inverted_index
1.0.0
Mencari frasa yang diucapkan orang-orang di sekitar mungkin sulit. Bagaimana dengan pembaruan dinamis kumpulan data ini? Penyimpanan terukur dan latensi rendah? Tujuan utama saya dari proyek ini adalah untuk membangun sistem yang memenuhi persyaratan ini dan memungkinkan untuk mengikuti perkembangan tren yang ada di tweet secara real-time.
Mengikuti gagasan indeks terbalik, saya menerapkan aplikasi yang secara real-time menemukan tweet dengan konten tertentu, menyimpannya dalam sistem file lokal dan memungkinkan untuk melakukan pencarian berbasis kata segera setelah menginisialisasi koneksi klien.
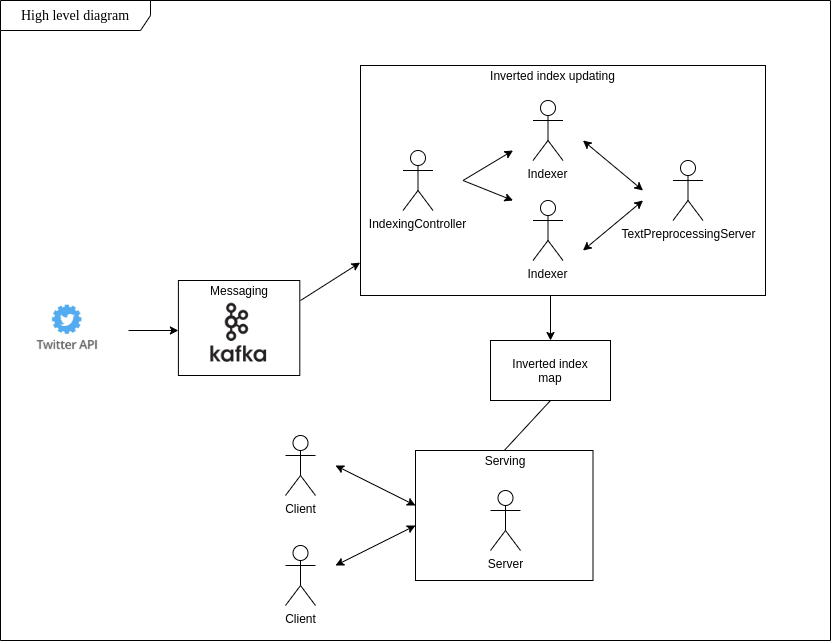
Untuk menjalankan aplikasi yang Anda perlukan:
git clone https://github.com/cyberpunk317/inverted_index.git TWITTER_APP_KEY = 'YOUR APP KEY'
TWITTER_APP_SECRET = 'YOUR APP SECRET'
TWITTER_KEY = 'YOUR KEY'
TWITTER_SECRET = 'YOUR SECRET' Buat Dockerfiles untuk klien dan server:
./gradlew clean build createClientDockerfile createMainDockerfile
Ini akan menghasilkan app_server.Dockerfile dan app_client.Dockerfile di direktori root.
Mulai aplikasi:
docker-compose up
Luncurkan sesi klien:
docker build -f app_client.Dockerfile -t client:latest . && docker run -it --rm --network=host client:latest bash
Mulailah mengetikkan kata-kata yang menarik. Server akan mengembalikan lokasi tweet dalam format 'dataset_v2//tweet_N.txt'. Misalnya:
You entered: war
Server response: [dataset_v2/Veeresh Dambal/tweet_30.txt, dataset_v2/pedro schliesser/tweet_1.txt]
Lihat masalah yang masih terbuka untuk mengetahui daftar fitur yang diusulkan (dan masalah umum).
Didistribusikan di bawah Lisensi MIT. Lihat LICENSE untuk informasi lebih lanjut.


