PubData
1.0.0

PubData adalah mesin pencari dan sistem pengambilan file untuk semua database bioinformatika di seluruh dunia. PubData mencari data FTP biomedis dengan cara yang mudah digunakan mirip dengan cara PubMed mencari literatur biomedis. PubData dihosting sebagai aplikasi web dan program perangkat lunak antarmuka pengguna grafis (GUI) mandiri, sementara PubMed dihosting sebagai server web online. PubData dibangun di atas pemrograman jaringan baru dan algoritme pemrosesan bahasa alami yang dapat ditambal ke server FTP dari database bioinformatika yang ditentukan pengguna, menanyakan kontennya, dan mengambil file untuk diunduh.
PubData ditulis dalam bahasa pemrograman Python (khususnya, Django dan PyQt4). PubData dapat mencari, mengakses, melihat, dan mengambil file dari jarak jauh dari pohon direktori yang sangat bersarang di database bioinformatika utama mana pun melalui jaringan komputer lokal. Dengan merakit semua database bioinformatika utama di bawah satu program perangkat lunak, PubData memungkinkan pengguna menghindari kerumitan yang tidak perlu dan kerumitan non-standar yang melekat pada pengaksesan database satu per satu menggunakan browser Internet. Lebih penting lagi, ini memungkinkan pengguna untuk menanyakan beberapa database secara bersamaan untuk kata kunci yang ditentukan pengguna (misalnya, human , cancer , transcriptome ). Dengan demikian, PubData memungkinkan peneliti untuk mencari, mengakses, melihat, dan mengunduh