Makalah Siswa Terbaik ACM MM'18
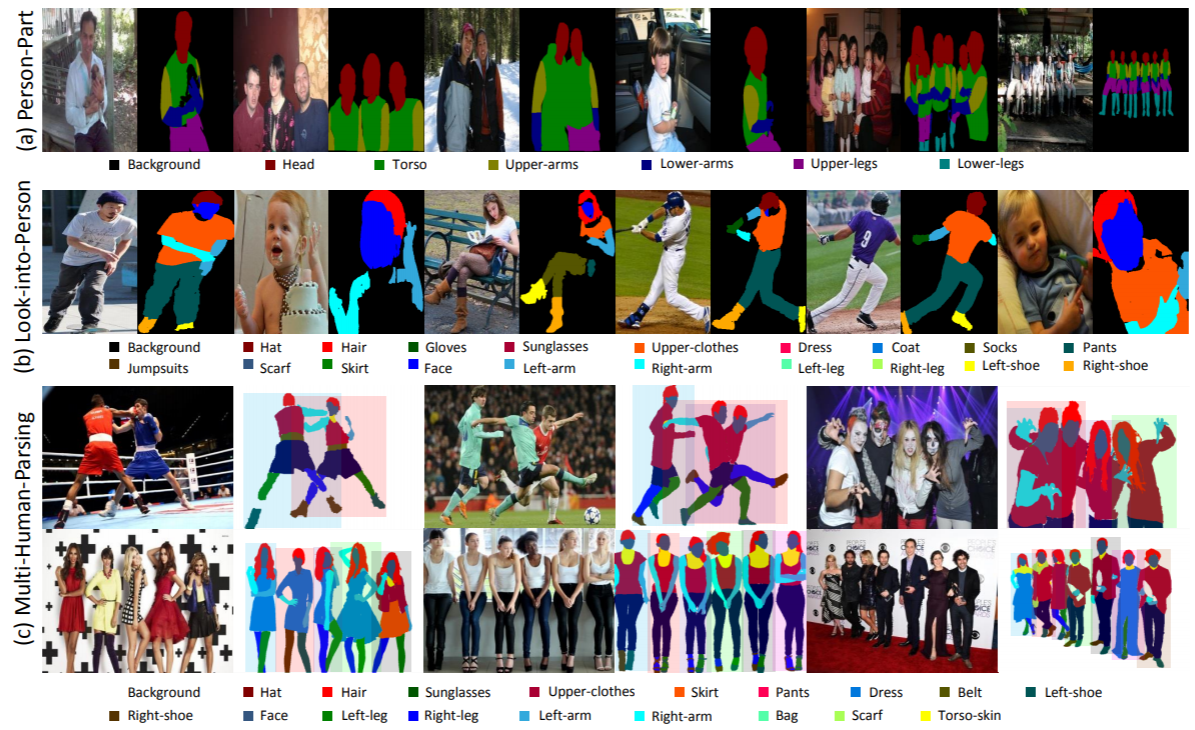
Proyek Multi-Human Parsing dari Learning and Vision (LV) Group, National University of Singapore (NUS) diusulkan untuk mendorong batas-batas pemahaman visual manusia yang mendetail dalam adegan keramaian.
Parsing Multi-Manusia sangat berbeda dari tugas pengenalan objek tradisional yang terdefinisi dengan baik, seperti deteksi objek, yang hanya memberikan prediksi tingkat kasar lokasi objek (kotak pembatas); segmentasi instance, yang hanya memprediksi topeng level instance tanpa informasi detail mengenai bagian tubuh dan kategori mode; penguraian manusia, yang beroperasi pada prediksi tingkat piksel tingkat kategori tanpa membedakan identitas yang berbeda.
Dalam skenario dunia nyata, setting beberapa orang dengan interaksi lebih realistis dan biasa. Oleh karena itu, diperlukan tugas, kumpulan data yang sesuai, dan metode dasar untuk mempertimbangkan informasi semantik terperinci dari setiap individu serta hubungan dan interaksi seluruh kelompok orang.
