cassandra lucene index
2.1.20.0
Indeks Cassandra Lucene Stratio, berasal dari Stratio Cassandra, adalah plugin untuk Apache Cassandra yang memperluas fungsionalitas indeksnya untuk menyediakan pencarian hampir real-time seperti ElasticSearch atau Solr, termasuk kemampuan pencarian teks lengkap dan pencarian multivariabel, geospasial, dan bitemporal gratis. Hal ini dicapai melalui implementasi indeks sekunder Cassandra berbasis Apache Lucene, di mana setiap node cluster mengindeks datanya sendiri. Indeks Cassandra Stratio adalah salah satu modul inti yang menjadi dasar platform BigData Stratio.
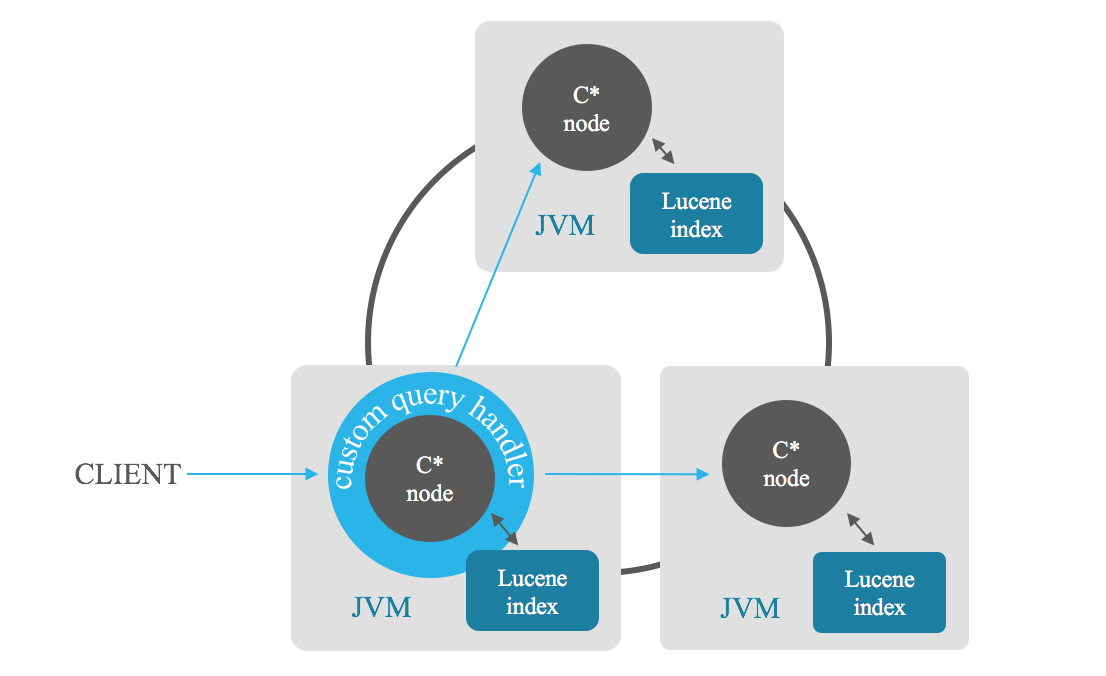
Pencarian relevansi indeks memungkinkan Anda mengambil n hasil yang lebih relevan dan memuaskan pencarian. Node koordinator mengirimkan pencarian ke setiap node dalam cluster, setiap node mengembalikan n hasil terbaiknya dan kemudian koordinator menggabungkan hasil parsial ini dan memberi Anda n hasil terbaik, menghindari pemindaian penuh. Anda juga dapat mendasarkan pengurutan pada kombinasi bidang.
Sel mana pun dalam tabel dapat diindeks, termasuk sel yang ada di kunci utama serta koleksi. Baris lebar juga didukung. Anda dapat memindai rentang token/kunci, menerapkan klausa CQL3 tambahan dan halaman pada hasil yang difilter.
