Sound Content Music Recommendation System
1.0.0

Jika Anda seperti saya, Anda menyukai musik. Saya suka musik dan saya suka menemukan musik baru. Spotify adalah salah satu layanan streaming musik teratas di internet, dan sudah menyertakan alat luar biasa yang membantu Anda menemukan musik baru berdasarkan apa yang Anda dengarkan. Hal ini dilakukan melalui kombinasi algoritma yang berbeda, termasuk pemfilteran kolaboratif di mana penggunaan serupa antar pengguna dilacak dan digunakan untuk menghasilkan rekomendasi atau rekomendasi berbasis konten yang merekomendasikan lagu baru berdasarkan informasi serupa antara informasi yang ditautkan ke sebuah lagu. Seperti sebuah lagu? Di Spotify, Anda dapat mendengarkan 'radio' lagu tersebut, yang akan mengumpulkan sekelompok lagu yang mirip dengan lagu tersebut dalam beberapa cara atau kombinasi beberapa cara. Bagaimana jika Anda menyukai sebuah lagu, namun tidak peduli dengan informasi apa pun selain hanya suara di dalamnya? Terkadang, hanya itu yang ingin saya dengar.
Saya membuat proyek ini untuk membuat sistem rekomendasi musik berdasarkan informasi dalam suara musik saja. Ini akan membantu pengguna menemukan musik baru melalui lagu yang terdengar serupa. Untuk melakukan hal tersebut, ia juga akan mengeksplorasi kesamaan antara semua musik, dan berupaya menangkap timbre, ritme, dan gaya sebuah lagu secara matematis.
Suara selalu ada di sekitar kita. Sepanjang hidup kita, kita tumbuh untuk membedakan suara yang berbeda dari orang lain. Begitu pula dengan musik - ada banyak jenis musik dan musik sering kali merupakan kombinasi dari berbagai jenis suara dan ritme yang dapat kita bedakan satu sama lain. Tapi bisakah kita mengukur informasi itu untuk diri kita sendiri? Terkadang musik dikategorikan ke dalam genre, artinya genre adalah sekelompok musisi yang memiliki kualitas gaya, bentuk, ritme, timbre, instrumen, atau budaya yang serupa. Namun tidak semua artis musik menciptakan suara dalam genre yang sama, dan tidak semua genre berisi jenis musik yang sama. Jadi apa itu suara, dan bagaimana kita membedakan berbagai jenis suara?
Suara adalah getaran gelombang akustik yang kita rasakan melalui telinga kita ketika gelombang tersebut menggetarkan gendang telinga kita. Gelombang suara adalah sinyal dan kecepatan getaran sinyal tersebut disebut frekuensi. Jika frekuensi suara lebih tinggi, kita menganggap suara tersebut memiliki nada yang lebih tinggi. Dalam musik, instrumen seperti bass atau bass drum akan menghasilkan suara yang bergetar pada frekuensi yang lebih rendah, sedangkan nada tinggi memiliki frekuensi yang lebih tinggi. Kedengarannya seperti benturan simbal atau high hat adalah kombinasi dari banyak gelombang pada frekuensi berbeda dan diwakili oleh gelombang yang 'berisik' dan tampak hampir acak.
Seperti apa suaranya? Salah satu cara kita memvisualisasikan suara adalah dengan memplot sinyal sepanjang waktu:
Saat kami memperpendek jangka waktu pada setiap subplot, kami dapat melihat sinyal audio lebih dekat. Perhatikan pada gambar sinyal yang paling diperbesar, gelombang tersebut merupakan kumpulan frekuensi yang berbeda. Mungkin ada satu sinyal frekuensi rendah yang digabungkan dengan sinyal frekuensi tinggi yang lebih kecil.
Jadi kita dapat memvisualisasikan suatu sinyal dari waktu ke waktu, namun kita sudah dapat mengetahui bahwa sulit untuk memahami banyak tentang gelombang suara tersebut hanya dengan melihat visualisasi ini. Jenis frekuensi apa yang ada dalam jendela 0,01 detik itu? Untuk menjawabnya, kita akan menggunakan transformasi Fourier untuk menghitung spektogram.
