YAYI UIE
1.0.0

[README] [?HF Repo] [?Versi web]
Cina |. Inggris
[28.03.2024] Semua model dan data diunggah ke Komunitas Sihir.
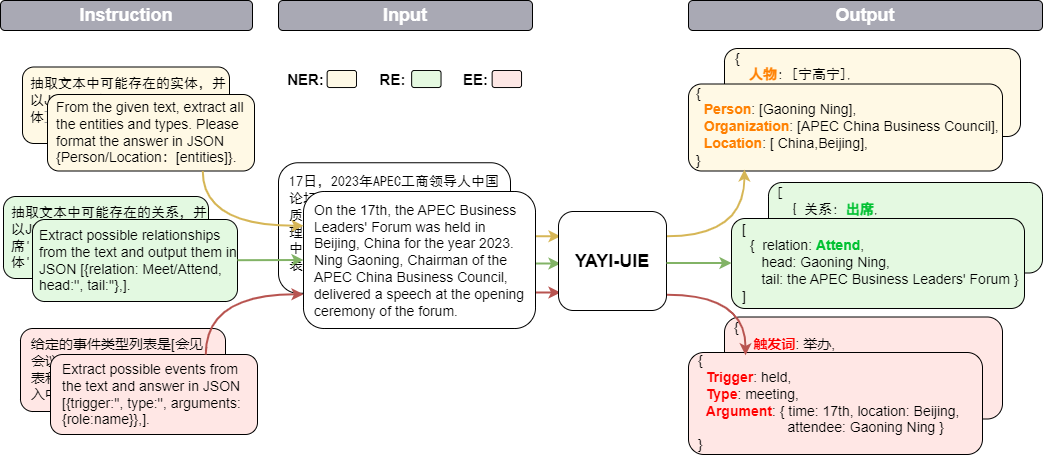
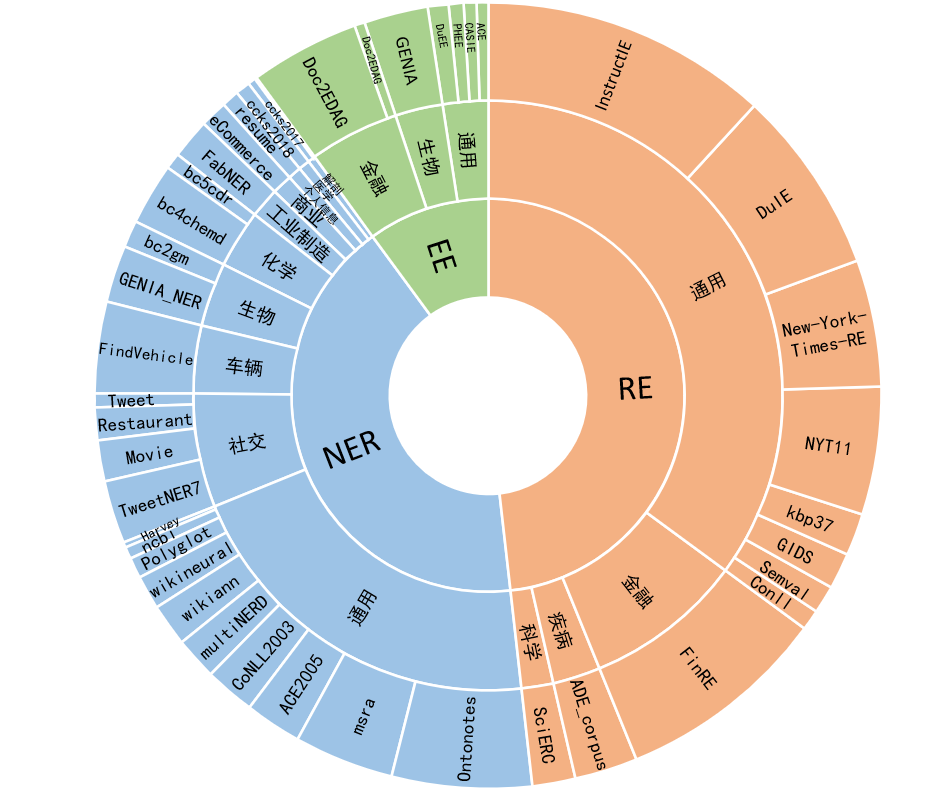
Yayi Information Extraction Unified Large Model (YAYI-UIE) menyempurnakan instruksi pada jutaan data ekstraksi informasi berkualitas tinggi yang dibuat secara manual. Tugas ekstraksi informasi pelatihan terpadu mencakup pengenalan entitas bernama (NER), ekstraksi hubungan (RE), dan ekstraksi peristiwa ( EE) untuk mencapai ekstraksi terstruktur secara umum, keamanan, keuangan, biologi, medis, komersial, pribadi, kendaraan, film, industri, restoran, ilmiah dan skenario lainnya.
