Interactive RAG
1.0.0
Agen merevolusi cara kita memanfaatkan model bahasa untuk pengambilan keputusan dan kinerja tugas. Agen adalah sistem yang menggunakan model bahasa untuk membuat keputusan dan melakukan tugas. Pendekatan ini dirancang untuk menangani skenario yang kompleks dan memberikan lebih banyak fleksibilitas dibandingkan pendekatan tradisional. Agen dapat dianggap sebagai mesin penalaran yang memanfaatkan model bahasa untuk memproses informasi, mengambil data yang relevan, menyerap (memotong/menyematkan) dan menghasilkan respons.
Di masa depan, agen akan memainkan peran penting dalam pemrosesan teks, mengotomatisasi tugas, dan meningkatkan interaksi manusia-komputer seiring kemajuan model bahasa.
Dalam contoh ini, kami secara khusus akan berfokus pada pemanfaatan agen dalam Dynamic Retrieval Augmented Generation (RAG). Dengan menggunakan ActionWeaver dan MongoDB Atlas, Anda akan memiliki kemampuan untuk mengubah strategi RAG Anda secara real-time melalui interaksi percakapan. Baik itu memilih lebih banyak bongkahan, menambah ukuran bongkahan, atau mengubah parameter lainnya, Anda dapat menyempurnakan pendekatan RAG untuk mencapai kualitas dan akurasi respons yang diinginkan. Anda bahkan dapat menambah/menghapus sumber ke database vektor Anda menggunakan bahasa alami!
# LLM Config
self.rag_config = {
"num_sources": 2,
"source_chunk_size": 1000,
"min_rel_score": 0.00,
"unique": True,
"summarize_chunks": True, # adds latency at ingest, everything comes at a cost
}
Memotong teks memang bagus, tetapi bagaimana cara menyimpannya?
Meringkas menghemat ruang dan mempercepat, namun dapat menghilangkan detail.
Menyimpan data mentah memang akurat, namun berukuran besar, lebih lambat, dan "berisik".
Kelebihan meringkas:
Kontra meringkas:
Apa yang tepat untuk Anda? Itu tergantung pada kebutuhan Anda! Mempertimbangkan:
DEMO 1
Buat lingkungan Python baru
python3 -m venv envAktifkan lingkungan Python baru
source env/bin/activateInstal persyaratannya
pip3 install -r requirements.txtTetapkan parameter di params.py:
# MongoDB
MONGODB_URI = " "
DATABASE_NAME = " genai "
COLLECTION_NAME = " rag "
# If using OpenAI
OPENAI_API_KEY = " "
# If using Azure OpenAI
OPENAI_TYPE = " azure "
OPENAI_API_VERSION = " 2023-10-01-preview "
OPENAI_AZURE_ENDPOINT = " https://.openai.azure.com/ "
OPENAI_AZURE_DEPLOYMENT = " "
Buat indeks Pencarian dengan definisi berikut
{
"mappings" : {
"dynamic" : true ,
"fields" : {
"embedding" : {
"dimensions" : 384 ,
"similarity" : " cosine " ,
"type" : " knnVector "
}
}
}
}Atur lingkungan
export OPENAI_API_KEY=Untuk menjalankan aplikasi RAG
env/bin/streamlit run rag/app.pyInformasi log yang dihasilkan oleh aplikasi akan ditambahkan ke app.log.
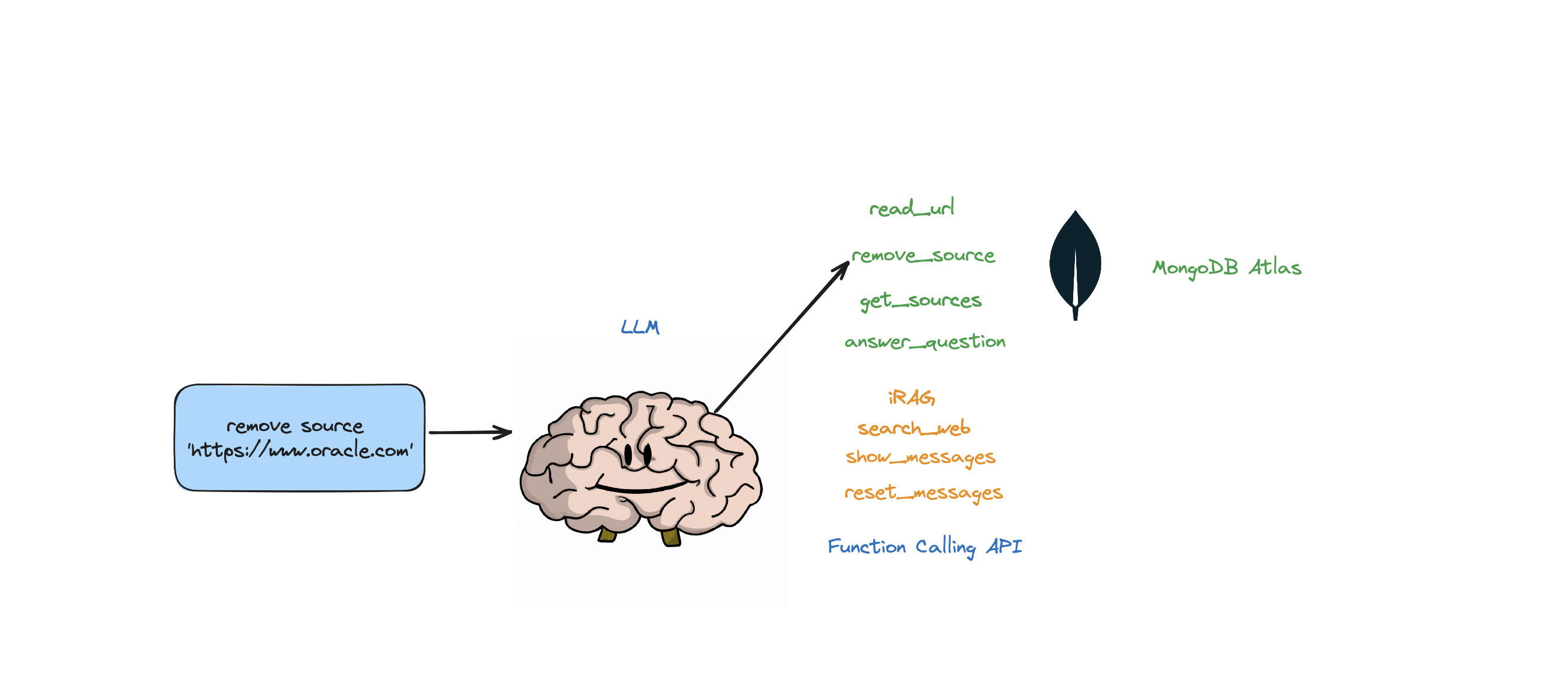
Bot ini mendukung tindakan berikut: menjawab pertanyaan, menelusuri web, membaca URL, menghapus sumber, mencantumkan semua sumber, dan menyetel ulang pesan. Ini juga mendukung tindakan yang disebut iRAG yang memungkinkan Anda mengontrol strategi RAG agen Anda secara dinamis.
