korpatbert
1.0.0
KorPatBERT (Korean Patent BERT) adalah model bahasa AI yang diteliti dan dikembangkan oleh Korea Patent Information Service.
Untuk memecahkan masalah pemrosesan bahasa alami Korea di bidang paten dan mempersiapkan infrastruktur informasi cerdas di industri paten, pra-pelatihan sejumlah besar dokumen paten dalam negeri (basis: sekitar 4,06 juta dokumen, besar: sekitar 5,06 juta dokumen) dilakukan berdasarkan arsitektur model dasar Google BERT yang ada (pra-pelatihan) dan diberikan secara gratis.
Ini adalah model bahasa terlatih berkinerja tinggi yang berspesialisasi dalam bidang paten dan dapat digunakan dalam berbagai tugas pemrosesan bahasa alami.
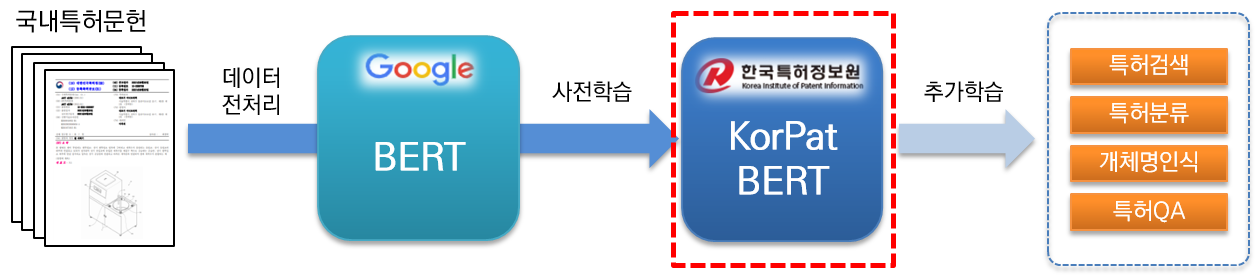
[Pangkalan KorPatBERT]
[KorPatBERT-besar]
[Pangkalan KorPatBERT]
[KorPatBERT-besar]
Sekitar 10 juta kata benda utama dan kata benda majemuk diekstraksi dari dokumen paten yang digunakan dalam pembelajaran model bahasa, dan ini ditambahkan ke kamus pengguna penganalisis morfem Korea Mecab-ko dan kemudian dibagi menjadi subkata melalui Google SentencePiece tokenizer (Tokenizer Paten Kalimat Mecab-ko).
| model | Atas@1(ACC) |
|---|---|
| Google BERT | 72.33 |
| KorBERT | 73.29 |
| KOBERT | 33.75 |
| KrBERT | 72.39 |
| Basis KorPatBERT | 76.32 |
| KorPatBERT-besar | 77.06 |
| model | Atas@1(ACC) | Atas@3(ACC) | Teratas@5(ACC) |
|---|---|---|---|
| Basis KorPatBERT | 61.91 | 82.18 | 86,97 |
| KorPatBERT-besar | 62.89 | 82.18 | 87.26 |
| Nama program | versi | Jalur panduan instalasi | Diperlukan? |
|---|---|---|---|
| ular piton | 3.6 ke atas | https://www.python.org/ | Y |
| anakonda | 4.6.8 dan lebih tinggi | https://www.anaconda.com/ | N |
| aliran tensor | 2.2.0 dan lebih tinggi | https://www.tensorflow.org/install/pip?hl=ko | Y |
| potongan kalimat | 0,1.96 atau lebih tinggi | https://github.com/google/sentencepiece | N |
| mecab-ko | 0.996-en-0.0.2 | https://bitbucket.org/eunjeon/mecab-ko-dic/src/master/ | Y |
| mecab-ko-dik | 2.1.1 | https://bitbucket.org/eunjeon/mecab-ko-dic/src/master/ | Y |
| mecab-python | 0.996-en-0.9.2 | https://bitbucket.org/eunjeon/mecab-ko-dic/src/master/ | Y |
| python-mecab-ko | 1.0.11 atau lebih tinggi | https://pypi.org/project/python-mecab-ko/ | Y |
| keras | 2.4.3 dan lebih tinggi | https://github.com/keras-team/keras | N |
| bert_for_tf2 | 0,14.4 dan lebih tinggi | https://github.com/kpe/bert-for-tf2 | N |
| tqdm | 4.59.0 dan lebih tinggi | https://github.com/tqdm/tqdm | N |
| soynlp | 0,0,493 atau lebih tinggi | https://github.com/lovit/soynlp | N |
Installation URL: https://bitbucket.org/eunjeon/mecab-ko-dic/src/master/
mecab-ko > 0.996-ko-0.9.2
mecab-ko-dic > 2.1.1
mecab-python > 0.996-ko-0.9.2
from korpat_tokenizer import Tokenizer
# (vocab_path=Vocabulary 파일 경로, cased=한글->True, 영문-> False)
tokenizer = Tokenizer(vocab_path="./korpat_vocab.txt", cased=True)
# 테스트 샘플 문장
example = "본 고안은 주로 일회용 합성세제액을 집어넣어 밀봉하는 세제액포의 내부를 원호상으로 열중착하되 세제액이 배출되는 절단부 쪽으로 내벽을 협소하게 형성하여서 내부에 들어있는 세제액을 잘짜질 수 있도록 하는 합성세제 액포에 관한 것이다."