Melalui sumber terbuka model besar Yayi UIE, kami akan menyumbangkan upaya kami sendiri untuk mempromosikan pengembangan komunitas sumber terbuka model besar yang telah dilatih sebelumnya di Tiongkok. Melalui sumber terbuka, kami akan membangun ekosistem model besar Yayi dengan setiap mitra. Untuk detail teknis lebih lanjut, silakan baca laporan teknis kami YAYI-UIE: Kerangka Kerja Penyetelan Instruksi yang Ditingkatkan dengan Obrolan untuk Ekstraksi Informasi Universal.
| nama | ? | Alamat unduhan | Logo model ajaib | Alamat unduhan |
|---|---|---|---|---|
| YAYI-UIE | wenge-penelitian/yayi-uie | Pengunduhan model | wenge-penelitian/yayi-uie | Pengunduhan model |
| Data YAYI-UIE | wenge-research/yayi_uie_sft_data | Pengunduhan kumpulan data | wenge-research/yayi_uie_sft_data | Pengunduhan kumpulan data |
54% dari korpus tingkat jutaan berbahasa Mandarin dan 46% dalam bahasa Inggris; kumpulan data mencakup 12 bidang termasuk keuangan, masyarakat, biologi, perdagangan, industri manufaktur, kimia, kendaraan, sains, penyakit dan perawatan medis, kehidupan pribadi, keamanan dan umum. Mencakup ratusan skenario
git clone https://github.com/wenge-research/yayi-uie.git
cd yayi-uieconda create --name uie python=3.8
conda activate uiepip install -r requirements.txt Versi torch dan transformers tidak disarankan lebih rendah dari versi yang direkomendasikan.
Model ini bersumber terbuka di repositori model Huggingface kami, dan Anda dipersilakan untuk mengunduh dan menggunakannya. Berikut ini adalah contoh kode yang hanya memanggil YAYI-UIE untuk inferensi tugas hilir. Kode ini dapat dijalankan pada satu GPU seperti A100/A800. Dibutuhkan sekitar 33 GB memori video saat menggunakan inferensi presisi bf16:
> >> import torch
> >> from transformers import AutoModelForCausalLM , AutoTokenizer
