linformer pytorch
version
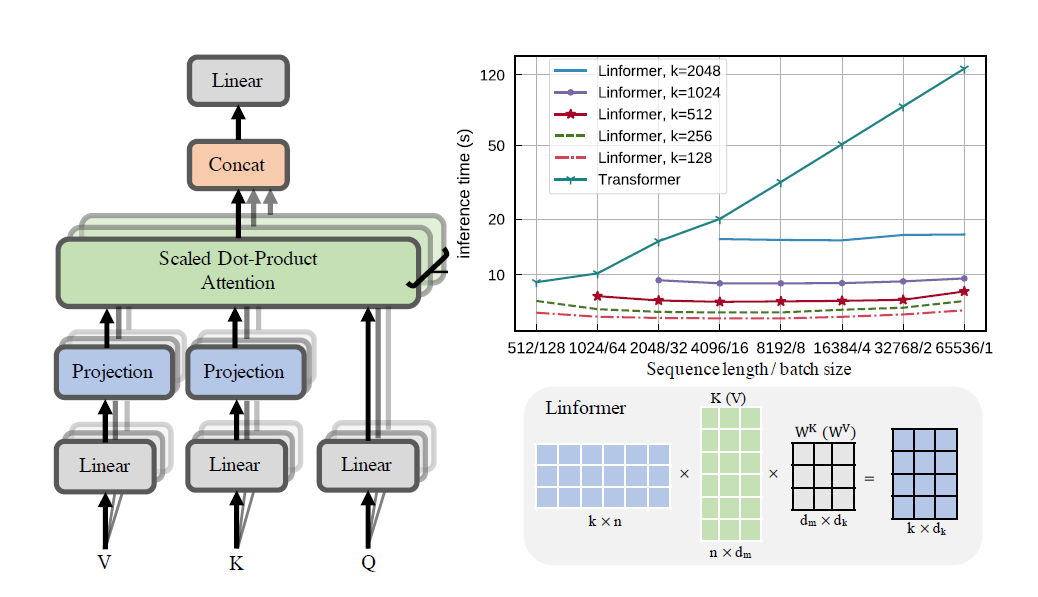
Implementasi praktis dari makalah Linformer. Ini adalah perhatian dengan hanya kompleksitas linier dalam n, yang memungkinkan panjang urutan yang sangat panjang (1mil+) untuk ditangani pada perangkat keras modern.
Repo ini adalah trafo gaya Perhatian Yang Anda Butuhkan, lengkap dengan modul encoder dan decoder. Yang baru di sini adalah sekarang, seseorang dapat membuat perhatian menjadi linier. Simak cara menggunakannya di bawah ini.
Ini sedang dalam proses validasi di wikitext-2. Saat ini, kinerjanya berada pada tingkat yang sama dengan mekanisme perhatian jarang lainnya, seperti Sinkhorn Transformer, tetapi hyperparameter terbaik masih harus ditemukan.
Visualisasi kepala juga dimungkinkan. Untuk melihat informasi lebih lanjut, lihat bagian Visualisasi di bawah.
Saya bukan penulis makalah ini.
1,23 juta token
pip install linformer-pytorch
Alternatifnya,
git clone https://github.com/tatp22/linformer-pytorch.git
cd linformer-pytorch
Model Bahasa Linformer
from linformer_pytorch import LinformerLM
import torch
model = LinformerLM (
num_tokens = 10000 , # Number of tokens in the LM
input_size = 512 , # Dimension 1 of the input
channels = 64 , # Dimension 2 of the input
dim_d = None , # Overwrites the inner dim of the attention heads. If None, sticks with the recommended channels // nhead, as in the "Attention is all you need" paper
dim_k = 128 , # The second dimension of the P_bar matrix from the paper
dim_ff = 128 , # Dimension in the feed forward network
dropout_ff = 0.15 , # Dropout for feed forward network
nhead = 4 , # Number of attention heads
depth = 2 , # How many times to run the model
dropout = 0.1 , # How much dropout to apply to P_bar after softmax
activation = "gelu" , # What activation to use. Currently, only gelu and relu supported, and only on ff network.
