rtdl num embeddings
v0.0.11
Penting
Lihat model DL tabel baru: TabM
arXiv? Paket Python Proyek DL tabel lainnya
Ini adalah implementasi resmi dari makalah "Tentang Penyematan Fitur Numerik dalam Pembelajaran Mendalam Tabular".
Dalam satu kalimat: mengubah fitur kontinu skalar asli menjadi vektor sebelum mencampurkannya ke tulang punggung utama (misalnya di MLP, Transformer, dll.) meningkatkan kinerja hilir jaringan saraf tabular.
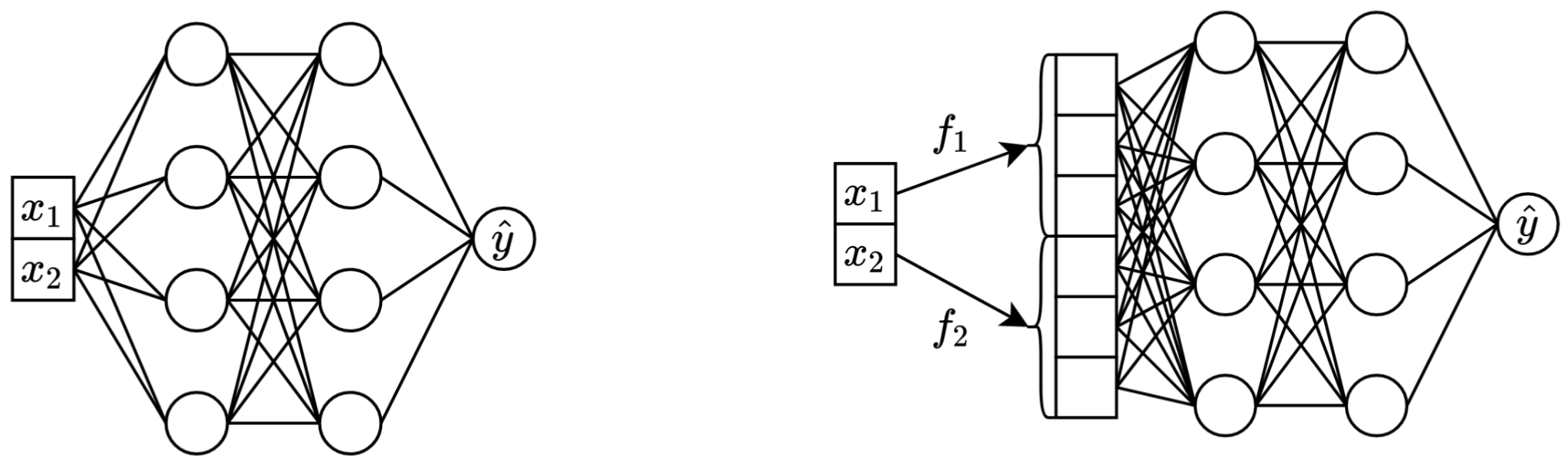
Kiri: vanilla MLP mengambil dua fitur berkelanjutan sebagai masukan.
Benar: MLP yang sama, tetapi sekarang dengan penyematan untuk fitur berkelanjutan.
Lebih detailnya:
Sebenarnya, tidak ada penjelasan tunggal. Terbukti, penyematan membantu mengatasi berbagai tantangan yang terkait dengan fitur berkelanjutan dan meningkatkan properti pengoptimalan model secara keseluruhan.
Secara khusus, fitur kontinu yang terdistribusi tidak teratur (dan distribusi gabungannya yang tidak teratur dengan label) adalah hal yang biasa dalam data tabular dunia nyata, dan hal ini menimbulkan tantangan pengoptimalan mendasar yang besar untuk model DL tabel tradisional. Referensi yang bagus untuk memahami tantangan ini (dan contoh yang bagus untuk mengatasi tantangan tersebut dengan mengubah ruang input) adalah makalah "Fitur Fourier Biarkan Jaringan Mempelajari Fungsi Frekuensi Tinggi dalam Domain Dimensi Rendah".
Namun, tidak jelas apakah distribusi yang tidak teratur adalah satu-satunya alasan mengapa penyematan tersebut bermanfaat.
