vit pytorch
1.9.1
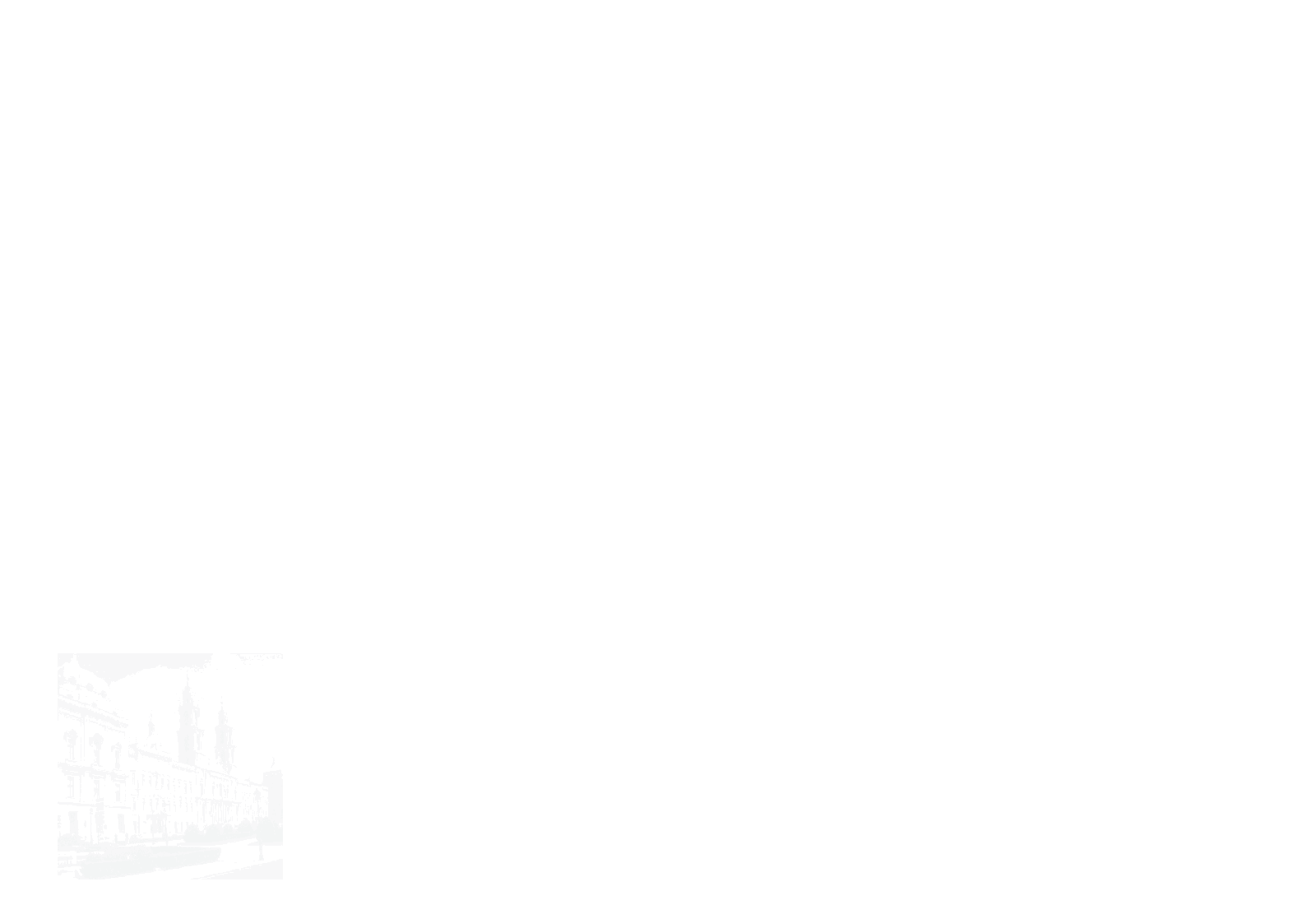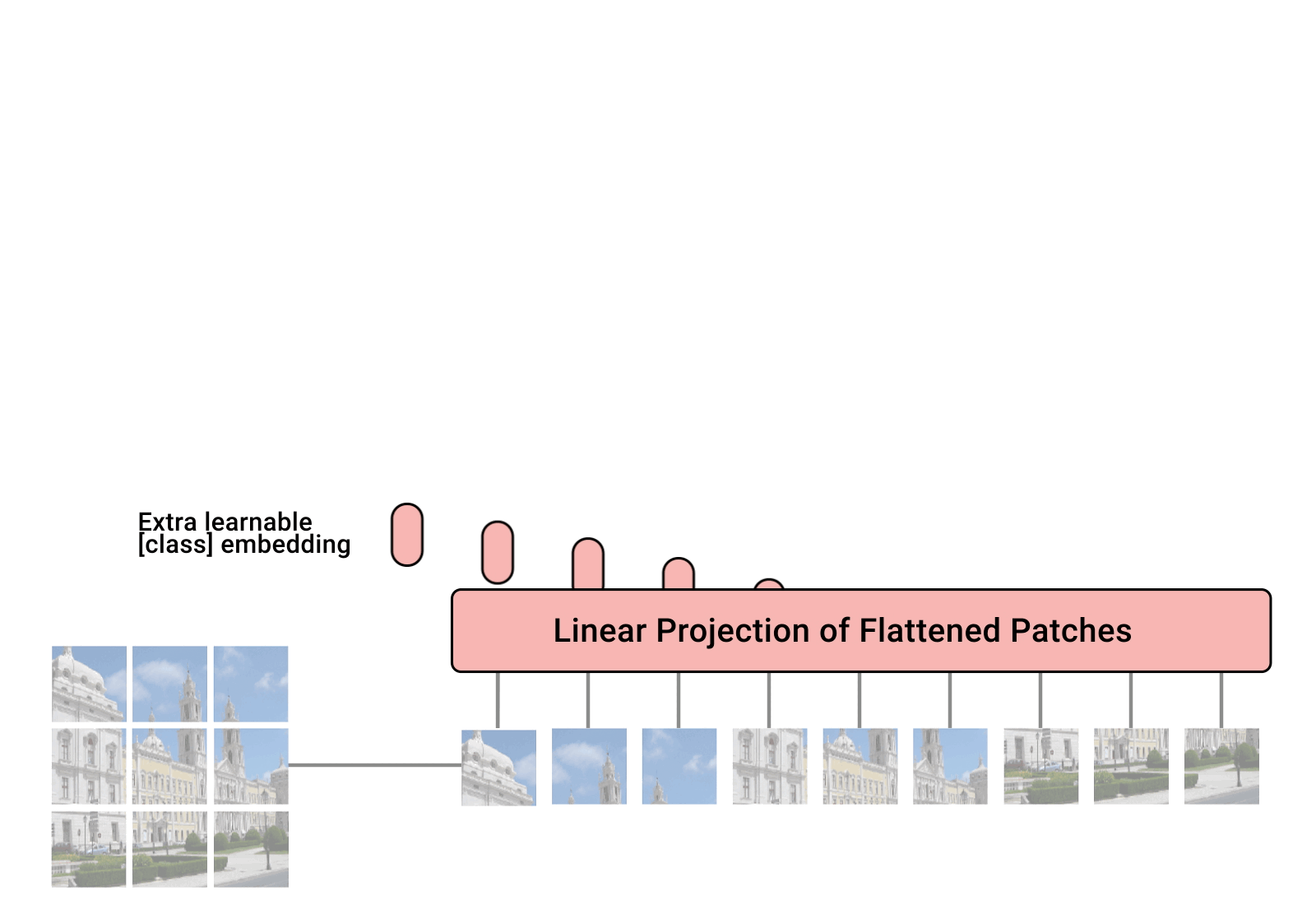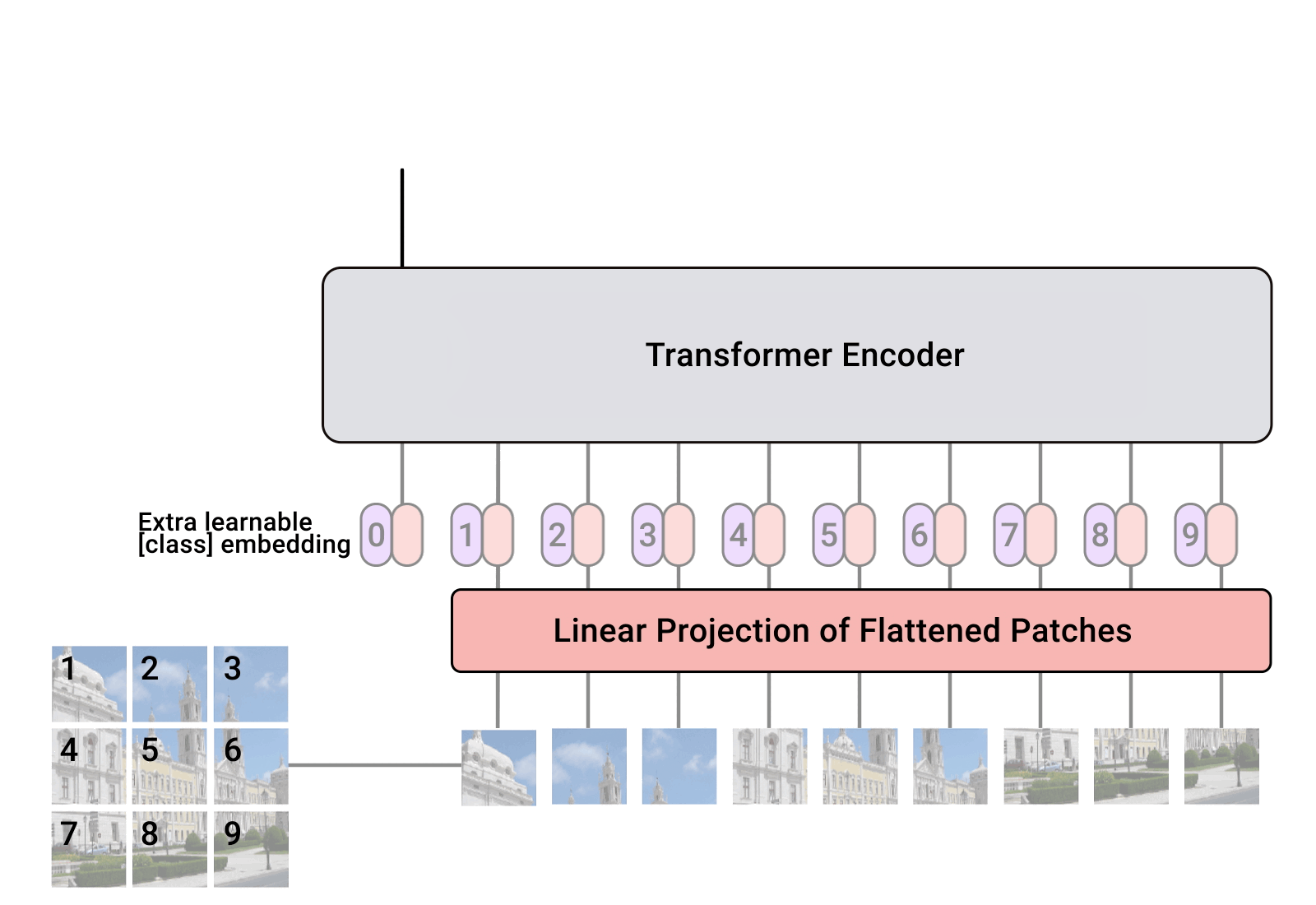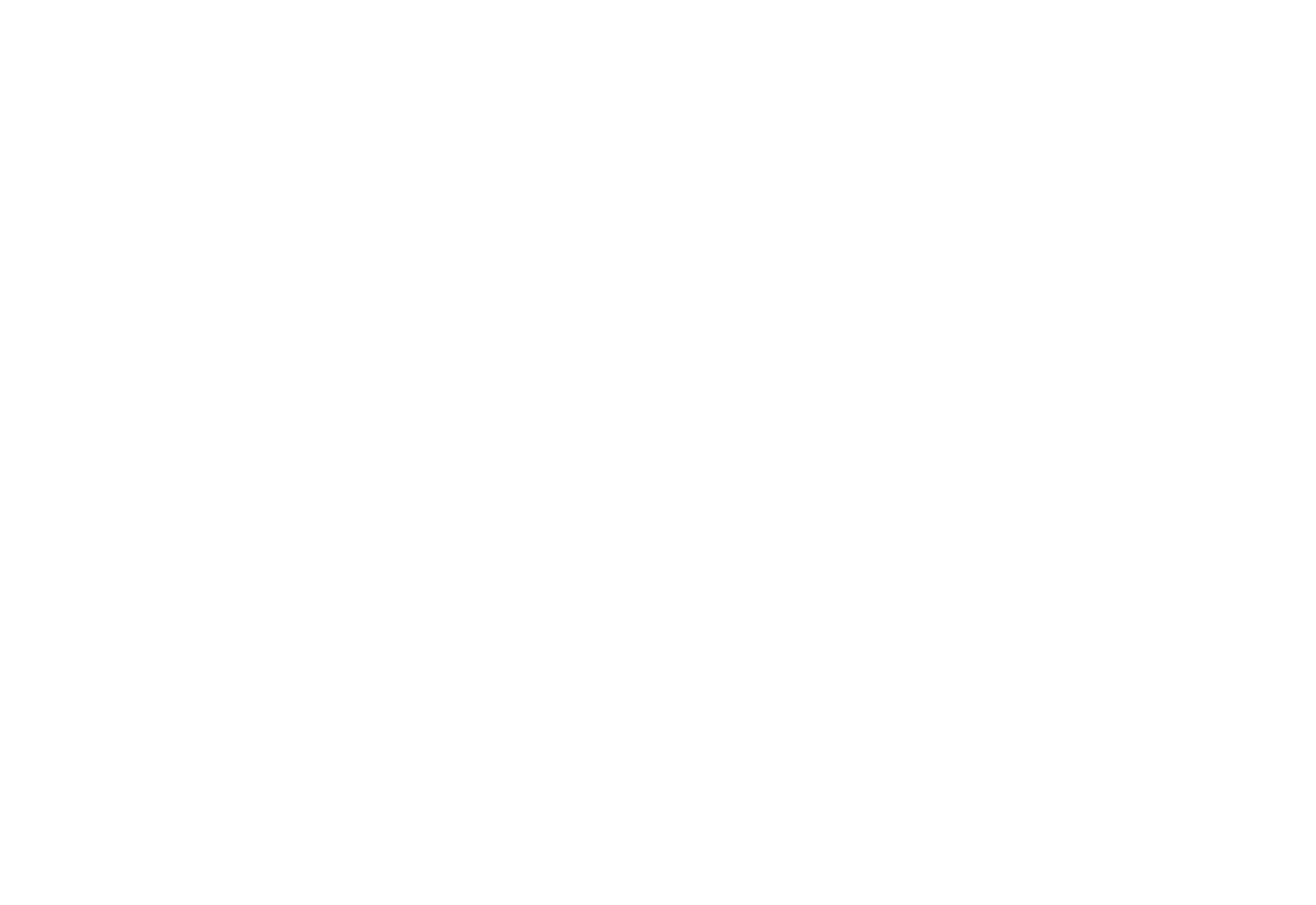
Implementasi Vision Transformer, cara sederhana untuk mencapai SOTA dalam klasifikasi vision hanya dengan satu encoder transformator, di Pytorch. Signifikansinya dijelaskan lebih lanjut dalam video Yannic Kilcher. Sebenarnya tidak banyak yang perlu dikodekan di sini, tapi sebaiknya jelaskan kepada semua orang sehingga kami mempercepat revolusi perhatian.
