alpaka-rlhf
Menyempurnakan LLaMA dengan RLHF (Pembelajaran Penguatan dengan Umpan Balik Manusia).
Demo Daring
Modifikasi pada Obrolan DeepSpeed
Langkah 1
- alpaca_rlhf/deepspeed_chat/training/step1_supervised_finetuning/main.py#main()
- alpaca_rlhf/deepspeed_chat/training/utils/data/data_utils.py#create_dataset_split()
- Latih hanya tanggapan dan tambahkan eos
- Hapus end_of_conversation_token
- alpaca_rlhf/deepspeed_chat/training/utils/data/data_utils.py#PromptDataset# getitem
- Label berbeda dari masukan
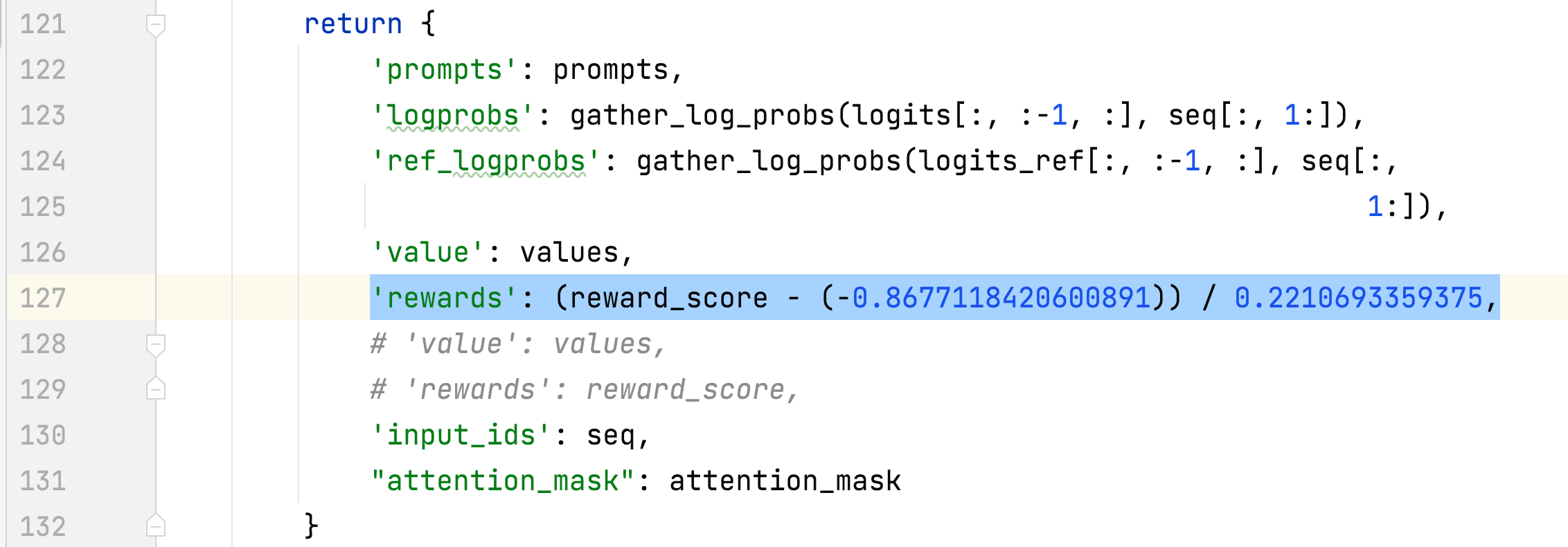
- alpaca_rlhf/deepspeed_chat/training/utils/data/raw_datasets.py#MultiTurnAlpacaDataset
- tambahkan MultiTurnAlpacaDataset
- alpaca_rlhf/deepspeed_chat/training/utils/module/lora.py#convert_linear_layer_to_lora
- Mendukung beberapa nama modul untuk lora
Langkah 2
- alpaca_rlhf/deepspeed_chat/training/step2_reward_model_finetuning/main.py#main()
- alpaca_rlhf/deepspeed_chat/training/utils/model/reward_model.py#RewardModel#forward()
- Memperbaiki ketidakstabilan numerik
- alpaca_rlhf/deepspeed_chat/training/utils/data/data_utils.py#create_dataset_split()
- Hapus end_of_conversation_token
Langkah 3
- alpaca_rlhf/deepspeed_chat/training/step3_rlhf_finetuning/main.py#main()
- alpaca_rlhf/deepspeed_chat/training/utils/data/data_utils.py#create_dataset_split()
- Perbaiki bug panjang maksimal
- alpaca_rlhf/deepspeed_chat/training/utils/data/data_utils.py#DataCollatorRLHF# panggilan
- Perbaiki bug sisi padding
- alpaca_rlhf/deepspeed_chat/training/step3_rlhf_finetuning/ppo_trainer.py#DeepSpeedPPOTrainer#generate_experience
- alpaca_rlhf/deepspeed_chat/training/step3_rlhf_finetuning/ppo_trainer.py#DeepSpeedPPOTrainer#_generate_sequence
Stey demi Langkah
- Menjalankan ketiga langkah pada 2 x A100 80G
- Kumpulan data
- Kertas pelukan wajah Dahoas/rm-statis GitHub
- MultiPutaranAlpaca
- Ini adalah versi multi-putaran dari kumpulan data alpaka dan dibuat berdasarkan AlpacaDataCleaned dan ChatAlpaca.
