nlp lt
1.0.0
Tujuan utama dari penelitian ini adalah untuk mempelajari dan mempelajari prinsip-prinsip pemrosesan bahasa alami (NLP) untuk bahasa Lituania. Sangat menarik untuk menganalisis metode NLP klasik dan melihat cara kerjanya, jadi dalam karya ini saya menerapkan klasifikasi teks, ekstraksi topik, permintaan pencarian, dan pengelompokan ide. Detail implementasi dan informasi lebih lanjut disimpan di paper/paper.pdf
Analisis data tidak dapat dilakukan tanpa memiliki data tekstual, oleh karena itu pekerjaan saya dimulai dari mendapatkan data mentah dari situs berita terpopuler www.delfi.lt. Saya memutuskan untuk merayapi artikel dari 5 kategori (Penjahat[227 artikel], Musik[120 artikel], Film[167 artikel], Olahraga[136 artikel], Sains[204 artikel]).
Kinerja klasifikasi diukur menggunakan matriks konfusi dimana baris adalah kategori sebenarnya dan kolom adalah kategori prediksi. Selain itu pendekatan tersebut mencapai recall di atas 90% dan presisi 90%.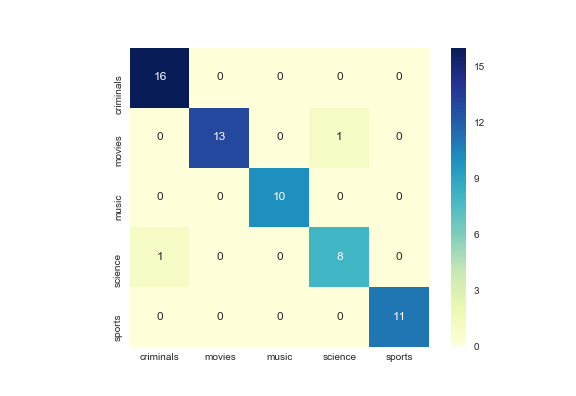
Gambar menunjukkan 6 komponen dengan 10 token untuk setiap komponen. Dari hasil ini kami dapat mendeteksi kata-kata yang paling penting dan secara intuitif menebak topik untuk setiap komponen utama. Misalnya 4 komponen utama menyimpan informasi tentang olahraga dan musik sedangkan 6 komponen utama menyimpan informasi tentang penjahat.
Hasil utama disajikan di bawah ini: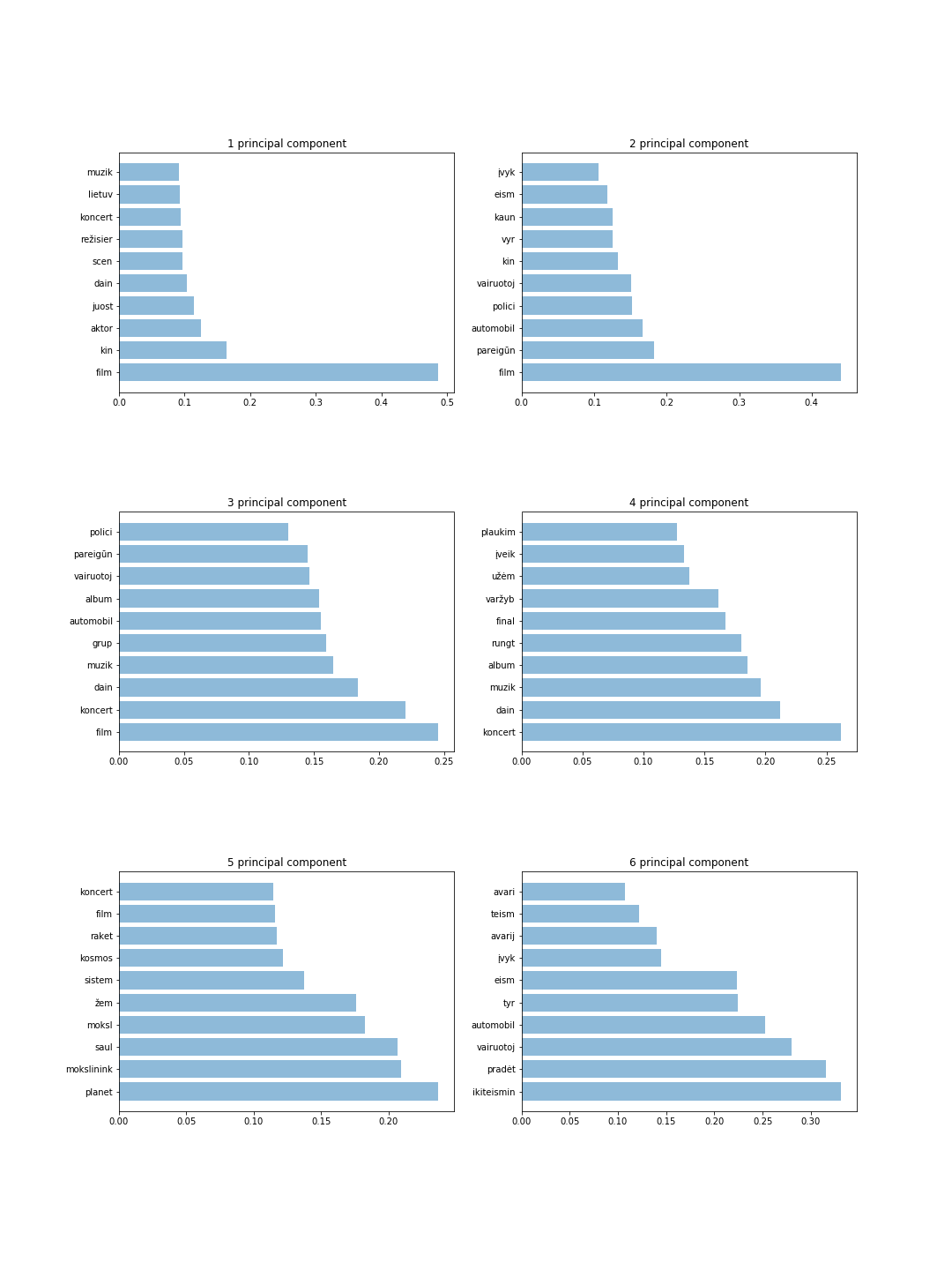
Pencarian didasarkan pada artikel http://webhome.cs.uvic.ca/~thomo/svd.pdf, di mana lsa diterapkan untuk menemukan dokumen terkait tidak hanya menggunakan kesamaan kueri yang tepat, tetapi juga hubungan yang lebih dalam antar dokumen.
Kueri = "švietim apdovanojam"
Hasil:
Sedang berlangsung