Untuk implementasi Pytorch dengan model terlatih, silakan lihat repositori Ross Wightman di sini.
Repositori resmi Jax ada di sini.
Terjemahan tensorflow2 juga ada di sini, dibuat oleh ilmuwan riset Junho Kim!
Terjemahan rami oleh Enrico Shippole!
$ pip install vit-pytorch import torch
from vit_pytorch import ViT
v = ViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
img = torch . randn ( 1 , 3 , 256 , 256 )
preds = v ( img ) # (1, 1000) image_size : int.patch_size : int.image_size harus habis dibagi patch_size .n = (image_size // patch_size) ** 2 dan n harus lebih besar dari 16 .num_classes : int.dim : int.nn.Linear(..., dim) .depth : int.heads : int.mlp_dim : int.channels : int, default 3 .dropout : mengambang di antara [0, 1] , default 0. .emb_dropout : melayang di antara [0, 1] , default 0 .pool : string, baik cls token pooling atau mean pooling Pembaruan dari beberapa penulis makalah asli yang sama mengusulkan penyederhanaan ViT yang memungkinkannya berlatih lebih cepat dan lebih baik.
Penyederhanaan ini mencakup penyematan posisi sinusoidal 2d, pengumpulan rata-rata global (tanpa token CLS), tidak ada dropout, ukuran batch 1024, bukan 4096, dan penggunaan augmentasi RandAugment dan MixUp. Mereka juga menunjukkan bahwa linear sederhana pada akhirnya tidak jauh lebih buruk daripada kepala MLP asli
Anda dapat menggunakannya dengan mengimpor SimpleViT seperti yang ditunjukkan di bawah ini
import torch
from vit_pytorch import SimpleViT
v = SimpleViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 16 ,
mlp_dim = 2048
)
img = torch . randn ( 1 , 3 , 256 , 256 )
preds = v ( img ) # (1, 1000) 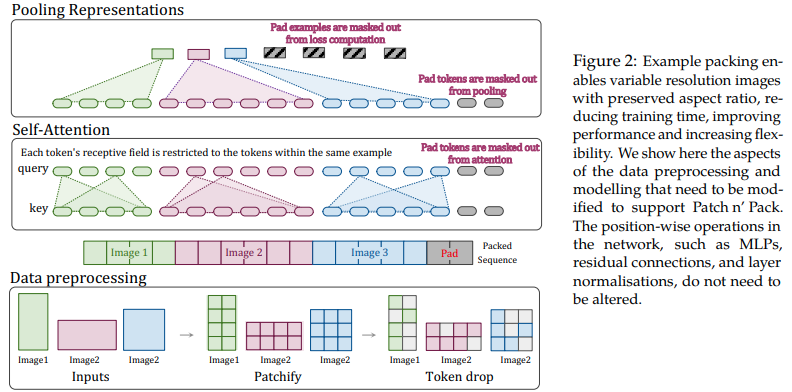
Makalah ini mengusulkan untuk memanfaatkan fleksibilitas perhatian dan penyembunyian untuk rangkaian panjang variabel untuk melatih gambar dengan berbagai resolusi, dikemas ke dalam satu kumpulan. Mereka mendemonstrasikan pelatihan yang jauh lebih cepat dan peningkatan akurasi, dengan satu-satunya biaya yang harus ditanggung adalah kompleksitas tambahan dalam arsitektur dan pemuatan data. Mereka menggunakan pengkodean posisi 2d yang difaktorkan, pelepasan token, serta normalisasi kunci kueri.
Anda dapat menggunakannya sebagai berikut
import torch
from vit_pytorch . na_vit import NaViT
v = NaViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1 ,
token_dropout_prob = 0.1 # token dropout of 10% (keep 90% of tokens)
)
# 5 images of different resolutions - List[List[Tensor]]
# for now, you'll have to correctly place images in same batch element as to not exceed maximum allowed sequence length for self-attention w/ masking
images = [
[ torch . randn ( 3 , 256 , 256 ), torch . randn ( 3 , 128 , 128 )],
[ torch . randn ( 3 , 128 , 256 ), torch . randn ( 3 , 256 , 128 )],
[ torch . randn ( 3 , 64 , 256 )]
]
preds = v ( images ) # (5, 1000) - 5, because 5 images of different resolution aboveAtau jika Anda lebih suka kerangka mengelompokkan gambar secara otomatis ke dalam urutan panjang variabel yang tidak melebihi panjang maksimal tertentu
images = [
torch . randn ( 3 , 256 , 256 ),
torch . randn ( 3 , 128 , 128 ),
torch . randn ( 3 , 128 , 256 ),
torch . randn ( 3 , 256 , 128 ),
torch . randn ( 3 , 64 , 256 )
]
preds = v (
images ,
group_images = True ,
group_max_seq_len = 64
) # (5, 1000) Terakhir, jika Anda ingin menggunakan varian NaViT menggunakan tensor bersarang (yang akan menghilangkan banyak masking dan padding sama sekali), pastikan Anda menggunakan versi 2.5 dan impor sebagai berikut
import torch
from vit_pytorch . na_vit_nested_tensor import NaViT
v = NaViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0. ,
emb_dropout = 0. ,
token_dropout_prob = 0.1
)
# 5 images of different resolutions - List[Tensor]
images = [
torch . randn ( 3 , 256 , 256 ), torch . randn ( 3 , 128 , 128 ),
torch . randn ( 3 , 128 , 256 ), torch . randn ( 3 , 256 , 128 ),
torch . randn ( 3 , 64 , 256 )
]
preds = v ( images )
assert preds . shape == ( 5 , 1000 )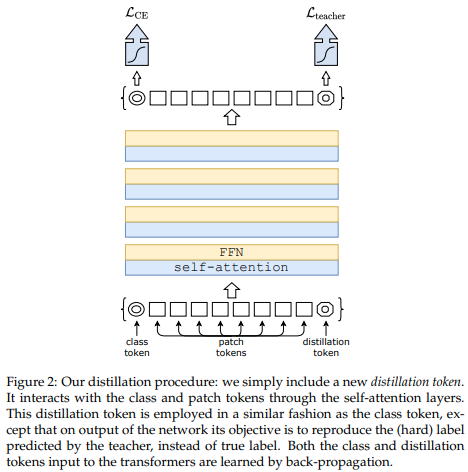
Sebuah makalah baru-baru ini menunjukkan bahwa penggunaan token distilasi untuk menyaring pengetahuan dari jaringan konvolusional ke transformator visi dapat menghasilkan transformator visi yang kecil dan efisien. Repositori ini menawarkan sarana untuk melakukan distilasi dengan mudah.
mantan. penyulingan dari Resnet50 (atau guru mana pun) ke transformator visi
import torch
from torchvision . models import resnet50
from vit_pytorch . distill import DistillableViT , DistillWrapper
teacher = resnet50 ( pretrained = True )
v = DistillableViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 8 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
distiller = DistillWrapper (
student = v ,
teacher = teacher ,
temperature = 3 , # temperature of distillation
alpha = 0.5 , # trade between main loss and distillation loss
hard = False # whether to use soft or hard distillation
)
img = torch . randn ( 2 , 3 , 256 , 256 )
labels = torch . randint ( 0 , 1000 , ( 2 ,))
loss = distiller ( img , labels )
loss . backward ()
# after lots of training above ...
pred = v ( img ) # (2, 1000) Kelas DistillableViT identik dengan ViT kecuali cara penanganan forward pass, jadi Anda seharusnya dapat memuat parameter kembali ke ViT setelah Anda menyelesaikan pelatihan distilasi.
Anda juga dapat menggunakan metode .to_vit yang praktis pada instans DistillableViT untuk mendapatkan kembali instans ViT .
v = v . to_vit ()
type ( v ) # <class 'vit_pytorch.vit_pytorch.ViT'> Makalah ini mencatat bahwa ViT kesulitan untuk memperhatikan pada kedalaman yang lebih dalam (melewati 12 lapisan), dan menyarankan untuk menggabungkan perhatian setiap kepala pasca-softmax sebagai solusi, yang disebut Re-attention. Hasilnya sejalan dengan makalah Talking Heads dari NLP.
Anda dapat menggunakannya sebagai berikut
import torch
from vit_pytorch . deepvit import DeepViT
v = DeepViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
img = torch . randn ( 1 , 3 , 256 , 256 )
preds = v ( img ) # (1, 1000) Makalah ini juga mencatat kesulitan dalam melatih transformator visi secara lebih mendalam dan mengusulkan dua solusi. Pertama, ia mengusulkan untuk melakukan perkalian per saluran dari keluaran blok sisa. Kedua, ia mengusulkan agar patch-patch tersebut saling memperhatikan satu sama lain, dan hanya mengizinkan token CLS untuk menangani patch-patch di beberapa lapisan terakhir.
Mereka juga menambahkan Talking Heads, mencatat peningkatan
Anda dapat menggunakan skema ini sebagai berikut
import torch
from vit_pytorch . cait import CaiT
v = CaiT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 12 , # depth of transformer for patch to patch attention only
cls_depth = 2 , # depth of cross attention of CLS tokens to patch
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1 ,
layer_dropout = 0.05 # randomly dropout 5% of the layers
)
img = torch . randn ( 1 , 3 , 256 , 256 )
preds = v ( img ) # (1, 1000) 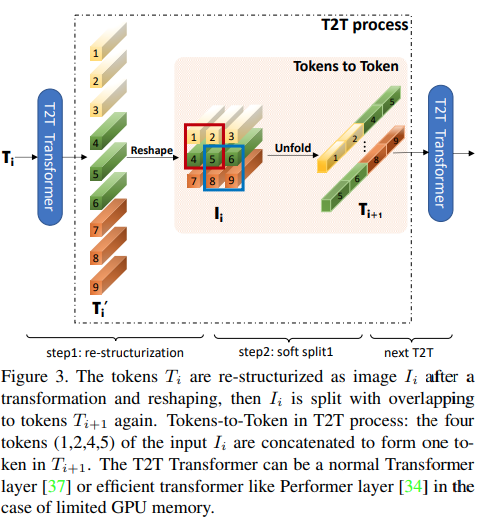
Makalah ini mengusulkan bahwa beberapa lapisan pertama harus menurunkan sampel urutan gambar dengan membuka lipatannya, sehingga menyebabkan data gambar yang tumpang tindih di setiap token seperti yang ditunjukkan pada gambar di atas. Anda dapat menggunakan varian ViT ini sebagai berikut.
import torch
from vit_pytorch . t2t import T2TViT
v = T2TViT (
dim = 512 ,
image_size = 224 ,
depth = 5 ,
heads = 8 ,
mlp_dim = 512 ,
num_classes = 1000 ,
t2t_layers = (( 7 , 4 ), ( 3 , 2 ), ( 3 , 2 )) # tuples of the kernel size and stride of each consecutive layers of the initial token to token module
)
img = torch . randn ( 1 , 3 , 224 , 224 )
preds = v ( img ) # (1, 1000) CCT mengusulkan transformator kompak dengan menggunakan konvolusi alih-alih menambal dan melakukan pengumpulan urutan. Hal ini memungkinkan CCT memiliki akurasi tinggi dan jumlah parameter yang rendah.
Anda dapat menggunakan ini dengan dua metode
import torch
from vit_pytorch . cct import CCT
cct = CCT (
img_size = ( 224 , 448 ),
embedding_dim = 384 ,
n_conv_layers = 2 ,
kernel_size = 7 ,
stride = 2 ,
padding = 3 ,
pooling_kernel_size = 3 ,
pooling_stride = 2 ,
pooling_padding = 1 ,
num_layers = 14 ,
num_heads = 6 ,
mlp_ratio = 3. ,
num_classes = 1000 ,
positional_embedding = 'learnable' , # ['sine', 'learnable', 'none']
)
img = torch . randn ( 1 , 3 , 224 , 448 )
pred = cct ( img ) # (1, 1000) Alternatifnya, Anda dapat menggunakan salah satu dari beberapa model yang telah ditentukan sebelumnya [2,4,6,7,8,14,16] yang telah menentukan terlebih dahulu jumlah lapisan, jumlah kepala perhatian, rasio mlp, dan dimensi penyematan.
import torch
from vit_pytorch . cct import cct_14
cct = cct_14 (
img_size = 224 ,
n_conv_layers = 1 ,
kernel_size = 7 ,
stride = 2 ,
padding = 3 ,
pooling_kernel_size = 3 ,
pooling_stride = 2 ,
pooling_padding = 1 ,
num_classes = 1000 ,
positional_embedding = 'learnable' , # ['sine', 'learnable', 'none']
)Repositori Resmi menyertakan tautan ke pos pemeriksaan model yang telah dilatih sebelumnya.