Transformasi Fourier adalah metode penghitungan amplitudo frekuensi yang ada di suatu bagian sinyal audio. Seperti yang Anda lihat pada grafik di atas, gelombang bisa menjadi kompleks dan setiap variasi sinyal mewakili frekuensi (kecepatan getaran) yang berbeda. Transformasi Fourier pada dasarnya akan mengekstraksi frekuensi untuk setiap bagian waktu dan menghasilkan susunan amplitudo frekuensi 2 dimensi terhadap waktu. Produk transformasi Fourier adalah spektogram. Dari spektogram, kami mengubah frekuensi yang dihasilkan ke skala mel untuk membuat spektogram mel. Spektogram mel lebih baik mewakili jarak yang dirasakan antar frekuensi saat kita mendengarnya.
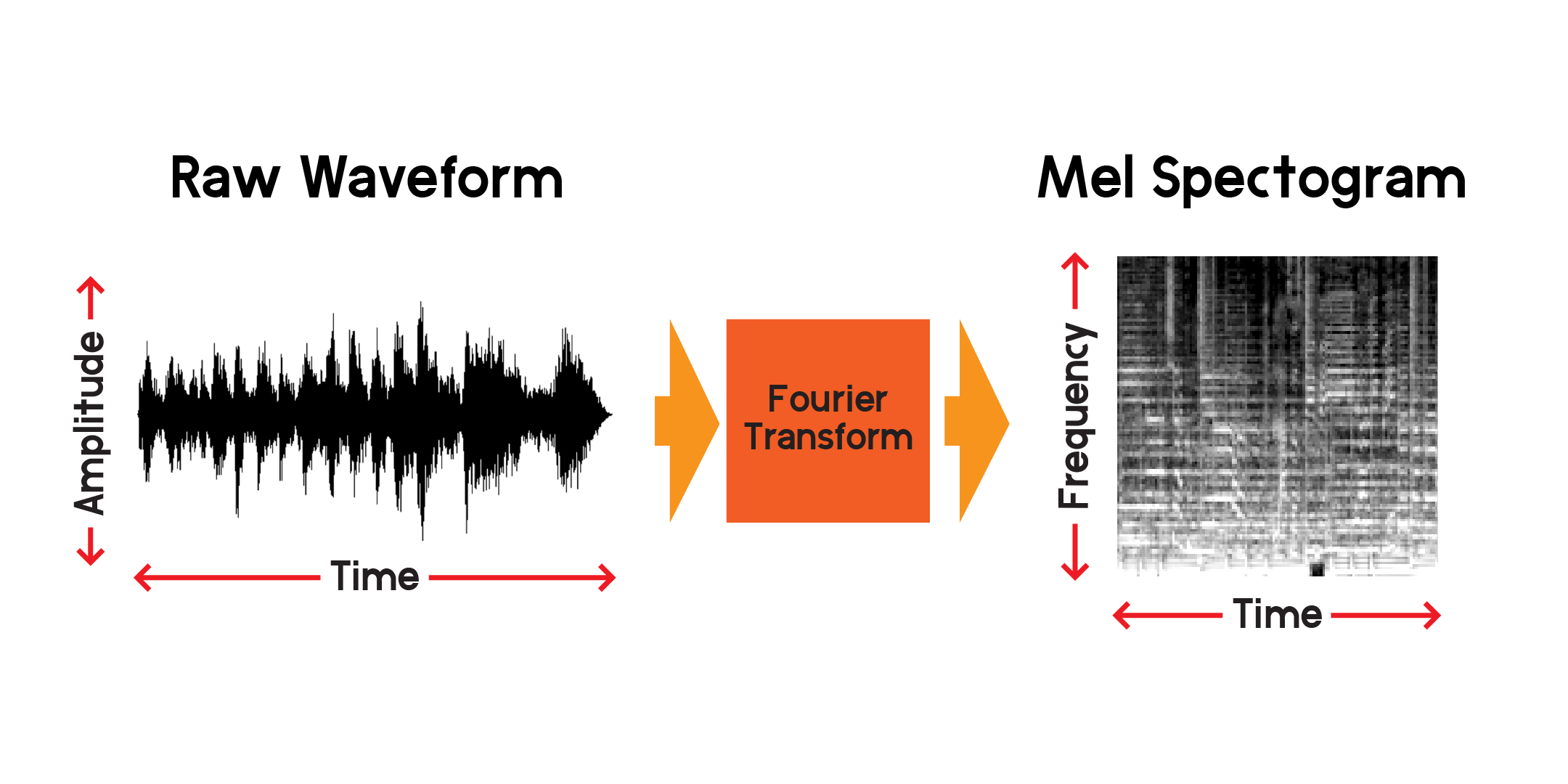
Mari kita buat contoh spektogram mel dari sampel audio yang sama yang kita buat di atas:
Menggunakan API Publik Spotify, saya mengambil informasi lagu di buku catatan sebelumnya. Dari sana saya dapat mengunduh pratinjau mp3 berdurasi 30 detik dari setiap lagu dan mengonversinya menjadi spektogram mel untuk digunakan dalam jaringan saraf yang melatih gambar. Pertama, mari kita lihat bingkai data yang akan kita gunakan untuk mengumpulkan pratinjau mp3.