- Masuk ke direktori ./alpaca_rlhf terlebih dahulu, lalu jalankan perintah berikut:
- langkah1: sh run.sh --num_gpus 2 /tmp/pycharm_project_227/alpaca_rlhf/deepspeed_chat/training/step1_supervised_finetuning/main.py --sft_only_data_path MultiTurnAlpaca --data_output_path /root/autodl-tmp/rlhf/tmp/ --model_name_or_path decapoda-research/llama-7b-hf --per_device_train_batch_size 8 --per_device_eval_batch_size 8 --max_seq_len 512 --learning_rate 3e-4 --num_train_epochs 1 --gradient_accumulation_steps 8 --num_warmup_steps 100 --output_dir /root/autodl-tmp/rlhf/actor --lora_dim 8 --lora_module_name q_proj,k_proj --only_optimize_lora --deepspeed --zero_stage 2
- ketika --sft_only_data_path MultiTurnAlpaca ditambahkan, harap unzip data/data.zip terlebih dahulu.
- langkah 2: sh run.sh --num_gpus 2 /tmp/pycharm_project_227/alpaca_rlhf/deepspeed_chat/training/step2_reward_model_finetuning/main.py --data_output_path /root/autodl-tmp/rlhf/tmp/ --model_name_or_path decapoda-research/llama-7b -hf --num_padding_at_beginning 0 --per_device_train_batch_size 4 --per_device_eval_batch_size 64 --learning_rate 5e-4 --num_train_epochs 1 --gradient_accumulation_steps 1 --num_warmup_steps 0 --zero_stage 2 --deepspeed --output_dir /root/autodl-tmp/rlhf/critic --lora_dim 8 --lora_module_name q_proj,k_proj --only_optimize_lora