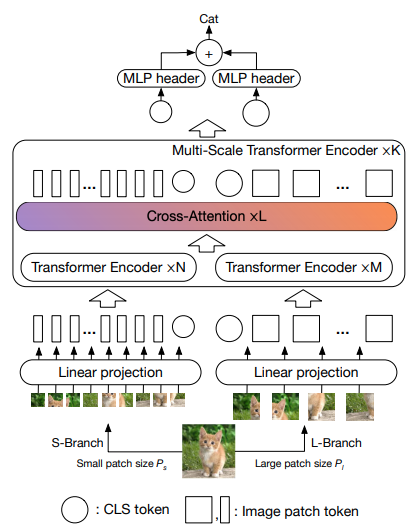
Makalah ini mengusulkan untuk memiliki dua transformator visi yang memproses gambar pada skala yang berbeda, dan sering kali saling bersilangan. Mereka menunjukkan peningkatan pada transformator visi dasar.
import torch
from vit_pytorch . cross_vit import CrossViT
v = CrossViT (
image_size = 256 ,
num_classes = 1000 ,
depth = 4 , # number of multi-scale encoding blocks
sm_dim = 192 , # high res dimension
sm_patch_size = 16 , # high res patch size (should be smaller than lg_patch_size)
sm_enc_depth = 2 , # high res depth
sm_enc_heads = 8 , # high res heads
sm_enc_mlp_dim = 2048 , # high res feedforward dimension
lg_dim = 384 , # low res dimension
lg_patch_size = 64 , # low res patch size
lg_enc_depth = 3 , # low res depth
lg_enc_heads = 8 , # low res heads
lg_enc_mlp_dim = 2048 , # low res feedforward dimensions
cross_attn_depth = 2 , # cross attention rounds
cross_attn_heads = 8 , # cross attention heads
dropout = 0.1 ,
emb_dropout = 0.1
)
img = torch . randn ( 1 , 3 , 256 , 256 )
pred = v ( img ) # (1, 1000) 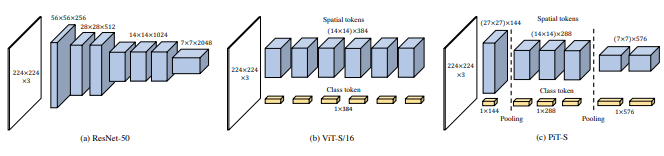
Makalah ini mengusulkan untuk menurunkan sampel token melalui prosedur pengumpulan menggunakan konvolusi yang mendalam.
import torch
from vit_pytorch . pit import PiT
v = PiT (
image_size = 224 ,
patch_size = 14 ,
dim = 256 ,
num_classes = 1000 ,
depth = ( 3 , 3 , 3 ), # list of depths, indicating the number of rounds of each stage before a downsample
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
# forward pass now returns predictions and the attention maps
img = torch . randn ( 1 , 3 , 224 , 224 )
preds = v ( img ) # (1, 1000) 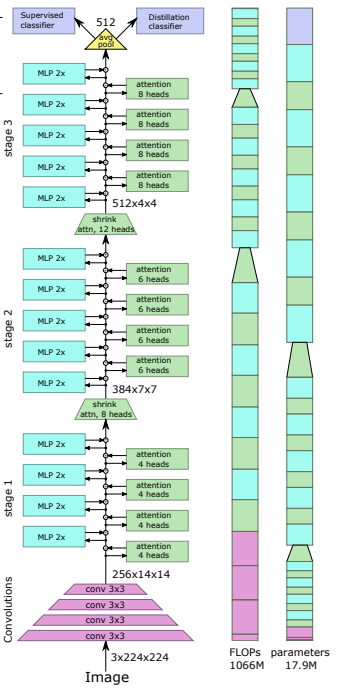
Makalah ini mengusulkan sejumlah perubahan, termasuk (1) penyematan konvolusional alih-alih proyeksi patch-wise (2) downsampling secara bertahap (3) non-linearitas ekstra dalam perhatian (4) bias posisi relatif 2d alih-alih bias posisi absolut awal (5 ) batchnorm menggantikan layernorm.
Repositori resmi
import torch
from vit_pytorch . levit import LeViT
levit = LeViT (
image_size = 224 ,
num_classes = 1000 ,
stages = 3 , # number of stages
dim = ( 256 , 384 , 512 ), # dimensions at each stage
depth = 4 , # transformer of depth 4 at each stage
heads = ( 4 , 6 , 8 ), # heads at each stage
mlp_mult = 2 ,
dropout = 0.1
)
img = torch . randn ( 1 , 3 , 224 , 224 )
levit ( img ) # (1, 1000) 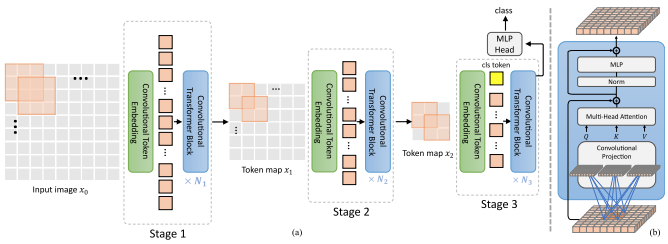
Makalah ini mengusulkan pencampuran konvolusi dan perhatian. Secara khusus, konvolusi digunakan untuk menyematkan dan menurunkan sampel peta gambar/fitur dalam tiga tahap. Konvolusi mendalam juga digunakan untuk memproyeksikan kueri, kunci, dan nilai untuk diperhatikan.
import torch
from vit_pytorch . cvt import CvT
v = CvT (
num_classes = 1000 ,
s1_emb_dim = 64 , # stage 1 - dimension
s1_emb_kernel = 7 , # stage 1 - conv kernel
s1_emb_stride = 4 , # stage 1 - conv stride
s1_proj_kernel = 3 , # stage 1 - attention ds-conv kernel size
s1_kv_proj_stride = 2 , # stage 1 - attention key / value projection stride
s1_heads = 1 , # stage 1 - heads
s1_depth = 1 , # stage 1 - depth
s1_mlp_mult = 4 , # stage 1 - feedforward expansion factor
s2_emb_dim = 192 , # stage 2 - (same as above)
s2_emb_kernel = 3 ,
s2_emb_stride = 2 ,
s2_proj_kernel = 3 ,
s2_kv_proj_stride = 2 ,
s2_heads = 3 ,
s2_depth = 2 ,
s2_mlp_mult = 4 ,
s3_emb_dim = 384 , # stage 3 - (same as above)
s3_emb_kernel = 3 ,
s3_emb_stride = 2 ,
s3_proj_kernel = 3 ,
s3_kv_proj_stride = 2 ,
s3_heads = 4 ,
s3_depth = 10 ,
s3_mlp_mult = 4 ,
dropout = 0.
)
img = torch . randn ( 1 , 3 , 224 , 224 )
pred = v ( img ) # (1, 1000) 
Makalah ini mengusulkan penggabungan perhatian lokal dan global, bersama dengan generator pengkodean posisi (diusulkan dalam CPVT) dan pengumpulan rata-rata global, untuk mencapai hasil yang sama seperti Swin, tanpa kompleksitas tambahan dari jendela yang bergeser, token CLS, atau penyematan posisi.
import torch
from vit_pytorch . twins_svt import TwinsSVT
model = TwinsSVT (
num_classes = 1000 , # number of output classes
s1_emb_dim = 64 , # stage 1 - patch embedding projected dimension
s1_patch_size = 4 , # stage 1 - patch size for patch embedding
s1_local_patch_size = 7 , # stage 1 - patch size for local attention
s1_global_k = 7 , # stage 1 - global attention key / value reduction factor, defaults to 7 as specified in paper
s1_depth = 1 , # stage 1 - number of transformer blocks (local attn -> ff -> global attn -> ff)
s2_emb_dim = 128 , # stage 2 (same as above)
s2_patch_size = 2 ,
s2_local_patch_size = 7 ,
s2_global_k = 7 ,
s2_depth = 1 ,
s3_emb_dim = 256 , # stage 3 (same as above)
s3_patch_size = 2 ,
s3_local_patch_size = 7 ,
s3_global_k = 7 ,
s3_depth = 5 ,
s4_emb_dim = 512 , # stage 4 (same as above)
s4_patch_size = 2 ,
s4_local_patch_size = 7 ,
s4_global_k = 7 ,
s4_depth = 4 ,
peg_kernel_size = 3 , # positional encoding generator kernel size
dropout = 0. # dropout
)
img = torch . randn ( 1 , 3 , 224 , 224 )
pred = model ( img ) # (1, 1000) 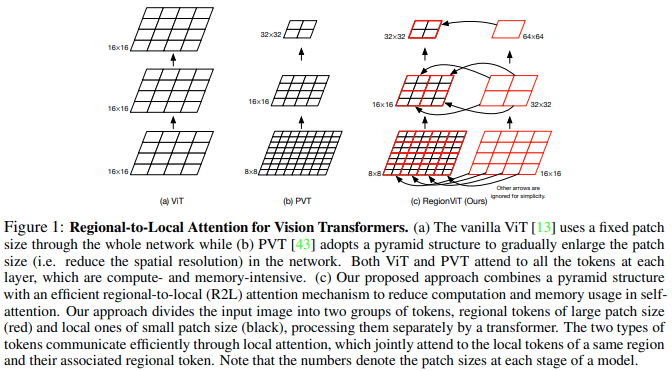
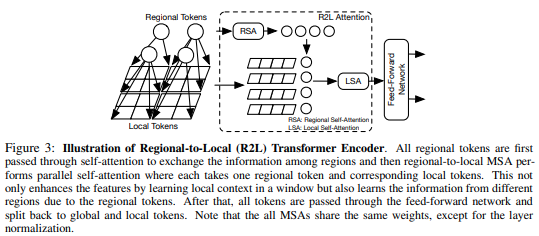
Makalah ini mengusulkan untuk membagi peta fitur menjadi wilayah lokal, di mana token lokal saling berinteraksi. Setiap wilayah lokal memiliki token regionalnya sendiri yang kemudian melayani semua token lokalnya, serta token regional lainnya.
Anda dapat menggunakannya sebagai berikut
import torch
from vit_pytorch . regionvit import RegionViT
model = RegionViT (
dim = ( 64 , 128 , 256 , 512 ), # tuple of size 4, indicating dimension at each stage
depth = ( 2 , 2 , 8 , 2 ), # depth of the region to local transformer at each stage
window_size = 7 , # window size, which should be either 7 or 14
num_classes = 1000 , # number of output classes
tokenize_local_3_conv = False , # whether to use a 3 layer convolution to encode the local tokens from the image. the paper uses this for the smaller models, but uses only 1 conv (set to False) for the larger models
use_peg = False , # whether to use positional generating module. they used this for object detection for a boost in performance
)
img = torch . randn ( 1 , 3 , 224 , 224 )
pred = model ( img ) # (1, 1000) 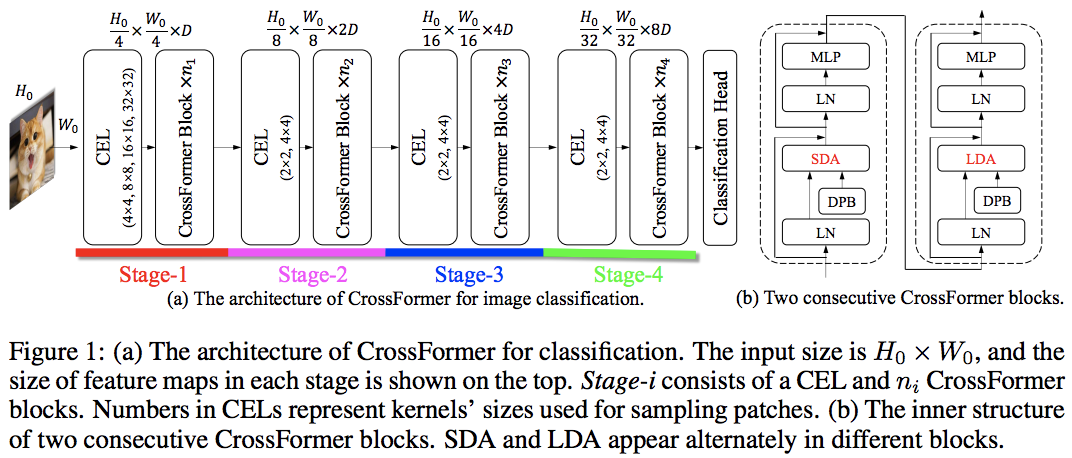
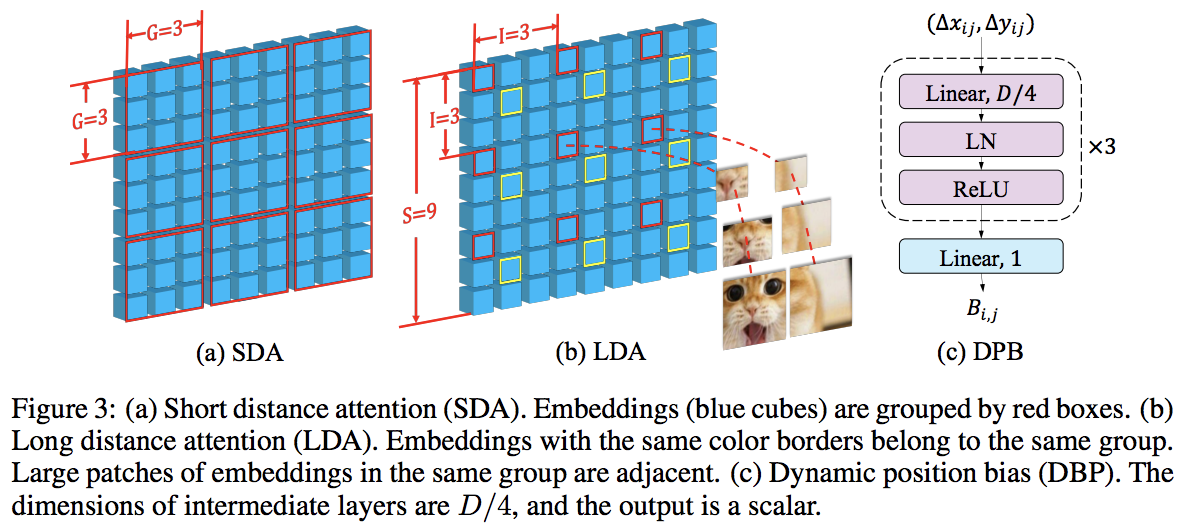
Makalah ini mengalahkan PVT dan Swin dengan menggunakan perhatian lokal dan global secara bergantian. Perhatian global dilakukan di seluruh dimensi windowing untuk mengurangi kompleksitas, seperti skema yang digunakan untuk perhatian aksial.