Di buku catatan lain, saya mengambil tautan pratinjau dari Spotify API, mengunduh mp3, dan mengonversi file suara menjadi gambar komposit yang berisi spektogram mel, Koefisien Cepstral Frekuensi Mel, dan Kromagram. Saya membuat gambar komposit ini dengan tujuan agar saya dapat menggunakan transformasi lain ini, tetapi untuk proyek ini, saya hanya akan melatih jaringan saraf pada spektogram mel.
Untuk membuat rekomendasi lagu serupa berdasarkan konten suaranya saja, saya perlu membuat fitur yang menjelaskan konten lagu tersebut. Selain itu, untuk melakukan ini dengan cepat, saya perlu mengompresi informasi setiap lagu menjadi kumpulan angka yang lebih kecil daripada masukan spektogram mel.
Untuk setiap file pratinjau lagu, ada lebih dari 600.000 sampel. Pada setiap spektogram mel terdapat 512 x 128 piksel dengan total 65.536 piksel. Bahkan gambar 128x128 mengandung 16.384 piksel. Model autoencoder ini akan memampatkan konten lagu menjadi 256 angka saja. Setelah autoencoder dilatih secara memadai, jaringan akan dapat merekonstruksi lagu dari vektor sepanjang 256 tersebut dengan jumlah kerugian yang minimal.
Autoencoder adalah jenis jaringan saraf yang terdiri dari encoder dan decoder . Pertama, encoder akan memampatkan informasi masukan menjadi jumlah data yang jauh lebih kecil, dan decoder akan merekonstruksi data agar sedekat mungkin dengan keluaran aslinya.
Autoencoder juga merupakan jenis jaringan saraf khusus yang tidak diawasi, meskipun bukan berarti tidak diawasi. Model ini diawasi secara mandiri karena menggunakan masukannya untuk melatih keluaran model.
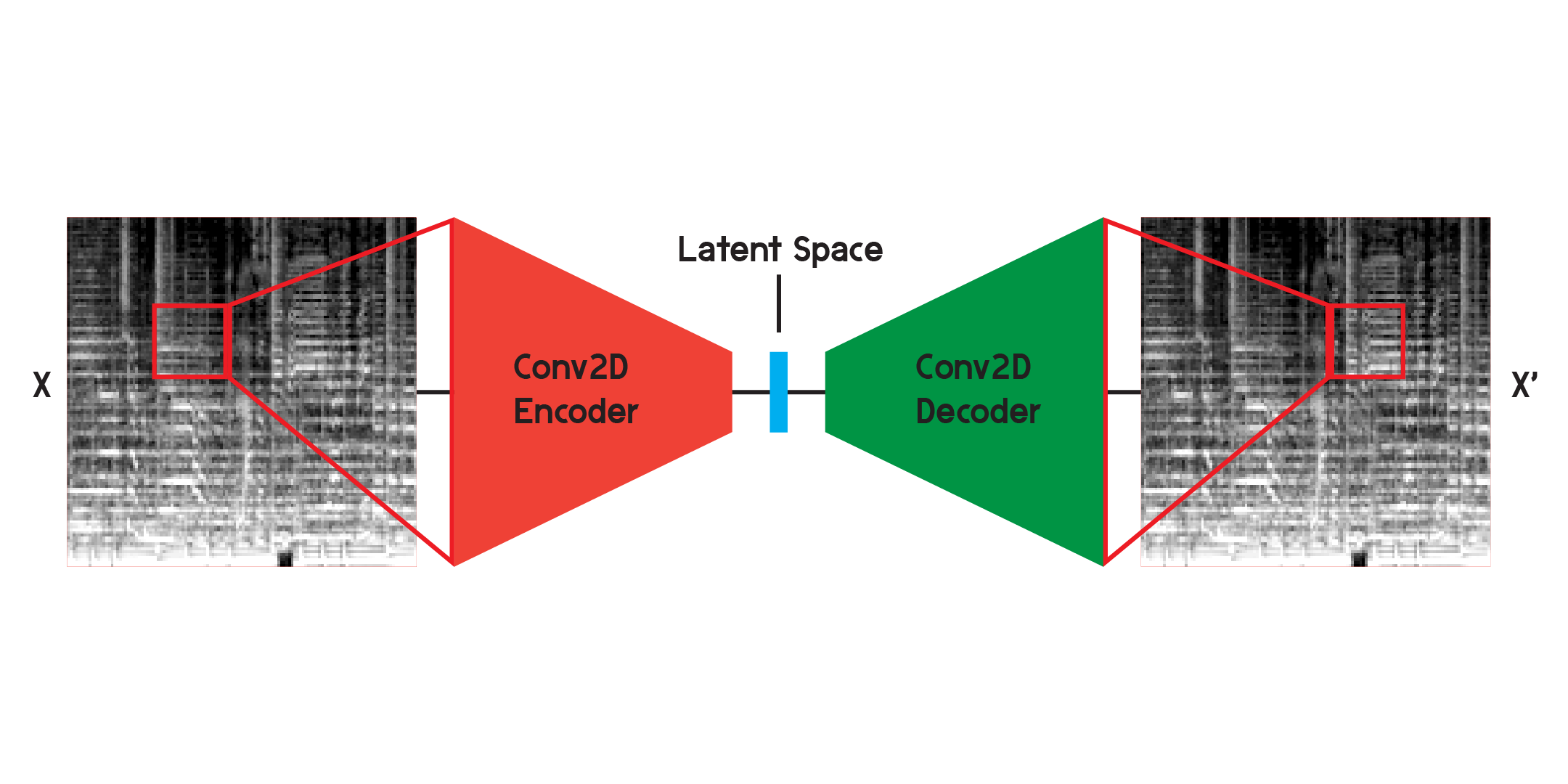