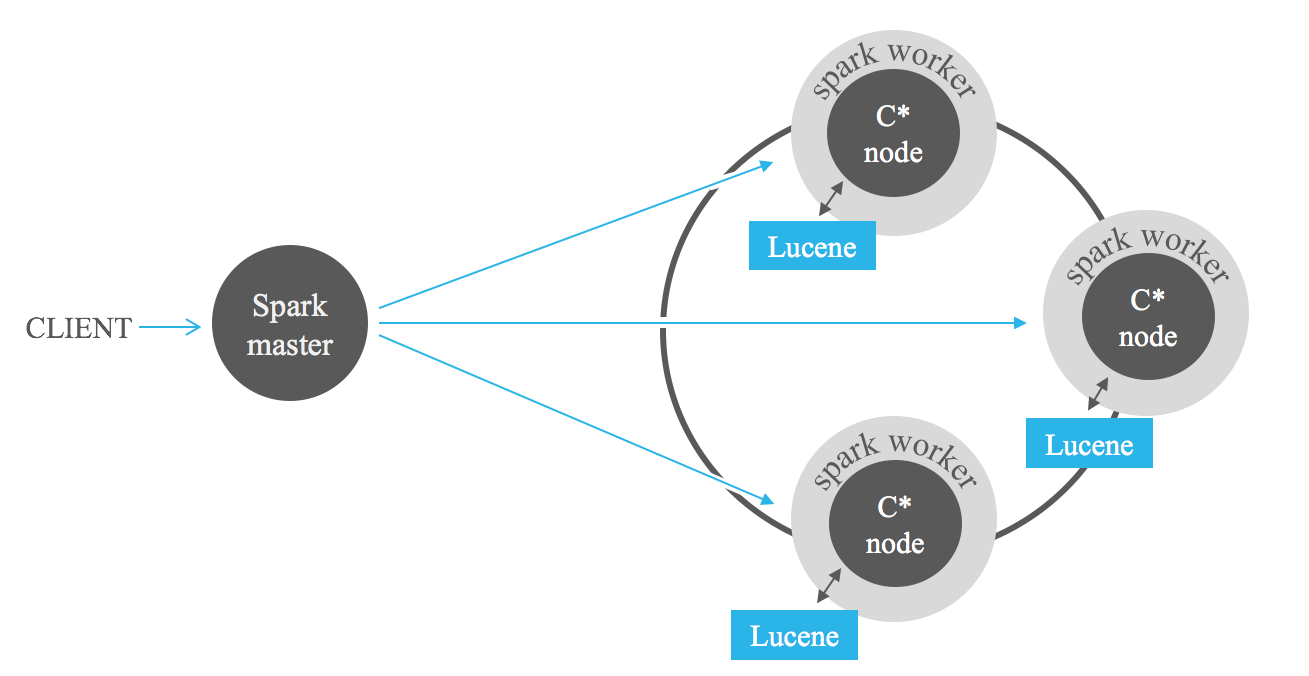
Pencarian dengan filter indeks sangat membantu saat menganalisis data yang disimpan di Cassandra dengan kerangka kerja MapReduce seperti Apache Hadoop atau, lebih baik lagi, Apache Spark. Menambahkan filter Lucene dalam input pekerjaan dapat secara drastis mengurangi jumlah data yang akan diproses, sehingga menghindari pemindaian penuh.
