vaex
Version linked to the paper
Vaex adalah pustaka Python berkinerja tinggi untuk DataFrame Out-of-Core yang lambat (mirip dengan Pandas), untuk memvisualisasikan dan menjelajahi kumpulan data tabel besar. Ini menghitung statistik seperti rata-rata, jumlah, hitungan, deviasi standar, dll, pada kisi N-dimensi selama lebih dari satu miliar ( 10^9 ) sampel/baris per detik . Visualisasi dilakukan menggunakan histogram , plot kepadatan , dan rendering volume 3d , memungkinkan eksplorasi interaktif data besar. Vaex menggunakan pemetaan memori, kebijakan penyalinan tanpa memori, dan komputasi lambat untuk kinerja terbaik (tidak ada memori yang terbuang).
Dengan pip:
$ pip install vaex
Atau conda:
$ conda install -c conda-forge vaex
Untuk lebih jelasnya, lihat dokumentasi
HDF5 dan Apache Arrow didukung.

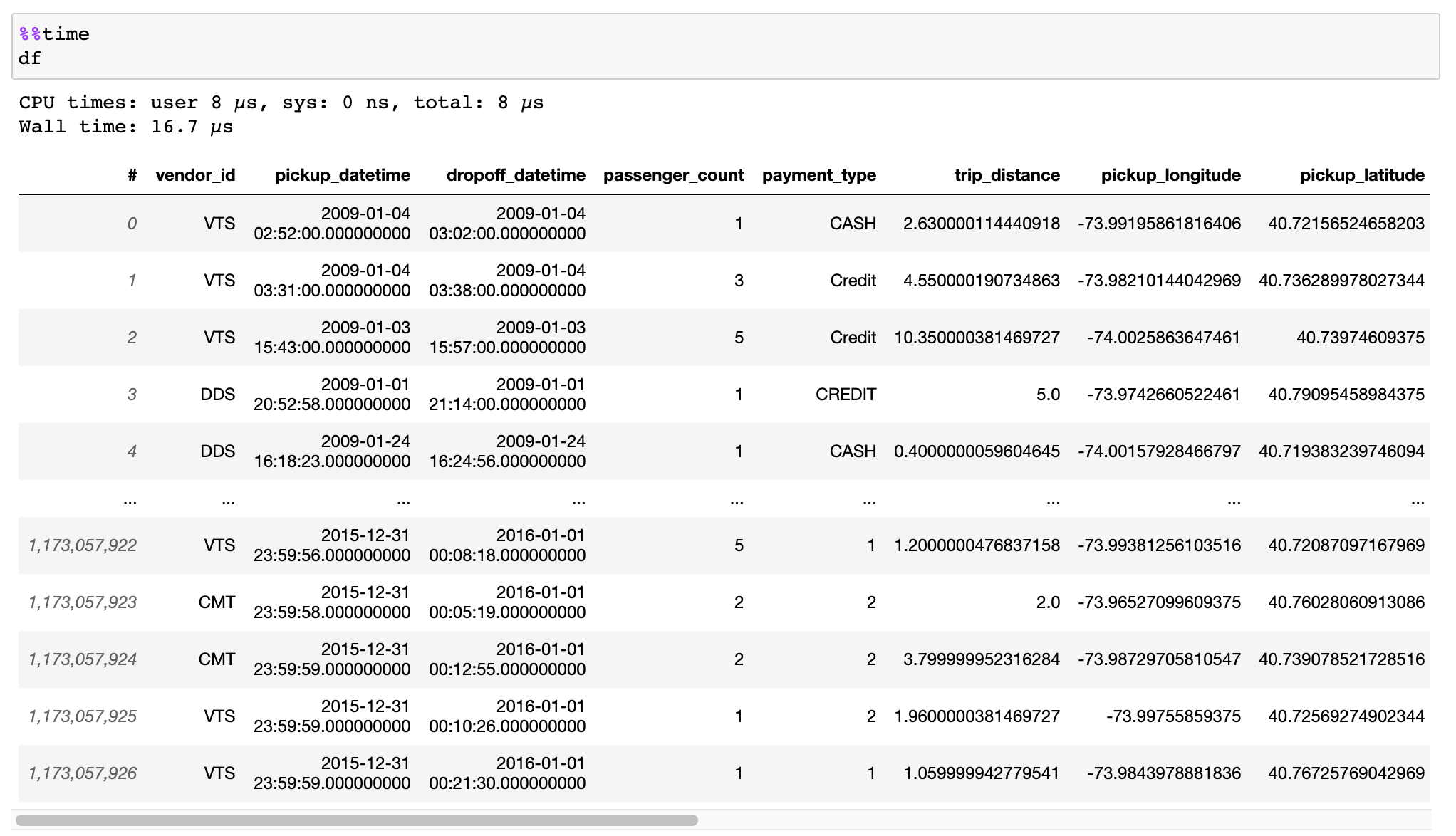
Baca dokumentasi tentang cara mengonversi data Anda secara efisien dari file CSV, Pandas DataFrames, atau sumber lainnya.