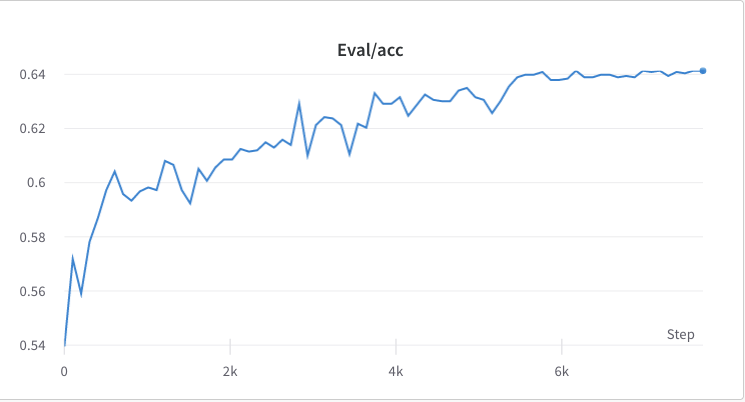
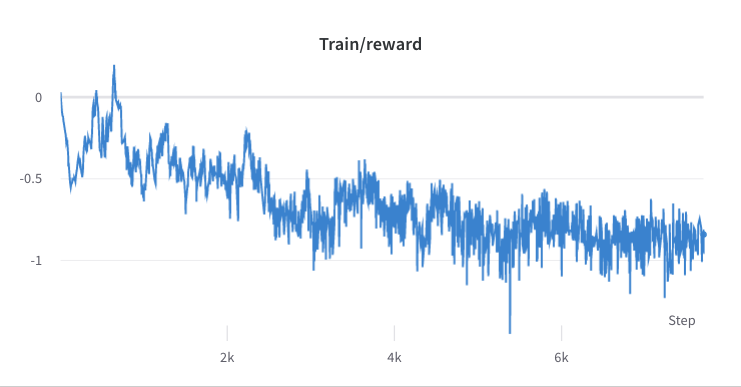
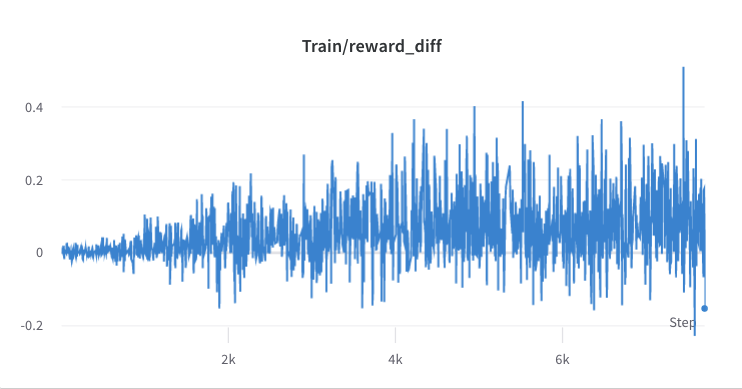
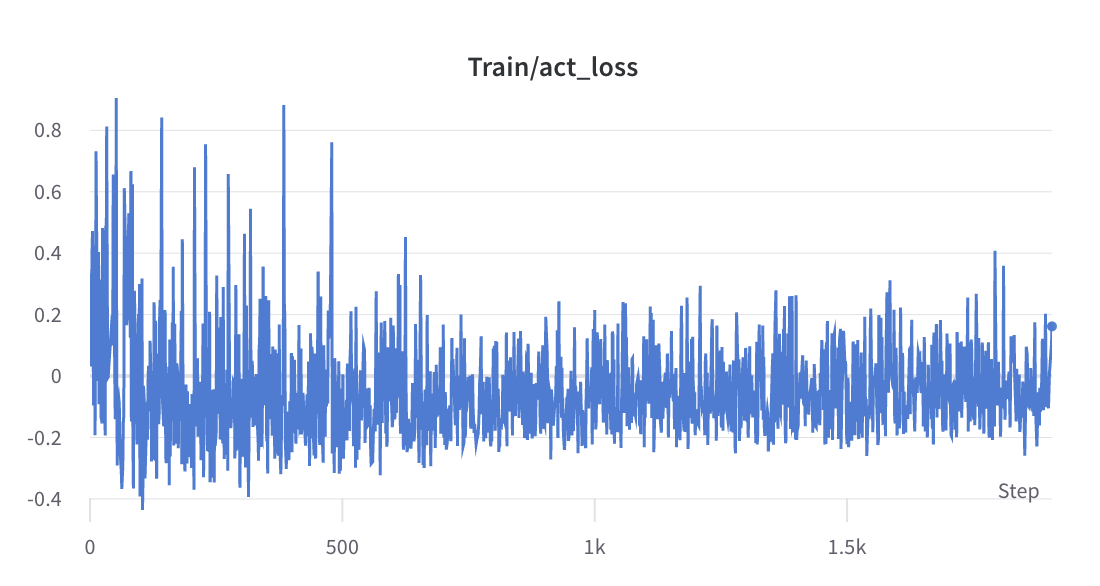
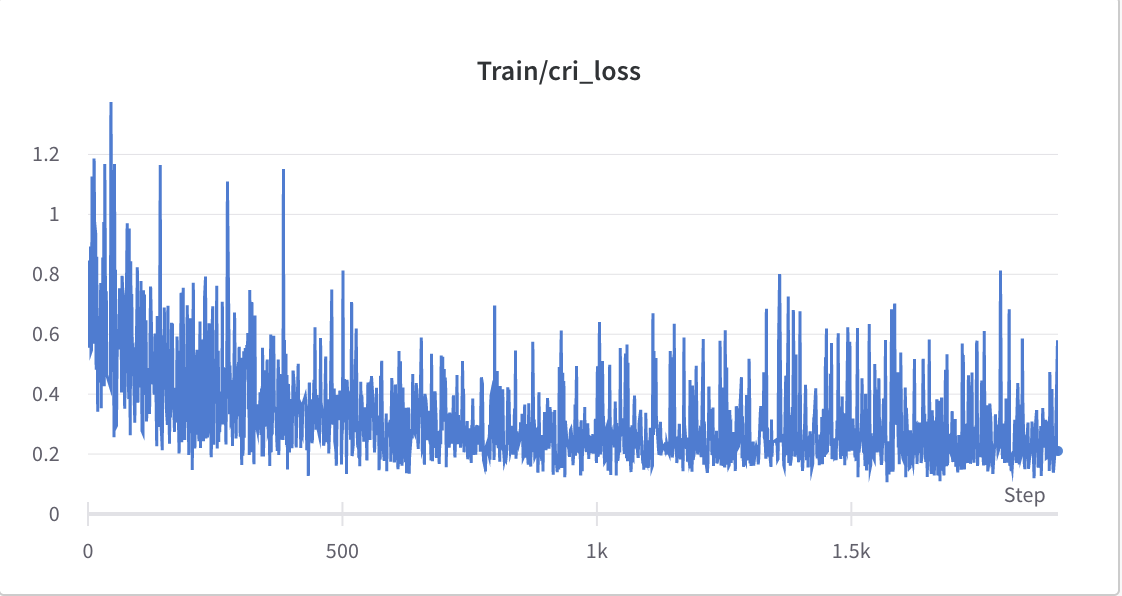
- proses pelatihan langkah 2
- Rata-rata dan deviasi standar imbalan dari respons yang dipilih dikumpulkan dan digunakan untuk menormalkan imbalan pada langkah 3. Dalam satu percobaan, masing-masing adalah -0,8677118420600891 dan 0,2210693359375 dan digunakan dalam alpaca_rlhf/deepspeed_chat/training/step3_rlhf_finetuning/ppo_trainer.py#DeepSpeedPPOTrainer#generate_experience