Mereka juga memiliki lapisan penyematan lintas skala, yang terbukti sebagai lapisan umum yang dapat meningkatkan semua transformator penglihatan. Bias posisi relatif dinamis juga diformulasikan untuk memungkinkan jaring menggeneralisasi gambar dengan resolusi lebih besar.
import torch
from vit_pytorch . crossformer import CrossFormer
model = CrossFormer (
num_classes = 1000 , # number of output classes
dim = ( 64 , 128 , 256 , 512 ), # dimension at each stage
depth = ( 2 , 2 , 8 , 2 ), # depth of transformer at each stage
global_window_size = ( 8 , 4 , 2 , 1 ), # global window sizes at each stage
local_window_size = 7 , # local window size (can be customized for each stage, but in paper, held constant at 7 for all stages)
)
img = torch . randn ( 1 , 3 , 224 , 224 )
pred = model ( img ) # (1, 1000) 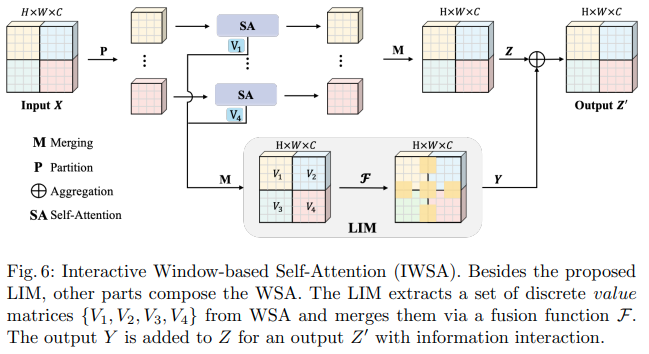
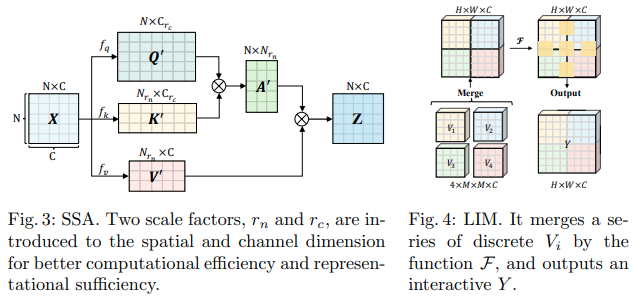
Makalah Bytedance AI ini mengusulkan modul Scalable Self Attention (SSA) dan Interactive Windowed Self Attention (IWSA). SSA meringankan komputasi yang diperlukan pada tahap awal dengan mengurangi peta fitur kunci/nilai sebanyak beberapa faktor ( reduction_factor ), sekaligus memodulasi dimensi kueri dan kunci ( ssa_dim_key ). IWSA melakukan perhatian mandiri dalam jendela lokal, serupa dengan makalah transformator visi lainnya. Namun, mereka menambahkan sisa nilai, melewati konvolusi ukuran kernel 3, yang mereka beri nama Local Interactive Module (LIM).
Mereka membuat klaim dalam tulisan ini bahwa skema ini mengungguli Swin Transformer, dan juga menunjukkan kinerja kompetitif terhadap Crossformer.
Anda dapat menggunakannya sebagai berikut (mis. ScalableViT-S)
import torch
from vit_pytorch . scalable_vit import ScalableViT
model = ScalableViT (
num_classes = 1000 ,
dim = 64 , # starting model dimension. at every stage, dimension is doubled
heads = ( 2 , 4 , 8 , 16 ), # number of attention heads at each stage
depth = ( 2 , 2 , 20 , 2 ), # number of transformer blocks at each stage
ssa_dim_key = ( 40 , 40 , 40 , 32 ), # the dimension of the attention keys (and queries) for SSA. in the paper, they represented this as a scale factor on the base dimension per key (ssa_dim_key / dim_key)
reduction_factor = ( 8 , 4 , 2 , 1 ), # downsampling of the key / values in SSA. in the paper, this was represented as (reduction_factor ** -2)
window_size = ( 64 , 32 , None , None ), # window size of the IWSA at each stage. None means no windowing needed
dropout = 0.1 , # attention and feedforward dropout
)
img = torch . randn ( 1 , 3 , 256 , 256 )
preds = model ( img ) # (1, 1000) 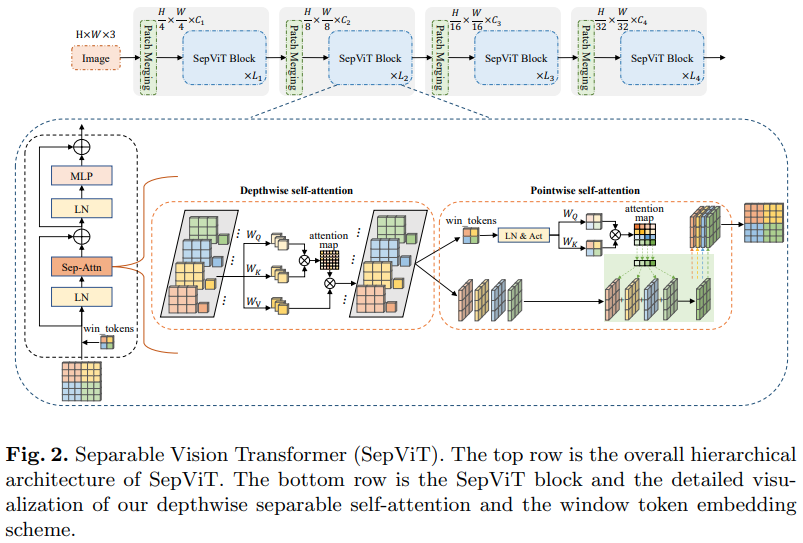
Makalah Bytedance AI lainnya, mengusulkan lapisan perhatian diri yang sangat mendalam yang tampaknya sebagian besar terinspirasi oleh konvolusi mobilenet yang dapat dipisahkan secara mendalam. Aspek yang paling menarik adalah penggunaan kembali peta fitur dari tahap perhatian diri secara mendalam sebagai nilai perhatian diri secara langsung, seperti yang ditunjukkan pada diagram di atas.
Saya telah memutuskan untuk hanya menyertakan versi SepViT dengan lapisan perhatian diri khusus ini, karena lapisan perhatian yang dikelompokkan bukanlah hal yang luar biasa atau baru, dan penulis tidak jelas tentang bagaimana mereka memperlakukan token jendela untuk lapisan perhatian diri kelompok. Selain itu, sepertinya hanya dengan lapisan DSSA saja, mereka mampu mengalahkan Swin.
mantan. SepViT-Lite
import torch
from vit_pytorch . sep_vit import SepViT
v = SepViT (
num_classes = 1000 ,
dim = 32 , # dimensions of first stage, which doubles every stage (32, 64, 128, 256) for SepViT-Lite
dim_head = 32 , # attention head dimension
heads = ( 1 , 2 , 4 , 8 ), # number of heads per stage
depth = ( 1 , 2 , 6 , 2 ), # number of transformer blocks per stage
window_size = 7 , # window size of DSS Attention block
dropout = 0.1 # dropout
)
img = torch . randn ( 1 , 3 , 224 , 224 )
preds = v ( img ) # (1, 1000) 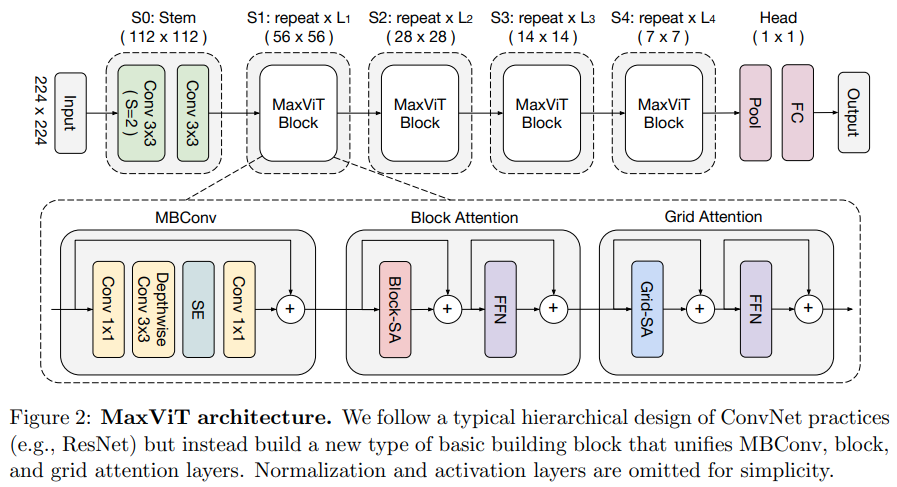
Makalah ini mengusulkan jaringan konvolusional/perhatian hibrid, menggunakan MBConv dari sisi konvolusi, dan kemudian perhatian renggang aksial blok/grid.
Mereka juga mengklaim transformator visi khusus ini bagus untuk model generatif (GAN).
mantan. MaxViT-S
import torch
from vit_pytorch . max_vit import MaxViT
v = MaxViT (
num_classes = 1000 ,
dim_conv_stem = 64 , # dimension of the convolutional stem, would default to dimension of first layer if not specified
dim = 96 , # dimension of first layer, doubles every layer
dim_head = 32 , # dimension of attention heads, kept at 32 in paper
depth = ( 2 , 2 , 5 , 2 ), # number of MaxViT blocks per stage, which consists of MBConv, block-like attention, grid-like attention
window_size = 7 , # window size for block and grids
mbconv_expansion_rate = 4 , # expansion rate of MBConv
mbconv_shrinkage_rate = 0.25 , # shrinkage rate of squeeze-excitation in MBConv
dropout = 0.1 # dropout
)
img = torch . randn ( 2 , 3 , 224 , 224 )
preds = v ( img ) # (2, 1000) 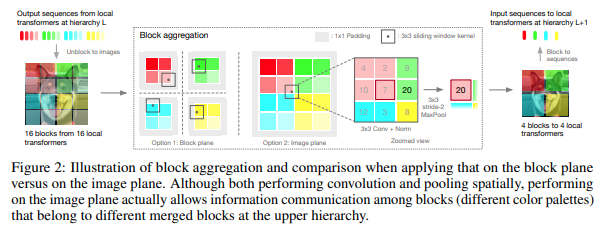
Makalah ini memutuskan untuk memproses gambar dalam tahapan hierarki, dengan perhatian hanya pada token blok lokal, yang terakumulasi seiring naiknya hierarki. Agregasi dilakukan pada bidang gambar, dan berisi konvolusi dan maxpool berikutnya untuk memungkinkannya meneruskan informasi melintasi batas.
Anda dapat menggunakannya dengan kode berikut (mis. NestT-T)
import torch
from vit_pytorch . nest import NesT
nest = NesT (
image_size = 224 ,
patch_size = 4 ,
dim = 96 ,
heads = 3 ,
num_hierarchies = 3 , # number of hierarchies
block_repeats = ( 2 , 2 , 8 ), # the number of transformer blocks at each hierarchy, starting from the bottom
num_classes = 1000
)
img = torch . randn ( 1 , 3 , 224 , 224 )
pred = nest ( img ) # (1, 1000) 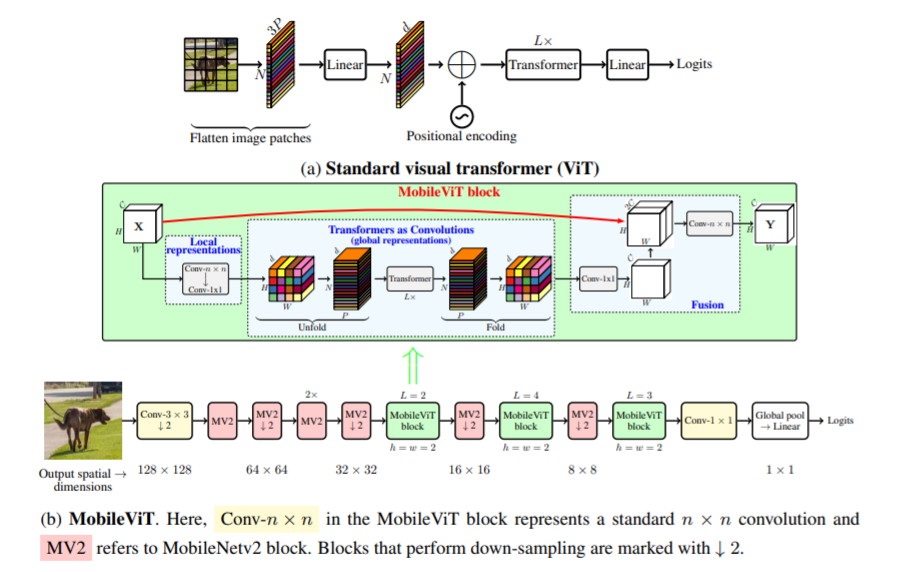
Makalah ini memperkenalkan MobileViT, transformator visi yang ringan dan bertujuan umum untuk perangkat seluler. MobileViT menghadirkan perspektif berbeda untuk pemrosesan informasi global dengan transformator.