Streaming lambat dari S3 didukung dalam kombinasi dengan pemetaan memori.

Jangan buang memori atau waktu dengan rekayasa fitur, kami (dengan malas) mengubah data Anda bila diperlukan.
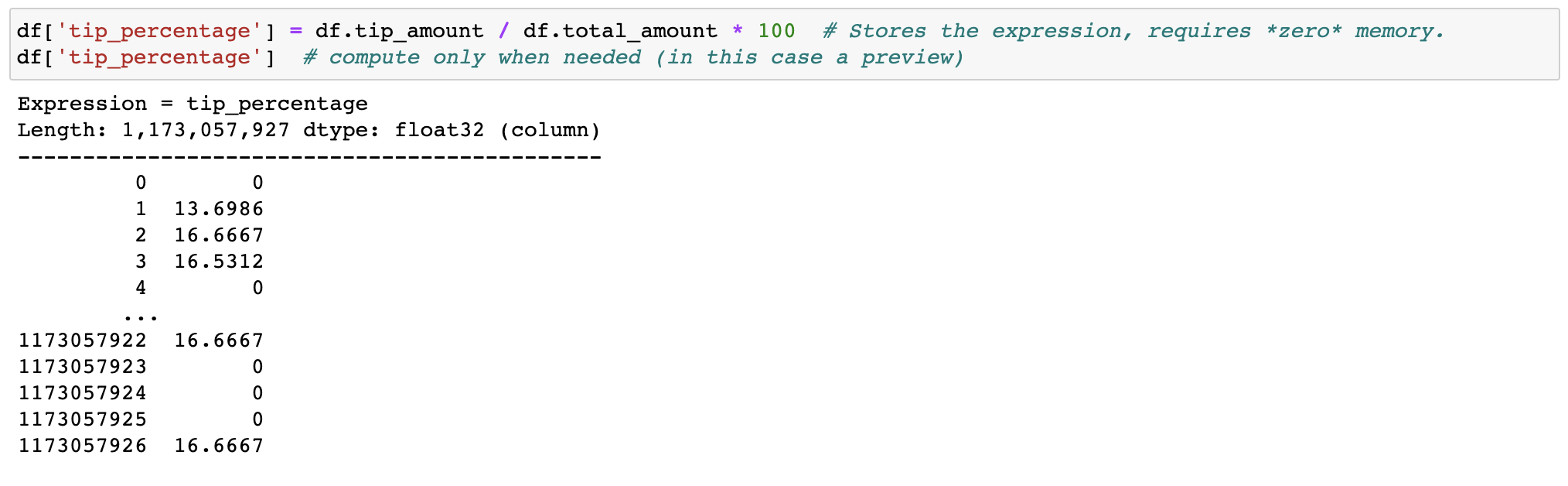
Memfilter dan mengevaluasi ekspresi tidak akan menyia-nyiakan memori dengan membuat salinan; data tetap tidak tersentuh di disk, dan hanya akan dialirkan bila diperlukan. Tunda waktu sebelum Anda membutuhkan cluster.
