Phi2 mini Chinese
1.0.0
Proyek ini adalah proyek eksperimental, dengan kode sumber terbuka dan bobot model, serta lebih sedikit data pra-pelatihan. Jika Anda memerlukan model kecil berbahasa Mandarin yang lebih baik, Anda dapat merujuk ke proyek ChatLM-mini-China
Peringatan
Proyek ini adalah proyek eksperimental dan dapat mengalami perubahan besar kapan saja, termasuk data pelatihan, struktur model, struktur direktori file, dll. Model versi pertama dan silakan periksa tag v1.0
Misalnya, menambahkan titik di akhir kalimat, mengubah bahasa Mandarin tradisional menjadi bahasa Mandarin yang disederhanakan, menghapus tanda baca yang berulang (misalnya, beberapa materi dialog memiliki banyak "。。。。。" ), standardisasi NFKC Unicode (terutama masalah full- konversi lebar ke setengah lebar dan data halaman web u3000 xa0) dll.
Untuk proses pembersihan data spesifik, silakan lihat proyek ChatLM-mini-China.
Proyek ini menggunakan tokenizer BPE byte level . Ada dua jenis kode pelatihan yang disediakan untuk segmentasi kata: char level dan byte level .
Setelah pelatihan, tokenizer ingat untuk memeriksa apakah ada simbol khusus yang umum dalam kosakata, seperti t , n , dll. Anda dapat mencoba encode dan decode teks yang berisi karakter khusus untuk melihat apakah teks tersebut dapat dipulihkan. Jika karakter khusus ini tidak disertakan, tambahkan melalui fungsi add_tokens . Gunakan len(tokenizer) untuk mendapatkan ukuran kosakata tokenizer.vocab_size tidak menghitung karakter yang ditambahkan melalui fungsi add_tokens .
Pelatihan Tokenizer menghabiskan banyak memori:
Melatih 100 juta karakter byte level memerlukan setidaknya 32G memori (pada kenyataannya, 32G tidak cukup, dan pertukaran akan sering dipicu. Pelatihan 13600k memerlukan waktu sekitar satu jam).
Pelatihan char level sebanyak 650 juta karakter (yang merupakan jumlah data yang sama di Wikipedia bahasa Mandarin) memerlukan setidaknya 32G memori. Karena swap dipicu beberapa kali, penggunaan sebenarnya jauh lebih dari 32G. Pelatihan 13600K membutuhkan waktu sekitar setengahnya jam.
Oleh karena itu, jika kumpulan datanya besar (tingkat GB), disarankan untuk mengambil sampel dari kumpulan data tersebut saat melatih tokenizer .
Gunakan teks dalam jumlah besar untuk pra-pelatihan tanpa pengawasan, terutama menggunakan kumpulan data BELLE dari bell open source .
Format kumpulan data: satu kalimat untuk satu sampel. Jika terlalu panjang, dapat dipotong dan dibagi menjadi beberapa sampel.
Selama proses pra-pelatihan CLM, input dan output model sama, dan saat menghitung cross-entropy loss harus digeser satu bit ( shift ).
Saat memproses korpus ensiklopedia, disarankan untuk menambahkan tanda '[EOS]' di akhir setiap entri. Pemrosesan korpus lainnya serupa. Akhir doc (yang dapat berupa akhir artikel atau akhir paragraf) harus ditandai dengan '[EOS]' . Tanda awal '[BOS]' dapat ditambahkan atau tidak.
Terutama menggunakan kumpulan data bell open source . Terima kasih bos BELLE.
Format data pelatihan SFT adalah sebagai berikut:
text = f"##提问: n { example [ 'instruction' ] } n ##回答: n { example [ 'output' ][ EOS ]" Saat model menghitung kerugian, model akan mengabaikan bagian sebelum tanda "##回答:" ( "##回答:" juga akan diabaikan), dimulai dari akhir "##回答:" .
Ingatlah untuk menambahkan tanda khusus akhir kalimat EOS , jika tidak, Anda tidak akan tahu kapan harus berhenti saat decode model. Tanda awal kalimat BOS dapat diisi atau dikosongkan.
Mengadopsi metode pengoptimalan preferensi DPO yang lebih sederhana dan hemat memori.
Sempurnakan model SFT sesuai dengan preferensi pribadi. Kumpulan data harus membuat tiga kolom: prompt , chosen dan rejected . Kolom rejected memiliki beberapa data dari model utama dalam tahap sft (misalnya, sft melatih 4 epoch dan mengambil a . 0.5 epoch checkpoint model) Generate, jika kemiripan antara yang dihasilkan rejected dan chosen di atas 0.9, maka data ini tidak diperlukan.
Ada dua model dalam proses DPO, satu adalah model yang akan dilatih, dan yang lainnya adalah model referensi. Saat dimuat, sebenarnya model tersebut sama, tetapi model referensi tidak ikut serta dalam pembaruan parameter.