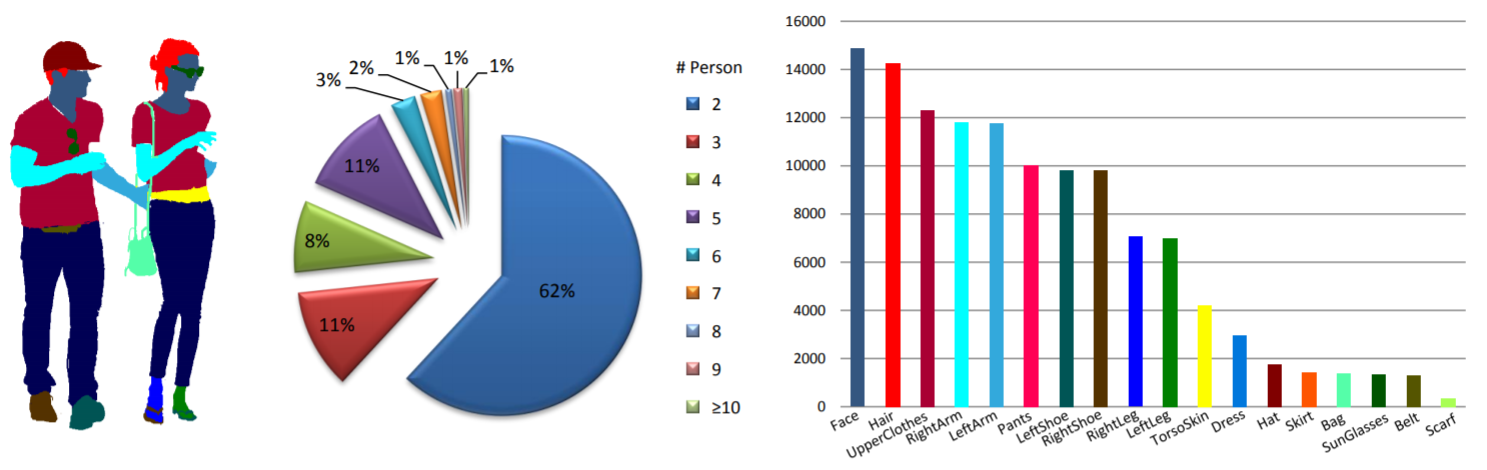
Statistik: Kumpulan data MHP v1.0 berisi 4.980 gambar, masing-masing berisi setidaknya dua orang (rata-rata 3). Kami secara acak memilih 980 gambar dan anotasi yang sesuai sebagai set pengujian. Sisanya berupa set pelatihan 3.000 gambar dan set validasi 1.000 gambar. Untuk setiap contoh, 18 kategori semantik didefinisikan dan diberi anotasi kecuali untuk kategori "latar belakang", yaitu “topi”, “rambut”, “kacamata hitam”, “pakaian atas”, “rok”, “celana”, “gaun”, “ ikat pinggang”, “sepatu kiri”, “sepatu kanan”, “wajah”, “kaki kiri”, “kaki kanan”, “lengan kiri”, “lengan kanan”, “tas”, “syal”, dan “kulit badan”. Setiap instance memiliki serangkaian anotasi lengkap setiap kali kategori terkait muncul di gambar saat ini.
Berita WeChat.
Download: Dataset MHP v1.0 tersedia di google drive dan baidu drive (password: cmtp).
Silakan merujuk ke makalah MHP v1.0 kami (dikirim ke IJCV) untuk lebih jelasnya.

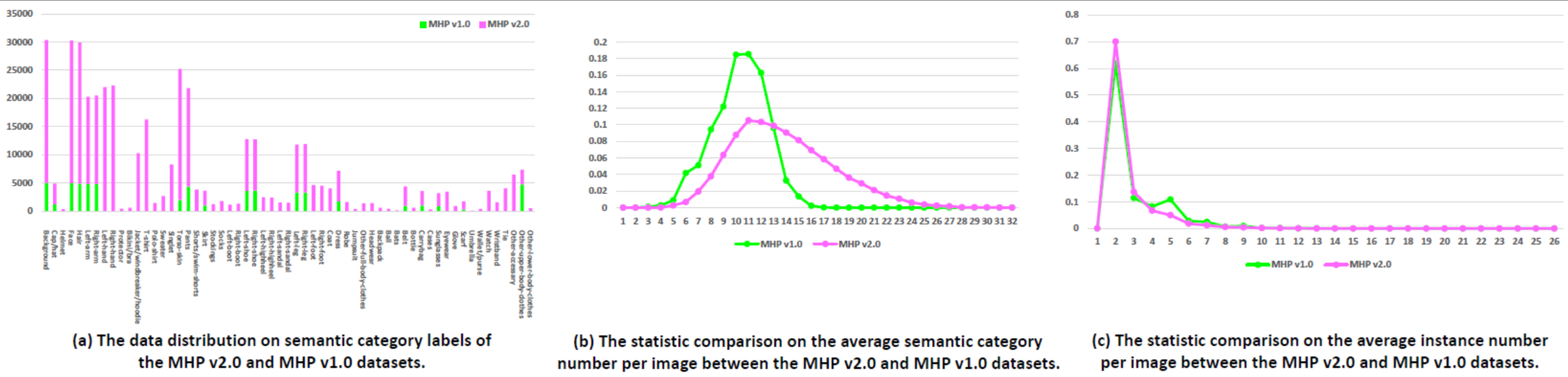

Statistik: Kumpulan data MHP v2.0 berisi 25.403 gambar, masing-masing berisi setidaknya dua orang (rata-rata 3). Kami secara acak memilih 5.000 gambar dan anotasi yang sesuai sebagai set pengujian. Sisanya berupa set pelatihan sebanyak 15.403 gambar dan set validasi sebanyak 5.000 gambar. Untuk setiap contoh, 58 kategori semantik ditentukan dan dianotasi kecuali untuk kategori "latar belakang", yaitu "topi/topi", "helm", "wajah", "rambut", "lengan kiri", "lengan kanan", "tangan kiri", "tangan kanan", "pelindung", "bikini/bra", "jaket/windbreaker/hoodie", "t-shirt", "polo-shirt", "sweater", "singlet", "kulit batang tubuh", "celana", "celana pendek/celana renang", "rok", "stoking", "kaus kaki", "sepatu bot kiri", "sepatu bot kanan", "sepatu kiri", "sepatu kanan", "hak tinggi kiri", "hak tinggi kanan", "sandal kiri", "sandal kanan", "kaki kiri", "kaki kanan", "kaki kiri", "kaki kanan", "mantel", "gaun", "jubah", "jumpsuit", "pakaian seluruh tubuh lainnya", "hiasan kepala", "ransel", "bola", "kelelawar", "ikat pinggang", "botol", "tas jinjing", "kotak", "kacamata hitam", "kacamata", "sarung tangan", "syal", "payung", "dompet/dompet", "jam tangan", "gelang", "dasi", "aksesori lain", "pakaian bagian atas lainnya" dan "pakaian bagian atas lainnya" dan "bagian bawah lainnya -pakaian badan". Setiap instance memiliki serangkaian anotasi lengkap setiap kali kategori terkait muncul di gambar saat