Anda dapat menggunakannya dengan kode berikut (mis. mobilevit_xs)
import torch
from vit_pytorch . mobile_vit import MobileViT
mbvit_xs = MobileViT (
image_size = ( 256 , 256 ),
dims = [ 96 , 120 , 144 ],
channels = [ 16 , 32 , 48 , 48 , 64 , 64 , 80 , 80 , 96 , 96 , 384 ],
num_classes = 1000
)
img = torch . randn ( 1 , 3 , 256 , 256 )
pred = mbvit_xs ( img ) # (1, 1000) 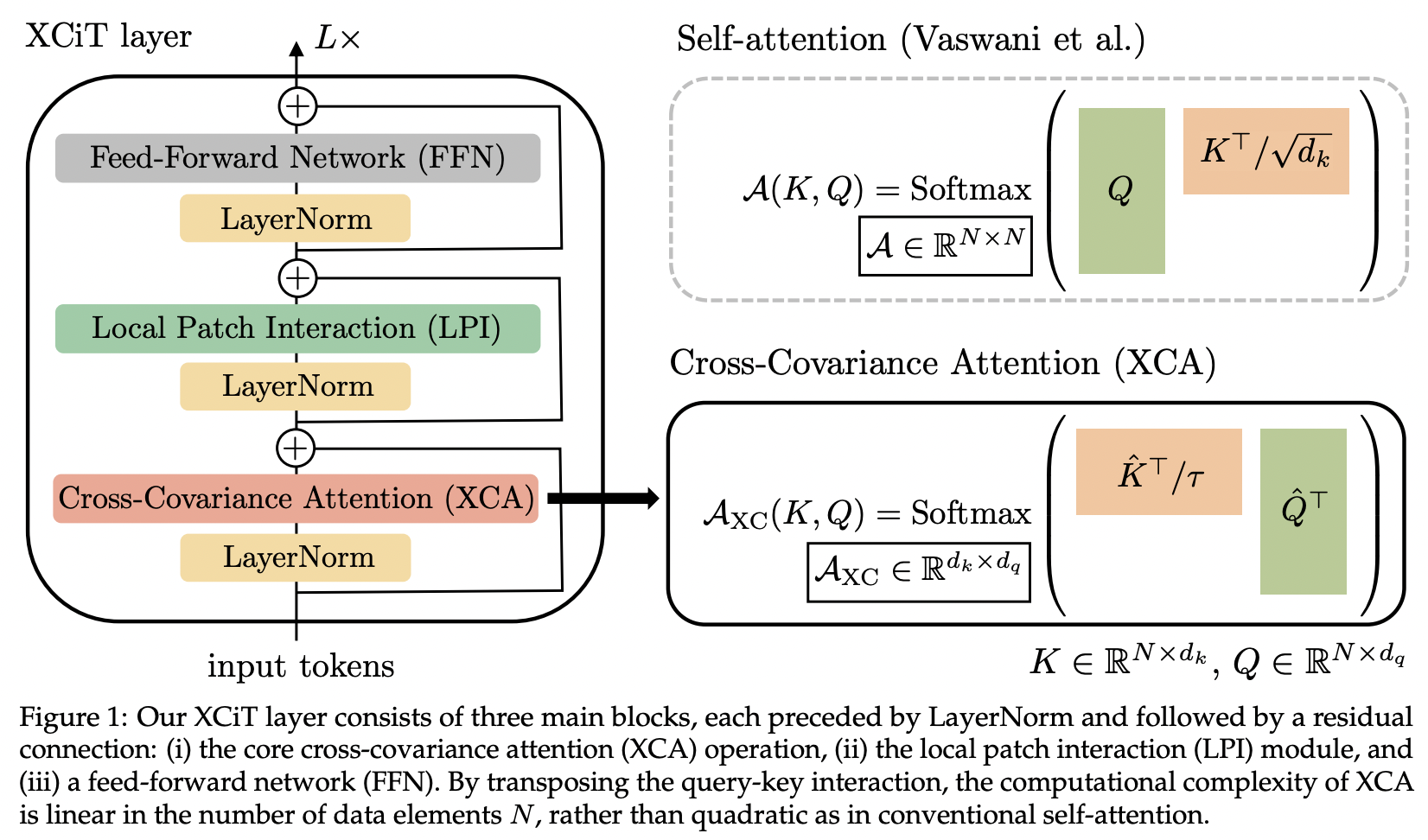
Makalah ini memperkenalkan perhatian kovarians silang (disingkat XCA). Seseorang dapat menganggapnya sebagai melakukan perhatian pada dimensi fitur daripada dimensi spasial (perspektif lain adalah konvolusi dinamis 1x1, intinya adalah peta perhatian yang ditentukan oleh korelasi spasial).
Secara teknis, ini berarti mentransposisi kueri, kunci, nilai sebelum menjalankan perhatian kesamaan kosinus dengan suhu yang dipelajari.
import torch
from vit_pytorch . xcit import XCiT
v = XCiT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 12 , # depth of xcit transformer
cls_depth = 2 , # depth of cross attention of CLS tokens to patch, attention pool at end
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1 ,
layer_dropout = 0.05 , # randomly dropout 5% of the layers
local_patch_kernel_size = 3 # kernel size of the local patch interaction module (depthwise convs)
)
img = torch . randn ( 1 , 3 , 256 , 256 )
preds = v ( img ) # (1, 1000) 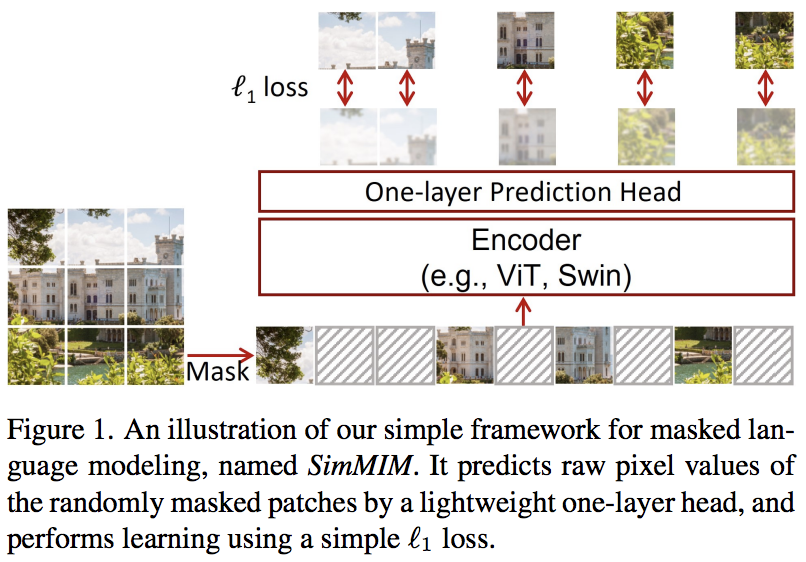
Makalah ini mengusulkan skema pemodelan gambar bertopeng sederhana (SimMIM), hanya menggunakan proyeksi linier dari token bertopeng ke dalam ruang piksel diikuti dengan hilangnya L1 dengan nilai piksel dari patch bertopeng. Hasilnya bersaing dengan pendekatan lain yang lebih rumit.
Anda dapat menggunakannya sebagai berikut
import torch
from vit_pytorch import ViT
from vit_pytorch . simmim import SimMIM
v = ViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 8 ,
mlp_dim = 2048
)
mim = SimMIM (
encoder = v ,
masking_ratio = 0.5 # they found 50% to yield the best results
)
images = torch . randn ( 8 , 3 , 256 , 256 )
loss = mim ( images )
loss . backward ()
# that's all!
# do the above in a for loop many times with a lot of images and your vision transformer will learn
torch . save ( v . state_dict (), './trained-vit.pt' )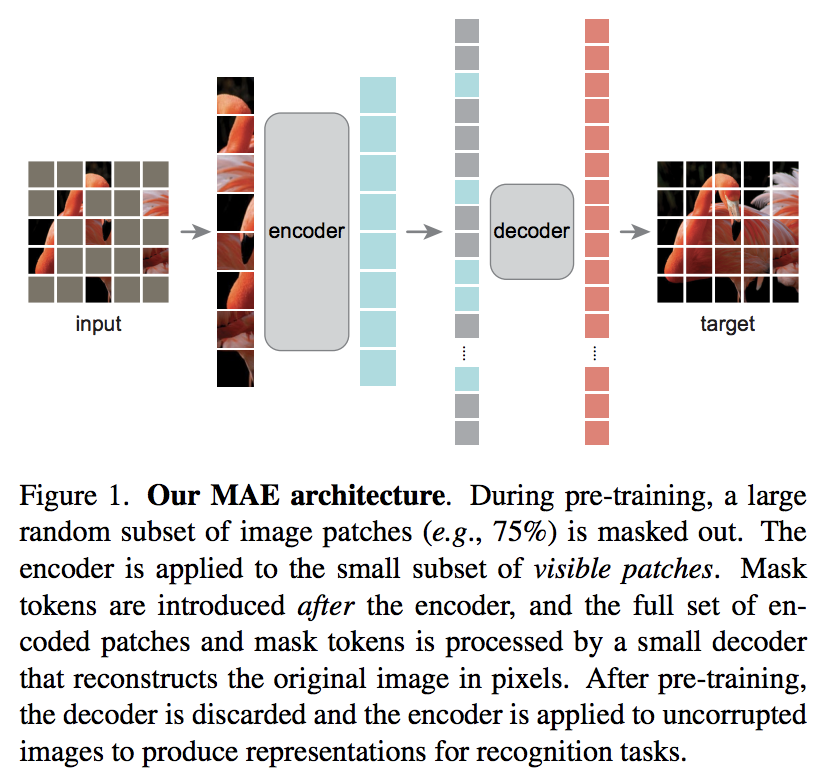
Makalah Kaiming He yang baru mengusulkan skema autoencoder sederhana di mana transformator visi menangani serangkaian patch yang terbuka kedoknya, dan dekoder yang lebih kecil mencoba merekonstruksi nilai piksel yang disamarkan.
Tinjauan makalah singkat DeepReader
AI Coffeebreak bersama Letitia
Anda dapat menggunakannya dengan kode berikut
import torch
from vit_pytorch import ViT , MAE
v = ViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 8 ,
mlp_dim = 2048
)
mae = MAE (
encoder = v ,
masking_ratio = 0.75 , # the paper recommended 75% masked patches
decoder_dim = 512 , # paper showed good results with just 512
decoder_depth = 6 # anywhere from 1 to 8
)
images = torch . randn ( 8 , 3 , 256 , 256 )
loss = mae ( images )
loss . backward ()
# that's all!
# do the above in a for loop many times with a lot of images and your vision transformer will learn
# save your improved vision transformer
torch . save ( v . state_dict (), './trained-vit.pt' )Berkat Zach, Anda dapat berlatih menggunakan tugas prediksi patch bertopeng asli yang disajikan di makalah, dengan kode berikut.