Saat bekerja dengan gambar, encoder adalah rangkaian lapisan konvolusional dua dimensi, yang membuat filter berbobot untuk mengekstrak pola dalam gambar, sekaligus mengompresi gambar menjadi bentuk yang semakin kecil. Decoder adalah cerminan dari proses di encoder, membentuk kembali dan memperluas sejumlah kecil data menjadi lebih besar. Model ini meminimalkan kesalahan kuadrat rata-rata antara model asli dan rekonstruksi. Setelah dilatih secara memadai, kesalahan kuadrat rata-rata antara model asli dan keluaran model akan sangat kecil. Meskipun kesalahan kuadrat rata-ratanya minimal, masih terdapat perbedaan visual antara gambar rekonstruksi dan gambar asli, terutama pada detail terkecil. Autoencoder adalah peredam kebisingan. Kami ingin mengekstrak detail sebanyak mungkin, namun pada akhirnya, autoencoder juga akan memadukan beberapa detail.
Saya awalnya melatih jaringan menggunakan struktur yang diilustrasikan di atas tetapi menemukan banyak detail yang hilang dalam rekonstruksi. Lapisan konvolusional mencari pola yang hanya merupakan potongan kecil dari keseluruhan gambar. Namun setelah melatih dan mengamati filter, sulit untuk memahami pola yang diekstraksi.
Autoencoder seperti ini dapat digunakan pada beberapa masalah berbeda, dan dengan lapisan konvolusional, terdapat banyak aplikasi untuk pengenalan dan pembuatan gambar. Namun karena spektogram mel bukan hanya berupa gambar tetapi juga grafik frekuensi konten suara dari waktu ke waktu, saya yakin struktur yang sedikit berbeda dapat diterapkan untuk meminimalkan kerugian dalam rekonstruksi, sekaligus meminimalkan ketidakpastian yang diciptakan oleh konvolusional 2 dimensi. lapisan.
Dalam model yang digunakan untuk hasil akhir model, saya membagi encoder menjadi dua encoder terpisah. Setiap pembuat enkode menggunakan lapisan konvolusional satu dimensi untuk mengompresi ruang gambar. Satu pembuat enkode melatih X, sedangkan pembuat enkode lainnya melatih transpos X atau versi input yang diputar 90 derajat. Dengan cara ini salah satu pembuat enkode mempelajari informasi dari sumbu waktu gambar, dan pembuat enkode lainnya mempelajari informasi dari sumbu frekuensi.