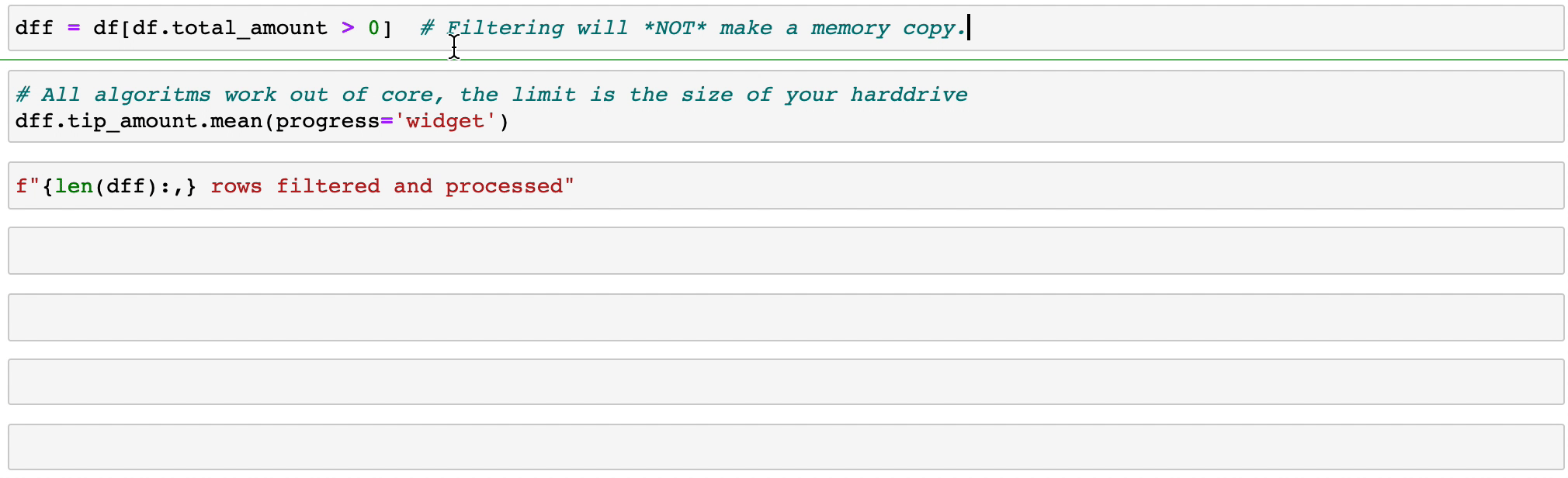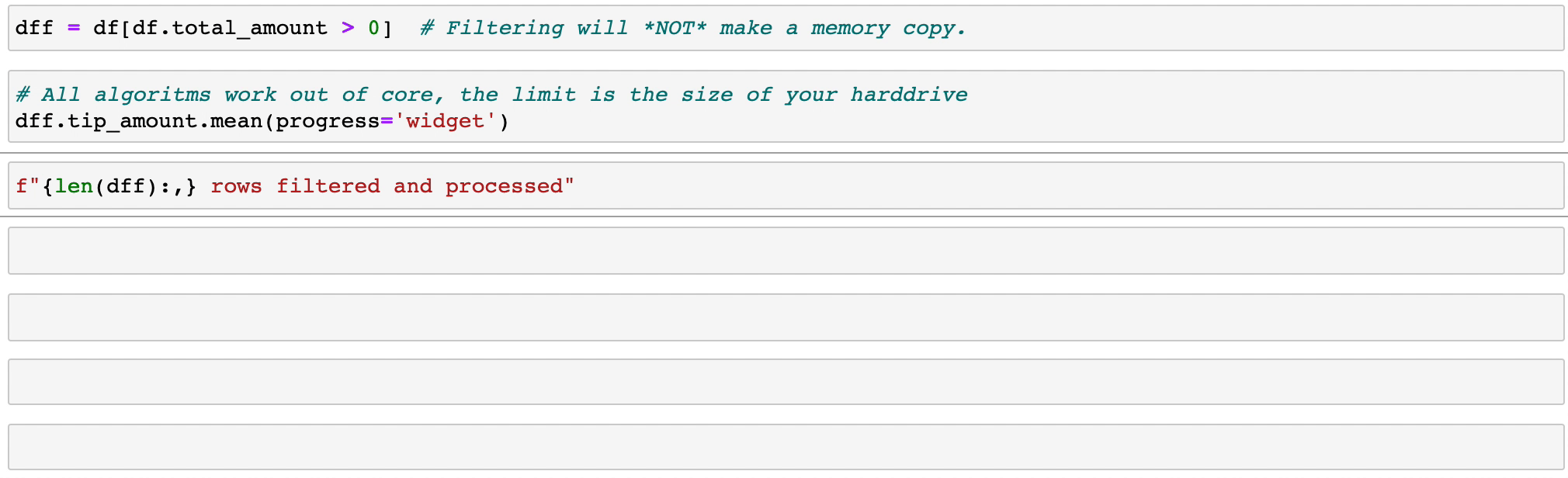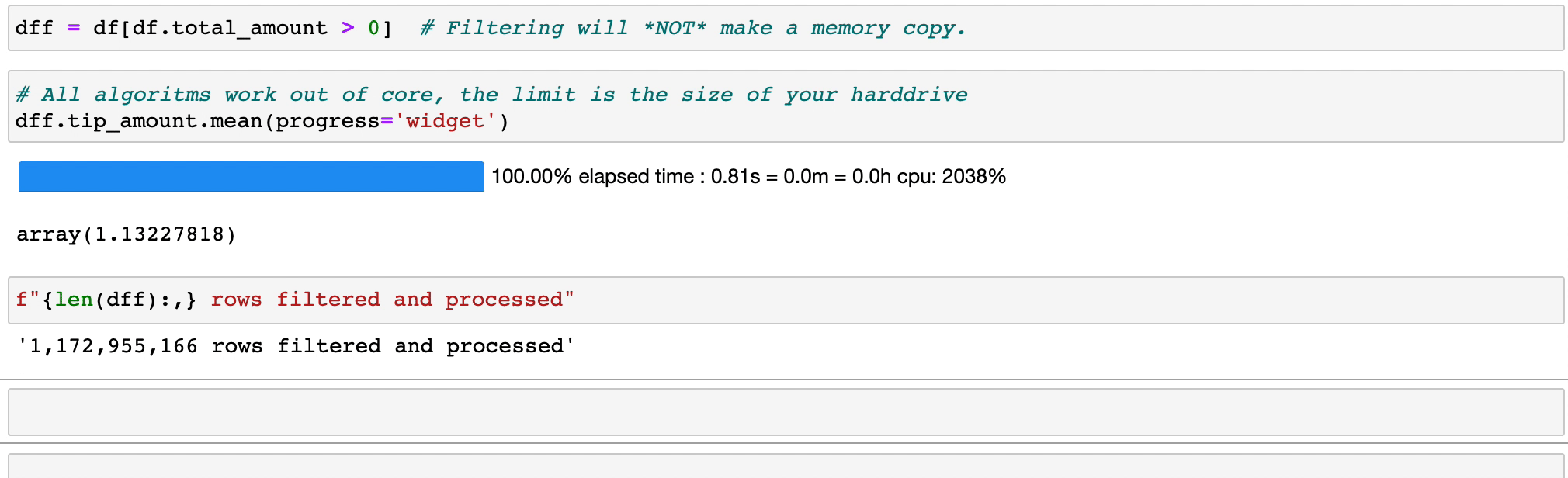