metode: 'rewards': (reward_score - (-0.8677118420600891)) / 0.2210693359375.
- langkah3: sh run.sh --num_gpus 2 /tmp/pycharm_project_227/alpaca_rlhf/deepspeed_chat/training/step3_rlhf_finetuning/main.py --data_output_path /root/autodl-tmp/rlhf/tmp/ --actor_model_name_or_path /root/autodl-tmp/ rlhf/aktor/ --tokenizer_name_or_path decapoda-research/llama-7b-hf --critic_model_name_or_path /root/autodl-tmp/rlhf/critic --actor_zero_stage 2 --critic_zero_stage 2 --num_padding_at_beginning 0 --per_device_train_batch_size 4 --per_device_mini_train_batch_size 4 --ppo_epochs 2 --actor_learning_rate 9.65e-6 --critic_learning_rate 5e-6 --gradient_accumulation_steps 1 --deepspeed --actor_lora_dim 8 --actor_lora_module_name q_proj --critic_lora_dim 8 --critic_lora_module_name q_proj,k_proj --only_optimize_lora --output_dir /root/autodl-tmp/rlhf/final
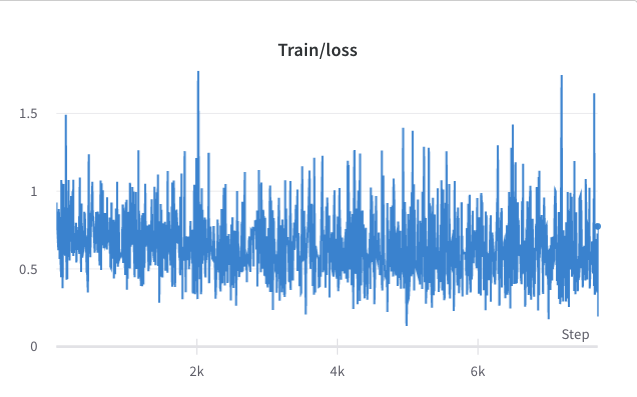
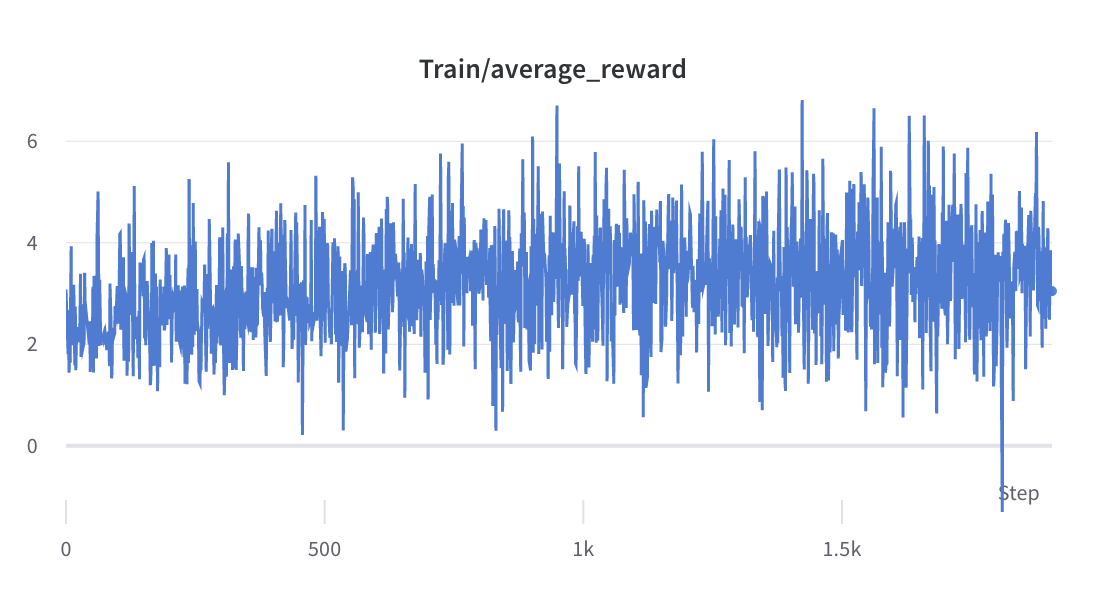
- proses pelatihan langkah 3
- Kesimpulan
- nohup sh run_inference.sh 0 alpaca_rlhf/inference/llama_chatbot_gradio.py --path /root/autodl-tmp/rlhf/final/actor > rlhf_inference.log 2>&1 &
- nohup sh run_inference.sh 0 alpaca_rlhf/inference/llama_chatbot_gradio.py --path /root/autodl-tmp/rlhf/actor > sft_inference.log 2>&1 &
