Difusi Stabil dapat terwujud berkat kolaborasi dengan Stability AI dan Runway serta dikembangkan berdasarkan pekerjaan kami sebelumnya:
Sintesis Gambar Resolusi Tinggi dengan Model Difusi Laten
Robin Rombach*, Andreas Blattmann*, Dominik Lorenz, Patrick Esser, Björn Ommer
CVPR '22 Lisan | GitHub | arXiv | Halaman proyek
 Difusi Stabil adalah model difusi teks-ke-gambar yang laten. Berkat donasi komputasi yang melimpah dari Stability AI dan dukungan dari LAION, kami dapat melatih Model Difusi Laten pada gambar 512x512 dari subset database LAION-5B. Mirip dengan Imagen Google, model ini menggunakan encoder teks CLIP ViT-L/14 yang dibekukan untuk mengkondisikan model pada perintah teks. Dengan UNet 860M dan encoder teks 123M, model ini relatif ringan dan berjalan pada GPU dengan VRAM minimal 10GB. Lihat bagian di bawah ini dan kartu model.
Difusi Stabil adalah model difusi teks-ke-gambar yang laten. Berkat donasi komputasi yang melimpah dari Stability AI dan dukungan dari LAION, kami dapat melatih Model Difusi Laten pada gambar 512x512 dari subset database LAION-5B. Mirip dengan Imagen Google, model ini menggunakan encoder teks CLIP ViT-L/14 yang dibekukan untuk mengkondisikan model pada perintah teks. Dengan UNet 860M dan encoder teks 123M, model ini relatif ringan dan berjalan pada GPU dengan VRAM minimal 10GB. Lihat bagian di bawah ini dan kartu model.
Lingkungan conda yang sesuai bernama ldm dapat dibuat dan diaktifkan dengan:
conda env create -f environment.yaml
conda activate ldm
Anda juga dapat memperbarui lingkungan difusi laten yang ada dengan menjalankan
conda install pytorch torchvision -c pytorch
pip install transformers==4.19.2 diffusers invisible-watermark
pip install -e .
Difusi Stabil v1 mengacu pada konfigurasi spesifik arsitektur model yang menggunakan autoencoder faktor downsampling 8 dengan encoder teks UNet 860M dan CLIP ViT-L/14 untuk model difusi. Model telah dilatih sebelumnya pada gambar 256x256 dan kemudian disempurnakan pada gambar 512x512.
Catatan: Difusi Stabil v1 adalah model difusi teks-ke-gambar umum dan oleh karena itu mencerminkan bias dan (kesalahan) konsepsi yang ada dalam data pelatihannya. Detail tentang prosedur dan data pelatihan, serta tujuan penggunaan model dapat ditemukan di kartu model terkait.
Anak timbangan tersedia melalui organisasi CompVis di Hugging Face di bawah lisensi yang berisi pembatasan berbasis penggunaan khusus untuk mencegah penyalahgunaan dan bahaya sebagaimana diinformasikan dalam kartu model, namun tetap permisif. Meskipun penggunaan komersial diizinkan berdasarkan ketentuan lisensi, kami tidak menyarankan penggunaan anak timbangan yang disediakan untuk layanan atau produk tanpa mekanisme dan pertimbangan keselamatan tambahan , karena diketahui terdapat keterbatasan dan bias pada anak timbangan, serta penelitian tentang penerapan yang aman dan etis. model teks-ke-gambar secara umum merupakan upaya yang berkelanjutan. Bobotnya adalah artefak penelitian dan harus diperlakukan seperti itu.
Lisensi CreativeML OpenRAIL M adalah lisensi Open RAIL M, yang diadaptasi dari karya yang dilakukan bersama oleh BigScience dan RAIL Initiative di bidang lisensi AI yang bertanggung jawab. Lihat juga artikel tentang lisensi BLOOM Open RAIL yang menjadi dasar lisensi kami.