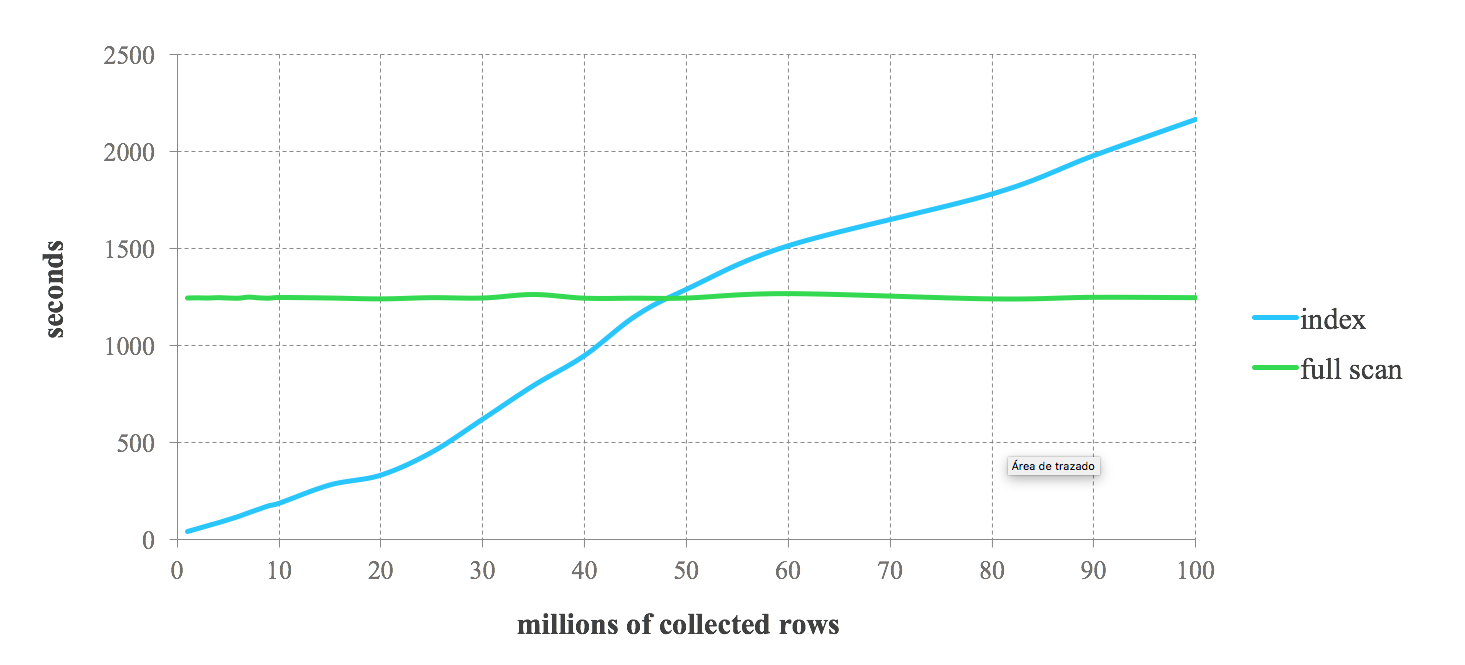
Hasil benchmark berikut dapat memberi Anda gambaran tentang performa yang diharapkan saat menggabungkan indeks Lucene dengan Spark. Kami melakukan kueri berturut-turut yang meminta dari 1% hingga 100% dari data yang disimpan. Kita dapat melihat kinerja tinggi untuk indeks untuk kueri yang meminta data yang difilter dengan kuat. Namun, kinerjanya menurun dalam kueri yang tidak terlalu ketat. Seiring bertambahnya jumlah rekaman yang dikembalikan oleh kueri, kami mencapai titik di mana indeks menjadi lebih lambat dibandingkan pemindaian penuh. Jadi, keputusan untuk menggunakan indeks dalam pekerjaan Spark Anda bergantung pada selektivitas kueri. Pertukaran antara kedua pendekatan bergantung pada kasus penggunaan tertentu. Secara umum, menggabungkan indeks Lucene dengan Spark direkomendasikan untuk pekerjaan yang mengambil tidak lebih dari 25% data yang disimpan.