> >> from transformers . generation . utils import GenerationConfig
> >> tokenizer = AutoTokenizer . from_pretrained ( "wenge-research/yayi-uie" , use_fast = False , trust_remote_code = True )
> >> model = AutoModelForCausalLM . from_pretrained ( "wenge-research/yayi-uie" , device_map = "auto" , torch_dtype = torch . bfloat16 , trust_remote_code = True )
> >> generation_config = GenerationConfig . from_pretrained ( "wenge-research/yayi-uie" )
> >> prompt = "文本:氧化锆陶瓷以其卓越的物理和化学特性在多个行业中发挥着关键作用。这种材料因其高强度、高硬度和优异的耐磨性,广泛应用于医疗器械、切削工具、磨具以及高端珠宝制品。在制造这种高性能陶瓷时,必须遵循严格的制造标准,以确保其最终性能。这些标准涵盖了从原材料选择到成品加工的全过程,保障产品的一致性和可靠性。氧化锆的制造过程通常包括粉末合成、成型、烧结和后处理等步骤。原材料通常是高纯度的氧化锆粉末,通过精确控制的烧结工艺,这些粉末被转化成具有特定微观结构的坚硬陶瓷。这种独特的微观结构赋予氧化锆陶瓷其显著的抗断裂韧性和耐腐蚀性。此外,氧化锆陶瓷的热膨胀系数与铁类似,使其在高温应用中展现出良好的热稳定性。因此,氧化锆陶瓷不仅在工业领域,也在日常生活中的应用日益增多,成为现代材料科学中的一个重要分支。 n抽取文本中可能存在的实体,并以json{制造品名称/制造过程/制造材料/工艺参数/应用/生物医学/工程特性:[实体]}格式输出。"
> >> # "<reserved_13>" is a reserved token for human, "<reserved_14>" is a reserved token for assistant
>> > prompt = "<reserved_13>" + prompt + "<reserved_14>"
> >> inputs = tokenizer ( prompt , return_tensors = "pt" ). to ( model . device )
> >> response = model . generate ( ** inputs , max_new_tokens = 512 , temperature = 0 )
> >> print ( tokenizer . decode ( response [ 0 ], skip_special_tokens = True ))Catatan:
文本:xx
【实体抽取】抽取文本中可能存在的实体,并以json{人物/机构/地点:[实体]}格式输出。
文本:xx
【关系抽取】已知关系列表是[注资,拥有,纠纷,自己,增持,重组,买资,签约,持股,交易]。根据关系列表抽取关系三元组,按照json[{'relation':'', 'head':'', 'tail':''}, ]的格式输出。
文本:xx
抽取文本中可能存在的关系,并以json[{'关系':'会见/出席', '头实体':'', '尾实体':''}, ]格式输出。
文本:xx
已知论元角色列表是[时间,地点,会见主体,会见对象],请根据论元角色列表从给定的输入中抽取可能的论元,以json{角色:论元}格式输出。
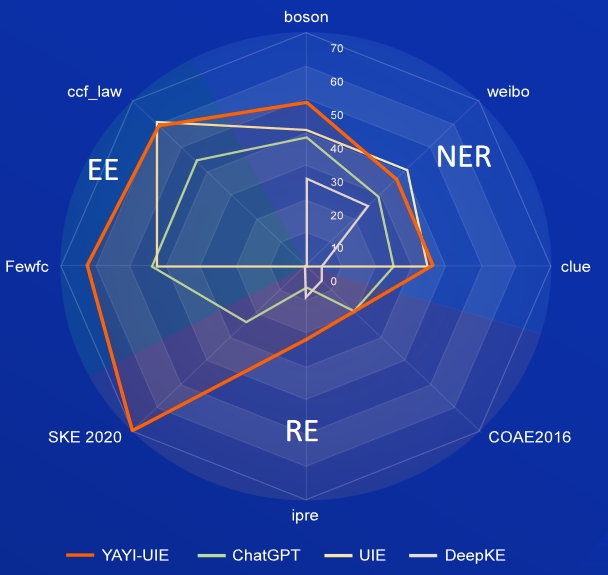
AI, Sastra, Musik, Politik, dan Sains adalah kumpulan data berbahasa Inggris, dan boson, petunjuk, dan weibo adalah kumpulan data Tiongkok.