Contoh: "atur konfigurasi RAG ke 3 sumber dan ukuran potongan 1250" => Konfigurasi RAG baru:{'num_sources': 3, 'source_chunk_size': 1250, 'min_rel_score': 0, 'unique': True}.
def __call__(self, text):
text = self.preprocess_query(text)
self.messages += [{"role": "user", "content":text}]
response = self.llm.create(messages=self.messages, actions = [
self.read_url,self.answer_question,self.remove_source,self.reset_messages,
self.iRAG, self.get_sources_list,self.search_web
], stream=True)
return response
Jika bot tidak dapat memberikan jawaban atas pertanyaan dari data yang disimpan di toko Atlas Vector, dan strategi RAG Anda (jumlah sumber, ukuran potongan, min_rel_score, dll), bot akan memulai pencarian web untuk menemukan informasi yang relevan. Anda kemudian dapat menginstruksikan bot untuk membaca dan belajar dari hasil tersebut.
RAG memang keren dan sebagainya, tetapi menemukan "strategi RAG" yang tepat itu rumit. Ukuran potongan, dan jumlah sumber unik akan berdampak langsung pada respon yang dihasilkan oleh LLM.
Dalam mengembangkan strategi RAG yang efektif, proses penyerapan sumber web, pemotongan, penyematan, ukuran potongan, dan jumlah sumber yang digunakan memainkan peran penting. Pemotongan memecah teks masukan untuk pemahaman yang lebih baik, penyematan menangkap maknanya, dan jumlah sumber memengaruhi keragaman respons. Menemukan keseimbangan yang tepat antara ukuran bagian dan jumlah sumber sangat penting untuk respons yang akurat dan relevan. Eksperimen dan penyesuaian diperlukan untuk menentukan pengaturan optimal.
Sebelum kita mendalami 'Pengambilan', mari kita bahas dulu tentang "Proses Penyerapan"
Mengapa harus ada proses terpisah untuk "menyerap" konten Anda ke dalam basis data vektor Anda? Dengan menggunakan keajaiban agen, kita dapat dengan mudah menambahkan konten baru ke database vektor.
Ada banyak jenis database yang dapat menyimpan embeddings ini, masing-masing memiliki kegunaan khusus. Namun untuk tugas yang melibatkan aplikasi GenAI, saya merekomendasikan MongoDB.
Bayangkan MongoDB sebagai kue yang bisa Anda miliki dan makan. Ini memberi Anda kekuatan bahasanya untuk membuat kueri, Mongo Query Language. Ini juga mencakup semua fitur hebat MongoDB. Selain itu, ini memungkinkan Anda menyimpan blok penyusun ini (penyematan vektor) dan melakukan operasi matematika pada blok tersebut, semuanya di satu tempat. Hal ini menjadikan MongoDB Atlas toko serba ada untuk semua kebutuhan penyematan vektor Anda!
@action("read_url", stop=True)
def read_url(self, urls: List[str]):
"""
Invoke this ONLY when the user asks you to 'read', 'add' or 'learn' some URL(s).
This function reads the content from specified sources, and ingests it into the Knowledgebase.
URLs may be provided as a single string or as a list of strings.
IMPORTANT! Use conversation history to make sure you are reading/learning/adding the right URLs.
Parameters
----------
urls : List[str]
List of URLs to scrape.
Returns
-------
str
A message indicating successful reading of content from the provided URLs.
"""
with self.st.spinner(f"```Analyzing the content in {urls}```"):
loader = PlaywrightURLLoader(urls=urls, remove_selectors=["header", "footer"])
documents = loader.load_and_split(self.text_splitter)
self.index.add_documents(
documents
)
return f"```Contents in URLs {urls} have been successfully ingested (vector embeddings + content).```"
{
"mappings": {
"dynamic": true,
"fields": {
"embedding": {
"dimensions": 384, #dimensions depends on the model
"similarity": "cosine",
"type": "knnVector"
}
}
}
}
def recall(self, text, n_docs=2, min_rel_score=0.25, chunk_max_length=800,unique=True):
#$vectorSearch
print("recall=>"+str(text))
response = self.collection.aggregate([
{
"$vectorSearch": {
"index": "default",
"queryVector": self.gpt4all_embd.embed_query(text), #GPT4AllEmbeddings()
"path": "embedding",
#"filter": {},
"limit": 15, #Number (of type int only) of documents to return in the results. Value can't exceed the value of numCandidates.