file dari server FTP database bioinformatika utama apa pun langsung dari satu lokasi terpusat. Dengan hanya menggunakan GUI atau aplikasi web, PubData memungkinkan pengguna menjelajahi beberapa server FTP bioinformatika secara bersamaan langsung dari kenyamanan komputer lokal mereka.
Silakan kutip: "Khomtchouk dkk.: 'PubData: mesin pencari untuk basis data bioinformatika di seluruh dunia', 2016: http://dx.doi.org/10.1101/069575" dalam sumber apa pun yang menggunakan metode apa pun yang terinspirasi oleh PubData .
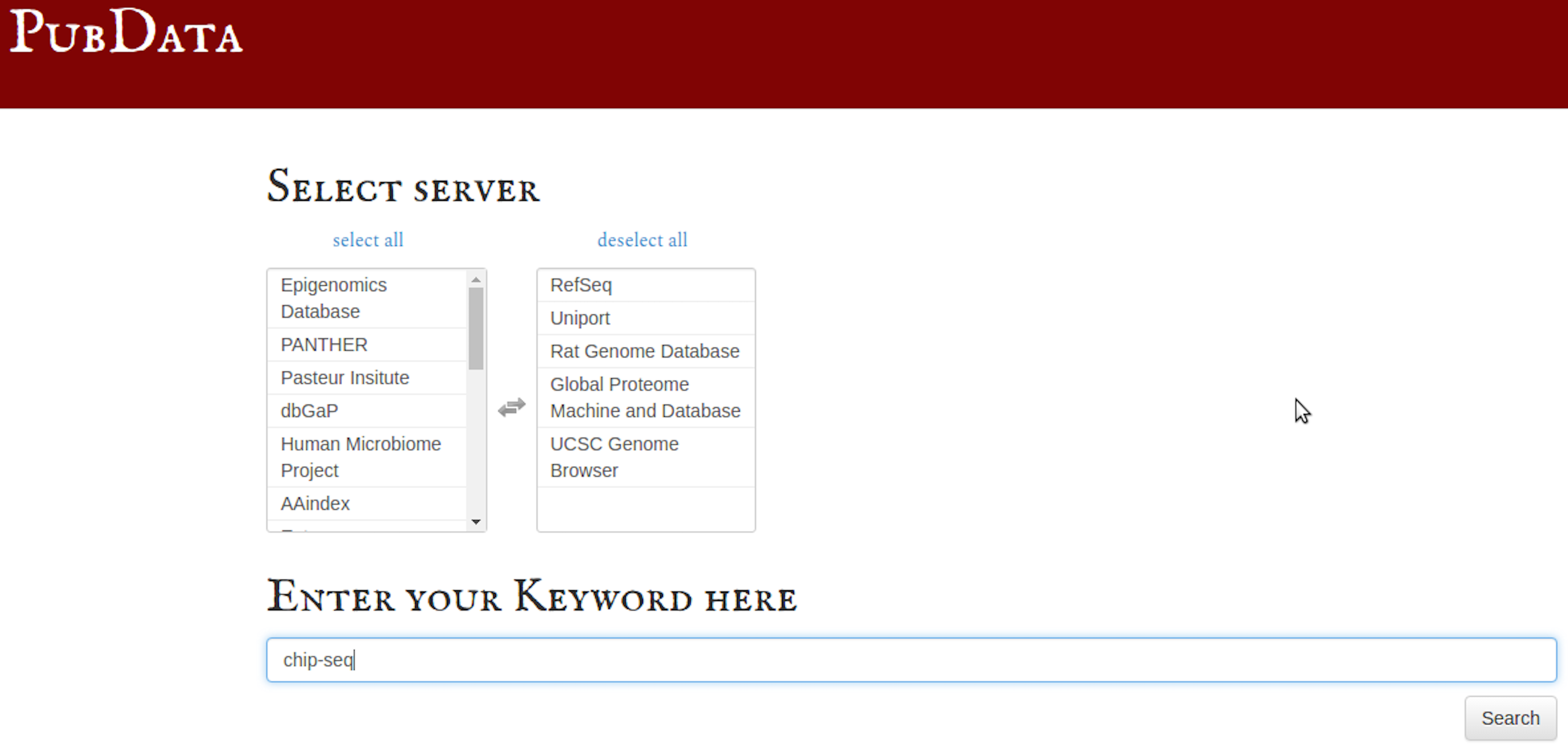
PubData . Saat Anda membuka PubData , pertama-tama pilih database bioinformatika untuk login:
Masuk ke database Sistem Klasifikasi PANTHER (Protein ANalysis THrough Evolutionary Relationships):
Jika Anda tidak melihat database favorit Anda dalam daftar, Anda dapat memasukkannya sendiri secara manual (nyaman untuk database yang baru diterbitkan):
Katakanlah Anda ingin "menelusuri Google" beberapa database secara bersamaan:
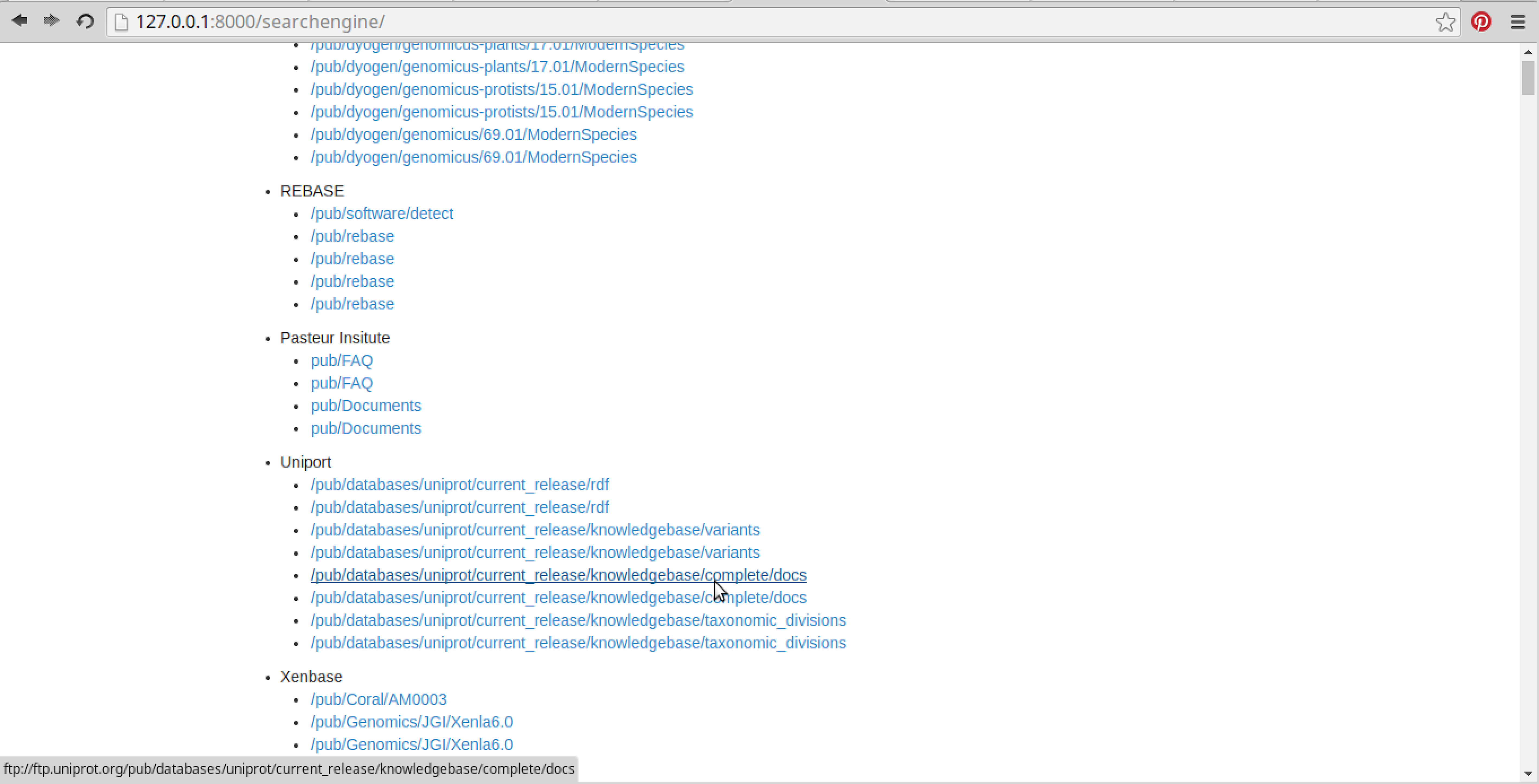
Pencarian kata kunci untuk file ChIP-seq di seluruh database yang dipilih ini (beberapa kata kunci juga dapat digunakan):
Menampilkan semua hasil pencarian relevan mengenai file ChIP-seq di semua database yang dipilih:
Pencarian kata kunci untuk file RNA-seq di seluruh database yang dipilih ini (beberapa kata kunci juga dapat digunakan):
Menampilkan semua hasil pencarian relevan mengenai file RNA-seq (dari database yang dipilih):