import torch
from vit_pytorch import ViT
from vit_pytorch . mpp import MPP
model = ViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 8 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
mpp_trainer = MPP (
transformer = model ,
patch_size = 32 ,
dim = 1024 ,
mask_prob = 0.15 , # probability of using token in masked prediction task
random_patch_prob = 0.30 , # probability of randomly replacing a token being used for mpp
replace_prob = 0.50 , # probability of replacing a token being used for mpp with the mask token
)
opt = torch . optim . Adam ( mpp_trainer . parameters (), lr = 3e-4 )
def sample_unlabelled_images ():
return torch . FloatTensor ( 20 , 3 , 256 , 256 ). uniform_ ( 0. , 1. )
for _ in range ( 100 ):
images = sample_unlabelled_images ()
loss = mpp_trainer ( images )
opt . zero_grad ()
loss . backward ()
opt . step ()
# save your improved network
torch . save ( model . state_dict (), './pretrained-net.pt' )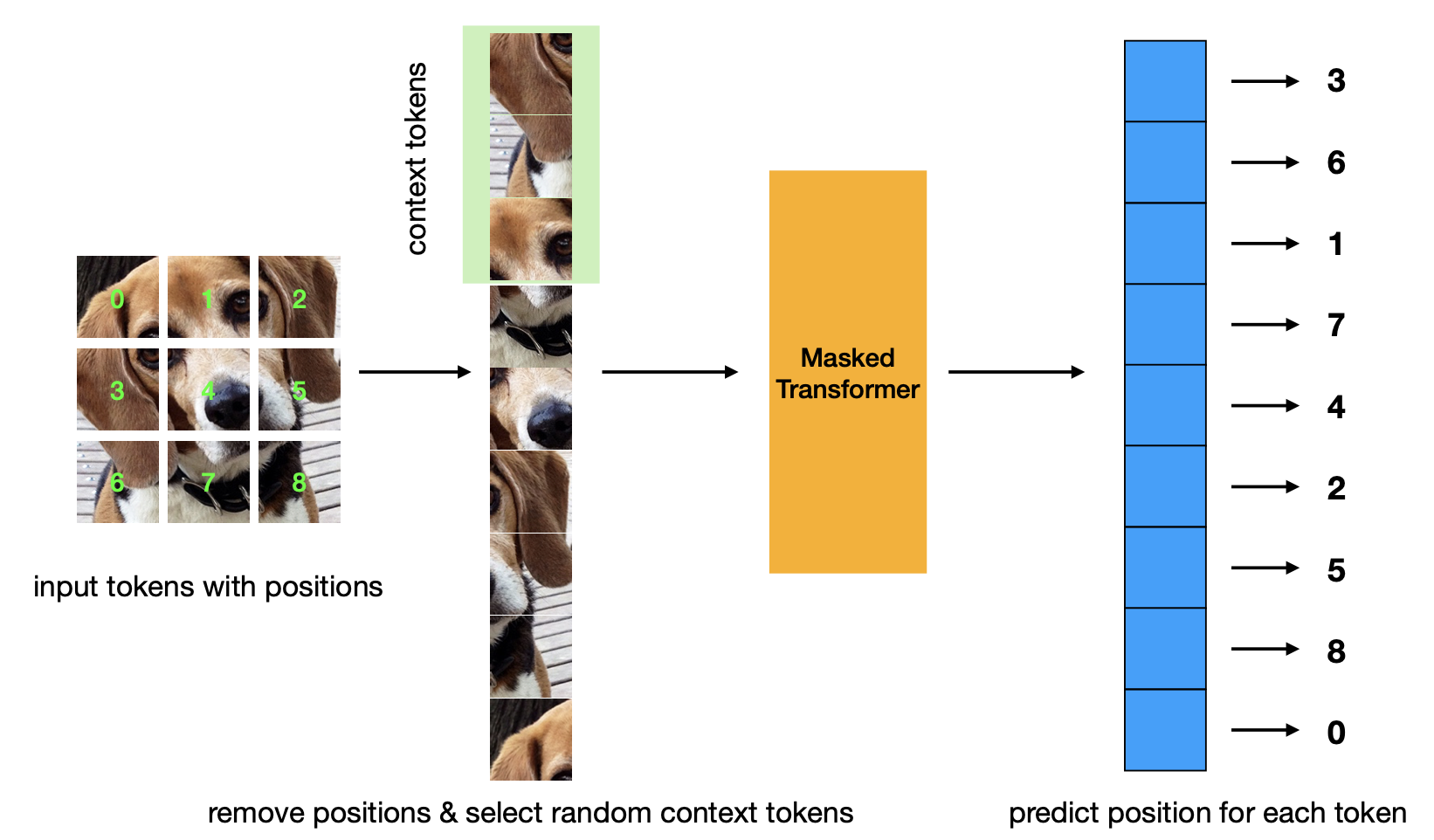
Makalah baru yang memperkenalkan kriteria pra-pelatihan prediksi posisi bertopeng. Strategi ini lebih efisien dibandingkan strategi Masked Autoencoder dan memiliki performa yang sebanding.
import torch
from vit_pytorch . mp3 import ViT , MP3
v = ViT (
num_classes = 1000 ,
image_size = 256 ,
patch_size = 8 ,
dim = 1024 ,
depth = 6 ,
heads = 8 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
)
mp3 = MP3 (
vit = v ,
masking_ratio = 0.75
)
images = torch . randn ( 8 , 3 , 256 , 256 )
loss = mp3 ( images )
loss . backward ()
# that's all!
# do the above in a for loop many times with a lot of images and your vision transformer will learn
# save your improved vision transformer
torch . save ( v . state_dict (), './trained-vit.pt' )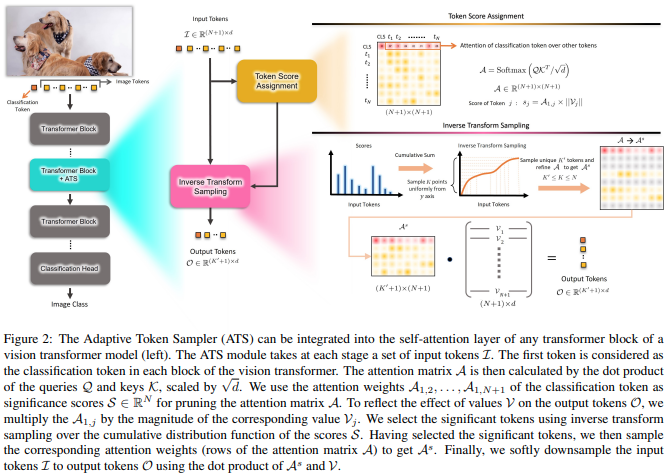
Makalah ini mengusulkan untuk menggunakan skor perhatian CLS, yang ditimbang kembali berdasarkan norma-norma kepala nilai, sebagai sarana untuk membuang token yang tidak penting di lapisan yang berbeda.
import torch
from vit_pytorch . ats_vit import ViT
v = ViT (
image_size = 256 ,
patch_size = 16 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
max_tokens_per_depth = ( 256 , 128 , 64 , 32 , 16 , 8 ), # a tuple that denotes the maximum number of tokens that any given layer should have. if the layer has greater than this amount, it will undergo adaptive token sampling
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
img = torch . randn ( 4 , 3 , 256 , 256 )
preds = v ( img ) # (4, 1000)
# you can also get a list of the final sampled patch ids
# a value of -1 denotes padding
preds , token_ids = v ( img , return_sampled_token_ids = True ) # (4, 1000), (4, <=8) 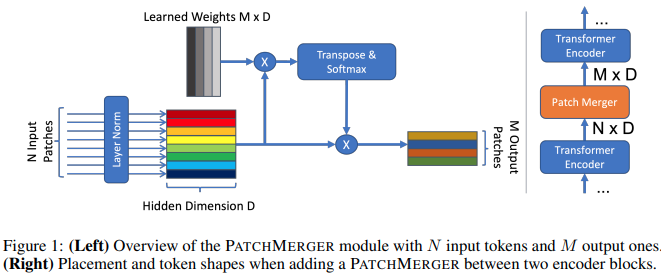
Makalah ini mengusulkan modul sederhana (Patch Merger) untuk mengurangi jumlah token di setiap lapisan transformator visi tanpa mengorbankan kinerja.
import torch
from vit_pytorch . vit_with_patch_merger import ViT
v = ViT (
image_size = 256 ,
patch_size = 16 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 12 ,
heads = 8 ,
patch_merge_layer = 6 , # at which transformer layer to do patch merging
patch_merge_num_tokens = 8 , # the output number of tokens from the patch merge
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
img = torch . randn ( 4 , 3 , 256 , 256 )
preds = v ( img ) # (4, 1000) Anda juga dapat menggunakan modul PatchMerger dengan sendirinya
import torch
from vit_pytorch . vit_with_patch_merger import PatchMerger
merger = PatchMerger (
dim = 1024 ,
num_tokens_out = 8 # output number of tokens
)
features = torch . randn ( 4 , 256 , 1024 ) # (batch, num tokens, dimension)
out = merger ( features ) # (4, 8, 1024) 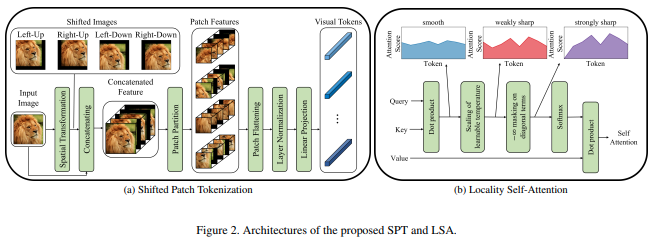
Makalah ini mengusulkan fungsi gambar baru untuk menambal yang menggabungkan pergeseran gambar, sebelum normalisasi dan membagi gambar menjadi beberapa tambalan. Saya mendapati peralihan sangat membantu dalam beberapa pekerjaan trafo lainnya, jadi saya memutuskan untuk memasukkan ini untuk eksplorasi lebih lanjut. Ini juga mencakup LSA dengan suhu yang dipelajari dan menutupi perhatian token terhadap dirinya sendiri.
Anda dapat menggunakan sebagai berikut:
import torch
from vit_pytorch . vit_for_small_dataset import ViT
v = ViT (
image_size = 256 ,
patch_size = 16 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
img = torch . randn ( 4 , 3 , 256 , 256 )
preds = v ( img ) # (1, 1000) Anda juga dapat menggunakan SPT dari makalah ini sebagai modul mandiri
import torch
from vit_pytorch . vit_for_small_dataset import SPT
spt = SPT (
dim = 1024 ,
patch_size = 16 ,
channels = 3
)
img = torch . randn ( 4 , 3 , 256 , 256 )
tokens = spt ( img ) # (4, 256, 1024) Berdasarkan permintaan populer, saya akan mulai memperluas beberapa arsitektur dalam repositori ini ke ViT 3D, untuk digunakan dengan video, pencitraan medis, dll.
Anda harus memasukkan dua hyperparameter tambahan: (1) jumlah frame frames dan (2) ukuran patch sepanjang dimensi frame frame_patch_size
Sebagai permulaan, ViT 3D
import torch
from vit_pytorch . vit_3d import ViT
v = ViT (
image_size = 128 , # image size
frames = 16 , # number of frames
image_patch_size = 16 , # image patch size
frame_patch_size = 2 , # frame patch size
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 8 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
video = torch . randn ( 4 , 3 , 16 , 128 , 128 ) # (batch, channels, frames, height, width)
preds = v ( video ) # (4, 1000)ViT Sederhana 3D
import torch
from vit_pytorch . simple_vit_3d import SimpleViT
v = SimpleViT (
image_size = 128 , # image size
frames = 16 , # number of frames
image_patch_size = 16 , # image patch size
frame_patch_size = 2 , # frame patch size
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 8 ,
mlp_dim = 2048
)
video = torch . randn ( 4 , 3 , 16 , 128 , 128 ) # (batch, channels, frames, height, width)
preds = v ( video ) # (4, 1000)CCT versi 3D
import torch
from vit_pytorch . cct_3d import CCT
cct = CCT (
img_size = 224 ,
num_frames = 8 ,
embedding_dim = 384 ,
n_conv_layers = 2 ,
frame_kernel_size = 3 ,
kernel_size = 7 ,
stride = 2 ,
padding = 3 ,
pooling_kernel_size = 3 ,
pooling_stride = 2 ,
pooling_padding = 1 ,
num_layers = 14 ,
num_heads = 6 ,
mlp_ratio = 3. ,
num_classes = 1000 ,
positional_embedding = 'learnable'
)
video = torch . randn ( 1 , 3 , 8 , 224 , 224 ) # (batch, channels, frames, height, width)
pred = cct ( video )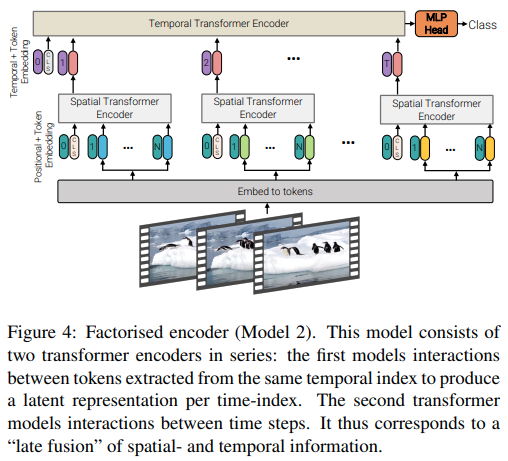
Makalah ini menawarkan 3 jenis arsitektur berbeda untuk perhatian video yang efisien, dengan tema utamanya adalah memfaktorkan perhatian melintasi ruang dan waktu. Repositori ini mencakup encoder terfaktor dan varian perhatian mandiri terfaktor. Varian encoder terfaktor adalah transformator spasial yang diikuti oleh transformator temporal. Varian perhatian diri yang difaktorkan adalah transformator spatio-temporal dengan lapisan perhatian diri spasial dan temporal yang bergantian.
import torch
from vit_pytorch . vivit import ViT
v = ViT (
image_size = 128 , # image size
frames = 16 , # number of frames
image_patch_size = 16 , # image patch size
frame_patch_size = 2 , # frame patch size
num_classes = 1000 ,
dim = 1024 ,
spatial_depth = 6 , # depth of the spatial transformer
temporal_depth = 6 , # depth of the temporal transformer
heads = 8 ,
mlp_dim = 2048 ,
variant = 'factorized_encoder' , # or 'factorized_self_attention'
)
video = torch . randn ( 4 , 3 , 16 , 128 , 128 ) # (batch, channels, frames, height, width)
preds = v ( video ) # (4, 1000) 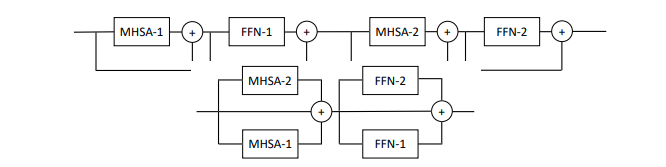
Makalah ini mengusulkan untuk memparalelkan beberapa blok perhatian dan umpan maju per lapisan (2 blok), mengklaim bahwa lebih mudah untuk berlatih tanpa kehilangan kinerja.
Anda bisa mencoba varian ini sebagai berikut
import torch
from vit_pytorch . parallel_vit import ViT
v = ViT (
image_size = 256 ,
patch_size = 16 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 8 ,
mlp_dim = 2048 ,
num_parallel_branches = 2 , # in paper, they claimed 2 was optimal
dropout = 0.1 ,
emb_dropout = 0.1
)
img = torch . randn ( 4 , 3 , 256 , 256 )
preds = v ( img ) # (4, 1000) 
Makalah ini menunjukkan bahwa menambahkan token memori yang dapat dipelajari pada setiap lapisan transformator visi dapat sangat meningkatkan hasil penyesuaian (selain token CLS dan kepala adaptor khusus tugas yang dapat dipelajari).