"numCandidates": 50 #Number of nearest neighbors to use during the search. You can't specify a number less than the number of documents to return (limit).
}
},
{
"$addFields":
{
"score": {
"$meta": "vectorSearchScore"
}
}
},
{
"$match": {
"score": {
"$gte": min_rel_score
}
}
},{"$project":{"score":1,"_id":0, "source":1, "text":1}}])
tmp_docs = []
str_response = []
for d in response:
if len(tmp_docs) == n_docs:
break
if unique and d["source"] in tmp_docs:
continue
tmp_docs.append(d["source"])
str_response.append({"URL":d["source"],"content":d["text"][:chunk_max_length],"score":d["score"]})
kb_output = f"Knowledgebase Results[{len(tmp_docs)}]:n```{str(str_response)}```n## n```SOURCES: "+str(tmp_docs)+"```nn"
self.st.write(kb_output)
return str(kb_output)
Dengan menggunakan ActionWeaver, pembungkus ringan untuk API pemanggilan fungsi, kita dapat membangun agen proksi pengguna yang secara efisien mengambil dan menyerap informasi relevan menggunakan MongoDB Atlas.
Agen proxy adalah perantara yang mengirimkan permintaan klien ke server atau sumber daya lain dan kemudian mengembalikan tanggapan.
Agen ini menyajikan data kepada pengguna secara interaktif dan dapat disesuaikan, sehingga meningkatkan pengalaman pengguna secara keseluruhan.
UserProxyAgent memiliki beberapa parameter RAG yang dapat dikustomisasi, seperti chunk_size (misalnya 1000), num_sources (misalnya 2), unique (misalnya True) dan min_rel_score (misalnya 0,00).
class UserProxyAgent:
def __init__(self, logger, st):
self.rag_config = {
"num_sources": 2,
"source_chunk_size": 1000,
"min_rel_score": 0.00,
"unique": True,
}
Berikut beberapa manfaat utama yang memengaruhi keputusan kami memilih ActionWeaver:
Agen pada dasarnya hanyalah sebuah program atau sistem komputer yang dirancang untuk memahami lingkungannya, membuat keputusan, dan mencapai tujuan tertentu.
Bayangkan agen sebagai entitas perangkat lunak yang menunjukkan tingkat otonomi tertentu dan melakukan tindakan di lingkungannya atas nama pengguna atau pemiliknya, namun dengan cara yang relatif independen. Dibutuhkan inisiatif untuk melakukan tindakan sendiri dengan mempertimbangkan pilihan-pilihan untuk mencapai tujuannya. Ide inti agen adalah menggunakan model bahasa untuk memilih rangkaian tindakan yang akan diambil. Berbeda dengan rantai, di mana serangkaian tindakan dikodekan dalam kode, agen menggunakan model bahasa sebagai mesin penalaran untuk menentukan tindakan mana yang harus diambil dan dalam urutan apa.
Tindakan adalah fungsi yang dapat dijalankan oleh agen. Ada dua pertimbangan desain penting seputar tindakan:
Giving the agent access to the right actions
Describing the actions in a way that is most helpful to the agent
Tanpa memikirkan keduanya, Anda tidak akan bisa membangun agen yang berfungsi. Jika Anda tidak memberi agen akses ke serangkaian tindakan yang benar, agen tidak akan pernah bisa mencapai tujuan yang Anda berikan. Jika Anda tidak menjelaskan tindakannya dengan baik, agen tidak akan tahu cara menggunakannya dengan benar.