use_pos_emb = True , # Whether or not to use positional embeddings
checkpoint_level = "C0" , # What checkpoint level to use. For more information, see below.
parameter_sharing = "layerwise" , # What level of parameter sharing to use. For more information, see below.
k_reduce_by_layer = 0 , # Going down `depth`, how much to reduce `dim_k` by, for the `E` and `F` matrices. Will have a minimum value of 1.
full_attention = False , # Use full attention instead, for O(n^2) time and space complexity. Included here just for comparison
include_ff = True , # Whether or not to include the Feed Forward layer
w_o_intermediate_dim = None , # If not None, have 2 w_o matrices, such that instead of `dim*nead,channels`, you have `dim*nhead,w_o_int`, and `w_o_int,channels`
emb_dim = 128 , # If you want the embedding dimension to be different than the channels for the Linformer
causal = False , # If you want this to be a causal Linformer, where the upper right of the P_bar matrix is masked out.
method = "learnable" , # The method of how to perform the projection. Supported methods are 'convolution', 'learnable', and 'no_params'
ff_intermediate = None , # See the section below for more information
). cuda ()
x = torch . randint ( 1 , 10000 ,( 1 , 512 )). cuda ()
y = model ( x )
print ( y ) # (1, 512, 10000) Perhatian diri Linformer, tumpukan MHAttention dan FeedForward s
from linformer_pytorch import Linformer
import torch
model = Linformer (
input_size = 262144 , # Dimension 1 of the input
channels = 64 , # Dimension 2 of the input
dim_d = None , # Overwrites the inner dim of the attention heads. If None, sticks with the recommended channels // nhead, as in the "Attention is all you need" paper
dim_k = 128 , # The second dimension of the P_bar matrix from the paper
dim_ff = 128 , # Dimension in the feed forward network
dropout_ff = 0.15 , # Dropout for feed forward network
nhead = 4 , # Number of attention heads
depth = 2 , # How many times to run the model
dropout = 0.1 , # How much dropout to apply to P_bar after softmax
activation = "gelu" , # What activation to use. Currently, only gelu and relu supported, and only on ff network.
checkpoint_level = "C0" , # What checkpoint level to use. For more information, see below.
parameter_sharing = "layerwise" , # What level of parameter sharing to use. For more information, see below.
k_reduce_by_layer = 0 , # Going down `depth`, how much to reduce `dim_k` by, for the `E` and `F` matrices. Will have a minimum value of 1.
full_attention = False , # Use full attention instead, for O(n^2) time and space complexity. Included here just for comparison
include_ff = True , # Whether or not to include the Feed Forward layer
w_o_intermediate_dim = None , # If not None, have 2 w_o matrices, such that instead of `dim*nead,channels`, you have `dim*nhead,w_o_int`, and `w_o_int,channels`
). cuda ()
x = torch . randn ( 1 , 262144 , 64 ). cuda ()
y = model ( x )
print ( y ) # (1, 262144, 64)Perhatian Linformer Multihead
from linformer_pytorch import MHAttention
import torch
model = MHAttention (
input_size = 512 , # Dimension 1 of the input
channels = 64 , # Dimension 2 of the input
dim = 8 , # Dim of each attn head
dim_k = 128 , # What to sample the input length down to
nhead = 8 , # Number of heads
dropout = 0 , # Dropout for each of the heads
activation = "gelu" , # Activation after attention has been concat'd
checkpoint_level = "C2" , # If C2, checkpoint each of the heads
parameter_sharing = "layerwise" , # What level of parameter sharing to do
E_proj , F_proj , # The E and F projection matrices
full_attention = False , # Use full attention instead
w_o_intermediate_dim = None , # If not None, have 2 w_o matrices, such that instead of `dim*nead,channels`, you have `dim*nhead,w_o_int`, and `w_o_int,channels`
)
x = torch . randn ( 1 , 512 , 64 )
y = model ( x )
print ( y ) # (1, 512, 64)Kepala perhatian linier, kebaruan makalah
from linformer_pytorch import LinearAttentionHead
import torch
model = LinearAttentionHead (
dim = 64 , # Dim 2 of the input
dropout = 0.1 , # Dropout of the P matrix
E_proj , F_proj , # The E and F layers
full_attention = False , # Use Full Attention instead
)
x = torch . randn ( 1 , 512 , 64 )
y = model ( x , x , x )
print ( y ) # (1, 512, 64)Modul encoder/decoder.
