. Bagian ini terdiri dari dua segmen utama: Contributions to LVLM Evaluation dan Contributions to LVLM Arena .
Anda dapat mengakses versi terbaru dari kode evaluasi kami di folder LVLM_evaluation. Direktori ini mencakup serangkaian kode evaluasi yang komprehensif, disertai dengan kumpulan data yang diperlukan. Jika Anda antusias untuk mengambil bagian dalam proses evaluasi, jangan ragu untuk membagikan hasil evaluasi Anda atau API inferensi model kepada kami melalui email di [email protected].
Kami mengucapkan terima kasih atas minat Anda untuk mengintegrasikan model Anda ke dalam LVLM Arena kami! Jika Anda ingin memasukkan model Anda ke dalam Arena kami, mohon siapkan penguji model yang disusun sebagai berikut:
class ModelTester:def __init__(mandiri, perangkat=Tidak Ada) -> Tidak ada:# TODO: inisialisasi model dan pra prosesor yang diperlukandef move_to_device(mandiri, perangkat) -> Tidak ada:# TODO: fungsi ini digunakan untuk mentransfer model antara CPU dan GPU (opsional)def generate(self, image, question) -> str: # TODO: kode inferensi model
Selain itu, kami terbuka terhadap tautan inferensi model online, seperti yang disediakan oleh platform seperti Gradio. Kontribusi Anda dihargai dengan sepenuh hati.
Kami mengucapkan terima kasih kepada tim terhormat di ChatBot Arena dan makalah mereka yang Menilai LLM sebagai juri atas karya berpengaruh mereka, yang menjadi inspirasi bagi upaya evaluasi LVLM kami. Kami juga ingin menyampaikan penghargaan yang tulus kepada para penyedia LVLM, yang kontribusinya yang berharga telah memberikan kontribusi signifikan terhadap kemajuan dan kemajuan model bahasa visi yang besar. Terakhir, kami berterima kasih kepada penyedia kumpulan data yang digunakan di LVLM-eHub kami.
Proyek ini adalah alat penelitian eksperimental untuk tujuan non-komersial saja. Perlindungannya terbatas dan mungkin menghasilkan konten yang tidak pantas. Ini tidak dapat digunakan untuk hal-hal ilegal, berbahaya, kekerasan, rasis, atau seksual.