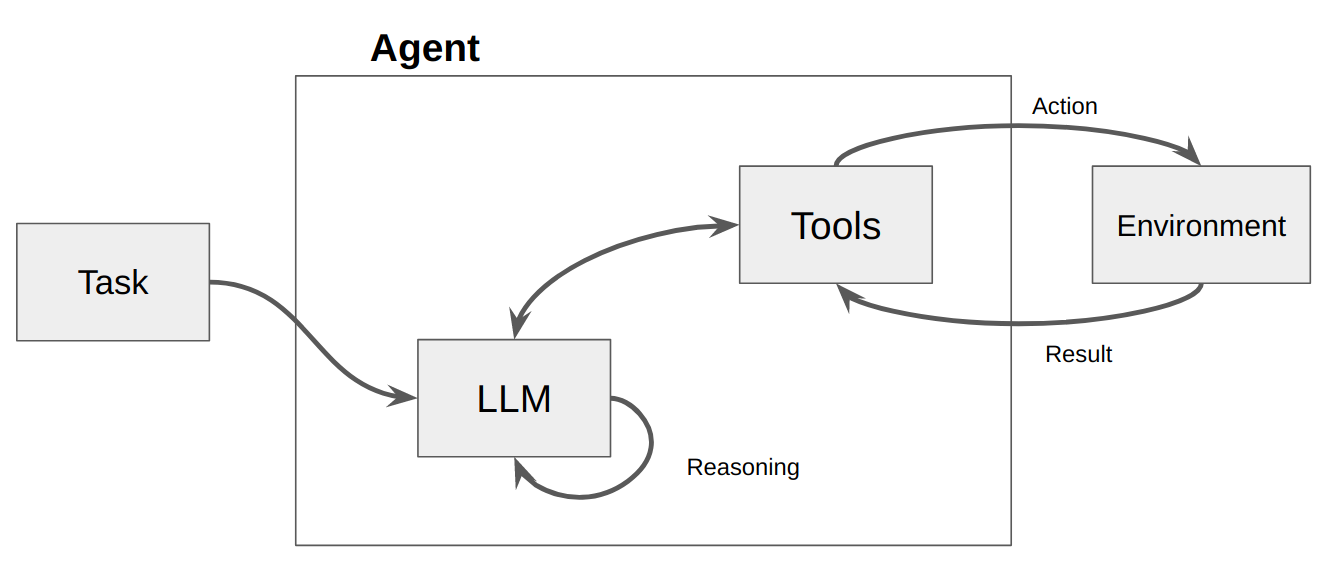
LLM kemudian dipanggil, menghasilkan respons terhadap pengguna ATAU tindakan yang harus diambil. Jika ditentukan bahwa respons diperlukan, maka respons tersebut diteruskan ke pengguna, dan siklus tersebut selesai. Apabila ditentukan bahwa suatu tindakan perlu dilakukan, maka dilakukan tindakan itu, dan dilakukan pengamatan (hasil tindakan). Tindakan & observasi terkait tersebut ditambahkan kembali ke prompt (kami menyebutnya "agen scratchpad"), dan loop direset, yaitu. LLM dipanggil lagi (dengan scratchpad agen yang diperbarui).
Di ActionWeaver, kita dapat mempengaruhi loop dengan menambahkan stop=True|False ke suatu tindakan. Jika stop=True , LLM akan segera mengembalikan output fungsi. Ini juga akan membatasi LLM melakukan beberapa panggilan fungsi. Dalam demo ini kita hanya akan menggunakan stop=True
ActionWeaver juga mendukung kontrol loop yang lebih kompleks menggunakan orch_expr(SelectOne[actions]) dan orch_expr(RequireNext[actions]) , tapi saya akan membiarkannya untuk BAGIAN II.
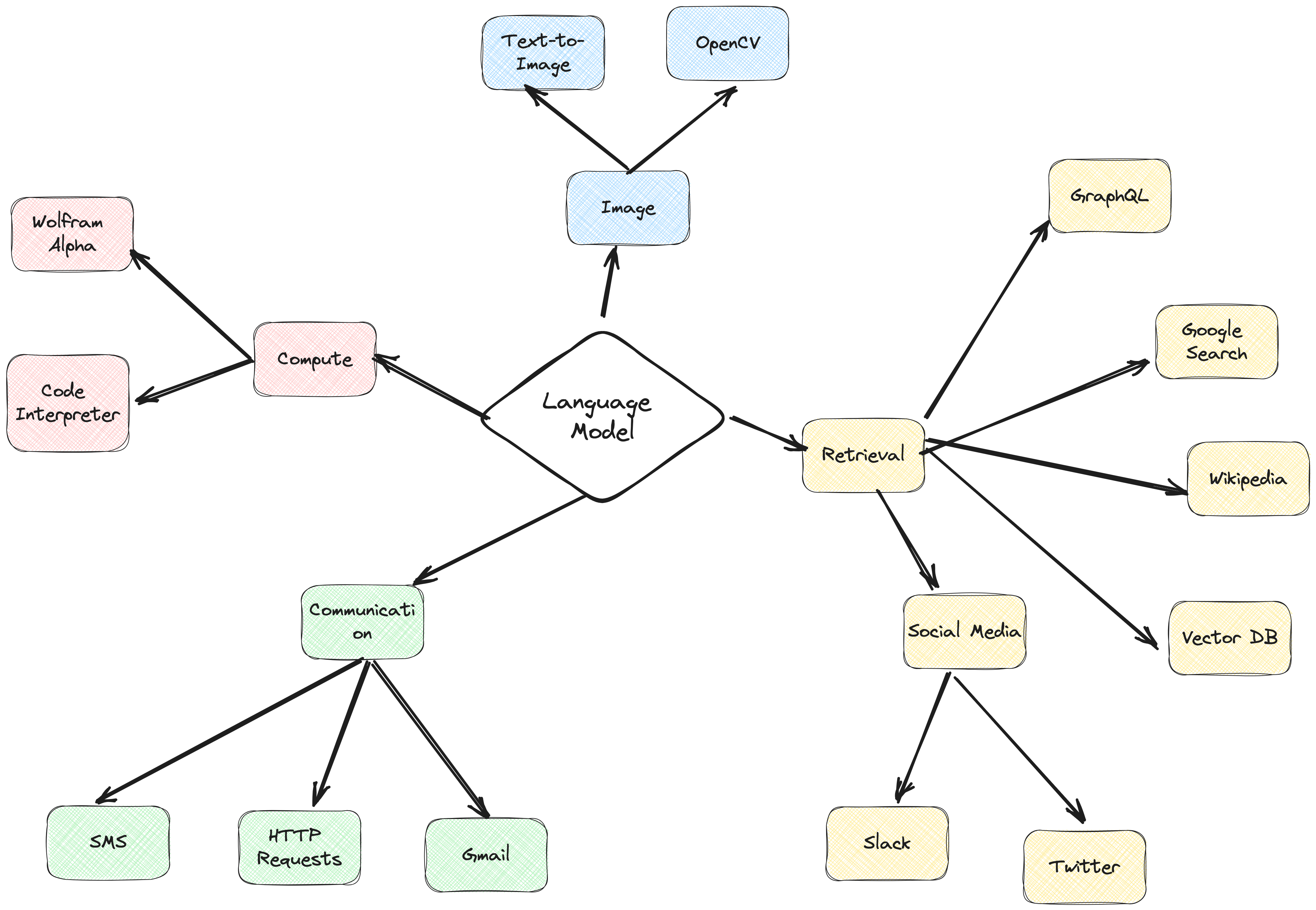
Kerangka kerja agen ActionWeaver adalah kerangka aplikasi AI yang menjadikan pemanggilan fungsi sebagai intinya. Hal ini dirancang untuk memungkinkan penggabungan sistem komputasi tradisional dengan kemampuan penalaran yang kuat dari Model Model Bahasa. ActionWeaver dibangun berdasarkan konsep pemanggilan fungsi LLM, sedangkan kerangka kerja populer seperti Langchain dan Haystack dibangun berdasarkan konsep pipeline.