Saat ini kami menyediakan pos pemeriksaan berikut:
sd-v1-1.ckpt : 237k langkah pada resolusi 256x256 di laion2B-en. 194k langkah pada resolusi 512x512 pada laion-resolusi tinggi (170 juta contoh dari LAION-5B dengan resolusi >= 1024x1024 ).sd-v1-2.ckpt : Dilanjutkan dari sd-v1-1.ckpt . 515k langkah pada resolusi 512x512 pada laion-aesthetics v2 5+ (bagian dari laion2B-en dengan perkiraan skor estetika > 5.0 , dan juga difilter ke gambar dengan ukuran asli >= 512x512 , dan perkiraan probabilitas tanda air < 0.5 . Perkiraan tanda air berasal dari metadata LAION-5B, skor estetika diperkirakan menggunakan LAION-Aesthetics Predictor V2).sd-v1-3.ckpt : Dilanjutkan dari sd-v1-2.ckpt . 195 ribu langkah pada resolusi 512x512 pada "laion-aesthetics v2 5+" dan 10% penurunan pengkondisian teks untuk meningkatkan pengambilan sampel panduan bebas pengklasifikasi.sd-v1-4.ckpt : Dilanjutkan dari sd-v1-2.ckpt . 225 ribu langkah pada resolusi 512x512 pada "laion-aesthetics v2 5+" dan 10% penurunan pengkondisian teks untuk meningkatkan pengambilan sampel panduan bebas pengklasifikasi. Evaluasi dengan skala panduan bebas pengklasifikasi yang berbeda (1.5, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0) dan 50 langkah pengambilan sampel PLMS menunjukkan peningkatan relatif pada pos pemeriksaan: 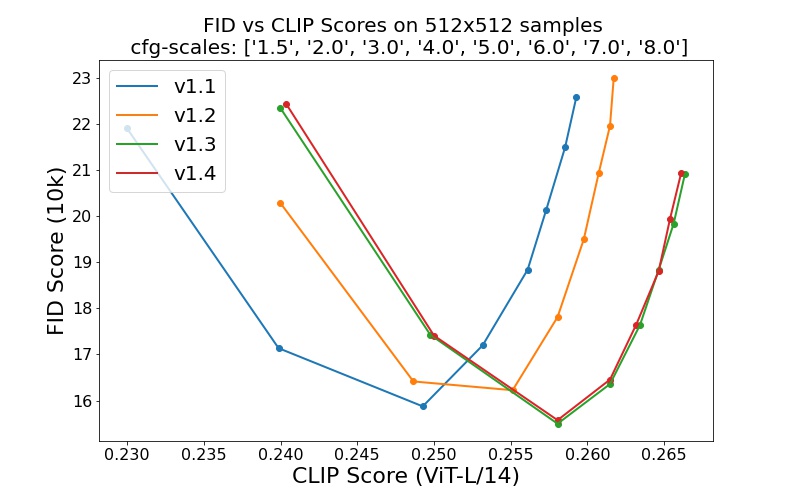


Difusi Stabil adalah model difusi laten yang dikondisikan pada penyematan teks (yang tidak dikumpulkan) dari pembuat enkode teks CLIP ViT-L/14. Kami menyediakan skrip referensi untuk pengambilan sampel, namun terdapat juga integrasi diffuser, yang kami harapkan akan menghasilkan pengembangan komunitas yang lebih aktif.
Kami menyediakan skrip pengambilan sampel referensi, yang mencakup
Setelah mendapatkan bobot stable-diffusion-v1-*-original , tautkan
mkdir -p models/ldm/stable-diffusion-v1/
ln -s <path/to/model.ckpt> models/ldm/stable-diffusion-v1/model.ckpt
dan sampel dengan
python scripts/txt2img.py --prompt "a photograph of an astronaut riding a horse" --plms
Secara default, ini menggunakan skala panduan --scale 7.5 , implementasi sampel PLMS Katherine Crowson, dan merender gambar berukuran 512x512 (tempat ia dilatih) dalam 50 langkah. Semua argumen yang didukung tercantum di bawah (ketik python scripts/txt2img.py --help ).
usage: txt2img.py [-h] [--prompt [PROMPT]] [--outdir [OUTDIR]] [--skip_grid] [--skip_save] [--ddim_steps DDIM_STEPS] [--plms] [--laion400m] [--fixed_code] [--ddim_eta DDIM_ETA]
[--n_iter N_ITER] [--H H] [--W W] [--C C] [--f F] [--n_samples N_SAMPLES] [--n_rows N_ROWS] [--scale SCALE] [--from-file FROM_FILE] [--config CONFIG] [--ckpt CKPT]
[--seed SEED] [--precision {full,autocast}]
optional arguments:
-h, --help show this help message and exit
--prompt [PROMPT] the prompt to render
--outdir [OUTDIR] dir to write results to
--skip_grid do not save a grid, only individual samples. Helpful when evaluating lots of samples
--skip_save do not save individual samples. For speed measurements.