Paket Python di direktori package/ adalah cara yang direkomendasikan untuk menggunakan makalah ini dalam praktik dan untuk pekerjaan di masa mendatang.
Sisa dokumen :
Direktori exp/ berisi banyak hasil dan hyperparameter (yang disesuaikan) untuk berbagai model dan kumpulan data yang digunakan dalam makalah ini.
Misalnya, mari kita jelajahi metrik untuk model MLP. Pertama, mari kita muat laporannya (file report.json ):
import json
from pathlib import Path
import pandas as pd
df = pd . json_normalize ([
json . loads ( x . read_text ())
for x in Path ( 'exp' ). glob ( 'mlp/*/0_evaluation/*/report.json' )
])Sekarang, untuk setiap kumpulan data, mari kita hitung rata-rata skor ujian dari semua benih acak:
print ( df . groupby ( 'config.data.path' )[ 'metrics.test.score' ]. mean (). round ( 3 ))Outputnya sama persis dengan Tabel 3 dari makalah:
config.data.path
data/adult 0.854
data/california -0.495
data/churn 0.856
data/covtype 0.964
data/fb-comments -5.686
data/gesture 0.632
data/higgs-small 0.720
data/house -32039.399
data/microsoft -0.747
data/otto 0.818
data/santander 0.912
Name: metrics.test.score, dtype: float64
Pendekatan di atas juga dapat digunakan untuk mengeksplorasi hyperparameter guna mendapatkan intuisi tentang nilai hyperparameter tipikal untuk algoritma yang berbeda. Misalnya, berikut cara menghitung median kecepatan pemelajaran yang disesuaikan untuk model MLP:
Catatan
Untuk beberapa algoritma (misalnya MLP, MLP-LR, MLP-PLR), proyek yang lebih baru menawarkan lebih banyak hasil yang dapat dieksplorasi dengan cara serupa. Misalnya, lihat makalah ini di TabR.
Peringatan
Gunakan pendekatan ini dengan hati-hati. Saat mempelajari nilai hyperparameter:
print ( df [ df [ 'config.seed' ] == 0 ][ 'config.training.lr' ]. quantile ( 0.5 ))
# Output: 0.0002716544410603358Penting
Bagian ini panjang. Gunakan fitur "Garis Besar" di GitHub di editor teks Anda untuk mendapatkan ikhtisar bagian ini.
Persiapan:
/usr/local/cuda-11.1/bin selalu ada dalam variabel lingkungan PATH Anda export PROJECT_DIR= < ABSOLUTE path to the repository root >
# example: export PROJECT_DIR=/home/myusername/repositories/num-embeddings
git clone https://github.com/yandex-research/tabular-dl-num-embeddings $PROJECT_DIR
cd $PROJECT_DIR
conda create -n num-embeddings python=3.9.7
conda activate num-embeddings
pip install torch==1.10.1+cu111 -f https://download.pytorch.org/whl/torch_stable.html
pip install -r requirements.txt
# if the following commands do not succeed, update conda
conda env config vars set PYTHONPATH= ${PYTHONPATH} : ${PROJECT_DIR}
conda env config vars set PROJECT_DIR= ${PROJECT_DIR}
# the following command appends ":/usr/local/cuda-11.1/lib64" to LD_LIBRARY_PATH;
# if your LD_LIBRARY_PATH already contains a path to some other CUDA, then the content
# after "=" should be "<your LD_LIBRARY_PATH without your cuda path>:/usr/local/cuda-11.1/lib64"
conda env config vars set LD_LIBRARY_PATH= ${LD_LIBRARY_PATH} :/usr/local/cuda-11.1/lib64
conda env config vars set CUDA_HOME=/usr/local/cuda-11.1
conda env config vars set CUDA_ROOT=/usr/local/cuda-11.1
# (optional) get a shortcut for toggling the dark mode with cmd+y
conda install nodejs
jupyter labextension install jupyterlab-theme-toggle
conda deactivate
conda activate num-embeddingsLISENSI: dengan mengunduh kumpulan data kami, Anda menerima lisensi semua komponennya. Kami tidak menerapkan batasan baru apa pun selain lisensi tersebut. Anda dapat menemukan daftar sumber di koran.
cd $PROJECT_DIR
wget " https://www.dropbox.com/s/r0ef3ij3wl049gl/data.tar?dl=1 " -O num_embeddings_data.tar
tar -xvf num_embeddings_data.tarKode di bawah ini mereproduksi hasil MLP pada kumpulan data Perumahan California. Saluran untuk algoritme dan kumpulan data lainnya sama persis.