Baca lebih lanjut di: https://thinhdanggroup.github.io/function-calling-openai/
Pengembang dapat melampirkan fungsi Python APAPUN sebagai alat dengan dekorator sederhana. Dalam contoh berikut, kami memperkenalkan tindakan get_sources_list, yang akan dipanggil oleh OpenAI API.
ActionWeaver menggunakan tanda tangan dan docstring metode yang dihias sebagai deskripsi, meneruskannya ke API fungsi OpenAI.
ActionWeaver menyediakan pembungkus ringan yang menangani konversi informasi docstring/dekorator ke dalam format yang benar untuk OpenAI API.
@action(name="get_sources_list", stop=True)
def get_sources_list(self):
"""
Invoke this to respond to list all the available sources in your knowledge base.
Parameters
----------
None
"""
sources = self.collection.distinct("source")
if sources:
result = f"Available Sources [{len(sources)}]:n"
result += "n".join(sources[:5000])
return result
else:
return "N/A"
stop=True ketika ditambahkan ke suatu tindakan berarti LLM akan segera mengembalikan output fungsi, namun ini juga membatasi LLM membuat beberapa pemanggilan fungsi. Misalnya, jika ditanya tentang cuaca di NYC dan San Francisco, model tersebut akan menjalankan dua fungsi terpisah secara berurutan untuk setiap kota. Namun, dengan stop=True , proses ini terhenti setelah fungsi pertama mengembalikan informasi cuaca untuk NYC atau San Francisco, bergantung pada kota mana yang pertama kali ditanyakan.
Untuk pemahaman yang lebih mendalam tentang cara kerja bot ini, silakan merujuk ke file bot.py. Selain itu, Anda dapat menjelajahi repositori ActionWeaver untuk rincian lebih lanjut.
Menghasilkan jejak penalaran memungkinkan model untuk mendorong, melacak, dan memperbarui rencana tindakan, dan bahkan menangani pengecualian. Contoh ini menggunakan ReAct yang dikombinasikan dengan chain-of-thinking (CoT).
Rantai Pemikiran
Penalaran + Tindakan
[EXAMPLES]
- User Input: What is MongoDB?
- Thought: I have to think step by step. I should not answer directly, let me check my available actions before responding.
- Observation: I have an action available "answer_question".
- Action: "answer_question"('What is MongoDB?')
- User Input: Reset chat history
- Thought: I have to think step by step. I should not answer directly, let me check my available actions before responding.
- Observation: I have an action available "reset_messages".
- Action: "reset_messages"()
- User Input: remove source https://www.google.com, https://www.example.com
- Thought: I have to think step by step. I should not answer directly, let me check my available actions before responding.
- Observation: I have an action available "remove_source".
- Action: "remove_source"(['https://www.google.com', 'https://www.example.com'])
- User Input: read https://www.google.com, https://www.example.com
- Thought: I have to think step by step. I should not answer directly, let me check my available actions before responding.
- Observation: I have an action available "read_url".
- Action: "read_url"(['https://www.google.com','https://www.example.com'])
[END EXAMPLES]
Teknik pemicuan Chain of Thought (CoT) dan ReAct ikut berperan dalam contoh ini. Begini caranya:
Anjuran Rantai Pemikiran (CoT):
Perintah Bereaksi:
Singkatnya, CoT dan ReAct memainkan peran penting dalam contoh-contoh ini. CoT memungkinkan model untuk berpikir selangkah demi selangkah dan memilih tindakan yang tepat, sementara ReAct memperluas fungsionalitas ini dengan memungkinkan model berinteraksi dengan lingkungannya dan memperbarui rencananya sesuai dengan itu. Kombinasi penalaran dan tindakan ini menjadikan model bahasa besar lebih fleksibel dan serbaguna, memungkinkan model tersebut menangani tugas dan situasi yang lebih luas.
Mari kita mulai dengan mengajukan pertanyaan kepada agen kami. Dalam hal ini, “Apa itu mangga?” . Hal pertama yang akan terjadi adalah, ia akan mencoba "mengingat" informasi relevan apa pun menggunakan kesamaan penyematan vektor. Ia kemudian akan merumuskan respons dengan konten yang "diingatnya", atau akan melakukan pencarian web. Karena basis pengetahuan kami saat ini kosong, kami perlu menambahkan beberapa sumber sebelum dapat merumuskan respons.
