mlmm evaluation
1.0.0
Kerangka Evaluasi Model Bahasa Besar Multibahasa
Repo ini berisi kumpulan data benchmark dan skrip evaluasi untuk Model Bahasa Besar Multibahasa (LLM). Kumpulan data ini dapat digunakan untuk mengevaluasi model dalam 26 bahasa berbeda dan mencakup tiga tugas berbeda: ARC, HellaSwag, dan MMLU. Ini dirilis sebagai bagian dari kerangka kerja Okapi kami untuk LLM yang disesuaikan dengan instruksi multibahasa dengan pembelajaran penguatan dari umpan balik manusia.
Saat ini, kumpulan data kami mendukung 26 bahasa: Rusia, Jerman, China, Prancis, Spanyol, Italia, Belanda, Vietnam, Indonesia, Arab, Hongaria, Rumania, Denmark, Slovakia, Ukraina, Katalan, Serbia, Kroasia, Hindi, Bengali, Tamil, Nepal, Malayalam, Marathi, Telugu, dan Kannada.
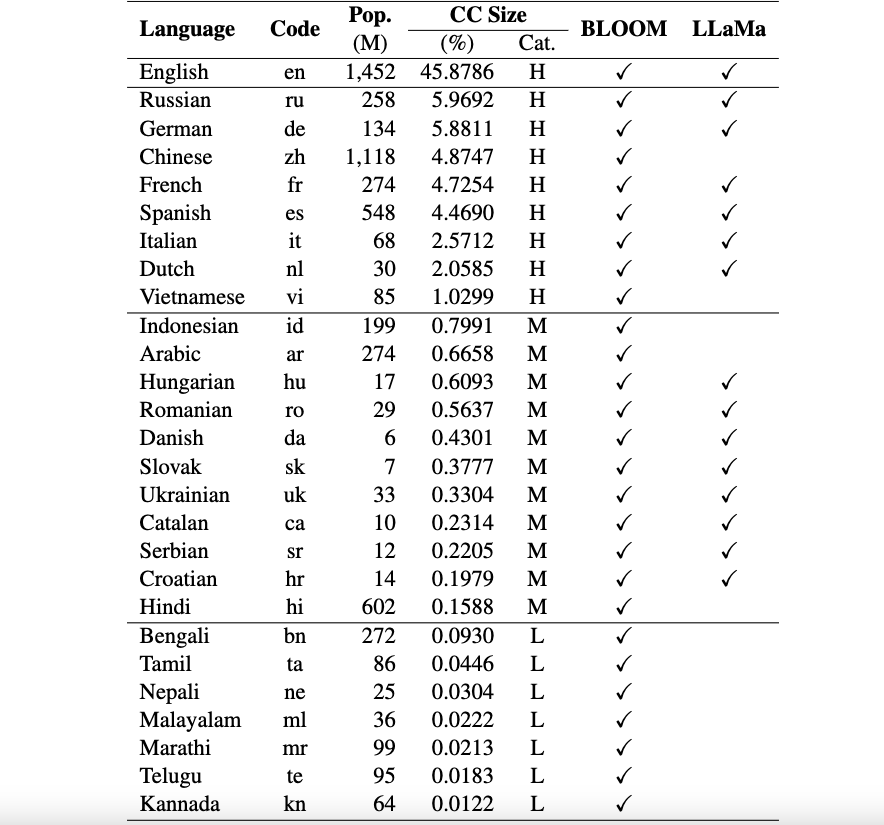
Kumpulan data ini diterjemahkan dari kumpulan data asli ARC, HellaSwag, dan MMLU dalam bahasa Inggris menggunakan ChatGPT. Makalah teknis kami untuk Okapi untuk mendeskripsikan kumpulan data beserta hasil evaluasi untuk beberapa LLM multibahasa (misalnya, BLOOM, LLaMa, dan model Okapi kami) dapat ditemukan di sini.
Pemberitahuan Penggunaan dan Lisensi : Kerangka evaluasi kami ditujukan dan dilisensikan hanya untuk penggunaan penelitian. Kumpulan datanya adalah CC BY NC 4.0 (hanya mengizinkan penggunaan non-komersial) yang tidak boleh digunakan di luar tujuan penelitian.
Untuk menginstal lm-eval dari cabang utama repositori kami, jalankan:
git clone https://github.com/nlp-uoregon/mlmm-evaluation.git
cd mlmm-evaluation
pip install -e " .[multilingual] " Pertama, Anda perlu mengunduh kumpulan data evaluasi multibahasa dengan menggunakan skrip berikut:
bash scripts/download.shUntuk mengevaluasi model Anda pada tiga tugas, Anda dapat menggunakan skrip berikut:
bash scripts/run.sh [LANG] [YOUR-MODEL-PATH]Misalnya, jika Anda ingin mengevaluasi model Okapi Vietnam kami, Anda dapat menjalankan:
bash scripts/run.sh vi uonlp/okapi-vi-bloomKami memelihara papan peringkat untuk melacak kemajuan LLM multibahasa.
Kerangka kerja kami sebagian besar diwarisi dari repo lm-evaluation-harness dari EleutherAI. Harap juga mengutip repo mereka jika Anda menggunakan kode tersebut.
Jika Anda menggunakan data, model, atau kode dalam repositori ini, harap kutip:
@article { dac2023okapi ,
title = { Okapi: Instruction-tuned Large Language Models in Multiple Languages with Reinforcement Learning from Human Feedback } ,
author = { Dac Lai, Viet and Van Nguyen, Chien and Ngo, Nghia Trung and Nguyen, Thuat and Dernoncourt, Franck and Rossi, Ryan A and Nguyen, Thien Huu } ,
journal = { arXiv e-prints } ,
pages = { arXiv--2307 } ,
year = { 2023 }
}

