qwen2 in a lambda
1.0.0
Diperbarui pada 11/09/2024
(Menandai tanggal karena seberapa cepat LLM API di Python bergerak dan mungkin menyebabkan perubahan besar pada saat orang lain membaca ini!)
Ini adalah penelitian kecil tentang bagaimana kita dapat memasukkan file model Qwen GGUF ke AWS Lambda menggunakan Docker dan SAM CLI
Diadaptasi dari https://makit.net/blog/llm-in-a-lambda-function/
Saya ingin mengetahui apakah saya dapat mengurangi pengeluaran AWS saya dengan hanya memanfaatkan kemampuan Lambda dan bukan Lambda + Bedrock karena kedua layanan tersebut akan menimbulkan lebih banyak biaya dalam jangka panjang.
Idenya adalah untuk menyesuaikan model bahasa kecil yang relatif tidak membutuhkan banyak sumber daya dan, mudah-mudahan, menerima latensi subdetik hingga detik pada konfigurasi memori 128 - 256 mb
Saya juga ingin menggunakan model GGUF untuk menggunakan tingkat kuantisasi yang berbeda untuk mengetahui kinerja/ukuran file mana yang terbaik untuk dimuat ke dalam memori
qwen2-1_5b-instruct-q5_k_m.gguf ke qwen_fuction/function/app.y / LOCAL_PATH qwen_function/function/requirements.txt (sebaiknya di venv/conda env)sam build / sam validatesam local start-api untuk menguji secara lokalcurl --header "Content-Type: application/json" --request POST --data '{"prompt":"hello"}' http://localhost:3000/generate untuk meminta LLMsam deploy --guided untuk menerapkan ke AWS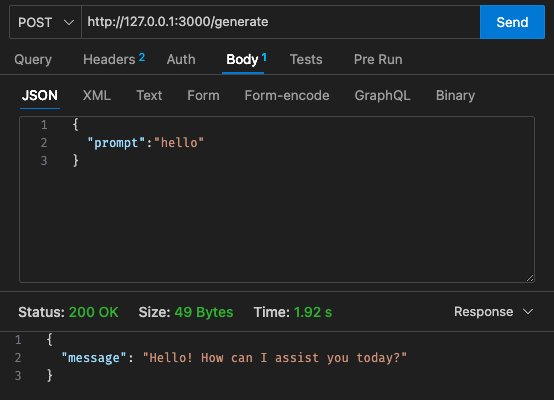
AWS
Konfigurasi awal - 128MB, batas waktu 30 detik
Konfigurasi #1 yang disesuaikan - 512MB, batas waktu 30 detik
Konfigurasi #2 yang disesuaikan - 512MB, batas waktu 30 detik
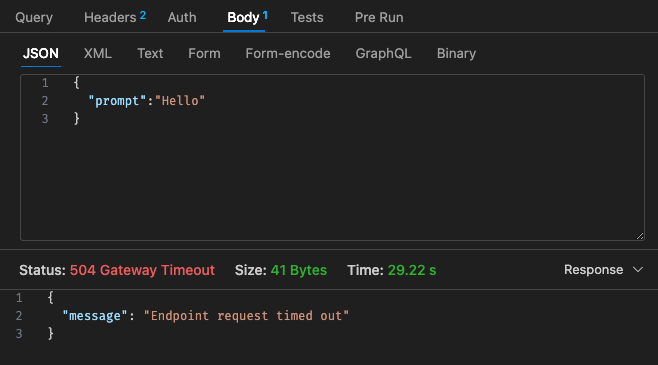
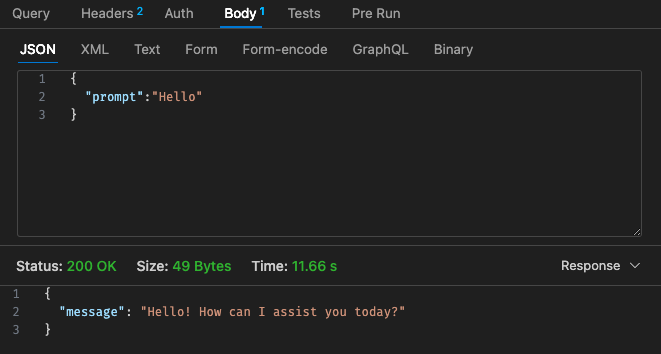
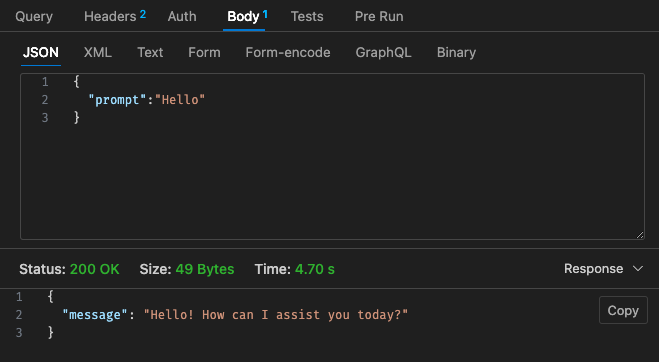
Mengacu kembali pada struktur harga Lambda,
Mungkin lebih murah jika hanya menggunakan LLM yang dihosting menggunakan AWS Bedrock, dll. di cloud karena struktur harga untuk Lambda w/ Qwen tidak terlihat lebih kompetitif dibandingkan dengan Claude 3 Haiku
Selain itu, batas waktu gateway API tidak mudah dikonfigurasi setelah batas waktu 30 detik, bergantung pada kasus penggunaan Anda, ini mungkin tidak terlalu ideal
Hasil via lokal tergantung spek mesin anda!! dan mungkin sangat menyimpangkan persepsi, ekspektasi, dan kenyataan Anda
Bergantung pada kasus penggunaan Anda juga, latensi per pemanggilan dan respons lambda mungkin menimbulkan pengalaman pengguna yang buruk
Secara keseluruhan, menurut saya ini adalah eksperimen kecil yang menyenangkan meskipun tidak sesuai dengan persyaratan anggaran & latensi melalui Qwen 1.5b untuk proyek sampingan saya. Sekali lagi terima kasih kepada @makit untuk panduannya!