Catatan: Untuk rangkaian sebab-akibat, seseorang dapat menyetel tanda causal=True di LinformerLM untuk menutupi bagian kanan atas matriks perhatian (n,k) .
import torch
from linformer_pytorch import LinformerLM
encoder = LinformerLM (
num_tokens = 10000 ,
input_size = 512 ,
channels = 16 ,
dim_k = 16 ,
dim_ff = 32 ,
nhead = 4 ,
depth = 3 ,
activation = "relu" ,
k_reduce_by_layer = 1 ,
return_emb = True ,
)
decoder = LinformerLM (
num_tokens = 10000 ,
input_size = 512 ,
channels = 16 ,
dim_k = 16 ,
dim_ff = 32 ,
nhead = 4 ,
depth = 3 ,
activation = "relu" ,
decoder_mode = True ,
)
x = torch . randint ( 1 , 10000 ,( 1 , 512 ))
y = torch . randint ( 1 , 10000 ,( 1 , 512 ))
x_mask = torch . ones_like ( x ). bool ()
y_mask = torch . ones_like ( y ). bool ()
enc_output = encoder ( x , input_mask = x_mask )
print ( enc_output . shape ) # (1, 512, 128)
dec_output = decoder ( y , embeddings = enc_output , input_mask = y_mask , embeddings_mask = x_mask )
print ( dec_output . shape ) # (1, 512, 10000) Cara mudah untuk mendapatkan matriks E dan F dapat dilakukan dengan memanggil fungsi get_EF . Sebagai contoh, untuk n dari 1000 dan k dari 100 :
from linfromer_pytorch import get_EF
import torch
E = get_EF ( 1000 , 100 ) Dengan tanda method , seseorang dapat mengatur metode yang dilakukan linformer untuk melakukan downsampling. Saat ini, tiga metode yang didukung:
learnable : Metode downsampling ini membuat modul n,k nn.Linear yang dapat dipelajari.convolution : Metode downsampling ini membuat konvolusi 1 hari, dengan panjang langkah dan ukuran kernel n/k .no_params : Ini membuat matriks n,k tetap dengan nilai dari N(0,1/k)Di masa depan, saya mungkin memasukkan pooling atau yang lainnya. Namun untuk saat ini, inilah pilihan yang ada.
Sebagai upaya untuk lebih memperkenalkan penghematan memori, konsep level pos pemeriksaan telah diperkenalkan. Tiga tingkat pos pemeriksaan saat ini adalah C0 , C1 , dan C2 . Saat menaikkan level pos pemeriksaan, seseorang mengorbankan kecepatan demi penghematan memori. Artinya, checkpoint level C0 adalah yang tercepat, namun memakan ruang paling banyak di GPU, sedangkan C2 adalah yang paling lambat, namun memakan ruang paling sedikit di GPU. Rincian masing-masing tingkat pos pemeriksaan adalah sebagai berikut:
C0 : Tidak ada pos pemeriksaan. Model-model tersebut berjalan dengan tetap menjaga semua perhatian utama dan lapisan ff di memori GPU.C1 : Periksa setiap perhatian MultiHead serta setiap lapisan ff. Dengan demikian, peningkatan depth akan berdampak minimal pada memori.C2 : Seiring dengan optimasi pada level C1 , periksa setiap head di setiap lapisan MultiHead Attention. Dengan ini, peningkatan nhead seharusnya berdampak lebih kecil pada memori. Namun, menggabungkan kepala dengan torch.cat masih memakan banyak memori, dan diharapkan hal ini dapat dioptimalkan di masa mendatang.Detail kinerjanya masih belum diketahui, tetapi ada opsi bagi pengguna yang ingin mencoba.