# You must explicitly set CUDA_VISIBLE_DEVICES if you want to use GPU
export CUDA_VISIBLE_DEVICES="0"
# Create a copy of the 'official' config
cp exp/mlp/california/0_tuning.toml exp/mlp/california/1_tuning.toml
# Run tuning (on GPU, it takes ~30-60min)
python bin/tune.py exp/mlp/california/1_tuning.toml
# Evaluate single models with 15 different random seeds
python bin/evaluate.py exp/mlp/california/1_tuning 15
# Evaluate ensembles (by default, three ensembles of size five each)
python bin/ensemble.py exp/mlp/california/1_evaluation
Bagian "Metrik" menunjukkan cara merangkum hasil yang diperoleh.
Kode ini disusun sebagai berikut:
bintrain4.py untuk jaringan saraf (ini mengimplementasikan semua embeddings dan tulang punggung dari kertas)xgboost_.py untuk XGBoostcatboost_.py untuk CatBoosttune.py untuk penyetelanevaluate.py untuk evaluasiensemble.py untuk perakitandatasets.py digunakan untuk membuat pemisahan kumpulan datasynthetic.py untuk menghasilkan kumpulan data ramah GBDT sintetistrain1_synthetic.py untuk eksperimen dengan data sintetislib berisi alat umum yang digunakan oleh program di binexp berisi konfigurasi dan hasil eksperimen (metrik, konfigurasi yang disetel, dll.). Nama folder yang disarangkan mengikuti nama dari kertas (contoh: exp/mlp-plr sesuai dengan model MLP-PLR dari kertas).package berisi paket Python untuk makalah iniCUDA_VISIBLE_DEVICES secara eksplisit saat menjalankan skriplib.dump_config dan lib.load_config alih-alih pustaka TOML kosongPola umum untuk menjalankan skrip adalah:
python bin/my_script.py a/b/c.toml di mana a/b/c.toml adalah file konfigurasi masukan (config). Outputnya akan ditempatkan di a/b/c . Struktur konfigurasi biasanya mengikuti kelas Config dari bin/my_script.py .
Ada juga skrip yang menggunakan argumen baris perintah dan bukan konfigurasi (misalnya bin/{evaluate.py,ensemble.py} ).
Anda memerlukan semuanya untuk mereproduksi hasil, tetapi Anda hanya memerlukan train4.py untuk pekerjaan selanjutnya, karena:
bin/train1.py mengimplementasikan superset fitur dari bin/train0.pybin/train3.py mengimplementasikan superset fitur dari bin/train1.pybin/train4.py mengimplementasikan superset fitur dari bin/train3.py Untuk melihat salah satu dari empat skrip yang digunakan untuk menjalankan eksperimen tertentu, periksa bidang "program" pada konfigurasi penyetelan yang sesuai. Misalnya, berikut adalah konfigurasi penyetelan untuk MLP pada kumpulan data California Housing: exp/mlp/california/0_tuning.toml . Konfigurasi menunjukkan bahwa bin/train0.py telah digunakan. Artinya konfigurasi di exp/mlp/california/0_evaluation kompatibel secara khusus dengan bin/train0.py . Untuk memverifikasinya, Anda dapat menyalin salah satunya ke lokasi terpisah dan meneruskan ke bin/train0.py :
mkdir exp/tmp
cp exp/mlp/california/0_evaluation/0.toml exp/tmp/0.toml
python bin/train0.py exp/tmp/0.toml
ls exp/tmp/0
@inproceedings{gorishniy2022embeddings,
title={On Embeddings for Numerical Features in Tabular Deep Learning},
author={Yury Gorishniy and Ivan Rubachev and Artem Babenko},
booktitle={{NeurIPS}},
year={2022},
}