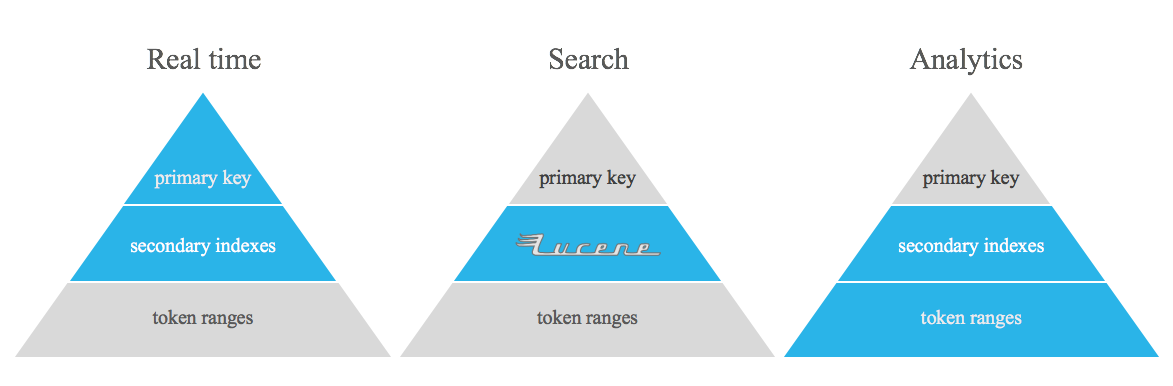
Proyek ini tidak dimaksudkan untuk menggantikan tabel denormalisasi Apache Cassandra, indeks terbalik, dan/atau indeks sekunder. Ini hanyalah alat untuk melakukan beberapa jenis pertanyaan yang sangat sulit ditangani menggunakan fitur bawaan Apache Cassandra, mengisi kesenjangan antara real-time dan analitik.
Informasi lebih rinci tersedia di dokumentasi Indeks Cassandra Lucene Stratio.
Integrasi teknologi pencarian Lucene ke Cassandra menyediakan:
Indeks Cassandra Lucene Stratio dan integrasinya dengan teknologi pencarian Lucene menyediakan:
Belum didukung:
counterIndeks Cassandra Lucene Stratio didistribusikan sebagai plugin untuk Apache Cassandra. Jadi, Anda hanya perlu membuat JAR yang berisi plugin dan menambahkannya ke classpath Cassandra:
git clone http://github.com/Stratio/cassandra-lucene-indexcd cassandra-lucene-indexgit checkout ABCXmvn clean packagecp plugin/target/cassandra-lucene-index-plugin-*.jar <CASSANDRA_HOME>/lib/Versi indeks Cassandra Lucene tertentu ditargetkan ke versi Apache Cassandra tertentu. Jadi, cassandra-lucene-index ABCX ditujukan untuk digunakan dengan Apache Cassandra ABC, misalnya cassandra-lucene-index:3.0.7.1 untuk cassandra:3.0.7. Harap dicatat bahwa rilis siap produksi adalah tag versi (misalnya 3.0.6.3), jangan gunakan cabang-X atau cabang master dalam produksi.
Alternatifnya, patching juga dapat dilakukan dengan profil Maven ini, dengan menentukan jalur instalasi Cassandra Anda, tugas ini juga menghapus versi JAR plugin sebelumnya di direktori CASSANDRA_HOME/lib/:
mvn clean package -Ppatch -Dcassandra_home= < CASSANDRA_HOME >Jika Anda belum menginstal versi Cassandra, ada juga profil alternatif yang memungkinkan Maven mengunduh dan menambal versi Apache Cassandra yang tepat:
mvn clean package -Pdownload_and_patch -Dcassandra_home= < CASSANDRA_HOME >Sekarang Anda dapat menjalankan Cassandra dan melakukan beberapa tes menggunakan Cassandra Query Language:
< CASSANDRA_HOME > /bin/cassandra -f
< CASSANDRA_HOME > /bin/cqlsh File indeks Lucene akan disimpan di direktori yang sama dengan tempat file Cassandra berada. Direktori data default adalah /var/lib/cassandra/data , dan setiap indeks ditempatkan di sebelah SSTables dari kelompok kolom yang diindeks.
Ingatlah bahwa jika Anda menggunakan pencarian bentuk geografis, Anda harus menyertakan toples JTS.
Untuk detail lebih lanjut tentang Apache Cassandra silakan lihat dokumentasinya.