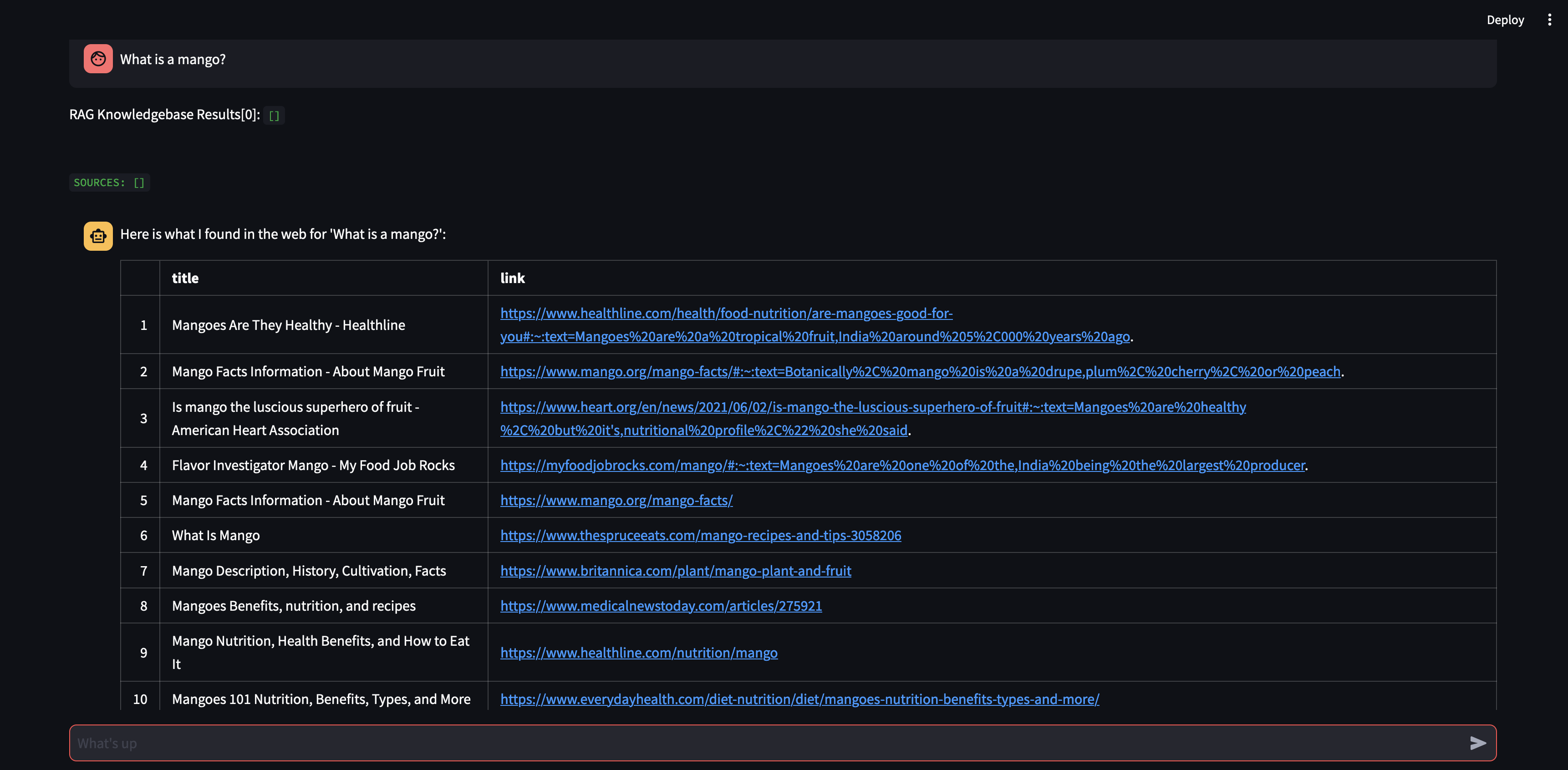
Karena bot tidak dapat memberikan jawaban menggunakan konten dalam database vektor, bot memulai pencarian Google untuk menemukan informasi yang relevan. Kini kami dapat menentukan sumber mana yang harus "dipelajari". Dalam hal ini, kami akan memerintahkannya untuk mempelajari dua sumber pertama dari hasil pencarian.
Selanjutnya, mari kita ubah strategi RAG! Mari kita buat hanya menggunakan satu sumber, dan gunakan potongan kecil berukuran 500 karakter.
Perhatikan bahwa meskipun dapat mengambil potongan, dengan skor relevansi yang cukup tinggi, namun tidak dapat menghasilkan respons karena ukuran potongan terlalu kecil dan konten potongan tidak cukup relevan untuk merumuskan respons. Karena tidak dapat menghasilkan respons dengan potongan kecil tersebut, ia melakukan penelusuran web atas nama pengguna.
Mari kita lihat apa yang terjadi jika kita menambah ukuran potongan menjadi 3000 karakter, bukan 500.