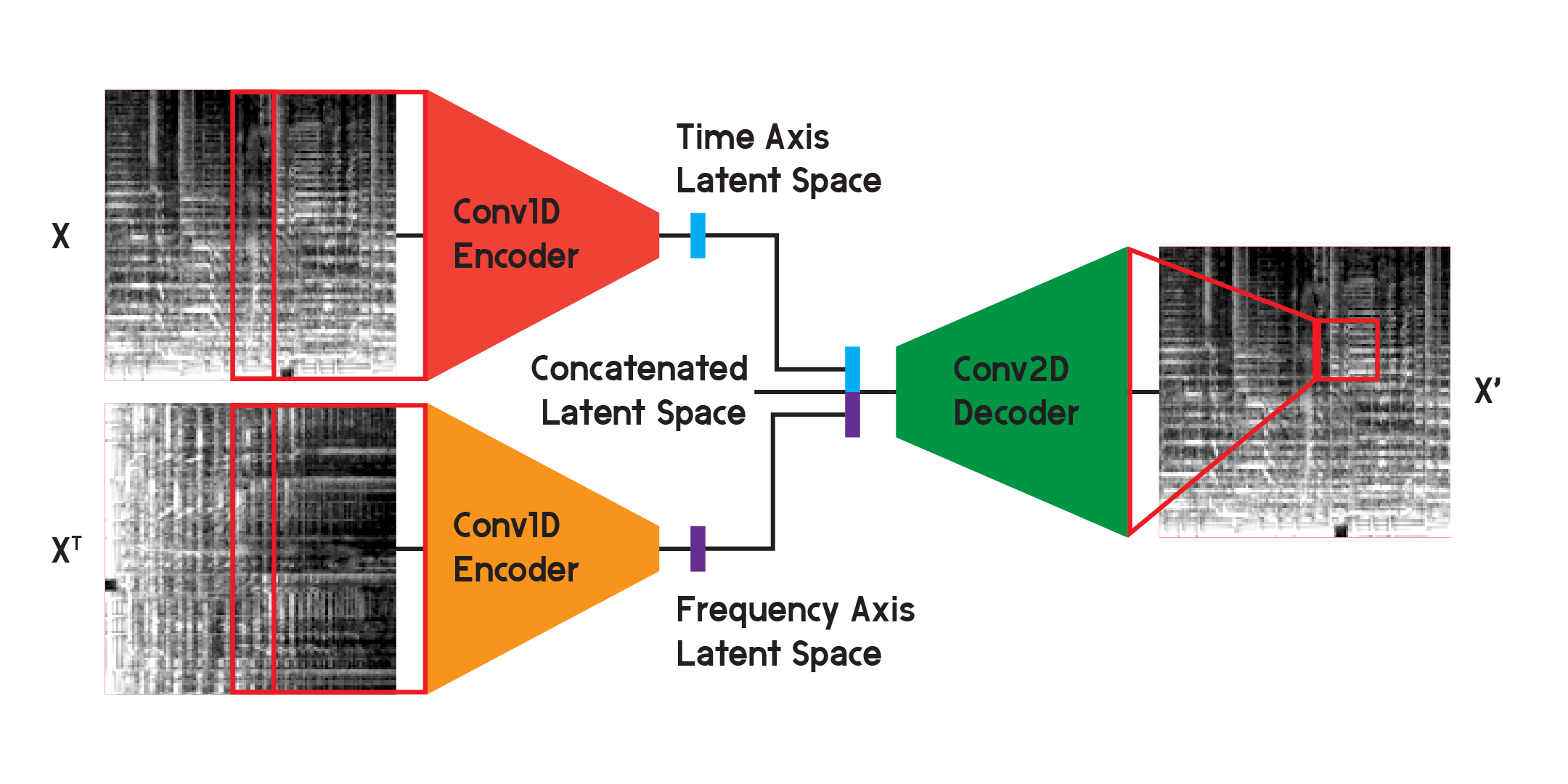
Setelah masukan dijalankan melalui setiap encoder, vektor-vektor yang dikodekan yang dihasilkan digabungkan menjadi satu vektor dan dimasukkan ke dalam decoder konvolusional dua dimensi seperti yang diilustrasikan sebelumnya. Outputnya dilatih untuk meminimalkan kerugian antara input seperti sebelumnya.