Repositori huggingface berat model: Phi2-Chinese-0.2B
from transformers import AutoTokenizer , AutoModelForCausalLM , GenerationConfig
import torch
device = torch . device ( "cuda" ) if torch . cuda . is_available () else torch . device ( "cpu" )
tokenizer = AutoTokenizer . from_pretrained ( 'charent/Phi2-Chinese-0.2B' )
model = AutoModelForCausalLM . from_pretrained ( 'charent/Phi2-Chinese-0.2B' ). to ( device )
txt = '感冒了要怎么办?'
prompt = f"##提问: n { txt } n ##回答: n "
# greedy search
gen_conf = GenerationConfig (
num_beams = 1 ,
do_sample = False ,
max_length = 320 ,
max_new_tokens = 256 ,
no_repeat_ngram_size = 4 ,
eos_token_id = tokenizer . eos_token_id ,
pad_token_id = tokenizer . pad_token_id ,
)
tokend = tokenizer . encode_plus ( text = prompt )
input_ids , attention_mask = torch . LongTensor ([ tokend . input_ids ]). to ( device ),
torch . LongTensor ([ tokend . attention_mask ]). to ( device )
outputs = model . generate (
inputs = input_ids ,
attention_mask = attention_mask ,
generation_config = gen_conf ,
)
outs = tokenizer . decode ( outputs [ 0 ]. cpu (). numpy (), clean_up_tokenization_spaces = True , skip_special_tokens = True ,)
print ( outs ) ##提问:
感冒了要怎么办?
##回答:
感冒是由病毒引起的,感冒一般由病毒引起,以下是一些常见感冒的方法:
- 洗手,特别是在接触其他人或物品后。
- 咳嗽或打喷嚏时用纸巾或手肘遮住口鼻。
- 用手触摸口鼻,特别是喉咙和鼻子。
- 如果咳嗽或打喷嚏,可以用纸巾或手绢来遮住口鼻,但要远离其他人。
- 如果你感冒了,最好不要触摸自己的眼睛、鼻子和嘴巴。
- 在感冒期间,最好保持充足的水分和休息,以缓解身体的疲劳。
- 如果您已经感冒了,可以喝一些温水或盐水来补充体液。
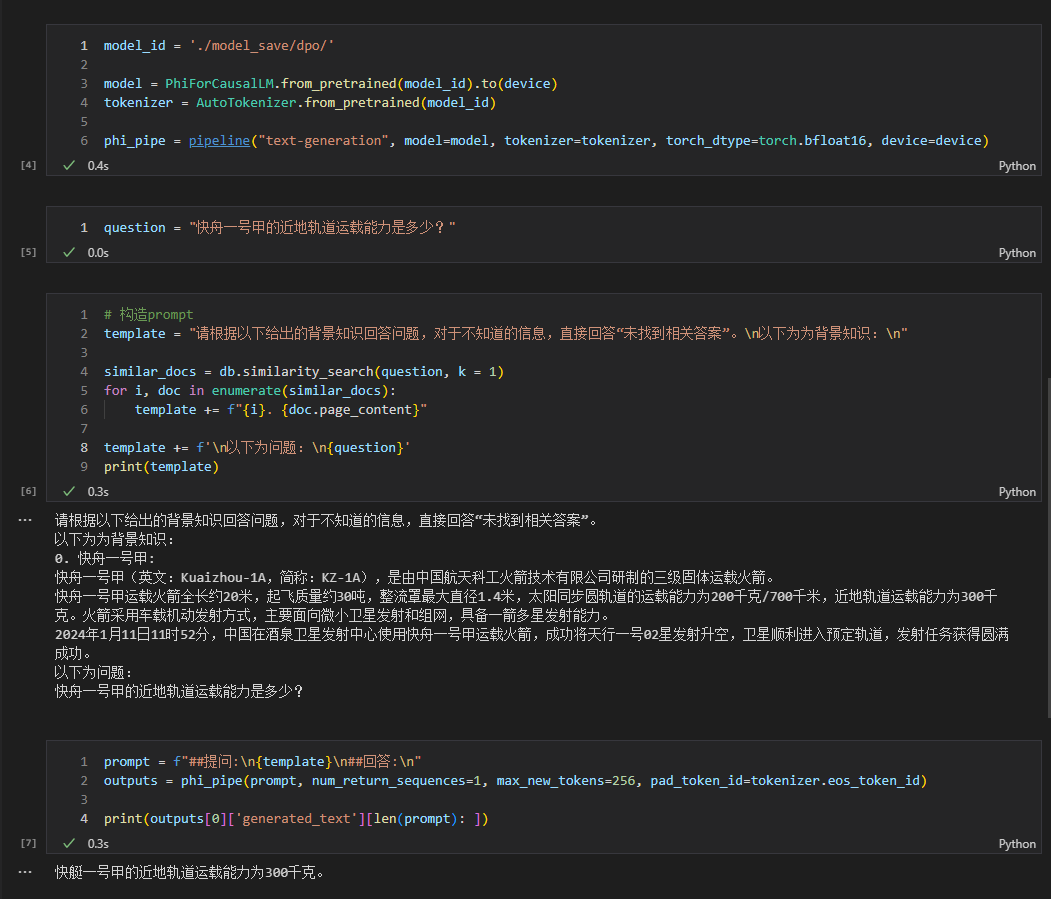
- 另外,如果感冒了,建议及时就医。 Lihat rag_with_langchain.ipynb untuk kode spesifiknya.
Jika menurut Anda proyek ini bermanfaat bagi Anda, silakan kutip.
@misc{Charent2023,
author={Charent Chen},
title={A small Chinese causal language model with 0.2B parameters base on Phi2},
year={2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/charent/Phi2-mini-Chinese}},
}
Proyek ini tidak menanggung risiko dan tanggung jawab atas keamanan data dan risiko opini publik yang disebabkan oleh model dan kode sumber terbuka, atau risiko dan tanggung jawab yang timbul dari model apa pun yang disesatkan, disalahgunakan, disebarluaskan, atau dieksploitasi secara tidak patut.