Anda dapat menggunakan ini dengan ViT yang dimodifikasi khusus sebagai berikut
import torch
from vit_pytorch . learnable_memory_vit import ViT , Adapter
# normal base ViT
v = ViT (
image_size = 256 ,
patch_size = 16 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 8 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
img = torch . randn ( 4 , 3 , 256 , 256 )
logits = v ( img ) # (4, 1000)
# do your usual training with ViT
# ...
# then, to finetune, just pass the ViT into the Adapter class
# you can do this for multiple Adapters, as shown below
adapter1 = Adapter (
vit = v ,
num_classes = 2 , # number of output classes for this specific task
num_memories_per_layer = 5 # number of learnable memories per layer, 10 was sufficient in paper
)
logits1 = adapter1 ( img ) # (4, 2) - predict 2 classes off frozen ViT backbone with learnable memories and task specific head
# yet another task to finetune on, this time with 4 classes
adapter2 = Adapter (
vit = v ,
num_classes = 4 ,
num_memories_per_layer = 10
)
logits2 = adapter2 ( img ) # (4, 4) - predict 4 classes off frozen ViT backbone with learnable memories and task specific head 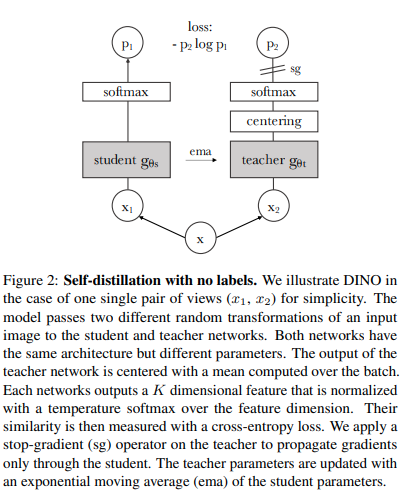
Anda dapat melatih ViT dengan teknik pembelajaran mandiri SOTA terbaru, Dino, dengan kode berikut.
Video Yannic Kilcher
import torch
from vit_pytorch import ViT , Dino
model = ViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 8 ,
mlp_dim = 2048
)
learner = Dino (
model ,
image_size = 256 ,
hidden_layer = 'to_latent' , # hidden layer name or index, from which to extract the embedding
projection_hidden_size = 256 , # projector network hidden dimension
projection_layers = 4 , # number of layers in projection network
num_classes_K = 65336 , # output logits dimensions (referenced as K in paper)
student_temp = 0.9 , # student temperature
teacher_temp = 0.04 , # teacher temperature, needs to be annealed from 0.04 to 0.07 over 30 epochs
local_upper_crop_scale = 0.4 , # upper bound for local crop - 0.4 was recommended in the paper
global_lower_crop_scale = 0.5 , # lower bound for global crop - 0.5 was recommended in the paper
moving_average_decay = 0.9 , # moving average of encoder - paper showed anywhere from 0.9 to 0.999 was ok
center_moving_average_decay = 0.9 , # moving average of teacher centers - paper showed anywhere from 0.9 to 0.999 was ok
)
opt = torch . optim . Adam ( learner . parameters (), lr = 3e-4 )
def sample_unlabelled_images ():
return torch . randn ( 20 , 3 , 256 , 256 )
for _ in range ( 100 ):
images = sample_unlabelled_images ()
loss = learner ( images )
opt . zero_grad ()
loss . backward ()
opt . step ()
learner . update_moving_average () # update moving average of teacher encoder and teacher centers
# save your improved network
torch . save ( model . state_dict (), './pretrained-net.pt' )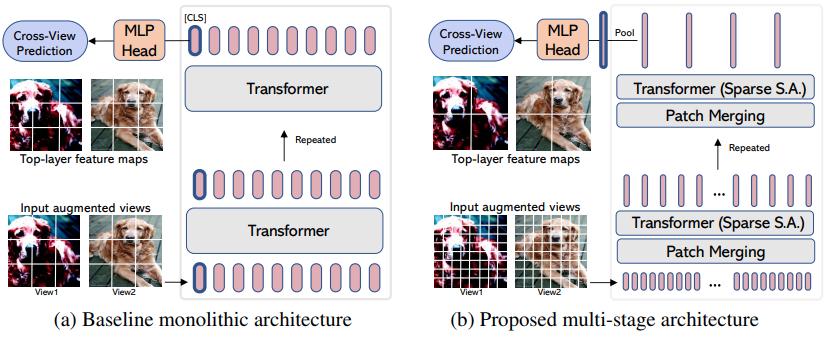
EsViT adalah varian Dino (dari atas) yang direkayasa ulang untuk mendukung ViT yang efisien dengan penggabungan patch/downsampling dengan memperhitungkan kerugian regional tambahan di antara tampilan yang diperbesar. Mengutip abstraknya, kinerjanya outperforms its supervised counterpart on 17 out of 18 datasets dengan throughput 3 kali lebih tinggi.
Meskipun disebut sebagai varian ViT baru, sebenarnya ini hanyalah sebuah strategi untuk melatih ViT multitahap (dalam makalah, mereka fokus pada Swin). Contoh di bawah ini akan menunjukkan cara menggunakannya dengan CvT . Anda harus menyetel hidden_layer ke nama lapisan dalam ViT efisien Anda yang menghasilkan representasi visual kumpulan non-rata-rata, tepat sebelum pengumpulan global dan proyeksi ke logit.
import torch
from vit_pytorch . cvt import CvT
from vit_pytorch . es_vit import EsViTTrainer
cvt = CvT (
num_classes = 1000 ,
s1_emb_dim = 64 ,
s1_emb_kernel = 7 ,
s1_emb_stride = 4 ,
s1_proj_kernel = 3 ,
s1_kv_proj_stride = 2 ,
s1_heads = 1 ,
s1_depth = 1 ,
s1_mlp_mult = 4 ,
s2_emb_dim = 192 ,
s2_emb_kernel = 3 ,
s2_emb_stride = 2 ,
s2_proj_kernel = 3 ,
s2_kv_proj_stride = 2 ,
s2_heads = 3 ,
s2_depth = 2 ,
s2_mlp_mult = 4 ,
s3_emb_dim = 384 ,
s3_emb_kernel = 3 ,
s3_emb_stride = 2 ,
s3_proj_kernel = 3 ,
s3_kv_proj_stride = 2 ,
s3_heads = 4 ,
s3_depth = 10 ,
s3_mlp_mult = 4 ,
dropout = 0.
)
learner = EsViTTrainer (
cvt ,
image_size = 256 ,
hidden_layer = 'layers' , # hidden layer name or index, from which to extract the embedding
projection_hidden_size = 256 , # projector network hidden dimension
projection_layers = 4 , # number of layers in projection network
num_classes_K = 65336 , # output logits dimensions (referenced as K in paper)
student_temp = 0.9 , # student temperature
teacher_temp = 0.04 , # teacher temperature, needs to be annealed from 0.04 to 0.07 over 30 epochs
local_upper_crop_scale = 0.4 , # upper bound for local crop - 0.4 was recommended in the paper
global_lower_crop_scale = 0.5 , # lower bound for global crop - 0.5 was recommended in the paper
moving_average_decay = 0.9 , # moving average of encoder - paper showed anywhere from 0.9 to 0.999 was ok
center_moving_average_decay = 0.9 , # moving average of teacher centers - paper showed anywhere from 0.9 to 0.999 was ok
)
opt = torch . optim . AdamW ( learner . parameters (), lr = 3e-4 )
def sample_unlabelled_images ():
return torch . randn ( 8 , 3 , 256 , 256 )
for _ in range ( 1000 ):
images = sample_unlabelled_images ()
loss = learner ( images )
opt . zero_grad ()
loss . backward ()
opt . step ()
learner . update_moving_average () # update moving average of teacher encoder and teacher centers
# save your improved network
torch . save ( cvt . state_dict (), './pretrained-net.pt' )Jika Anda ingin memvisualisasikan bobot perhatian (post-softmax) untuk penelitian Anda, cukup ikuti prosedur di bawah ini
import torch
from vit_pytorch . vit import ViT
v = ViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
# import Recorder and wrap the ViT
from vit_pytorch . recorder import Recorder
v = Recorder ( v )
# forward pass now returns predictions and the attention maps
img = torch . randn ( 1 , 3 , 256 , 256 )
preds , attns = v ( img )
# there is one extra patch due to the CLS token
attns # (1, 6, 16, 65, 65) - (batch x layers x heads x patch x patch)untuk membersihkan kelas dan hook setelah Anda mengumpulkan cukup data
v = v . eject () # wrapper is discarded and original ViT instance is returned Anda juga dapat mengakses embeddings dengan pembungkus Extractor
import torch
from vit_pytorch . vit import ViT
v = ViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
# import Recorder and wrap the ViT
from vit_pytorch . extractor import Extractor
v = Extractor ( v )
# forward pass now returns predictions and the attention maps
img = torch . randn ( 1 , 3 , 256 , 256 )
logits , embeddings = v ( img )
# there is one extra token due to the CLS token
embeddings # (1, 65, 1024) - (batch x patches x model dim) Atau katakanlah untuk CrossViT , yang memiliki encoder multiskala yang menghasilkan dua set embeddings untuk skala 'besar' dan 'kecil'
import torch
from vit_pytorch . cross_vit import CrossViT
v = CrossViT (
image_size = 256 ,
num_classes = 1000 ,
depth = 4 ,
sm_dim = 192 ,
sm_patch_size = 16 ,
sm_enc_depth = 2 ,
sm_enc_heads = 8 ,
sm_enc_mlp_dim = 2048 ,
lg_dim = 384 ,
lg_patch_size = 64 ,
lg_enc_depth = 3 ,
lg_enc_heads = 8 ,
lg_enc_mlp_dim = 2048 ,
cross_attn_depth = 2 ,
cross_attn_heads = 8 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
# wrap the CrossViT
from vit_pytorch . extractor import Extractor
v = Extractor ( v , layer_name = 'multi_scale_encoder' ) # take embedding coming from the output of multi-scale-encoder
# forward pass now returns predictions and the attention maps
img = torch . randn ( 1 , 3 , 256 , 256 )
logits , embeddings = v ( img )
# there is one extra token due to the CLS token
embeddings # ((1, 257, 192), (1, 17, 384)) - (batch x patches x dimension) <- large and small scales respectively Mungkin ada beberapa orang yang berasal dari visi komputer yang berpendapat bahwa perhatian masih dipengaruhi oleh biaya kuadrat. Untungnya, kami memiliki banyak teknik baru yang mungkin bisa membantu. Repositori ini menawarkan cara bagi Anda untuk memasang trafo perhatian Anda sendiri.
Contoh dengan Nystromformer
$ pip install nystrom-attention import torch
from vit_pytorch . efficient import ViT
from nystrom_attention import Nystromformer
efficient_transformer = Nystromformer (
dim = 512 ,
depth = 12 ,
heads = 8 ,
num_landmarks = 256
)
v = ViT (
dim = 512 ,
image_size = 2048 ,
patch_size = 32 ,
num_classes = 1000 ,
transformer = efficient_transformer
)
img = torch . randn ( 1 , 3 , 2048 , 2048 ) # your high resolution picture
v ( img ) # (1, 1000)Kerangka kerja lain yang jarang saya rekomendasikan adalah Routing Transformer atau Sinkhorn Transformer
Makalah ini sengaja menggunakan jaringan perhatian paling vanilla untuk membuat pernyataan. Jika Anda ingin menggunakan beberapa perbaikan terbaru untuk jaring perhatian, silakan gunakan Encoder dari repositori ini.
mantan.
$ pip install x-transformers import torch
from vit_pytorch . efficient import ViT
from x_transformers import Encoder
v = ViT (
dim = 512 ,
image_size = 224 ,
patch_size = 16 ,
num_classes = 1000 ,
transformer = Encoder (
dim = 512 , # set to be the same as the wrapper
depth = 12 ,
heads = 8 ,
ff_glu = True , # ex. feed forward GLU variant https://arxiv.org/abs/2002.05202
residual_attn = True # ex. residual attention https://arxiv.org/abs/2012.11747
)
)
img = torch . randn ( 1 , 3 , 224 , 224 )
v ( img ) # (1, 1000) Anda sudah bisa memasukkan gambar non-persegi - Anda hanya perlu memastikan tinggi dan lebarnya kurang dari atau sama dengan image_size , dan keduanya habis dibagi patch_size
mantan.
import torch
from vit_pytorch import ViT
v = ViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
img = torch . randn ( 1 , 3 , 256 , 128 ) # <-- not a square
preds = v ( img ) # (1, 1000) import torch
from vit_pytorch import ViT
v = ViT (
num_classes = 1000 ,
image_size = ( 256 , 128 ), # image size is a tuple of (height, width)
patch_size = ( 32 , 16 ), # patch size is a tuple of (height, width)
dim = 1024 ,
depth = 6 ,
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
img = torch . randn ( 1 , 3 , 256 , 128 )
preds = v ( img )Berasal dari visi komputer dan baru mengenal transformator? Berikut adalah beberapa sumber yang sangat mempercepat pembelajaran saya.