Pada akhirnya, kerugian pada model akhir jauh lebih rendah dibandingkan pada struktur dasar, mencapai rata-rata kesalahan kuadrat sebesar 0,0037 (pelatihan) dan 0,0037 (validasi) setelah 20 epoch, dengan 125.440 gambar di set pelatihan, dan 2560 di set pelatihan. set validasi.
Kami akan membuat model di sini untuk tujuan demonstrasi saja, karena saya melatih model tersebut di buku catatan lain, dan akan memuat bobot dari model yang dilatih setelah model tersebut dibuat.
Dengan menggunakan kelas khusus untuk menjalankan inferensi melalui jaringan dan menyimpan hasilnya, kita dapat membuat ruang laten untuk setiap spektogram mel yang kita miliki. Kita dapat melakukan ini dengan menjalankan data hanya melalui encoder dan menerima vektor seukuran yang kita inisialisasi modelnya, dalam hal ini 256 dimensi.
Untuk mengeksplorasi lanskap abstrak yang diciptakan oleh ruang laten data melalui model, kita dapat menggunakan reduksi dimensi. UMAP, seperti T-SNE, dapat mereduksi ruang multidimensi menjadi 2 dimensi untuk divisualisasikan dalam sebuah plot.
Kelas LatentSpace khusus akan mencari rekomendasi menggunakan kesamaan kosinus untuk setiap vektor.
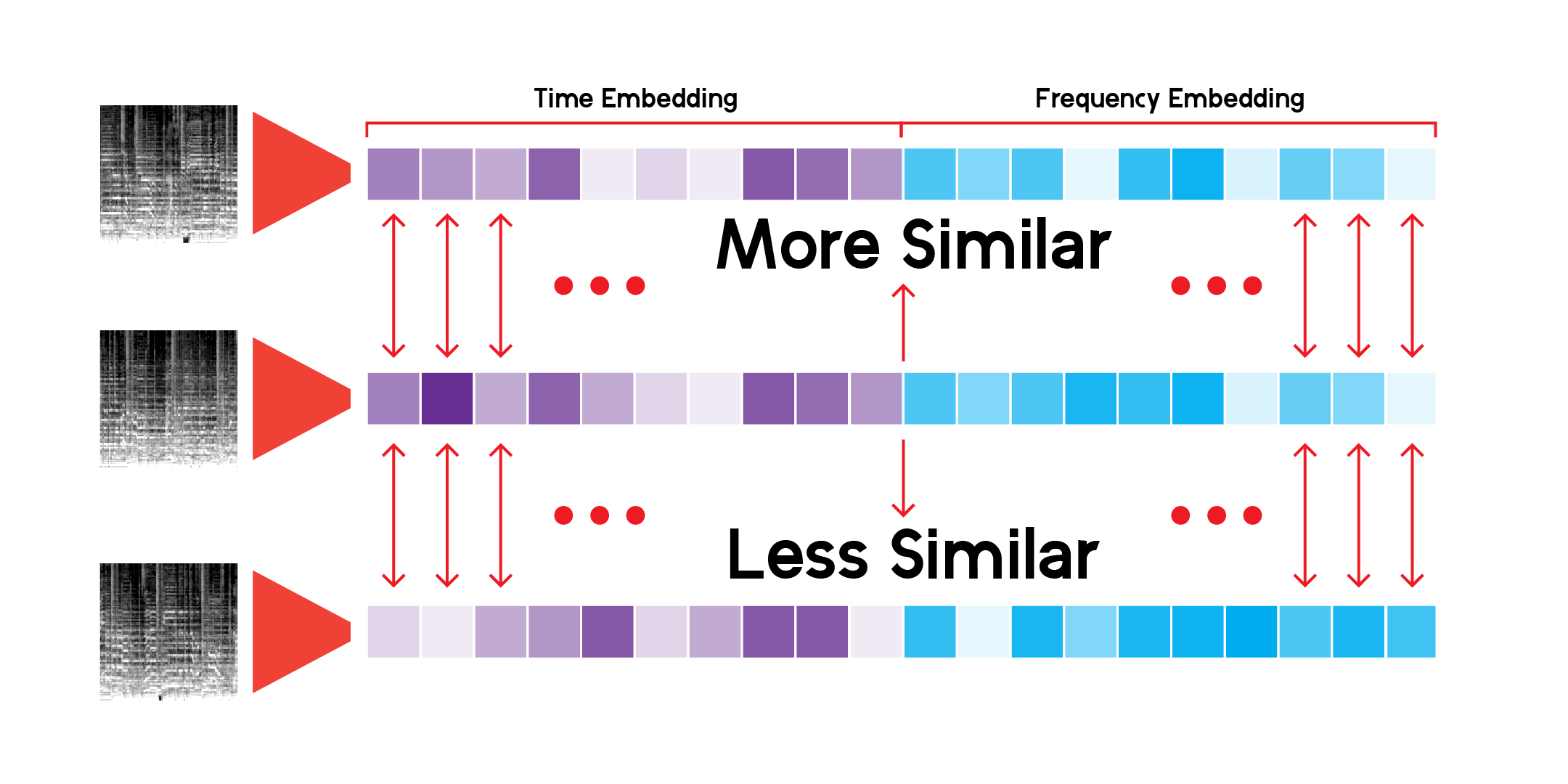
Saya telah menelusuri sistem rekomendasi ini tanpa henti, dan saya puas bahwa model tersebut dapat memilih hubungan yang sangat menarik antara suara musik yang berbeda namun juga mirip. Berikut beberapa kesimpulan saya:
Yang saya maksud dengan ini adalah model membuat rekomendasi berdasarkan konten suara di setiap lagu, namun tidak mendengarkan lagunya. Ini menciptakan spektogram mel dan membuat perbandingan matematis.
Terkadang sistem akan membuat rekomendasi lagu berdasarkan usianya. Jika sebuah lagu direkam sejak lama, frekuensi tertentu dari bahan atau peralatan rekaman tersebut akan diambil oleh model, dan menampilkan hasilnya.
Selain itu, modelnya sangat pandai menangkap suara atau instrumen tertentu. Oleh karena itu, jika sebuah lagu mengandung banyak percakapan atau nyanyian yang berbicara, lagu tersebut mungkin hanya merekomendasikan lagu dengan kata-kata yang diucapkan. Selain itu, jika ada banyak distorsi dalam sebuah lagu, mungkin akan direkomendasikan suara hujan atau nyanyian burung.