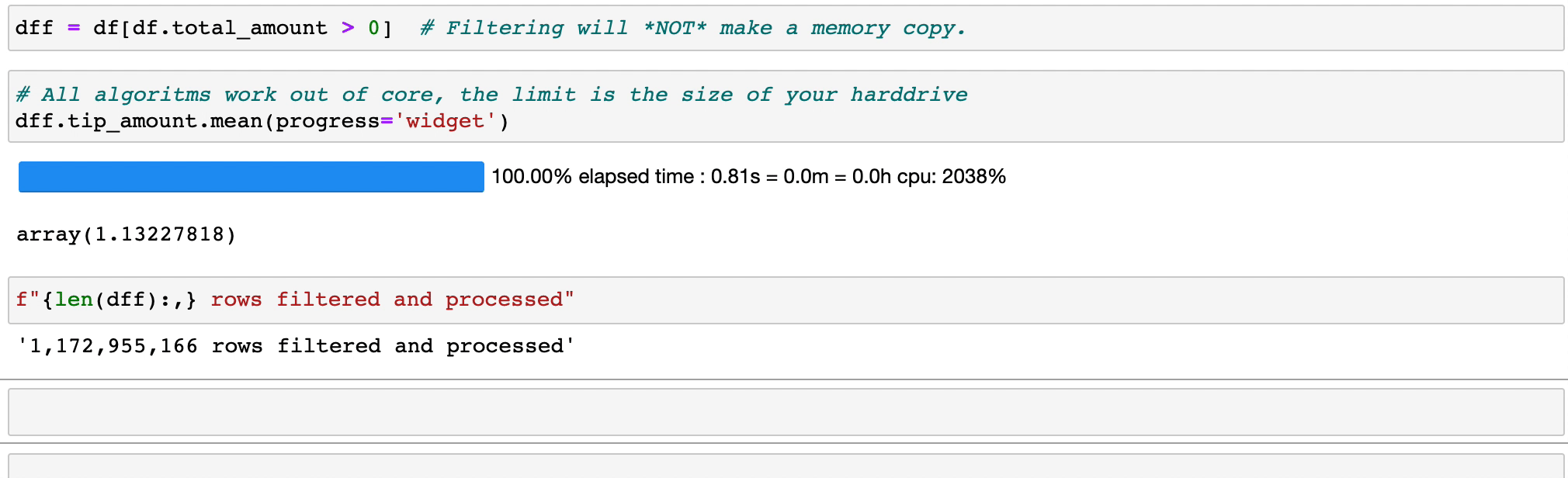
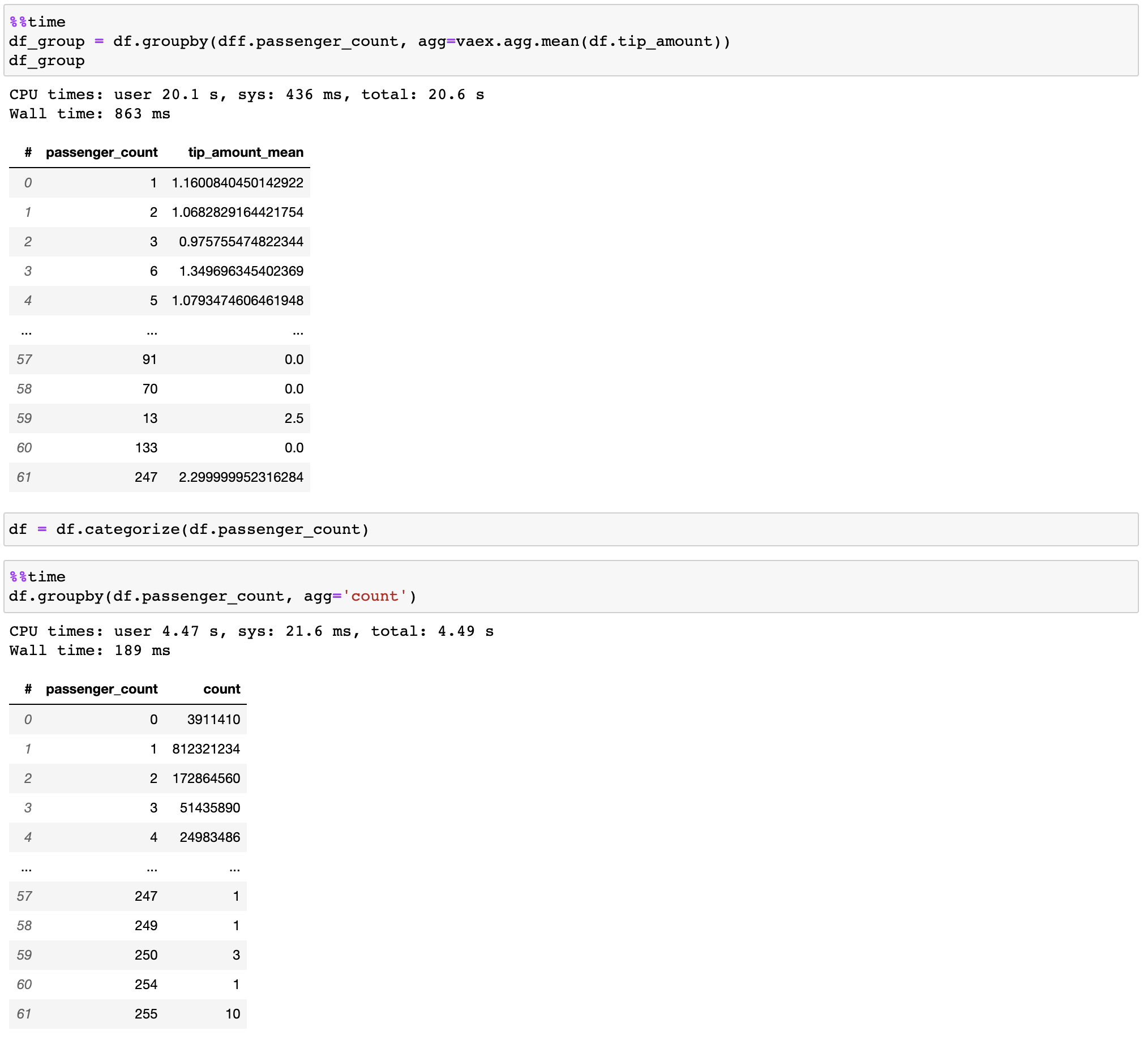
Vaex mengimplementasikan operasi groupby yang paralel dan berperforma tinggi, terutama saat menggunakan kategori (>1 miliar/detik).