Upaya lain untuk memperkenalkan penghematan memori dalam makalah ini adalah dengan memperkenalkan pembagian parameter antar proyeksi. Hal ini disebutkan di bagian 4 makalah ini; Secara khusus, ada 4 jenis pembagian parameter yang penulis bahas, dan semuanya telah diterapkan di repo ini. Opsi pertama menggunakan paling banyak memori, dan setiap opsi selanjutnya mengurangi kebutuhan memori yang diperlukan.
none : Ini bukan pembagian parameter. Untuk setiap head dan setiap lapisan, matriks E baru dan matriks F baru dihitung untuk setiap head pada setiap lapisan.headwise : Setiap lapisan memiliki matriks E dan F yang unik. Semua kepala di lapisan berbagi matriks ini.kv : Setiap lapisan memiliki matriks proyeksi unik P , dan E = F = P untuk setiap lapisan. Semua kepala berbagi matriks proyeksi P .layerwise : Ada satu matriks proyeksi P , dan setiap kepala di setiap lapisan menggunakan E = F = P . Seperti yang dimulai di makalah, ini berarti bahwa untuk jaringan 12 lapisan, 12 kepala, masing-masing akan terdapat 288 , 24 , 12 dan 1 matriks proyeksi berbeda.
Perhatikan bahwa dengan opsi k_reduce_by_layer , opsi layerwise tidak akan efektif, karena akan menggunakan dimensi k untuk lapisan pertama. Oleh karena itu, jika nilai k_reduce_by_layer lebih besar dari 0 , kemungkinan besar seseorang tidak boleh menggunakan opsi berbagi layerwise .
Perlu diketahui juga bahwa menurut penulis, pada gambar 3, pembagian parameter ini tidak terlalu mempengaruhi hasil akhir. Jadi mungkin yang terbaik adalah tetap menggunakan berbagi layerwise untuk semuanya, tetapi ada opsi bagi pengguna untuk mencobanya.
Satu masalah kecil dengan implementasi Linformer saat ini adalah panjang urutan Anda harus cocok dengan flag input_size model. Padder memasukkan ukuran input sedemikian rupa sehingga tensor dapat dimasukkan ke dalam jaringan. Contoh:
from linformer_pytorch import Linformer , Padder
import torch
model = Linformer (
input_size = 512 ,
channels = 16 ,
dim_d = 32 ,
dim_k = 16 ,
dim_ff = 32 ,
nhead = 6 ,
depth = 3 ,
checkpoint_level = "C1" ,
)
model = Padder ( model )
x = torch . randn ( 1 , 500 , 16 ) # This does not match the input size!
y = model ( x )
print ( y ) # (1, 500, 16) 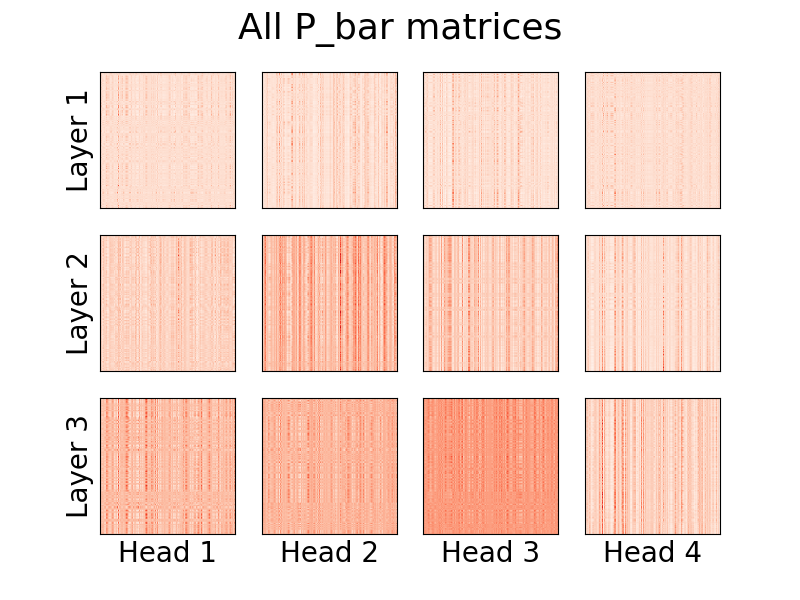
Dimulai dengan versi 0.8.0 , kini kita dapat memvisualisasikan kepala perhatian linformer! Untuk melihat cara kerjanya, cukup impor kelas Visualizer , dan jalankan fungsi plot_all_heads() untuk melihat gambar semua kepala perhatian di setiap tingkat, dengan ukuran (n,k). Pastikan Anda menentukan visualize=True di forward pass, karena ini menyimpan matriks P_bar sehingga kelas Visualizer dapat memvisualisasikan head dengan benar.