Beberapa pratinjau lagu tidak tersedia di Spotify API, seperti yang ditunjukkan dalam EDA awal saya. Oleh karena itu, kontribusi mereka terhadap model juga hilang dan tidak akan menjadi rekomendasi padahal mereka mungkin cocok untuk model tersebut. Misalnya, tidak ada lagu karya James Brown, The Beatles, atau Prince. Membutuhkan lebih banyak data.
Sistem ini menggunakan lebih dari 278.000 pratinjau untuk membuat rekomendasi, dan itu masih belum cukup. Melihat proyeksi UMAP untuk semua track, terdapat banyak kesinambungan data, namun terdapat beberapa lubang. Idealnya, sistem dapat menggunakan lebih banyak data untuk digunakan.
Apa yang membuat sistem/layanan rekomendasi seperti Spotify begitu baik dalam memberikan rekomendasi adalah sistem/layanan ini menggabungkan berbagai jenis sistem rekomendasi dan fitur seperti ini untuk memberikan rekomendasi. Dari melacak apa yang rutin Anda dengarkan, hingga menggunakan pemfilteran kolaboratif untuk menemukan rekomendasi berdasarkan penggunaan serupa oleh pengguna, Spotify dapat membuat prediksi yang jauh lebih seimbang tentang apa yang disukai dan didengarkan seseorang. Menurut saya model ini menarik untuk membuat prediksi, namun model ini dapat ditingkatkan dengan menambahkan lebih banyak fitur seperti genre serupa, tahun rilis, dan data pengguna serupa untuk membuat prediksi yang lebih baik.
Secara keseluruhan, selain membuat prediksi dan rekomendasi, saya merasa pentingnya model ini dalam menjelaskan kontinuitas dan spektrum bahasa dan suara musik. Genre adalah label yang diberikan orang pada artis atau suara, namun genre menyatu dan setiap suara ada dalam ruang yang berkesinambungan ini, setidaknya secara matematis.
Selain itu, musik tidak memiliki hambatan. Sering kali, saat menanyakan sebuah lagu di sistem rekomendasi, hasilnya akan datang dari berbagai era dan tempat berbeda. Karena tidak ada metadata lagu yang merupakan masukan untuk autoencoder, hasilnya didasarkan pada kesamaan soniknya, dan tidak lebih.