Transformator Bergambar - Jay Alammar
Transformers dari Awal - Peter Bloem
Transformator Beranotasi - Harvard NLP
@article { hassani2021escaping ,
title = { Escaping the Big Data Paradigm with Compact Transformers } ,
author = { Ali Hassani and Steven Walton and Nikhil Shah and Abulikemu Abuduweili and Jiachen Li and Humphrey Shi } ,
year = 2021 ,
url = { https://arxiv.org/abs/2104.05704 } ,
eprint = { 2104.05704 } ,
archiveprefix = { arXiv } ,
primaryclass = { cs.CV }
} @misc { dosovitskiy2020image ,
title = { An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale } ,
author = { Alexey Dosovitskiy and Lucas Beyer and Alexander Kolesnikov and Dirk Weissenborn and Xiaohua Zhai and Thomas Unterthiner and Mostafa Dehghani and Matthias Minderer and Georg Heigold and Sylvain Gelly and Jakob Uszkoreit and Neil Houlsby } ,
year = { 2020 } ,
eprint = { 2010.11929 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { touvron2020training ,
title = { Training data-efficient image transformers & distillation through attention } ,
author = { Hugo Touvron and Matthieu Cord and Matthijs Douze and Francisco Massa and Alexandre Sablayrolles and Hervé Jégou } ,
year = { 2020 } ,
eprint = { 2012.12877 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { yuan2021tokenstotoken ,
title = { Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet } ,
author = { Li Yuan and Yunpeng Chen and Tao Wang and Weihao Yu and Yujun Shi and Francis EH Tay and Jiashi Feng and Shuicheng Yan } ,
year = { 2021 } ,
eprint = { 2101.11986 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { zhou2021deepvit ,
title = { DeepViT: Towards Deeper Vision Transformer } ,
author = { Daquan Zhou and Bingyi Kang and Xiaojie Jin and Linjie Yang and Xiaochen Lian and Qibin Hou and Jiashi Feng } ,
year = { 2021 } ,
eprint = { 2103.11886 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { touvron2021going ,
title = { Going deeper with Image Transformers } ,
author = { Hugo Touvron and Matthieu Cord and Alexandre Sablayrolles and Gabriel Synnaeve and Hervé Jégou } ,
year = { 2021 } ,
eprint = { 2103.17239 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { chen2021crossvit ,
title = { CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification } ,
author = { Chun-Fu Chen and Quanfu Fan and Rameswar Panda } ,
year = { 2021 } ,
eprint = { 2103.14899 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { wu2021cvt ,
title = { CvT: Introducing Convolutions to Vision Transformers } ,
author = { Haiping Wu and Bin Xiao and Noel Codella and Mengchen Liu and Xiyang Dai and Lu Yuan and Lei Zhang } ,
year = { 2021 } ,
eprint = { 2103.15808 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { heo2021rethinking ,
title = { Rethinking Spatial Dimensions of Vision Transformers } ,
author = { Byeongho Heo and Sangdoo Yun and Dongyoon Han and Sanghyuk Chun and Junsuk Choe and Seong Joon Oh } ,
year = { 2021 } ,
eprint = { 2103.16302 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { graham2021levit ,
title = { LeViT: a Vision Transformer in ConvNet's Clothing for Faster Inference } ,
author = { Ben Graham and Alaaeldin El-Nouby and Hugo Touvron and Pierre Stock and Armand Joulin and Hervé Jégou and Matthijs Douze } ,
year = { 2021 } ,
eprint = { 2104.01136 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { li2021localvit ,
title = { LocalViT: Bringing Locality to Vision Transformers } ,
author = { Yawei Li and Kai Zhang and Jiezhang Cao and Radu Timofte and Luc Van Gool } ,
year = { 2021 } ,
eprint = { 2104.05707 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { chu2021twins ,
title = { Twins: Revisiting Spatial Attention Design in Vision Transformers } ,
author = { Xiangxiang Chu and Zhi Tian and Yuqing Wang and Bo Zhang and Haibing Ren and Xiaolin Wei and Huaxia Xia and Chunhua Shen } ,
year = { 2021 } ,
eprint = { 2104.13840 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { su2021roformer ,
title = { RoFormer: Enhanced Transformer with Rotary Position Embedding } ,
author = { Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu } ,
year = { 2021 } ,
eprint = { 2104.09864 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
} @misc { zhang2021aggregating ,
title = { Aggregating Nested Transformers } ,
author = { Zizhao Zhang and Han Zhang and Long Zhao and Ting Chen and Tomas Pfister } ,
year = { 2021 } ,
eprint = { 2105.12723 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { chen2021regionvit ,
title = { RegionViT: Regional-to-Local Attention for Vision Transformers } ,
author = { Chun-Fu Chen and Rameswar Panda and Quanfu Fan } ,
year = { 2021 } ,
eprint = { 2106.02689 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { wang2021crossformer ,
title = { CrossFormer: A Versatile Vision Transformer Hinging on Cross-scale Attention } ,
author = { Wenxiao Wang and Lu Yao and Long Chen and Binbin Lin and Deng Cai and Xiaofei He and Wei Liu } ,
year = { 2021 } ,
eprint = { 2108.00154 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { caron2021emerging ,
title = { Emerging Properties in Self-Supervised Vision Transformers } ,
author = { Mathilde Caron and Hugo Touvron and Ishan Misra and Hervé Jégou and Julien Mairal and Piotr Bojanowski and Armand Joulin } ,
year = { 2021 } ,
eprint = { 2104.14294 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { he2021masked ,
title = { Masked Autoencoders Are Scalable Vision Learners } ,
author = { Kaiming He and Xinlei Chen and Saining Xie and Yanghao Li and Piotr Dollár and Ross Girshick } ,
year = { 2021 } ,
eprint = { 2111.06377 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { xie2021simmim ,
title = { SimMIM: A Simple Framework for Masked Image Modeling } ,
author = { Zhenda Xie and Zheng Zhang and Yue Cao and Yutong Lin and Jianmin Bao and Zhuliang Yao and Qi Dai and Han Hu } ,
year = { 2021 } ,
eprint = { 2111.09886 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { fayyaz2021ats ,
title = { ATS: Adaptive Token Sampling For Efficient Vision Transformers } ,
author = { Mohsen Fayyaz and Soroush Abbasi Kouhpayegani and Farnoush Rezaei Jafari and Eric Sommerlade and Hamid Reza Vaezi Joze and Hamed Pirsiavash and Juergen Gall } ,
year = { 2021 } ,
eprint = { 2111.15667 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { mehta2021mobilevit ,
title = { MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer } ,
author = { Sachin Mehta and Mohammad Rastegari } ,
year = { 2021 } ,
eprint = { 2110.02178 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { lee2021vision ,
title = { Vision Transformer for Small-Size Datasets } ,
author = { Seung Hoon Lee and Seunghyun Lee and Byung Cheol Song } ,
year = { 2021 } ,
eprint = { 2112.13492 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { renggli2022learning ,
title = { Learning to Merge Tokens in Vision Transformers } ,
author = { Cedric Renggli and André Susano Pinto and Neil Houlsby and Basil Mustafa and Joan Puigcerver and Carlos Riquelme } ,
year = { 2022 } ,
eprint = { 2202.12015 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { yang2022scalablevit ,
title = { ScalableViT: Rethinking the Context-oriented Generalization of Vision Transformer } ,
author = { Rui Yang and Hailong Ma and Jie Wu and Yansong Tang and Xuefeng Xiao and Min Zheng and Xiu Li } ,
year = { 2022 } ,
eprint = { 2203.10790 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @inproceedings { Touvron2022ThreeTE ,
title = { Three things everyone should know about Vision Transformers } ,
author = { Hugo Touvron and Matthieu Cord and Alaaeldin El-Nouby and Jakob Verbeek and Herv'e J'egou } ,
year = { 2022 }
} @inproceedings { Sandler2022FinetuningIT ,
title = { Fine-tuning Image Transformers using Learnable Memory } ,
author = { Mark Sandler and Andrey Zhmoginov and Max Vladymyrov and Andrew Jackson } ,
year = { 2022 }
} @inproceedings { Li2022SepViTSV ,
title = { SepViT: Separable Vision Transformer } ,
author = { Wei Li and Xing Wang and Xin Xia and Jie Wu and Xuefeng Xiao and Minghang Zheng and Shiping Wen } ,
year = { 2022 }
} @inproceedings { Tu2022MaxViTMV ,
title = { MaxViT: Multi-Axis Vision Transformer } ,
author = { Zhengzhong Tu and Hossein Talebi and Han Zhang and Feng Yang and Peyman Milanfar and Alan Conrad Bovik and Yinxiao Li } ,
year = { 2022 }
} @article { Li2021EfficientSV ,
title = { Efficient Self-supervised Vision Transformers for Representation Learning } ,
author = { Chunyuan Li and Jianwei Yang and Pengchuan Zhang and Mei Gao and Bin Xiao and Xiyang Dai and Lu Yuan and Jianfeng Gao } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2106.09785 }
} @misc { Beyer2022BetterPlainViT
title = { Better plain ViT baselines for ImageNet-1k } ,
author = { Beyer, Lucas and Zhai, Xiaohua and Kolesnikov, Alexander } ,
publisher = { arXiv } ,
year = { 2022 }
}
@article { Arnab2021ViViTAV ,
title = { ViViT: A Video Vision Transformer } ,
author = { Anurag Arnab and Mostafa Dehghani and Georg Heigold and Chen Sun and Mario Lucic and Cordelia Schmid } ,
journal = { 2021 IEEE/CVF International Conference on Computer Vision (ICCV) } ,
year = { 2021 } ,
pages = { 6816-6826 }
} @article { Liu2022PatchDropoutEV ,
title = { PatchDropout: Economizing Vision Transformers Using Patch Dropout } ,
author = { Yue Liu and Christos Matsoukas and Fredrik Strand and Hossein Azizpour and Kevin Smith } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2208.07220 }
} @misc { https://doi.org/10.48550/arxiv.2302.01327 ,
doi = { 10.48550/ARXIV.2302.01327 } ,
url = { https://arxiv.org/abs/2302.01327 } ,
author = { Kumar, Manoj and Dehghani, Mostafa and Houlsby, Neil } ,
title = { Dual PatchNorm } ,
publisher = { arXiv } ,
year = { 2023 } ,
copyright = { Creative Commons Attribution 4.0 International }
} @inproceedings { Dehghani2023PatchNP ,
title = { Patch n' Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution } ,
author = { Mostafa Dehghani and Basil Mustafa and Josip Djolonga and Jonathan Heek and Matthias Minderer and Mathilde Caron and Andreas Steiner and Joan Puigcerver and Robert Geirhos and Ibrahim M. Alabdulmohsin and Avital Oliver and Piotr Padlewski and Alexey A. Gritsenko and Mario Luvci'c and Neil Houlsby } ,
year = { 2023 }
} @misc { vaswani2017attention ,
title = { Attention Is All You Need } ,
author = { Ashish Vaswani and Noam Shazeer and Niki Parmar and Jakob Uszkoreit and Llion Jones and Aidan N. Gomez and Lukasz Kaiser and Illia Polosukhin } ,
year = { 2017 } ,
eprint = { 1706.03762 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @inproceedings { Darcet2023VisionTN ,
title = { Vision Transformers Need Registers } ,
author = { Timoth'ee Darcet and Maxime Oquab and Julien Mairal and Piotr Bojanowski } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:263134283 }
} @inproceedings { ElNouby2021XCiTCI ,
title = { XCiT: Cross-Covariance Image Transformers } ,
author = { Alaaeldin El-Nouby and Hugo Touvron and Mathilde Caron and Piotr Bojanowski and Matthijs Douze and Armand Joulin and Ivan Laptev and Natalia Neverova and Gabriel Synnaeve and Jakob Verbeek and Herv{'e} J{'e}gou } ,
booktitle = { Neural Information Processing Systems } ,
year = { 2021 } ,
url = { https://api.semanticscholar.org/CorpusID:235458262 }
} @inproceedings { Koner2024LookupViTCV ,
title = { LookupViT: Compressing visual information to a limited number of tokens } ,
author = { Rajat Koner and Gagan Jain and Prateek Jain and Volker Tresp and Sujoy Paul } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:271244592 }
} @article { Bao2022AllAW ,
title = { All are Worth Words: A ViT Backbone for Diffusion Models } ,
author = { Fan Bao and Shen Nie and Kaiwen Xue and Yue Cao and Chongxuan Li and Hang Su and Jun Zhu } ,
journal = { 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) } ,
year = { 2022 } ,
pages = { 22669-22679 } ,
url = { https://api.semanticscholar.org/CorpusID:253581703 }
} @misc { Rubin2024 ,
author = { Ohad Rubin } ,
url = { https://medium.com/ @ ohadrubin/exploring-weight-decay-in-layer-normalization-challenges-and-a-reparameterization-solution-ad4d12c24950 }
} @inproceedings { Loshchilov2024nGPTNT ,
title = { nGPT: Normalized Transformer with Representation Learning on the Hypersphere } ,
author = { Ilya Loshchilov and Cheng-Ping Hsieh and Simeng Sun and Boris Ginsburg } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273026160 }
} @inproceedings { Liu2017DeepHL ,
title = { Deep Hyperspherical Learning } ,
author = { Weiyang Liu and Yanming Zhang and Xingguo Li and Zhen Liu and Bo Dai and Tuo Zhao and Le Song } ,
booktitle = { Neural Information Processing Systems } ,
year = { 2017 } ,
url = { https://api.semanticscholar.org/CorpusID:5104558 }
} @inproceedings { Zhou2024ValueRL ,
title = { Value Residual Learning For Alleviating Attention Concentration In Transformers } ,
author = { Zhanchao Zhou and Tianyi Wu and Zhiyun Jiang and Zhenzhong Lan } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273532030 }
} @article { Zhu2024HyperConnections ,
title = { Hyper-Connections } ,
author = { Defa Zhu and Hongzhi Huang and Zihao Huang and Yutao Zeng and Yunyao Mao and Banggu Wu and Qiyang Min and Xun Zhou } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2409.19606 } ,
url = { https://api.semanticscholar.org/CorpusID:272987528 }
}Saya membayangkan suatu masa ketika kita akan menjadi robot seperti halnya anjing bagi manusia, dan saya mendukung mesin. —Claude Shannon