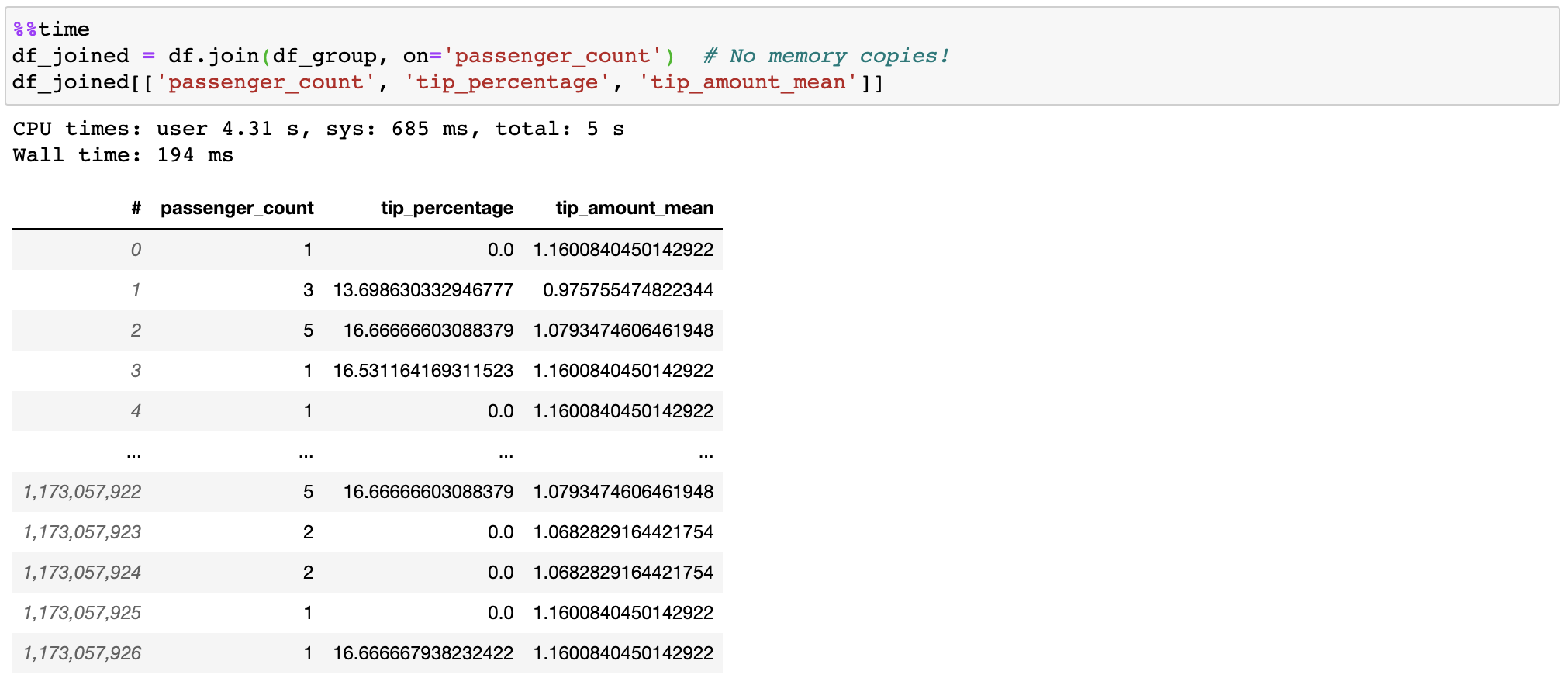
Vaex tidak menyalin/mewujudkan tabel 'kanan' saat bergabung, menghemat gigabyte memori. Dengan bergabungnya subdetik dalam satu miliar baris, ini cukup cepat!
Lihat halaman kontribusi.
Bergabunglah dalam diskusi di saluran Slack kami!
Artikel
Ikuti tutorial kami
Tonton pembicaraan terbaru kami:
Hubungi kami untuk solusi ilmu data, pelatihan, atau dukungan perusahaan di https://vaex.io/