Kami akan membuat tabel berikut untuk menyimpan tweet:
CREATE KEYSPACE demo
WITH REPLICATION = { ' class ' : ' SimpleStrategy ' , ' replication_factor ' : 1 };
USE demo;
CREATE TABLE tweets (
id INT PRIMARY KEY ,
user TEXT ,
body TEXT ,
time TIMESTAMP ,
latitude FLOAT,
longitude FLOAT
);Sekarang Anda dapat membuat indeks Lucene khusus dengan pernyataan berikut:
CREATE CUSTOM INDEX tweets_index ON tweets ()
USING ' com.stratio.cassandra.lucene.Index '
WITH OPTIONS = {
' refresh_seconds ' : ' 1 ' ,
' schema ' : ' {
fields: {
id: {type: "integer"},
user: {type: "string"},
body: {type: "text", analyzer: "english"},
time: {type: "date", pattern: "yyyy/MM/dd"},
place: {type: "geo_point", latitude: "latitude", longitude: "longitude"}
}
} '
}; Ini akan mengindeks semua kolom dalam tabel dengan tipe yang ditentukan, dan akan di-refresh sekali per detik. Alternatifnya, Anda dapat secara eksplisit menyegarkan semua pecahan indeks dengan pencarian kosong dengan konsistensi ALL :
CONSISTENCY ALL
SELECT * FROM tweets WHERE expr(tweets_index, ' {refresh:true} ' );
CONSISTENCY QUORUMSekarang, untuk mencari tweet dalam rentang tanggal tertentu:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: {type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"}
} ' );Pencarian yang sama dapat dilakukan dengan memaksa penyegaran eksplisit pada pecahan indeks yang terlibat:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: {type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
refresh: true
} ' ) limit 100 ;Sekarang, untuk mencari 100 tweet teratas yang lebih relevan dengan kolom isi berisi frasa “big data memberikan organisasi” dalam rentang tanggal yang disebutkan di atas:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: {type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1}
} ' ) LIMIT 100 ;Untuk menyaring pencarian agar hanya mendapatkan tweet yang ditulis oleh pengguna yang namanya dimulai dengan "a":
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1}
} ' ) LIMIT 100 ;Untuk mendapatkan 100 hasil filter terbaru, Anda dapat menggunakan opsi pengurutan :
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1},
sort: {field: "time", reverse: true}
} ' ) limit 100 ;Pencarian sebelumnya dapat dibatasi pada tweet yang dibuat dekat dengan posisi geografis:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"},
{type: "geo_distance", field: "place", latitude: 40.3930, longitude: -3.7328, max_distance: "1km"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1},
sort: {field: "time", reverse: true}
} ' ) limit 100 ;Dimungkinkan juga untuk mengurutkan hasil berdasarkan jarak ke posisi geografis:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"},
{type: "geo_distance", field: "place", latitude: 40.3930, longitude: -3.7328, max_distance: "1km"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1},
sort: [
{field: "time", reverse: true},
{field: "place", type: "geo_distance", latitude: 40.3930, longitude: -3.7328}
]
} ' ) limit 100 ;Yang terakhir, Anda dapat merutekan pencarian apa pun ke rentang token atau partisi tertentu, sedemikian rupa sehingga hanya sebagian dari node cluster yang akan terkena, sehingga menghemat sumber daya yang berharga:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"},
{type: "geo_distance", field: "place", latitude: 40.3930, longitude: -3.7328, max_distance: "1km"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1},
sort: [
{field: "time", reverse: true},
{field: "place", type: "geo_distance", latitude: 40.3930, longitude: -3.7328}
]
} ' ) AND TOKEN(id) >= TOKEN( 0 ) AND TOKEN(id) < TOKEN( 10000000 ) limit 100 ;Yang terakhir ini adalah dasar untuk dukungan kerangka kerja Hadoop, Spark dan MapReduce lainnya.
Silakan merujuk ke dokumentasi Indeks Cassandra Lucene Stratio yang komprehensif.


