Dropout NeuralNetworks
1.0.0
Dalam proyek penelitian ini, saya akan fokus pada dampak perubahan angka putus sekolah pada dataset MNIST. Tujuan saya adalah mereproduksi gambar di bawah ini dengan data yang digunakan dalam makalah penelitian. Tujuan dari proyek ini adalah untuk mempelajari bagaimana figur pembelajaran mesin diproduksi. Secara khusus, mempelajari pengaruh kesalahan klasifikasi saat mengubah/tidak mengubah probabilitas dropout.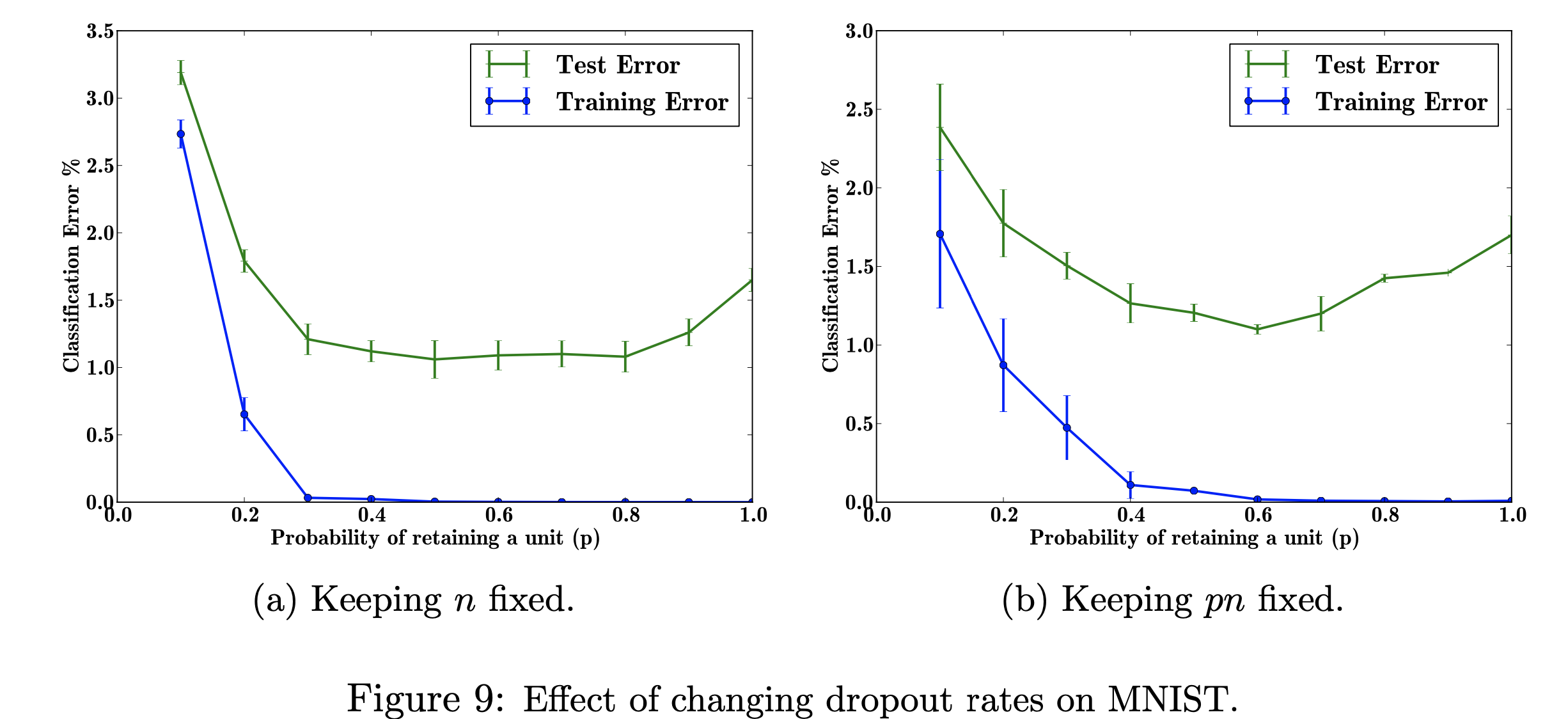 Gambar Dirujuk dari: Srivastava, N., Hinton, G.,Krizhevsky, A., Krizhevsky, I., Salakhutdinov, R., Dropout: Cara Sederhana untuk Mencegah Jaringan Neural Overfitting, Gambar 9
Gambar Dirujuk dari: Srivastava, N., Hinton, G.,Krizhevsky, A., Krizhevsky, I., Salakhutdinov, R., Dropout: Cara Sederhana untuk Mencegah Jaringan Neural Overfitting, Gambar 9
Saya menggunakan TensorFlow untuk menjalankan dropout pada kumpulan data MNIST, Matplotlib untuk membantu membuat ulang gambar di makalah. Saya juga menggunakan perpustakaan Desimal bawaan untuk menghitung nilai p yang berbeda, dari 0,0 hingga 1,0. Pustaka "csv" diimpor untuk menambahkan data yang dijalankan sebelumnya ke dalam file CSV, untuk menghemat waktu dalam penghitungan nilai p yang sudah dihitung. Numpy diimpor agar plotting memiliki ukuran langkah yang sama pada sumbu x dan y. Terakhir, saya mengimpor "os" sehingga saya dapat menghilangkan kesalahan karena menggunakan CPU daripada GPU.
Menjelajahi efek dari berbagai nilai hyperparameter 'p' yang dapat disetel (probabilitas mempertahankan unit dalam jaringan) dan jumlah lapisan tersembunyi, 'n', yang memengaruhi tingkat kesalahan. Ketika hasil kali p dan n tetap, kita dapat melihat bahwa besarnya kesalahan untuk nilai p yang kecil telah berkurang (gambar 9a) dibandingkan dengan menjaga jumlah lapisan tersembunyi tetap konstan (gambar 9b).