# 샘플 토크나이즈
tokens = tokenizer.tokenize(example)
# 샘플 인코딩 (max_len=토큰 최대 길이)
ids, _ = tokenizer.encode(example, max_len=256)
# 샘플 디코딩
decoded_tokens = tokenizer.decode(ids)
# 결과 출력
print("Length of Token dictionary ===>", len(tokenizer._token_dict.keys()))
print("Input example ===>", example)
print("Tokenized example ===>", tokens)
print("Converted example to IDs ===>", ids)
print("Converted IDs to example ===>", decoded_tokens)
Length of Token dictionary ===> 21400
Input example ===> 본 고안은 주로 일회용 합성세제액을 집어넣어 밀봉하는 세제액포의 내부를 원호상으로 열중착하되 세제액이 배출되는 절단부 쪽으로 내벽을 협소하게 형성하여서 내부에 들어있는 세제액을 잘짜질 수 있도록 하는 합성세제 액포에 관한 것이다.
Tokenized example ===> ['[CLS]', '본', '고안', '은', '주로', '일회용', '합성', '##세', '##제', '##액', '을', '집', '##어넣', '어', '밀봉', '하', '는', '세제', '##액', '##포', '의', '내부', '를', '원호', '상', '으로', '열', '##중', '착하', '되', '세제', '##액', '이', '배출', '되', '는', '절단부', '쪽', '으로', '내벽', '을', '협소', '하', '게', '형성', '하', '여서', '내부', '에', '들', '어', '있', '는', '세제', '##액', '을', '잘', '짜', '질', '수', '있', '도록', '하', '는', '합성', '##세', '##제', '액', '##포', '에', '관한', '것', '이', '다', '.', '[SEP]']
Converted example to IDs ===> [5, 58, 554, 32, 2716, 6554, 817, 20418, 20308, 20514, 15, 732, 15572, 39, 1634, 12, 11, 5934, 20514, 20367, 9, 315, 16, 5922, 17, 33, 279, 20399, 16971, 26, 5934, 20514, 13, 674, 26, 11, 10132, 1686, 33, 3781, 15, 11950, 12, 64, 87, 12, 3958, 315, 10, 51, 39, 25, 11, 5934, 20514, 15, 1803, 12889, 399, 24, 25, 118, 12, 11, 817, 20418, 20308, 299, 20367, 10, 439, 56, 13, 18, 14, 6, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
Converted IDs to example ===> ['본', '고안', '은', '주로', '일회용', '합성', '##세', '##제', '##액', '을', '집', '##어넣', '어', '밀봉', '하', '는', '세제', '##액', '##포', '의', '내부', '를', '원호', '상', '으로', '열', '##중', '착하', '되', '세제', '##액', '이', '배출', '되', '는', '절단부', '쪽', '으로', '내벽', '을', '협소', '하', '게', '형성', '하', '여서', '내부', '에', '들', '어', '있', '는', '세제', '##액', '을', '잘', '짜', '질', '수', '있', '도록', '하', '는', '합성', '##세', '##제', '액', '##포', '에', '관한', '것', '이', '다', '.']
※ Ini sama dengan metode pembelajaran dasar BERT Google, dan untuk contoh penggunaan, lihat bagian 2.3 특허분야 사전학습 언어모델(KorPatBERT) 사용자 매뉴얼 .
Kami mensosialisasikan model bahasa Institut Informasi Paten Korea melalui prosedur tertentu kepada organisasi, perusahaan, dan peneliti yang tertarik padanya. Silakan isi formulir aplikasi dan persetujuan sesuai dengan prosedur aplikasi di bawah ini dan kirimkan aplikasi melalui email kepada penanggung jawab.
| nama file | penjelasan |
|---|---|
| pat_all_mecab_dic.csv | Kamus Pengguna Paten Mecab |
| lm_test_data.tsv | Kumpulan data sampel klasifikasi |
| korpat_tokenizer.py | Program Tokenisasi KorPat |
| tes_tokenize.py | Contoh penggunaan Tokenizer |
| tes_tokenize.ipynb | Contoh penggunaan Tokenizer (Jupiter) |
| tes_lm.py | Contoh penggunaan model bahasa |
| tes_lm.ipynb | Contoh penggunaan model bahasa (Jupyter) |
| korpat_bert_config.json | File Konfigurasi KorPatBERT |
| korpat_vocab.txt | File Kosakata KorPatBERT |
| model.ckpt-381250.meta | File Model KorPatBERT |
| model.ckpt-381250.index | File Model KorPatBERT |
| model.ckpt-381250.data-00000-of-00001 | File Model KorPatBERT |