--ddim_steps DDIM_STEPS
number of ddim sampling steps
--plms use plms sampling
--laion400m uses the LAION400M model
--fixed_code if enabled, uses the same starting code across samples
--ddim_eta DDIM_ETA ddim eta (eta=0.0 corresponds to deterministic sampling
--n_iter N_ITER sample this often
--H H image height, in pixel space
--W W image width, in pixel space
--C C latent channels
--f F downsampling factor
--n_samples N_SAMPLES
how many samples to produce for each given prompt. A.k.a. batch size
--n_rows N_ROWS rows in the grid (default: n_samples)
--scale SCALE unconditional guidance scale: eps = eps(x, empty) + scale * (eps(x, cond) - eps(x, empty))
--from-file FROM_FILE
if specified, load prompts from this file
--config CONFIG path to config which constructs model
--ckpt CKPT path to checkpoint of model
--seed SEED the seed (for reproducible sampling)
--precision {full,autocast}
evaluate at this precision
Catatan: Konfigurasi inferensi untuk semua versi v1 dirancang untuk digunakan dengan pos pemeriksaan khusus EMA. Karena alasan ini use_ema=False diatur dalam konfigurasi, jika tidak, kode akan mencoba beralih dari bobot non-EMA ke EMA. Jika Anda ingin menguji pengaruh EMA vs tanpa EMA, kami menyediakan pos pemeriksaan "lengkap" yang berisi kedua jenis bobot tersebut. Untuk ini, use_ema=False akan memuat dan menggunakan bobot non-EMA.
Cara sederhana untuk mengunduh dan mencicipi Difusi Stabil adalah dengan menggunakan perpustakaan diffuser:
# make sure you're logged in with `huggingface-cli login`
from torch import autocast
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline . from_pretrained (
"CompVis/stable-diffusion-v1-4" ,
use_auth_token = True
). to ( "cuda" )
prompt = "a photo of an astronaut riding a horse on mars"
with autocast ( "cuda" ):
image = pipe ( prompt )[ "sample" ][ 0 ]
image . save ( "astronaut_rides_horse.png" )Dengan menggunakan mekanisme difusi-denoising seperti yang pertama kali diusulkan oleh SDEdit, model ini dapat digunakan untuk berbagai tugas seperti terjemahan dan peningkatan gambar-ke-gambar dengan panduan teks. Mirip dengan skrip sampling txt2img, kami menyediakan skrip untuk melakukan modifikasi gambar dengan Difusi Stabil.
Berikut ini penjelasan contoh sketsa kasar yang dibuat di Pinta diubah menjadi karya seni detail.
python scripts/img2img.py --prompt "A fantasy landscape, trending on artstation" --init-img <path-to-img.jpg> --strength 0.8
Di sini, kekuatan adalah nilai antara 0,0 dan 1,0, yang mengontrol jumlah noise yang ditambahkan ke gambar masukan. Nilai yang mendekati 1.0 memungkinkan adanya banyak variasi tetapi juga akan menghasilkan gambar yang tidak konsisten secara semantik dengan masukan. Lihat contoh berikut.
Masukan

Keluaran


Prosedur ini, misalnya, juga dapat digunakan untuk meningkatkan sampel dari model dasar.
Basis kode kami untuk model difusi dibangun berdasarkan basis kode ADM OpenAI dan https://github.com/lucidrains/denoising-diffusion-pytorch. Terima kasih untuk sumber terbuka!
Implementasi encoder trafo berasal dari x-transformator oleh lucidrains.
@misc{rombach2021highresolution,
title={High-Resolution Image Synthesis with Latent Diffusion Models},
author={Robin Rombach and Andreas Blattmann and Dominik Lorenz and Patrick Esser and Björn Ommer},
year={2021},
eprint={2112.10752},
archivePrefix={arXiv},
primaryClass={cs.CV}
}