ini. Selain itu, pose manusia 2D dengan 16 titik kunci padat ("bahu kanan", "siku kanan", "pergelangan tangan kanan", "bahu kiri", "siku kiri", "pergelangan tangan kiri", "kanan- pinggul", "lutut kanan", "pergelangan kaki kanan", "pinggul kiri", "lutut kiri", "pergelangan kaki kiri", "kepala", "leher", "tulang belakang" dan "panggul". Masing-masing titik kunci memiliki tanda yang menunjukkan apakah itu benar terlihat-0/tertutup-1/keluar-gambar-2) dan kotak pembatas kepala & instance juga disediakan untuk memfasilitasi penelitian Estimasi Pose Multi-Manusia.
Unduh: Dataset MHP v2.0 tersedia di google drive dan baidu drive (kata sandi: uxrb).
Silakan merujuk ke makalah MHP v2.0 kami (Makalah Siswa Terbaik ACM MM'18) untuk lebih jelasnya.
Parsing Multi-Manusia: Kami menggunakan dua metrik yang berpusat pada manusia untuk evaluasi parsing multi-manusia, yang awalnya dilaporkan oleh makalah MHP v1.0 kami. Kedua metrik tersebut adalah Presisi Rata-rata berdasarkan bagian (AP p ) (%) dan Persentase Bagian Semantik yang diurai dengan Benar (PCP) (%). Untuk kode evaluasi, silakan merujuk ke folder "Evaluasi" di bawah repositori "Multi-Human-Parsing_MHP" kami.
Estimasi Pose Multi-Manusia: Mengikuti MPII, kami menggunakan ukuran evaluasi mAP (%).
Kami telah menyelenggarakan Lokakarya CVPR 2018 tentang Pemahaman Visual Manusia dalam Crowd Scene (VUHCS 2018). Workshop ini bekerjasama dengan NUS, CMU dan SYSU. Berdasarkan VUHCS 2017, kami semakin memperkuat Lokakarya ini dengan menambahkan 5 jalur kompetisi: parsing manusia satu orang, parsing manusia multi-orang, estimasi pose satu orang, estimasi pose multi-manusia, dan fine- penguraian multi-manusia yang terperinci.
Pengiriman Hasil & Papan Peringkat.
Berita WeChat.
Silakan berkonsultasi dan pertimbangkan untuk mengutip makalah berikut:
@article{zhao2018understanding,
title={Understanding Humans in Crowded Scenes: Deep Nested Adversarial Learning and A New Benchmark for Multi-Human Parsing},
author={Zhao, Jian and Li, Jianshu and Cheng, Yu and Zhou, Li and Sim, Terence and Yan, Shuicheng and Feng, Jiashi},
journal={arXiv preprint arXiv:1804.03287},
year={2018}
}
@article{li2017towards,
title={Multi-Human Parsing in the Wild},
author={Li, Jianshu and Zhao, Jian and Wei, Yunchao and Lang, Congyan and Li, Yidong and Sim, Terence and Yan, Shuicheng and Feng, Jiashi},
journal={arXiv preprint arXiv:1705.07206},
year={2017}
}