| Model | AI | Literatur | Musik | Politik | Sains | Rata-rata bahasa Inggris | boson | petunjuk | Rata-rata orang Cina | |
|---|---|---|---|---|---|---|---|---|---|---|
| davinci | 2.97 | 9.87 | 13.83 | 18.42 | 10.04 | 11.03 | - | - | - | 31.09 |
| ObrolanGPT 3.5 | 54.4 | 54.07 | 61.24 | 59.12 | 63 | 58.37 | 38.53 | 25.44 | 29.3 | |
| UIE | 31.14 | 38.97 | 33.91 | 46.28 | 41.56 | 38.37 | 40.64 | 34.91 | 40,79 | 38.78 |
| USM | 28.18 | 56 | 44.93 | 36.1 | 44.09 | 41.86 | - | - | - | - |
| InstruksikanUIE | 49 | 47.21 | 53.16 | 48.15 | 49.3 | 49.36 | - | - | - | - |
| TahuLM | 13.76 | 20.18 | 14.78 | 33.86 | 9.19 | 18.35 | 25.96 | 4.44 | 25.2 | 18.53 |
| YAYI-UIE | 52.4 | 45,99 | 51.2 | 51.82 | 50.53 | 50.39 | 49.25 | 36.46 | 36.78 | 40.83 |
FewRe, Wiki-ZSL adalah kumpulan data berbahasa Inggris, SKE 2020, COAE2016, IPRE adalah kumpulan data Tiongkok
| Model | Sedikit Rel | Wiki-ZSL | Rata-rata bahasa Inggris | SKE 2020 | COAE2016 | IPRE | Rata-rata orang Cina |
|---|---|---|---|---|---|---|---|
| ObrolanGPT 3.5 | 9.96 | 13.14 | 11.55 24.47 | 19.31 | 6.73 | 16.84 | |
| ZETT(T5-kecil) | 30.53 | 31.74 | 31.14 | - | - | - | - |
| ZETT (basis T5) | 33.71 | 31.17 | 32.44 | - | - | - | - |
| InstruksikanUIE | 39.55 | 35.2 | 37.38 | - | - | - | - |
| TahuLM | 17.46 | 15.33 | 16.40 | 0,4 | 6.56 | 9.75 | 5.57 |
| YAYI-UIE | 36.09 | 41.07 | 38.58 | 70.8 | 19.97 | 22.97 | 37.91 |
berita komoditas adalah kumpulan data berbahasa Inggris, FewFC, ccf_law adalah kumpulan data Tiongkok
EET (identifikasi jenis acara)
| Model | berita komoditas | BeberapaFC | ccf_law | Rata-rata orang Cina |
|---|---|---|---|---|
| ObrolanGPT 3.5 | 1.41 | 16.15 | 0 | 8.08 |
| UIE | - | 50.23 | 2.16 | 26.20 |
| InstruksikanUIE | 23.26 | - | - | - |
| YAYI-UIE | 12.45 | 81.28 | 12.87 | 47.08 |
EEA (ekstraksi argumen peristiwa)
| Model | berita komoditas | BeberapaFC | ccf_law | Rata-rata orang Cina |
|---|---|---|---|---|
| ObrolanGPT 3.5 | 8.6 | 44.4 | 44.57 | 44.49 |
| UIE | - | 43.02 | 60,85 | 51.94 |
| InstruksikanUIE | 21.78 | - | - | - |
| YAYI-UIE | 19.74 | 63.06 | 59.42 | 61.24 |
Model SFT yang dilatih berdasarkan data terkini dan model dasar masih memiliki permasalahan efektivitas sebagai berikut:
Berdasarkan batasan model di atas, kami mewajibkan pengembang untuk hanya menggunakan kode sumber terbuka, data, model, dan turunan berikutnya yang dihasilkan oleh proyek ini untuk tujuan penelitian dan bukan untuk tujuan komersial atau penggunaan lain yang akan menimbulkan kerugian bagi masyarakat. Harap berhati-hati dalam mengidentifikasi dan menggunakan konten yang dihasilkan oleh Yayi Big Model, dan jangan menyebarkan konten berbahaya yang dihasilkan ke Internet. Jika terjadi akibat buruk, komunikator akan bertanggung jawab. Proyek ini hanya dapat digunakan untuk tujuan penelitian, dan pengembang proyek tidak bertanggung jawab atas segala kerugian atau kerugian yang disebabkan oleh penggunaan proyek ini (termasuk namun tidak terbatas pada data, model, kode, dll.). Silakan lihat penafian untuk detailnya.
Kode dan data dalam proyek ini bersifat open source sesuai dengan protokol Apache-2.0. Ketika komunitas menggunakan model YAYI UIE atau turunannya, harap ikuti perjanjian komunitas dan perjanjian komersial Baichuan2.
Jika Anda menggunakan model kami dalam pekerjaan Anda, Anda dapat mengutip makalah kami:
@article{YAYI-UIE,
author = {Xinglin Xiao, Yijie Wang, Nan Xu, Yuqi Wang, Hanxuan Yang, Minzheng Wang, Yin Luo, Lei Wang, Wenji Mao, Dajun Zeng}},
title = {YAYI-UIE: A Chat-Enhanced Instruction Tuning Framework for Universal Information Extraction},
journal = {arXiv preprint arXiv:2312.15548},
url = {https://arxiv.org/abs/2312.15548},
year = {2023}
}