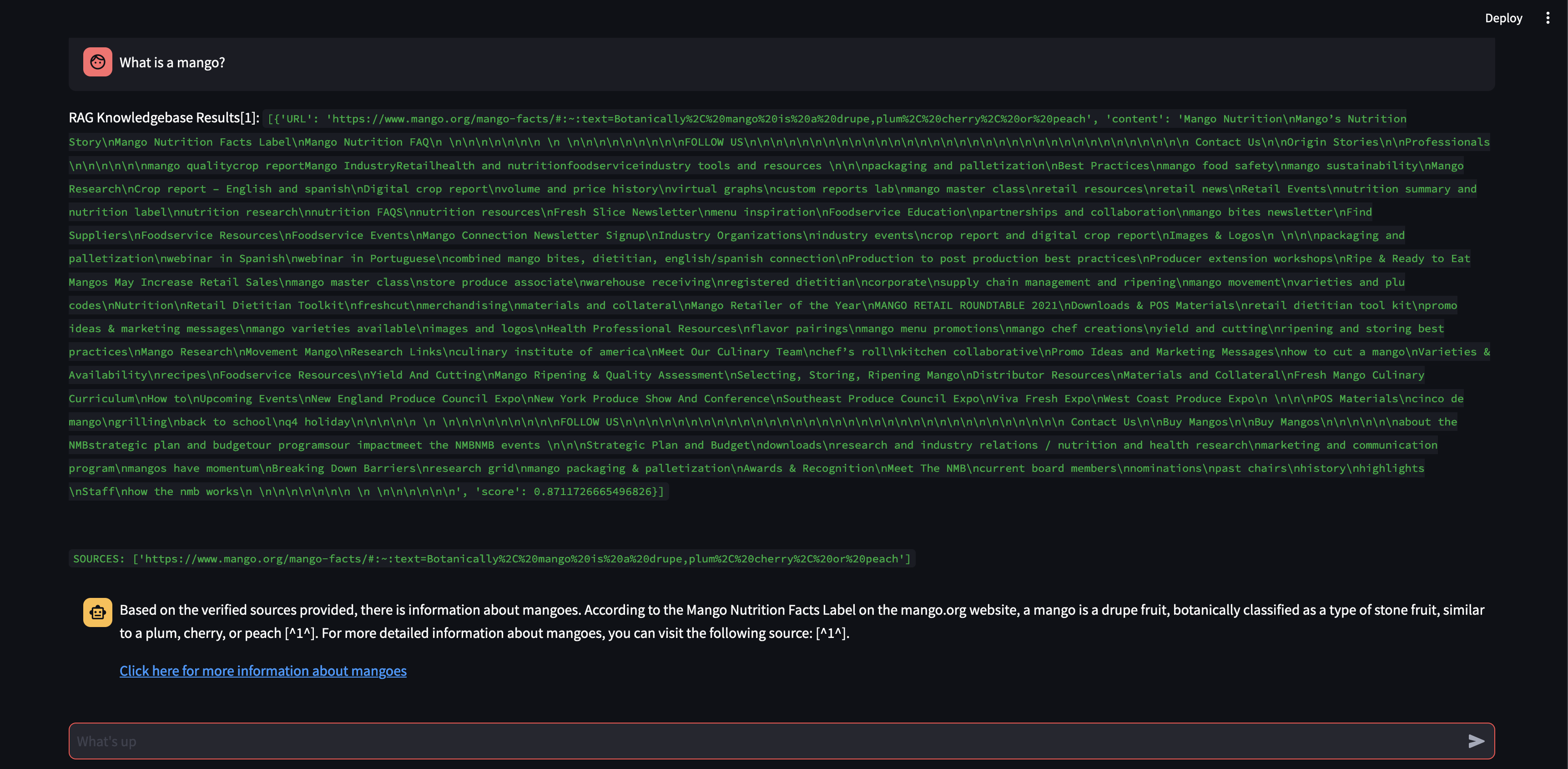
Sekarang, dengan ukuran potongan yang lebih besar, ia dapat merumuskan respons secara akurat menggunakan pengetahuan dari database vektor!
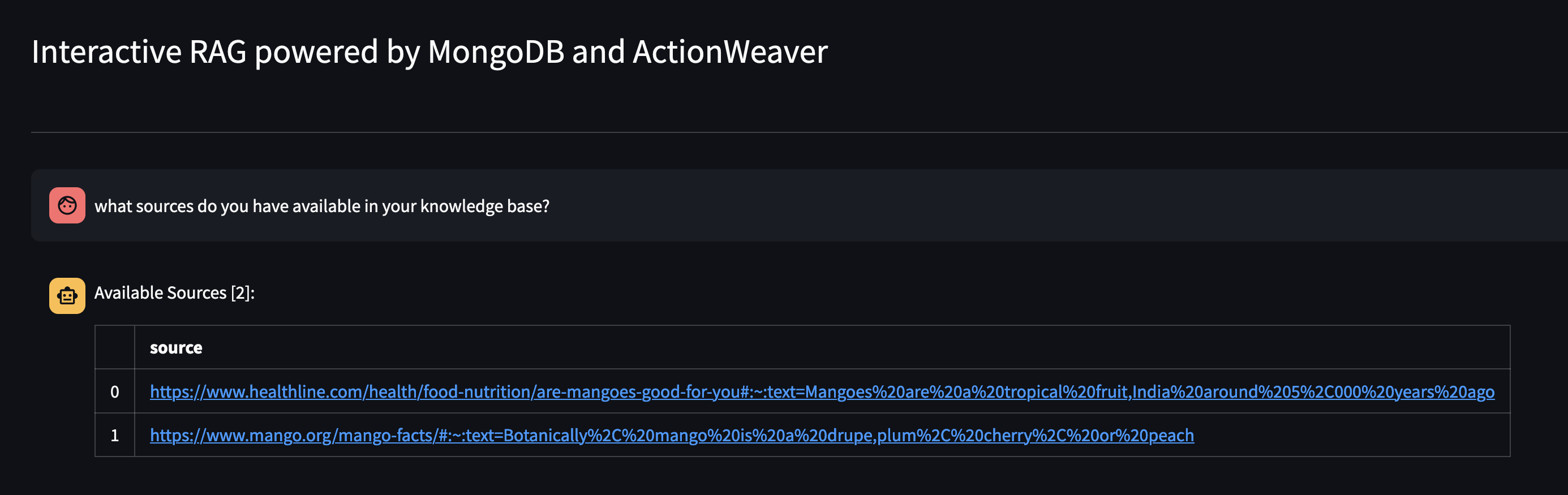
Mari kita lihat apa yang tersedia di basis pengetahuan Agen dengan menanyakannya: Sumber apa yang Anda miliki di basis pengetahuan Anda?