Dengan data pelatihan yang terbatas, banyak hubungan rumit antara input/output yang disebabkan oleh noise pengambilan sampel. Mereka akan ada di set pelatihan, tetapi tidak dalam data pengujian nyata meskipun diambil dari distribusi yang sama. Komplikasi ini menyebabkan overfitting, ini adalah salah satu algoritma untuk membantu mencegah terjadinya overfitting. Input untuk gambar ini adalah kumpulan data angka tulisan tangan, dan output setelah penambahan dropout adalah nilai berbeda yang menggambarkan hasil penerapan metode dropout. Secara keseluruhan, lebih sedikit kesalahan yang dihasilkan setelah menambahkan dropout.
Masalah dunia nyata yang dapat diterapkan adalah pencarian Google, seseorang mungkin mencari judul film tetapi mereka mungkin hanya mencari gambar karena mereka lebih pembelajar visual. Jadi menghilangkan bagian tekstual, atau penjelasan singkat akan membantu Anda fokus pada fitur gambar. Artikel tersebut menyatakan dari mana mereka mengambil data (http://yann.lecun.com/exdb/mnist/). Setiap gambar merupakan representasi 28x28 digit. Label y tampaknya merupakan kolom data gambar.
Tujuan saya mereproduksi angka ini adalah untuk menguji/melatih data dan menghitung kesalahan klasifikasi untuk setiap probabilitas p (probabilitas mempertahankan unit dalam jaringan). Tujuan saya adalah meningkatkan p seiring dengan turunnya kesalahan untuk menunjukkan bahwa implementasi saya valid, dan saya akan menyetel parameter hiper ini untuk mendapatkan hasil yang sama. Saya akan melakukan ini dengan mengulang semua data pelatihan dan pengujian menggunakan arsitektur 784-2048-2048-2048-10 dan menjaga n tetap lalu mengubah pn menjadi diperbaiki. Saya kemudian akan mengumpulkan/menulis data ke dalam file csv. File csv ini kemudian akan berisi semua data yang diperlukan untuk menampilkan angka. Dalam proyek ini, saya akan mempelajari bagaimana tingkat putus sekolah dapat bermanfaat bagi keseluruhan kesalahan dalam jaringan saraf.
Klik untuk Melihat