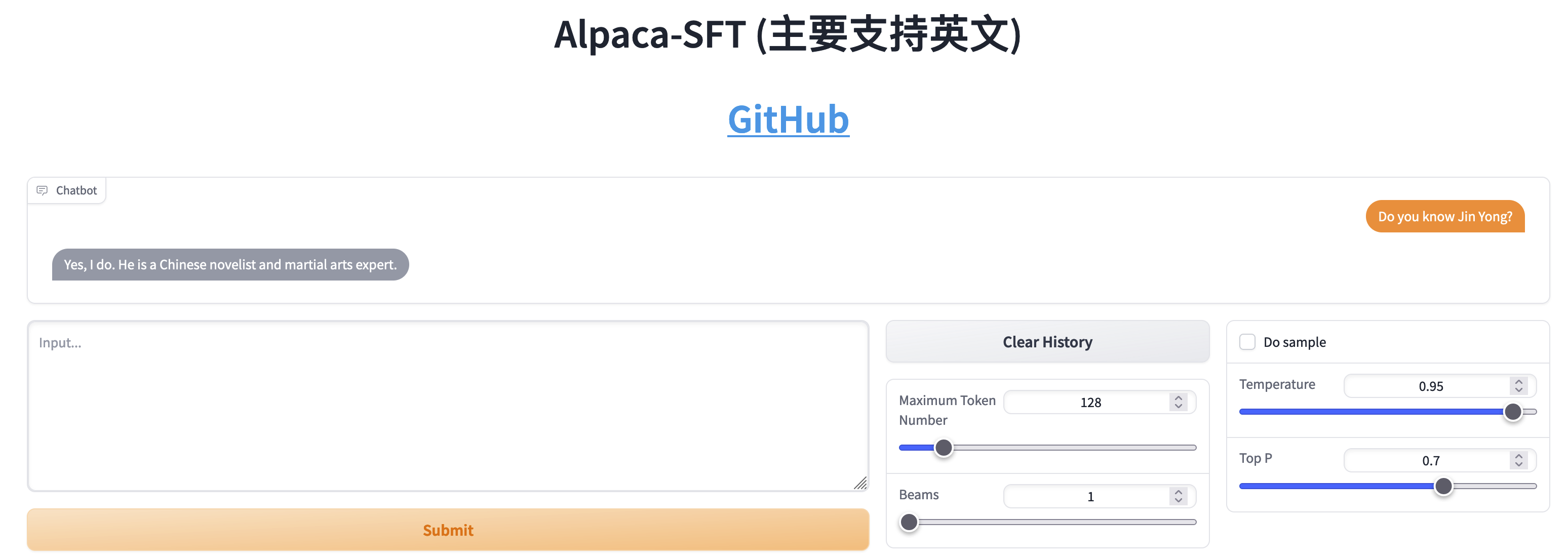
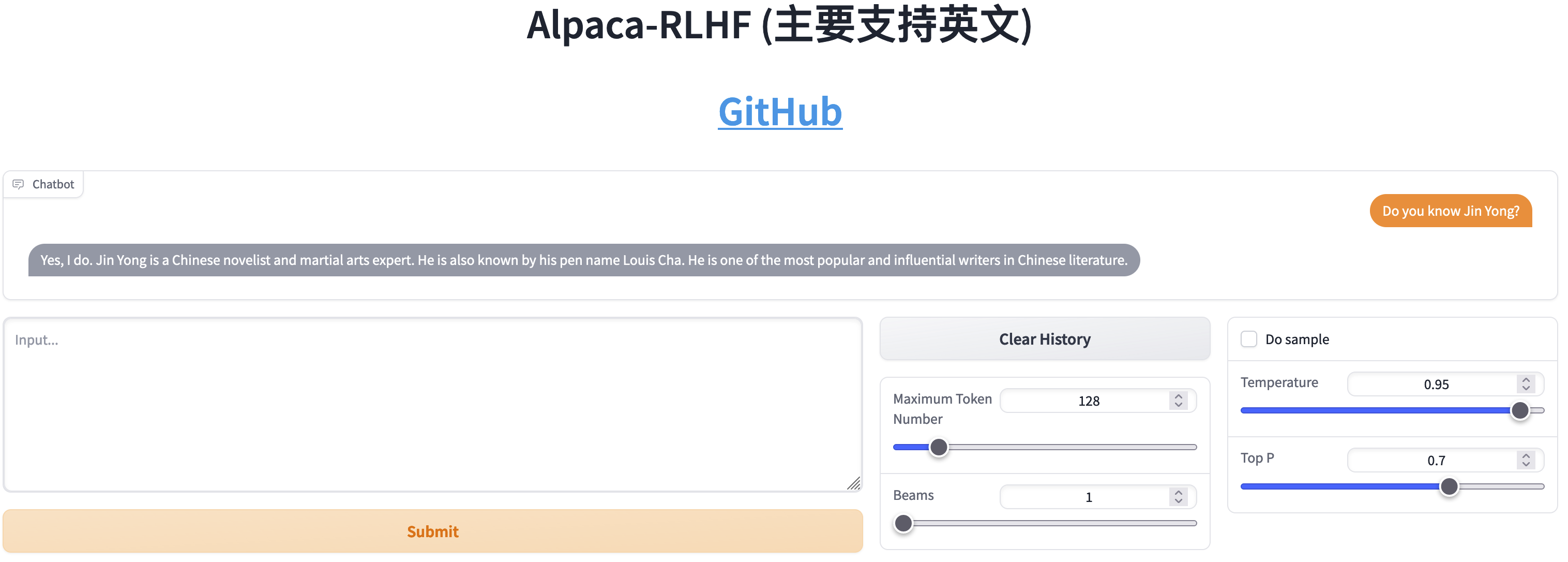
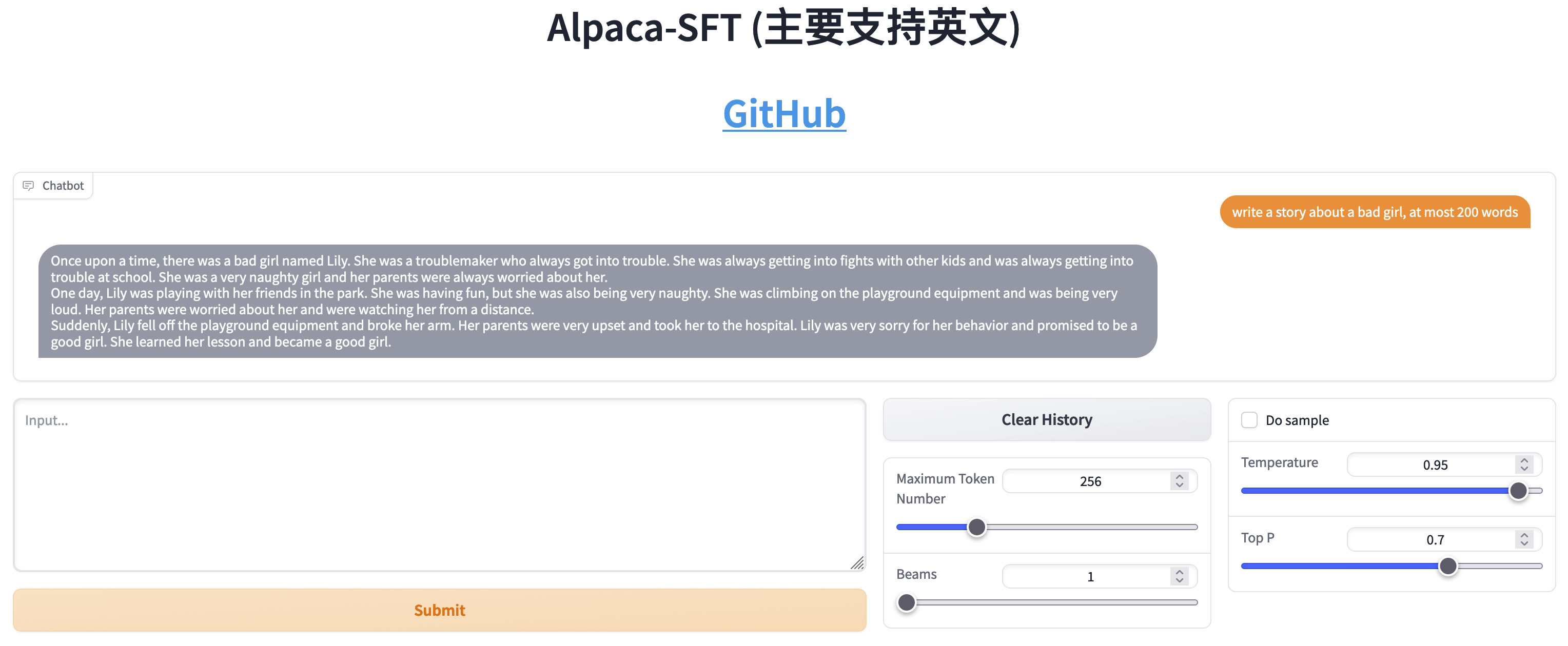
Perbandingan antara SFT dan RLHF
Referensi
Artikel
- 如何正确复现 Instruksikan GPT / RLHF?
- 影响PPO算法性能的10个关键技巧(附PPO算法简洁Pytorch实现)
Sumber
Peralatan
Kumpulan data
- Kumpulan Data Preferensi Manusia Stanford (SHP)
- HH-RLHF
- hh-rlhf
- Melatih Asisten yang Bermanfaat dan Tidak Berbahaya dengan Pembelajaran Penguatan dari Umpan Balik Manusia [makalah]
- Dahoas/statis-hh
- Dahoas/rm-statis
- GPT-4-LLM
- Asisten Terbuka
Repositori Terkait
- alpaka saya
- multi-turn-alpaca