Jika Anda ingin menghapus sumber daya tertentu, Anda dapat melakukan sesuatu seperti:
USER: remove source 'https://www.oracle.com' from the knowledge base
Untuk menghapus semua sumber dalam koleksi - Kita dapat melakukan sesuatu seperti:
USER: what sources do you have in your knowledge base?
AGENT: {response}
USER: remove all those sources please
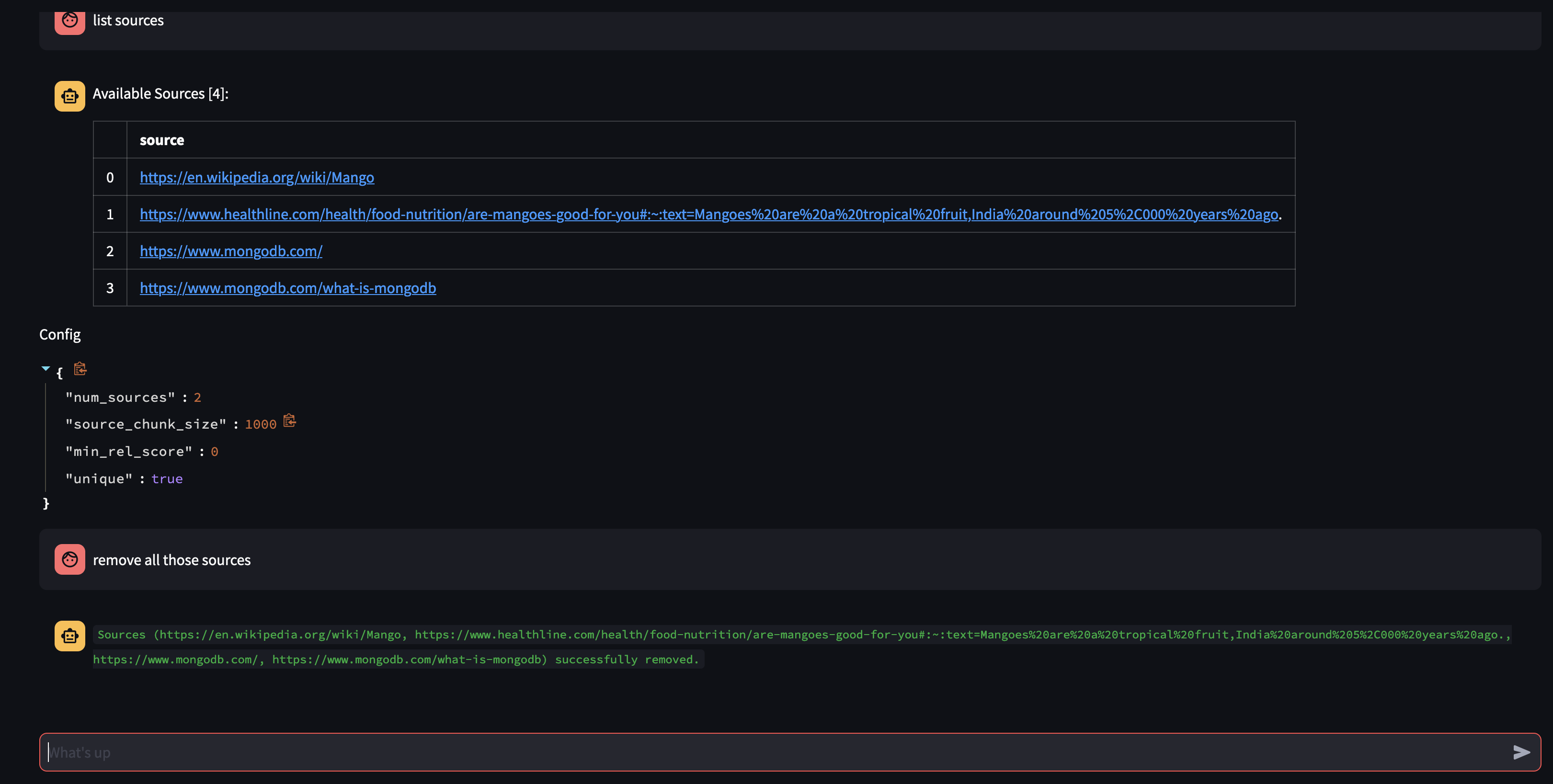
Demo ini memberikan gambaran sekilas tentang cara kerja agen AI kami, menunjukkan kemampuannya untuk mempelajari dan merespons pertanyaan pengguna secara interaktif. Kami telah menyaksikan bagaimana perusahaan ini menggabungkan basis pengetahuan internalnya dengan pencarian web real-time secara mulus untuk memberikan informasi yang komprehensif dan akurat. Potensi teknologi ini sangat besar, lebih dari sekadar menjawab pertanyaan sederhana. Semua ini tidak akan mungkin terjadi tanpa keajaiban API Pemanggilan Fungsi .
Ini terinspirasi oleh https://github.com/TengHu/Interactive-RAG
Kami menyambut kontribusi dari komunitas sumber terbuka.
Lisensi Apache 2.0