Contoh kode yang berfungsi dapat ditemukan di bawah, dan kode yang sama dapat ditemukan di ./examples/example_vis.py :
import torch
from linformer_pytorch import Linformer , Visualizer
model = Linformer (
input_size = 512 ,
channels = 16 ,
dim_k = 128 ,
dim_ff = 32 ,
nhead = 4 ,
depth = 3 ,
activation = "relu" ,
checkpoint_level = "C0" ,
parameter_sharing = "layerwise" ,
k_reduce_by_layer = 1 ,
)
# One can load the model weights here
x = torch . randn ( 1 , 512 , 16 ) # What input you want to visualize
y = model ( x , visualize = True )
vis = Visualizer ( model )
vis . plot_all_heads ( title = "All P_bar matrices" , # Change the title if you'd like
show = True , # Show the picture
save_file = "./heads.png" , # If not None, save the picture to a file
figsize = ( 8 , 6 ), # How big the figure should be
n_limit = None # If not None, limit how much from the `n` dimension to show
)Penjelasan rinci tentang arti kepala-kepala ini dapat ditemukan di #15.
Mirip dengan Reformator, saya akan mencoba membuat Modul Encoder/Decoder, agar pelatihannya bisa disederhanakan. Ini berfungsi seperti 2 kelas LinformerLM . Param dapat disesuaikan secara individual untuk masing-masing parameter, dengan encoder memiliki awalan enc_ untuk semua hyperparam, dan decoder memiliki awalan dec_ dengan cara yang sama. Sejauh ini yang sudah dilaksanakan adalah:
import torch
from linformer_pytorch import LinformerEncDec
encdec = LinformerEncDec (
enc_num_tokens = 10000 ,
enc_input_size = 512 ,
enc_channels = 16 ,
dec_num_tokens = 10000 ,
dec_input_size = 512 ,
dec_channels = 16 ,
)
x = torch . randint ( 1 , 10000 ,( 1 , 512 ))
y = torch . randint ( 1 , 10000 ,( 1 , 512 ))
output = encdec ( x , y )Saya berencana memiliki cara untuk menghasilkan urutan teks untuk ini.
ff_intermediate Sekarang, dimensi model bisa berbeda di lapisan perantara. Perubahan ini berlaku pada modul ff, dan hanya pada bagian encoder saja. Sekarang, jika flag ff_intermediate bukan None, layernya akan terlihat seperti ini:
channels -> ff_dim -> ff_intermediate (For layer 1)
ff_intermediate -> ff_dim -> ff_intermediate (For layers 2 to depth-1)
ff_intermediate -> ff_dim -> channels (For layer depth)
Berbeda dengan
channels -> ff_dim -> channels (For all layers)
input_size dan dim_k , masing-masing.apex harus bekerja dengan ini, namun dalam praktiknya, belum diuji.input_size , k= dim_k , dan d= dim_d . LinformerEncDec Ini adalah pertama kalinya saya mereproduksi hasil dari sebuah makalah, jadi ada beberapa hal yang mungkin salah. Jika Anda melihat masalah, silakan buka masalahnya, dan saya akan mencoba mengatasinya.
Terima kasih kepada lucidrains, yang repositorinya yang jarang mendapat perhatian membantu saya merancang Repo Linformer ini.
@misc { wang2020linformer ,
title = { Linformer: Self-Attention with Linear Complexity } ,
author = { Sinong Wang and Belinda Z. Li and Madian Khabsa and Han Fang and Hao Ma } ,
year = { 2020 } ,
eprint = { 2006.04768 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @inproceedings { vaswani2017attention ,
title = { Attention is all you need } ,
author = { Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, {L}ukasz and Polosukhin, Illia } ,
booktitle = { Advances in neural information processing systems } ,
pages = { 5998--6008 } ,
year = { 2017 }
}"Dengarkan dengan penuh perhatian..."


